






C++入门基础:
1.C++与C语言的区别(大厂面试高频题):
- C++既可以面向对象又可以面向过程,持有面向对象三大特性:封装,继承,多态,而C语言只是面向过程,并没有面向对象的三大特性。
- C++类型检查更为严格,C语言中类型转化几乎都是任意的,但是C++编译器对于类型转换进行非常严格检查,部分强制类型转化在C编译器中可以通过,但是C++编译器是无法通过的。
- C++提供了泛型模版的支持(Template),同时也提供了模版标准库(STL)的支持,以及引用,运算符重载和命名空间(避免命名冲突)。
- C++与C应用领域不同:C语言常用于直接控制硬件,特别是C语言在嵌入式领域应用很广,比如常见的驱动开发等与硬件直接打交道的领域,C++可以用于应用层开发,用户界面开发等与操作系统打交道的领域,特别是图形图像领域,几乎所有高性能图形图像库都是C++实现。
2.C++编译过程:预处理+编译+汇编+链接(动态链接与静态链接)(大厂面试高频题)
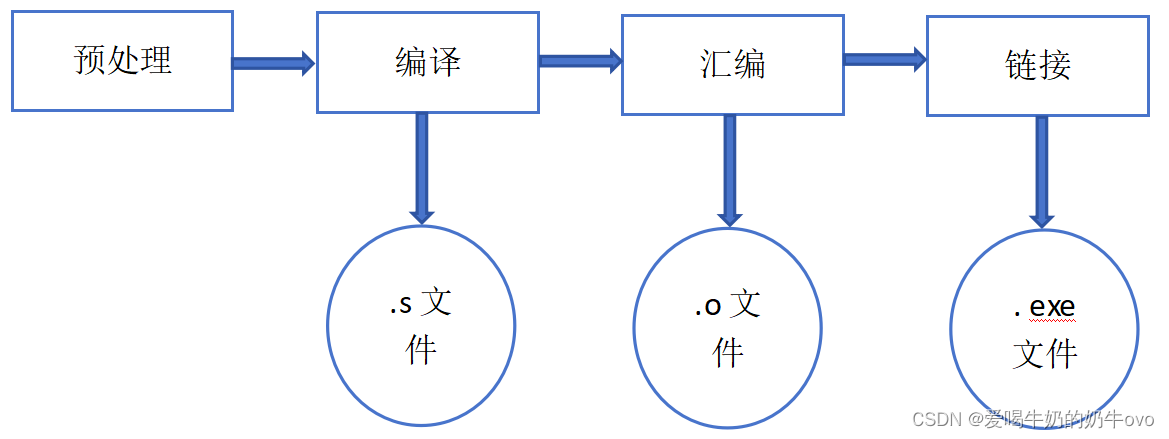
- 预处理:处理“#”之后以及特殊字符的指令。(在编译之前的工作)
- 编译:将源文件(.cpp文件)翻译成机器语言(汇编),并生成.s文件。
- 汇编:将汇编语言翻译成目标机器指令,并生成.o文件。
- 链接:链接分为静态链接与动态链接。其实就是将所有的目标文件链接起来,并生成可执行文件即.exe文件。
- 静态链接:可支持程序员我们自己开发程序模块,提高了效率。但是缺点就是浪费空间,消耗资源,而且更新迭代比较困难。
- 动态链接:一般为.dll文件,动态链接是在运行时才将所有的目标文件链接起来(相当于推迟链接),一般情况下,我们通常将静态链接与动态链接结合使用。
3.C++中的头文件与源文件(.h文件与.cpp文件)
- 在C++的世界里,C++文件通常进行分层,包含头文件(.h文件)与源文件(.cpp文件)。
- 头文件(.h文件):头文件是用来声明函数与变量,实现对函数的封装的。
- 源文件(.cpp文件):源文件用来对声明函数的实现的。
- < >与" "的区别(大厂面试高频题):引用< >,编译器是从系统库中寻找对应的头文件,一般用于标准库头文件;而引用" ",编译器首先是从当前文件夹寻找头文件,当找不到以后,再从系统文件中进行寻找,一般用于自己定义的头文件。
hello_world.h文件:
const char*message="hello world"; //字符串常量
void hello_world();
hello_world.cpp文件:
#include <iostream> //系统标准库
#include "hello_world.h"//自己定义的hello_world.h
using namespace std;//命名空间std
//对hello_world函数的实现
void hello_world(){
std::cout<<message<<std::endl;
//cout<<message<<endl;//同上
}
int main(int argc,char **argv){
hello_world();
std::cin.get();
return 0;
}运行结果:
hello world
通过上述的代码,我们其实可以将以上这些概括成:头是声明,源是定义,< >查找标准库," "用来寻找定义库。
4.C++中的注释(通常常见的两种注释)
- // :一般通常用于行的注释(函数功能以及变量的含义等等)
- /* */:一般用于块的注释
5.C++中的常用的输入输出(需包含头文件<iostream>)
备注:ostream(输出流),istream(输入流),iostream(输入输出流),sstream(字符串流),ifstream(写入文件流),ofstream(写出文件流),fstream(文件流)
备注:流在中阶篇进行深入探讨
- 输入:std::cin>>...>>...>>...(相当于C语言中scanf函数)
- 输出:std::cout<<...<<...<<...(相当于C语言中的printf函数)
- 换行:std::endl(相当于C语言中的\n)
6.C++的命名空间(using namespace std与自定义命名空间)
- std:C++标准库中的函数以及对象都是在std域中的。(为了防止命名冲突)例如我们自己创建对象时,创建名为cout的对象,若没有std命名空间,那么ostream中的对象cout就会与我们所创建的对象起冲突。
- 为了能够顺利访问域中的东西,需在域名后加上“::”(相当于在某个地方拿东西,需要加上限定符,表示这东西是在这个地方拿的,并不是其他地方或者凭空出现的),例如想要访问std空间里面的东西,需写成:std::。
- 自定义命名空间:当然在C++中我们也可以自定义命名空间,访问属于自己定义域中的内容。
#include <iostream>
namespace cherno{
int age(25);
char name[20]="cherno";
float score=90.0;
}
using namespace cherno;//使用cherno的命名空间
int main(int argc,char **argv){
std::cout<<age<<" "<<name<<" "<<score<<std::endl;
return 0;
}运行结果:
25 cherno 90
上述代码中,我们定义了一个名为cherno的命名空间,并使用了该命名空间里的内容,运行结果如我们所预想的一样,到这里一切都还顺利,不过这样使用命名空间真的会一直顺利下去吗?
#include <iostream>
namespace cherno{
int age(25);
char name[20]="cherno";
float score=90.0;
}
using namespace cherno;
int main(int argc,char **argv){
int age=80;
std::cout<<age<<" "<<name<<" "<<score<<std::endl;
return 0;
}运行结果:
80 cherno 90
当我们定义一个与命名空间冲突的名字时,(与cherno的age同名),C++编译器在这里不认识cherno的age,会调用main函数里的age,(main函数为主入口,编译器都会从该入口进行调用,编译器首先遇见了main中的age,会默认之后的age都是这个)那么有什么办法可以避免这种情况呢?(统一用域)(另一种方法不介绍了)
#include <iostream>
namespace cherno{
int age(25);
char name[20]="cherno";
float score=90.0;
}
using namespace cherno;//可加也可不加
int main(int argc,char **argv){
int age=80;
std::cout<<cherno::age<<" "<<cherno::name<<" "<<cherno::score<<std::endl;
return 0;
}运行结果:
25 cherno 90
这样写代码,可读性较高,而且也避免了命名的冲突,所以大家在写程序时,需要习惯写域。
备注:在命名空间里,也可写函数。
- 嵌套式命名空间
#include <iostream>
namespace cherno{
int age(25);
char name[20]="cherno";
float score=90.0;
namespace lambda{
auto add=[](auto a,auto b){
return a+b;
};
}
}
// using namespace cherno;//可加也可不加
int main(int argc,char **argv){
// int age=80;
// std::cout<<cherno::age<<" "<<cherno::name<<" "<<cherno::score<<std::endl;
int a=10,b=10;
std::cout<<cherno::lambda::add(a,b)<<std::endl;
return 0;
}运行结果:
20
备注:上述代码使用了lambda函数(lambda在高阶进行深入探讨)
嵌套式其实就是域中域,哈哈哈,现在,相信聪明的大家已经能够掌握域与命名空间的知识啦!
7.C++常用的数据类型
备注:括号中表示占用字节数
int:整形(4)short :短整形(2) long:长整型(4)long long:长长整形(8)
float:单精度(4)double:双精度(8)
bool:布尔类型(1)(true为1,flase为0)
char:字符型(1)(以ASCII值存储)
#include <iostream>
#include <sstream>
int main(int argc,char **argv){
std::stringstream stream;
stream<<sizeof(int)<<" "<<sizeof(short)<<" "<<sizeof(long)<<" "<<sizeof(long long)<<std::endl;
stream<<sizeof(float)<<" "<<sizeof(double)<<std::endl;
stream<<true<<" "<<false<<" "<<sizeof(bool)<<std::endl;
char ch=97;//'a'所对应的ASCII值97
//char ch='a';(同上)
stream<<ch<<" "<<sizeof(char)<<std::endl;
std::cout<<stream.str();
return 0;
}运行结果:
4 2 4 8
4 8
1 0 1
a 1
备注:C++中,字符型都可以用ASCII值来表示,上述代码使用了字符串流(sstream),sstream在中阶或者高阶篇进行深入探讨。
8.C++中的字符串型(需包含头文件<string>)
- C字符串通常使用char[maxn],而C++提供了字符串库(string)(提供一些字符串的常用算法,C++字符串也可作为迭代器进行使用)
#include <iostream>
#include <cstring>//c字符串库
#include <string> //c++字符串库
const int maxn=100;//c++风格常量
//#define maxn 100(同上)
int main(int argc,char **argv){
char ch[maxn]="hello world!";//c风格字符串
//c风格字符访问方式
for(int i=0;i<strlen(ch);i++){
std::cout<<ch[i];
}
std::cout<<std::endl;
std::string strs="hello world!";
//c++新访问方式
for(char ch:strs){
std::cout<<ch;
}
std::cout<<std::endl;
// for(int i=0;i<strs.size();i++){
// std::cout<<strs[i];
// }
// std::endl;(同上)
//c++迭代器访问
for(auto iter=strs.begin();iter!=strs.end();iter++){
std::cout<<*iter;
}
std::cout<<std::endl;
//向末尾添加字符串
std::string temp="welcome to c++ world!";
strs.append(temp);
//strs+=temp;(同上)
std::cout<<strs<<std::endl;
// strs.append("welcome to c++ world!");(同上)
// strs.append(temp.begin(),temp.end());(同上)
std::cout<<strs.at(1)<<std::endl;//等价于strs[1],结果是'e'
std::cout<<strs.back()<<std::endl;//等价于strs[strs.size()-1],结果是'!'与之相反的是strs.front()
// std::cout<<strs.c_str();//转化为c风格字符串
// std::cout<<strs.compare("welcome to my world!");//比较字符串是否相等,相等返回1,不等返回0
// std::cout<<strs.data()<<std::endl;//获取字符串
auto iter=strs.erase(strs.begin(),strs.begin()+4);//删除前四个字符
std::cout<<strs<<std::endl;
//从0位置开始查找'o'的位置
if(strs.find('o',0)!=std::string::npos){
std::cout<<strs.find('o',0)<<std::endl;
}
//从1位置开始查找第一个'o'的位置,与之相反的是find_first_not_of
if(strs.find_first_of('o',1)!=std::string::npos){
std::cout<<strs.find_first_of('o',1)<<std::endl;
}
//在1位置插入'~'
strs.insert(strs.begin()+1,'~');
// char ch='~';(同上)
// strs.insert(1,ch);
std::cout<<strs<<std::endl;
return 0;
}
运行结果:
hello world!
hello world!
hello world!
hello world!welcome to c++ world!
e
!
1
o world!welcome to c++ world!
0
3
o~ world!welcome to c++ world!
备注:C++字符串,灵活性以及相关对字符串的算法,大家可以每个都实现以下,加深理解!
9.C++常用运算符(算术运算符,逻辑运算符,三目运算符)
- 算术运算符:>=(大于等于),<=(小于等于),!=(不等于)
- >(大于),<(小于),==(等于)
- +(加),-(减),*(乘),/(除)
- %(余)
- 逻辑运算符:&&(与)---> 两者为真才为真,两者有一假就为假
- ||(或) ---> 两者只要有个真就是真,两者都为假,才是假
- !(非)--->真成假,假成真
- 三目运算符:条件?指令1:指令2 ---> 若条件为真,执行指令1,否则执行指令2
10.C++位运算(常用位运算)
- &(按位与):有0即0,全为1才为1
例如:0001&0001=0001,0010&0110=0010
- |(按位或):有1即1,全为0才为0
例如:0011|0001=0011,1001|0110=1111
- ^(按位异或):相同为0,不同为1
例如:0011^0001=0010,1001^0110=1111
- ~(取反):0转为1,1转为0
例如:~0=1,~1=0
- <<(左移):最高位舍去,最低位补0
例如:0001<<k(表示左移k位),假如k=2,结果是0100
- >>(右移):最地位舍去,最高位补1
例如:1101>>k(表示右移k位),假如k=2,结果是0011
备注:位运算执行快,效率高,位运算某些技巧以及常面题参考以上链接!!!
11.C++函数(为什么要写函数)
- 为什么要写函数?
- 不用函数计算三组两数相乘(代码如下):
#include <iostream>
int main(int argc,char **argv){
unsigned int a=2,b=3;//无符号整形,大于等于0
std::cout<<a*b<<std::endl;
int c=4,d=5;//有符号整形,可以有负数
std::cout<<c*d<<std::endl;
size_t e=6,f=8;//size_t ---> unsigned long long
std::cout<<e*f<<std::endl;
return 0;
}运行结果:
6
2048
试想一下,假如若干的数据让你进行计算,那么如果与上述代码一样将一行一行数据计算,代码是不是非常糟糕呢? 那么我们该怎样做,才能将代码写的既简洁又高效呢?其实这边需要的就是函数了,我们将乘法这个功能,作为函数,进行封装,代码如下:
#include <iostream>
template <typename T>
void mutiply(T &&a,T &&b){
std::cout<<a*b<<std::endl;
}
int main(int argc,char **argv){
mutiply(2,3);
mutiply(4,5);
mutiply(6,8);
return 0;
}运行结果:
6
20
48
备注:利用了C++的函数模版+右值引用(之后高阶再继续深入探讨)
上面的代码,比我们之前的简洁多了,并且可读性高了一点呢!如果还有人有强迫症的话(本人就有很严重的强迫症),其实也可以对mutiply函数继续封装成一个独立的函数。代码如下:
#include <iostream>
template <typename T>
void mutiply(T &&a,T &&b){
std::cout<<a*b<<std::endl;
}
void test(){
mutiply(2,3);
mutiply(4,5);
mutiply(6,8);
}
int main(int argc,char **argv){
test();
return 0;
}运行结果:
6
20
48
总结:写函数,其实就是想我们想做的事情封装,使代码简洁,易读。
备注:函数指针在指针篇进行深入探讨
12.C++判断(if,if-else,switch)
- if:如果条件为真,执行相对应的命令
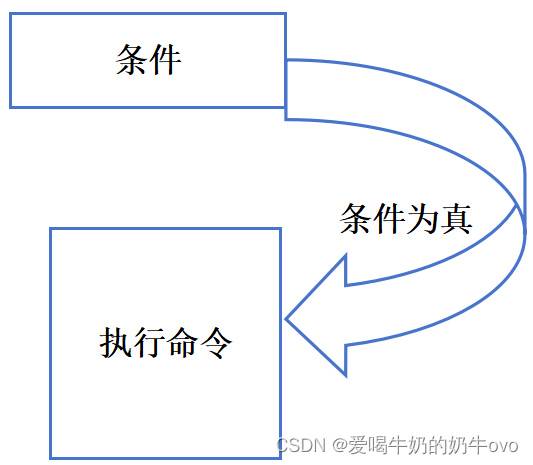
经典题:判断年份是否为闰年?(能被4整除,且不被100整数或者能被400整除的年份),代码如下:
#include <iostream>
//判断是否是闰年
bool is_leap_year(unsigned int &year){
bool res=false;
if((year%4==0&&year%100!=0)||year%400==0)//如果满足闰年条件,更新res值
res=true;
return res;
}
int main(int argc,char **argv){
unsigned int year;//无符号数,大于等于0
std::cin>>year;//从键盘输入年份
std::cout<<is_leap_year(year)<<std::endl;//为闰年输出1,不为闰年输出0
return 0;
}运行结果:(分别输入2023与2024)
0
1
- if-else: 如果条件为真,执行相对应的命令1,否则执行对应的命令2
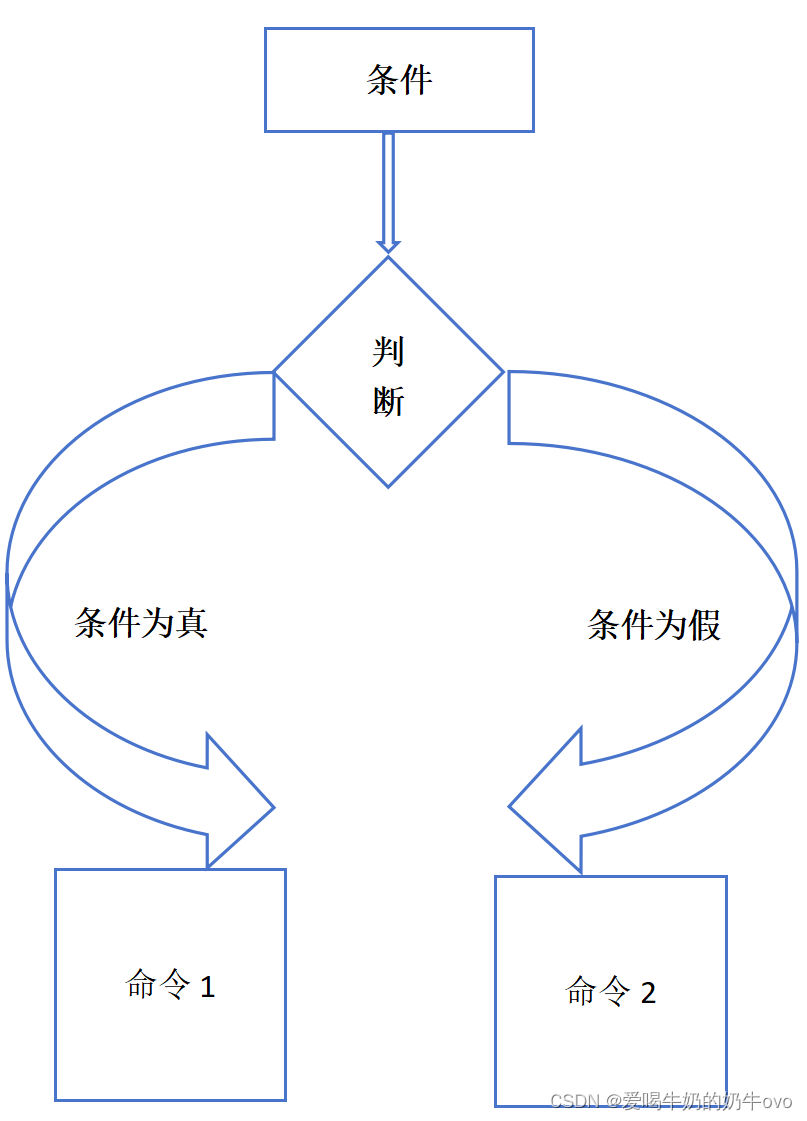
经典题:判断一个数是否是偶数,代码如下:
#include <iostream>
void is_even_number(unsigned int &number){
if(number%2==0){
std::cout<<"the number is even number"<<std::endl;
}else{
std::cout<<"the number is odd number"<<std::endl;
}
}
int main(int argc,char **argv){
unsigned int number;
std::cin>>number;
is_even_number(number);
return 0;
}运行结果:(分别输入4,5)
the number is even number
the number is odd number
- switch:(选择语句)判断条件,如果哪条case符合,执行相对应的命令
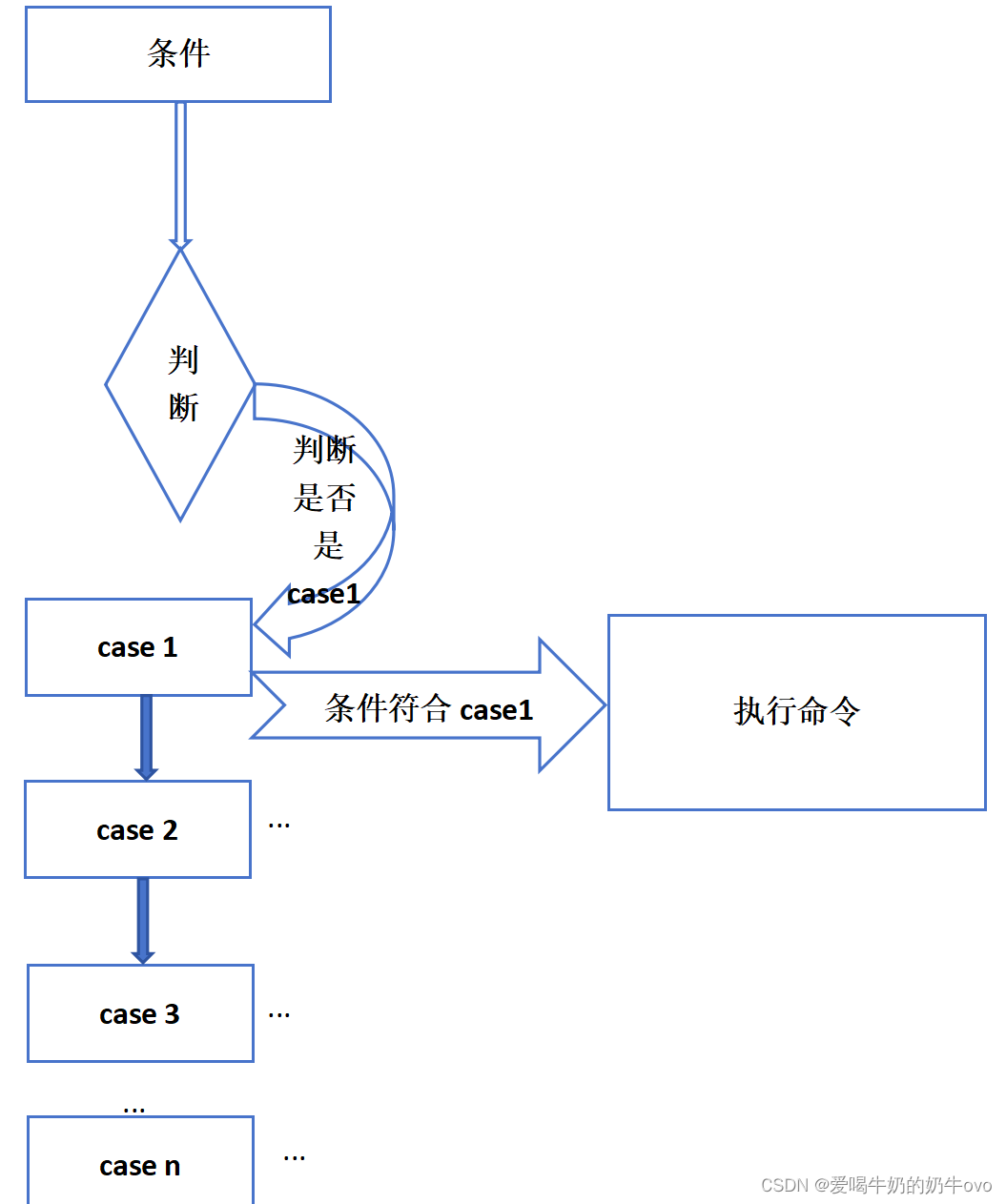
经典题:判断今天星期几?代码如下:
#include <iostream>
void which_day(unsigned int &number){
switch(number){
case 1:
std::cout<<"the day is monday"<<std::endl;
break;
case 2:
std::cout<<"the day is tuesday"<<std::endl;
break;
case 3:
std::cout<<"the day is wednesday"<<std::endl;
break;
case 4:
std::cout<<"the day is thursday"<<std::endl;
break;
case 5:
std::cout<<"the day is friday"<<std::endl;
break;
case 6:
std::cout<<"the day is saturday"<<std::endl;
default:
std::cout<<"the day is sunday"<<std::endl;
break;
}
}
int main(int argc,char **argv){
unsigned int number;
std::cin>>number;
which_day(number);
return 0;
}运行结果:(分别输入2,7)
the day is tuesday
the day is sunday
注意:case下的执行命令后,需要加break,切记别漏
备注:我们需要习惯写函数!!!
13.C++循环(for,while,do_while)
- for循环:(单层循环与多重循环)
单层for循环:
怎样使用for循环呢?或者说为什么要使用for循环呢?
经典题目:判断1~10中哪些是奇数,并分别打印出来
不使用for循环,使用枚举方法进行枚举,代码如下:
#include <iostream>
enum number{
a=1,b,c,d,e,f,g,j,k,l
};
bool is_odd_number(int &&number){
return number%2!=0?true:false;
}
void which_type_number(){
if(is_odd_number(number::a))
std::cout<<number::a<<" ";
if(is_odd_number(number::b))
std::cout<<number::b<<" ";
if(is_odd_number(number::c))
std::cout<<number::c<<" ";
if(is_odd_number(number::d))
std::cout<<number::d<<" ";
if(is_odd_number(number::e))
std::cout<<number::e<<" ";
if(is_odd_number(number::f))
std::cout<<number::f<<" ";
if(is_odd_number(number::g))
std::cout<<number::g<<" ";
if(is_odd_number(number::j))
std::cout<<number::j<<" ";
if(is_odd_number(number::k))
std::cout<<number::k<<" ";
if(is_odd_number(number::l))
std::cout<<number::l<<std::endl;
}
int main(int argc,char **argv){
which_type_number();
return 0;
}运行结果:
1 3 5 7 9
上述代码,通过枚举的方式进行处理1~10的所有奇数。如果说10个数没有压力,那么100个,1000个,10000个呢?oh,my god!怎么那么繁琐呢?那么我们该通过什么进行对代码的优化呢?那么其实这里就需要for循环了,优化后,代码如下:
#include <iostream>
void which_type_number(){
for(unsigned int i=1;i<=10;i++){
if(i%2!=0)
std::cout<<i<<" ";
}
std::cout<<std::endl;
}
int main(int argc,char **argv){
which_type_number();
return 0;
}运行结果:
1 3 5 7 9
通过上述的两个代码,可以发现for循环可以简化代码,并循环重复执行同一个或者多种命令。
双重循环:
经典题:打印m行,n列带“*”矩阵,代码如下:
#include <iostream>
int m,n;//m:表示行 n:表示列
void print_matrix(){
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
std::cout<<"*";//内层循环执行的命令
}
std::cout<<std::endl;//外层循环执行的命令
}
}
int main(){
std::cin>>m>>n;
print_matrix();
return 0;
}运行结果:(输入3,4)
****
****
****
- while:与for有着异曲同工之妙
用while替换上述的经典题(打印奇数),代码如下:
#include <iostream>
void which_type_number(){
int i=1;
while(i<=10){
if(i%2!=0)
std::cout<<i<<" ";
i++;
}
std::cout<<std::endl;
}
int main(int argc,char **argv){
which_type_number();
return 0;
}运行结果:
1 3 5 7 9
备注:使用while,先进行定义变量,再判断。
注意:使用while一定要对变量进行更新,不然会陷入死循环。
- do-while:先执行命令,再进行判断(与while进行区分)
用do-while替换上述的经典题(打印奇数),代码如下:
#include <iostream>
void which_type_number(){
int i=1;
do{
if(i%2!=0)
std::cout<<i<<" ";
i++;
}while(i<=10);
std::cout<<std::endl;
}
int main(int argc,char **argv){
which_type_number();
return 0;
}运行结果:
1 3 5 7 9
注意:使用do-while一定切记while后面必须加;,还需要注意变量的变化。
14.C++主要控制流(continue,break,return)
一般情况下,控制流与循环搭档
- continue:跳过当前语句,继续进入下一次循环
经典题:水仙花数(求100~999的水仙花数)(各个位数的立方和等于自身),代码如下:
#include <iostream>
#include <math.h>
void print_number_of_daffodils(unsigned int start,unsigned int end){
for(unsigned int i=start;i<end;i++){
if(pow(i%10,3)+pow(i/10%10,3)+pow(i/10/10%10,3)!=i) continue;
std::cout<<"i="<<i<<std::endl;
}
}
int main(int argc,char **argv){
print_number_of_daffodils(100,1000);
return 0;
}运行结果:
i=153
i=370
i=371
i=407
上述代码,continue跳过当前语句,进入下一次循环
- break:退出当前循环体(退出最内层循环)
经典题:判断一个数是否是质数?(只能被本身整除的数)代码如下:
#include <iostream>
#include <math.h>
//判断是否是质数
bool is_prime_number(int &number){
bool res=true;
for(int i=2;i<=sqrt(number);i++){
if(number%i==0){
res=false;
break;
}
}
return res;
}
int main(int argc,char **argv){
int number;
std::cin>>number;
std::cout<<is_prime_number(number)<<std::endl;//是质数输出1,不是输出0
return 0;
}运行结果:(分别输入2,4,7,9)
1
0
1
0
上述代码,break退出当前循环
- return:退出循环体(退出最外层循环)
上述代码可用return替换,代码如下:
#include <iostream>
#include <math.h>
//判断是否是质数
bool is_prime_number(int &number){
for(int i=2;i<=sqrt(number);i++){
if(number%i==0) return false;
}
return true;
}
int main(int argc,char **argv){
int number;
std::cin>>number;
std::cout<<is_prime_number(number)<<std::endl;//是质数输出1,不是输出0
return 0;
}运行结果:(输入2,4,7,9)
1
0
1
0
上述代码,return表示退出最外层循环
15.C++数组(普通数组+动态数组(std::vector)+std::array(STL提供的固定数组))
- 普通数组:普通的数组(静态)
一维数组初始化:数据类型+数组名+[数组容量]={数据}或者数据类型+数组名+[ ]={数据}
备注:注意数组容量需选择合适的大小,防止越界
经典题:二分查找(在一维数组中,查找目标值(target),若找到,返回目标值的下标,若不能,返回-1),代码如下:
#include <iostream>
#include <algorithm>
int nums[]={1,5,4,7,0,10,8,11,13};
int length=sizeof(nums)/sizeof(int);//求解数组大小 sizeof(arr)/sizeof(int)
//二分查找
int serch_half_of_target(int start,int end,int &target){
//数组排序(从小到大排序)
//nums[]={0,1,4,5,7,8,10,11,13}
std::sort(nums,nums+length,[](const auto &u,const auto &v){
return u<v;
});
//二分查找模版(也可使用递归)
while(start<=end){
int mid=start+(end-start)/end;
if(nums[mid]<target)
start=mid+1;
else if(nums[mid]>target)
end=mid-1;
else
return mid;
}
return -1;
}
//递归版本
// int serch_half_of_target(int start,int end,int &target){
// //数组排序(从小到大排序)
// //nums[]={0,1,4,5,7,8,10,11,13}
// std::sort(nums,nums+length,[](const auto &u,const auto &v){
// return u<v;
// });
// //递归版本
// if(start>end)
// return -1;
// int mid=start+(end-start)/end;
// if(nums[mid]==target)
// return mid;
// else if(nums[mid]<target)
// return serch_half_of_target(mid+1,end,target);
// else
// return serch_half_of_target(start,mid-1,target);
// }
int main(int argc,char **argv){
int target=5;
std::cout<<serch_half_of_target(0,length-1,target)<<std::endl;
return 0;
}运行结果:
3
备注:数组指针与指针数组在指针篇进行深入探讨
使用sort函数进行排序,需包含<algorithm>头文件(algorithm(c++编译器提供的算法库))
数组基本操作
访问一维数组:数组名+[下标](下标默认是从0开始),表示数组第(下标+1)个元素值
数组长度:利用sizeof,进行求解(sizeof(数组名)/sizeof(数据类型))
注意:二分查找模版较多,针对不同问题,需选择不同的版子,二分查找一般适用于数组元素基本有序的情况
备注:二分查找与递归在数据结构与算法篇进行深入探讨
二维数组初始化:数据类型+数组名[行的容量][列的容量]={{数据},{数据}...}
经典题:旋转数组,代码如下:
#include <iostream>
const int len=3;
//#define len 3 (同上)
void rotate(int nums[len][len]){
for(int i=0;i<len/2;i++){
for(int j=0;j<len;j++){
auto temp=nums[i][j];
nums[i][j]=nums[len-i-1][j];
nums[len-i-1][j]=temp;
}
}
for(int i=0;i<len;i++){
for(int j=0;j<i;j++){
auto temp=nums[i][j];
nums[i][j]=nums[j][i];
nums[j][i]=temp;
}
}
}
void show(int nums[len][len]){
for(int i=0;i<len;i++){
for(int j=0;j<len;j++){
std::cout<<nums[i][j]<<" ";
}
std::cout<<std::endl;
}
}
int main(int argc,char **argv){
int nums[len][len]={{1,2,3},{4,5,6},{7,8,9}};
show(nums);//原先的矩阵
std::cout<<std::endl;
rotate(nums);
show(nums);//旋转后的矩阵
return 0;
}运行结果:
1 2 3
4 5 6
7 8 9
7 4 1
8 5 2
9 6 3
二维数组常用操作
访问数组:数组名+[行标][列标],表示第(行标+1)行,第(列标+1)列的元素值
强调:数组下标是从0开始的
二维数组列数:使用sizeof(sizeof(arr[0])/sizeof(数组类型))
二维数组行数:使用sizeof(sizeof(arr)/sizeof(二维数组列数*sizeof(数据类型)))
备注:数组都是采用顺序存储的
一维数组存储:

二维数组存储:

- vector容器:标准模版库(STL)中的数组容器(动态),可作为迭代器使用(必须加<vector>头文件)
创建vector对象,代码如下:(vector提供了模版,vector<typename T>与vector<bool>)
#include <iostream>
#include <vector>
#include <string>
class student;
int main(int argc,char **argv){
std::vector<int>vec1;
std::vector<float>vec2;
std::vector<std::string>vec3;
std::vector<student*>vec4;
...
return 0;
}备注:vector基本上可以放常用的任何数据类型(包括类,指针等)
初始化一维vector对象:
- 直接初始化,代码如下:
#include <iostream>
#include <vector>
#include <ostream>
const int len=5;
std::ostream &operator<<(std::ostream &stream,std::vector<int>&ret){
for(auto &elem:ret){
stream<<elem<<" ";
}
return stream;
}
int main(int argc,char **argv){
//直接初始化
std::vector<int>vec{1,2,3,4,5};
// std::vector<int>vec={1,2,3,4,5};
//利用第三方进行初始化
std::vector<int>ret(vec);
// std::vector<int>ret=vec;//vector类提供赋值重载函数operator=(同上)
//利用指针初始化
// std::vector<int>ret(vec.begin(),vec.end());//(同上)
//利用resize函数+遍历,进行初始化
// std::vector<int>ret;
// ret.resize(vec.size());
// //普通遍历
// for(int i=0;i<vec.size();i++){
// ret[i]=vec[i];
// }
//利用assign函数进行初始化
// std::vector<int>ret;
// ret.assign(vec.begin(),vec.end());
// int nums[len]={1,2,3,4,5};//普通数组(基本同上)
//利用push_back进行初始化
//push_back:向末尾添加元素(同ret={1,2,3,4,5})
// std::vector<int>ret;
// ret.push_back(1);
// ret.push_back(2);
// ret.push_back(3);
// ret.push_back(4);
// ret.push_back(5);
//备注:与resize搭配利用遍历进行push_back更快
std::cout<<ret<<std::endl;
return 0;
}运行结果:
1 2 3 4 5
备注:operator运算符重载在中阶篇进行深入探讨
- vector常用功能(增删改查),代码如下:
#include <iostream>
#include <vector>
#include <algorithm>
void show(std::vector<int>&ret){
//获取数组的大小:size()与capacity()
//普通遍历
// for(int i=0;i<ret.size();i++){
// std::cout<<ret[i]<<" ";
// }
//迭代器遍历
for(auto iter=ret.begin();iter!=ret.end();iter++){
std::cout<<*iter<<" ";
}
//另一种迭代器遍历
// for(int &elem:ret){
// std::cout<<elem<<" ";
// }
std::cout<<std::endl;
}
int main(int argc,char **argv){
std::vector<int>ret{1,2,3,4,5};
show(ret);//第一次打印{1,2,3,4,5}
//添加元素
//末尾添加元素使用push_back()
ret.push_back(6);//向vector末尾添加元素6
show(ret);//第二次打印{1,2,3,4,5,6}
//指定位置插入元素使用insert
std::vector<int>::iterator iter=ret.begin();//插入的首位置(第一个元素)
ret.insert(iter,7);//在第一个插入7 {7,1,2,3,4,5,6}
ret.insert(iter+2,3,0);//在第三个位置插入3个0 {7,1,0,0,0,2,3,4,5,6}
std::vector<int>new_ret{9,10,11,12,13,14};
ret.insert(iter+3,new_ret.begin(),new_ret.end());//在第4个位置插入new_ret数组的所有元素 {7,1,0,9,10,11,12,13,14,0,0,2,3,4,5,6}
show(ret);//第三次打印
//删除元素
//末尾删除元素
ret.pop_back();//删除ret数组最后一个元素 {7,1,0,9,10,11,12,13,14,0,0,2,3,4,5}
show(ret);//第四次打印
//删除指定位置的元素
ret.erase(ret.begin());//删除第一个元素 {1,0,9,10,11,12,13,14,0,0,2,3,4,5}
ret.erase(ret.begin()+2);//删除第三个元素 {1,0,10,11,12,13,14,0,0,2,3,4,5}
ret.erase(ret.begin()+1,ret.begin()+4);//删除第2个~第4个元素 {1,12,13,14,0,0,2,3,4,5}
//删除指定元素
// ret.erase(std::remove(ret.begin(),ret.end(),5),ret.end());//删除指定为5的元素
//通过迭代器删除指定元素
// for(auto iter=ret.begin();iter!=ret.end();){
// if(*iter==5)
// ret.erase(iter);
// iter++;
// }
show(ret);//第五次打印
//修改元素值
ret[2]=100;//第三个值改为100
show(ret);//第六次打印 {1,12,100,14,0,0,2,3,4,5}
//查找某个元素
//如果查找到元素返回下标
if(std::find(ret.begin(),ret.end(),100)!=ret.end()){
std::cout<<std::distance(ret.begin(),std::find(ret.begin(),ret.end(),100))<<std::endl; // 2
}
//遍历方法进行查找
//普通遍历
// for(int i=0;i<ret.size();i++){
// if(ret[i]==100)
// std::cout<<i<<std::endl;
// }
//迭代器遍历(指针)
// for(auto iter=ret.begin();iter!=ret.end();iter++){
// if(*iter==100)
// std::cout<<iter-ret.begin()<<std::endl;
// }
return 0;
}运行结果:
1 2 3 4 5
1 2 3 4 5 6
7 1 0 9 10 11 12 13 14 0 0 2 3 4 5 6
7 1 0 9 10 11 12 13 14 0 0 2 3 4 5
1 12 13 14 0 0 2 3 4 5
1 12 100 14 0 0 2 3 4 5
2
备注:auto:自动推导类型,在中阶篇进行深入探讨
二维数组:基本同一维(略)
补充(<size_t Count,const std::allocator<int>&Val>)+resize用法:
#include <iostream>
#include <vector>
const int n=10;
std::ostream &operator<<(std::ostream &stream,std::vector<int>&ret){
for(auto elem:ret){
stream<<elem<<" ";
}
stream<<std::endl;
return stream;
}
int main(){
std::vector<int>ret(n,8);//定义10个8
std::cout<<ret;//第一次打印 {8,8,8,8,8,8,8,8}
ret.resize(3);//设置数组大小为3
std::cout<<ret;//第二次打印 {8,8,8}
ret.resize(7);//扩充数组大小为7
std::cout<<ret;//第三次打印 {8,8,8,0,0,0,0}
}运行结果:
8 8 8 8 8 8 8 8 8 8
8 8 8
8 8 8 0 0 0 0
备注:STL提供的vector容器用法很多,需要大家多多练习,孰能生巧!!!
- std::array:STL提供的固定数组(必须加<array>头文件)
固定数组(std::array)模版:std::array<typename T,size_t Size>
自己的(std::array)Demo,代码如下:
#include <array>
#include <iostream>
#include <sstream>
std::array<int,5>array_a={1,3,5};//创建名为array_a的数组,数据为{1,3,5,0,0}
void show(){
//普通数组访问方式
// for(int i=0;i<array_a.size();i++){
// std::cout<<array_a[i]<<" ";
// }
//C++数组访问方式
// for(auto &elem:array_a)
// std::cout<<elem<<" ";
//迭代器访问数组
for(auto iter=array_a.begin();iter!=array_a.end();iter++){
std::cout<<*iter<<" ";
}
std::cout<<std::endl;
}
int main(int argc,char **argv){
std::stringstream stream;
/*
array_a.front():访问数组第一个元素
array_a.back():访问数组最后一个元素
array_a.at(2):访问数组第3个元素
array_a.data():返回数组的地址
array_a.size():数组的长度
array_a.empty():数组是否为空
*/
show();//第一次显示
stream<<array_a.front()<<" "<<array_a.back()<<" "<<array_a.at(2)<<" "<<array_a.data()
<<" "<<array_a.size()<<" "<<array_a.empty()<<std::endl;
std::cout<<stream.str();
//将数组所有的数据填充为4
array_a.fill(4);
show();//第二次显示
return 0;
}运行结果:
1 3 5 0 0
1 0 5 0x7ff63c703000 5 0
4 4 4 4 4
备注:STL提供的std::array(固定数组),需要多多练习,熟能生巧!!!
16.C++枚举(enum)
- enum:一些值的集合,如果想要给枚举更实用的定义,那就是给这些值指定一个名称
经典题:写日志(不同等级会发出不同的日志信息),代码如下:
#include <iostream>
enum level:int{
levelError=0,levelWarning,levelInfo
};
int WriteLog(int &&level,const char *message){
if(level>=levelInfo){
std::cout<<"[INFO]"<<message<<std::endl;
return 0;
}
if(level>=levelWarning){
std::cout<<"[WARNING]"<<message<<std::endl;
return 0;
}
if(level>=levelError){
std::cout<<"[ERROR]"<<message<<std::endl;
return 0;
}
return 0;
}
void test(){
WriteLog(0,"Welcome to C++ World");
WriteLog(1,"Welcome to C++ World");
WriteLog(2,"Welcome to C++ World");
}
int main(int argc,char **argv){
test();
return 0;
}运行结果:
[ERROR]Welcome to C++ World
[WARNING]Welcome to C++ World
[INFO]Welcome to C++ World
备注:默认情况下,enum里的值都是从0开始的,依次往后加1,当然程序员可以自己定义enum里面元素值是多少
- 构造方法:enum+名称{元素};或者enum+名称+:+数据类型{元素};
- 使用方法:名称+::+元素名(使用域进行访问)
备注:使用时,使用域名访问是最好的,如果不使用域名,需要看enum在不在作用域里面
总结:使用enum(枚举体),主要为了保证代码的可读性
17.C++结构体与联合体(struct与union)
- struct(结构体):是一种数据结构,结构体可以声明成变量,指针以及数组,用来实现更为复杂的数据结构,当然结构体还包括成员变量以及成员函数等等。(其实就是将一套数据封装成一个结构体)
经典结构体:完成对某人的信息进行封装(包括姓名,年龄,电话以及地址等等),代码如下:
#include <iostream>
#include <string>
const int maxn=50;
struct person{
unsigned int age;
char name[maxn];
char tel_phone[maxn];
std::string address;
void eat(const char*message){
std::cout<<name<<" love eat "<<message<<std::endl;
}
void drink(const char *message){
std::cout<<name<<" love drink "<<message<<std::endl;
}
}cherno;
std::ostream &operator<<(std::ostream &stream,person &cherno){
stream<<cherno.age<<" "<<cherno.name<<" "<<cherno.tel_phone<<" "<<cherno.address<<std::endl;
return stream;
}
int main(int argc,char **argv){
cherno={20,"cherno","88888888","New York"};
std::cout<<cherno;
cherno.eat("apple");
cherno.drink("coco");
return 0;
}运行结果:
20 cherno 88888888 New York
cherno love eat apple
cherno love drink coco
补充:
结构体声明,参考代码如下:
#include <iostream>
const int maxn=50;
/*
声明方法
struct+结构体名+{成员};
*/
/*声明一个名为student的结构体
成员分别是:age:年龄
name:姓名
stu_id:学号
score:总分
*/
struct student{
unsigned int age;//年龄
char name[maxn];//姓名
unsigned int stu_id; //学号
float score;//总分
};
/*可在构体后加上结构体定义,如下所示
student_1:学生1
student_2:学生2
备注:并未对学生1与学生2进行初始化
*/
// struct student{
// unsigned int age;//年龄
// char name[maxn];//姓名
// unsigned int stu_id; //学号
// float score;//总分
// }student_1,student_2;
/*
对上述的学生1与学生2初始化
学生1信息初始化为:年龄18,姓名cherno,学号1,总分100
学生2信息初始化为:年龄19,姓名thread,学号2,总分99
*/
// struct student{
// unsigned int age;//年龄
// char name[maxn];//姓名
// unsigned int stu_id; //学号
// float score;//总分
// }student_1{18,"cherno",1,100.0},student_2{19,"thread",2,99.0};
int main(int argc,char **argv){
return 0;
}备注:上述代码将一部分结构体定义给出,需要大家手动练习练习,熟能生巧!!!
结构体定义(上述代码补充),参考代码如下:
#include <iostream>
const int maxn=50;
/*
声明方法
struct+结构体名+{成员};
*/
/*声明一个名为student的结构体
成员分别是:age:年龄
name:姓名
stu_id:学号
score:总分
*/
struct student{
unsigned int age;//年龄
char name[maxn];//姓名
unsigned int stu_id; //学号
float score;//总分
};
int main(int argc,char **argv){
/*
普通定义
student_1:学生1
student_2:学生2
*/
student student_1={18,"cherno",1,100.0};
student student_2={19,"thread",2,99.0};
/*
指针定义
*student_1:学生1
*student_2:学生2
*/
// student *student_1=&student_1;
// student *student_2=&student_2;
/*
数组定义
students[];
*/
// student students[10];
// students[1]={18,"cherno",1,100.0};
// students[2]={19,"thread",2,99.0};
return 0;
}纠正:上述代码定义结构体数组时,下标错误,正确代码请看下文代码
结构体访问(上述代码补充),代码如下:
#include <iostream>
#include <sstream>
const int maxn=50;
/*
声明方法
struct+结构体名+{成员};
*/
/*声明一个名为student的结构体
成员分别是:age:年龄
name:姓名
stu_id:学号
score:总分
*/
struct student{
unsigned int age;//年龄
char name[maxn];//姓名
unsigned int stu_id; //学号
float score;//总分
};
int main(int argc,char **argv){
/*
普通定义
student_1:学生1
student_2:学生2
*/
student student_1={18,"cherno",1,100.0};
student student_2={19,"thread",2,99.0};
//普通访问
std::stringstream stream;
stream<<student_1.age<<" "<<student_1.name<<" "<<student_1.stu_id<<" "<<student_1.score<<std::endl;
stream<<student_2.age<<" "<<student_2.name<<" "<<student_2.stu_id<<" "<<student_2.score<<std::endl;
std::cout<<stream.str();
/*
指针定义
*student_1:学生1
*student_2:学生2
*/
// student *student_1=&student_1;
// student *student_2=&student_2;
//指针访问
// std::stringstream stream;
// stream<<student_1->age<<" "<<student_1->name<<" "<<student_1->stu_id<<" "<<student_1->score<<std::endl;
/*
数组定义
students[];
*/
//数组访问
// student students[10];
// students[0]={18,"cherno",1,100.0};
// students[1]={19,"thread",2,99.0};
// std::stringstream stream;
// stream<<students[0].age<<" "<<students[0].name<<" "<<students[0].stu_id<<" "<<students[0].score<<std::endl;
return 0;
}运行结果:
18 cherno 1 100
19 thread 2 99
备注:结构体需要大家多多练习,孰能生巧!!!
struct结构体内存(遵循内存对齐原则):
- 内存占用:每个成员变量都有自己的一片内存,并且互不干涉,遵循内存对齐原则,结构体占用内存长度是所有的成员变量长度之和。
注意:struct结构体占用内存仅仅是成员变量所占用的内存,而成员函数并不占用内存。
- 遵循内存对齐原则:内存对齐原则详解
备注:内存对齐原则需要大家进行理解!!!
- union(联合体):
- 内存占用:共用同一片内存,并且只有一个成员变量能得到这块内存的使用权,联合体总长度至少满足最大成员变量占用内存大小,并且联合体占用内存长度还需要满足是所有成员变量长度的整数倍。
union(联合体):联合体详解
18.C++指针(普通指针+数组指针+指针数组+函数指针+多级指针)
- 指针与引用的区别(大厂面试高频题):
1.指针与引用都是地址的概念,指针是指向某一块内存,它的内容存储的是指向内存的地址,引用是某块内存的别名。程序为指针分配内存,而不为引用分配。
2.指针使用前需要加*号,而引用需要加&号
3.引用在定义时被初始化,之后不能被修改,不过指针能够被修改。即引用的对象不能改,指针指向的对象是可以修改的。
4.指针被使用前需要判断是否为空,而引用不需要。
5.引用只有一级,而指针是有多级指针的
6.运算符++与--有区别,指针是指向下一个或者上一个对象,而引用就是对象本身内容进行运算。
- 普通指针:指向某一块内存,它的内容存储的是指向内存的地址。
普通指针常用操作,参考代码如下:
#include <iostream>
int main(int argc,char **argv){
int aa=8;
int *ptr=&aa;
std::cout<<"ptr="<<ptr<<std::endl;
//取地址加&号
std::cout<<"aa's address="<<&aa<<std::endl;
//取地址里面的内容需要解指针,加*号
std::cout<<"ptr's content="<<*ptr<<std::endl;
/*
引用其实就是给变量起个另外的名字,你还是你自己
*/
int &bb=aa;
std::cout<<"bb's address"<<&bb<<std::endl;
std::cout<<"aa's address="<<&aa<<std::endl;
std::cout<<"bb's content="<<bb<<std::endl;
return 0;
}运行结果:
ptr=0x5ec79ff81c
aa's address=0x5ec79ff81c
ptr's content=8
bb's address0x5ec79ff81c
aa's address=0x5ec79ff81c
bb's content=8
备注:引用可以代替指针进行使用
经典题:两数交换
错误做法,参考代码如下:
#include <iostream>
void swap(int a,int b){
int temp=a;
a=b;
b=temp;
}
int main(int argc,char **argv){
int a=2,b=3;
swap(a,b);
std::cout<<"a="<<a<<" "<<"b="<<b<<std::endl;
return 0;
}运行结果:
a=2 b=3
修改代码,查看a,b地址,代码如下:
#include <iostream>
void swap(int a,int b){
std::cout<<&a<<std::endl;
std::cout<<&b<<std::endl;
int temp=a;
a=b;
b=temp;
std::cout<<&a<<std::endl;
std::cout<<&b<<std::endl;
}
int main(int argc,char **argv){
int a=2,b=3;
swap(a,b);
std::cout<<"a="<<a<<" "<<"b="<<b<<std::endl;
return 0;
}运行结果:
0x1229bff8a0
0x1229bff8a8
0x1229bff8a0
0x1229bff8a8
a=2 b=3
备注:传统的值传递并没有达到,实参交换的效果
怎样解决这种麻烦呢,这边就提供了两种方式:指针传递以及引用传递
指针传递,参考代码如下:
#include <iostream>
void swap(int *a,int *b){
std::cout<<a<<std::endl;
std::cout<<b<<std::endl;
int *temp=a;
a=b;
b=temp;
std::cout<<a<<std::endl;
std::cout<<b<<std::endl;
}
int main(int argc,char **argv){
int a=2,b=3;
swap(&a,&b);
std::cout<<"a="<<a<<" "<<"b="<<b<<std::endl;
return 0;
}运行结果:
0x40e35ffdac
0x40e35ffda8
0x40e35ffda8
0x40e35ffdac
a=2 b=3
备注:指针传递,达到了实参交换的效果
引用传递,参考代码如下:
#include <iostream>
void swap(int &a,int &b){
int temp=a;
a=b;
b=temp;
}
int main(int argc,char **argv){
int a=2,b=3;
swap(a,b);
std::cout<<"a="<<a<<" "<<"b="<<b<<std::endl;
return 0;
}运行结果:
a=3 b=2
备注:引用传递也完美完成了实参交换
注意:形参是函数体用来接收传递值的,而实参用于真正传递给函数的值
总结:作者通过<time>,已验证指针传递与引用传递同样快,大家需要习惯使用引用!!!
- 数组指针:
数组指针一般形式:数据类型+(*指针名)[常量表达式]
一维数组指针,参考代码如下:
#include <iostream>
const unsigned int len=5;
int main(int argc,char **argv){
int aa[len]={20,12,1,3,22};
int (*ptr)[len];
ptr=&aa;
//遍历,打印数组
for(unsigned int i=0;i<len;i++){
std::cout<<(*ptr)[i]<<" ";
}
std::cout<<std::endl;
return 0;
}运行结果:
20 12 1 3 22
备注:数组指针是指针指向数组
具体一维数组指针结构图:

二维数组指针,参考代码如下:
#include <iostream>
const unsigned int row=3;
const unsigned int cow=4;
int main(int argc,char **argv){
int aa[row][cow]={{1,2,3,4},{5,6,7,8},{9,10,11,12}};
int (*ptr)[cow];
ptr=aa;
for(unsigned int i=0;i<row;i++){
for(unsigned int j=0;j<cow;j++){
std::cout<<*(*(ptr+i)+j)<<" ";
}
std::cout<<std::endl;
}
return 0;
}运行结果:
1 2 3 4
5 6 7 8
9 10 11 12
具体二维数组指针结构图:
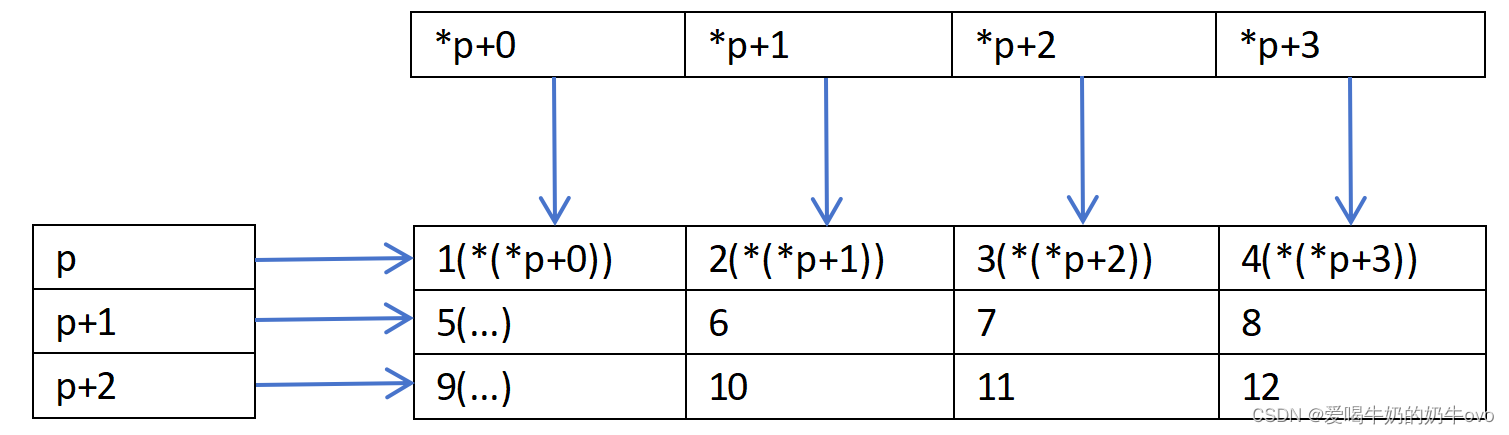
备注:p++是指向的是数组第二行的首地址
- 指针数组:
指针数组一般形式:数据类型+*+指针名[常量表达式]或者数据类型+*+数组名+[ ]
存储形式:以指针形式存储(<typename T>)(T *[ ])

备注:T类型数组存储是指针(模版在高阶篇进行深入探讨)
一维指针数组,参考代码如下:
#include <iostream>
#include <algorithm>
template <typename T>
void one_dimensional_ptr_array(T res,int &&length){
/*
一维指针数组常用操作:
遍历
指针数组运算
*/
T ptr=res;
for(int i=0;i<length;i++){
std::cout<<*(ptr+i)<<" ";
}
std::cout<<std::endl;
//(++,--) 备注:--与++一致
(*ptr)++;
for(int i=0;i<length;i++){
std::cout<<*(ptr+i)<<" ";
}
std::cout<<std::endl;
//遍历
while(length){
std::cout<<*(ptr++)<<" ";
length--;
}
std::cout<<std::endl;
/*
常用算法
排序,旋转
*/
//排序(从小到大)
std::sort(res,res+length,[](const auto &u,const auto &v){
return u<v;});
// std::sort(res,res+length,[](const auto &u,const auto &v){
// return u>v;});//从大到小排序
std::reverse(res,res+length);//旋转
}
int main(int argc,char **argv){
int res[]={2,12,1,9,20};
one_dimensional_ptr_array(res,sizeof(res)/sizeof(int));
char *strs[]={"chinese","cherno","20","love c++"};
for(int i=0;i<sizeof(strs)/sizeof(strs[0]);i++){
std::cout<<*(strs+i)<<" ";
}
return 0;
}
运行结果:
2 12 1 9 20
3 12 1 9 20
3 12 1 9 20
chinese cherno 20 love c++
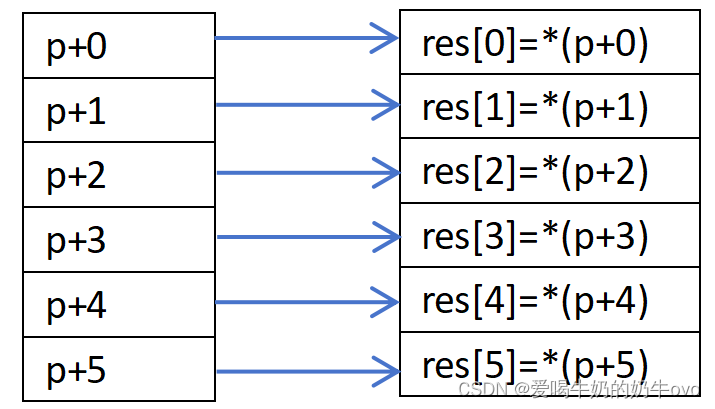
备注:指针数组名就是指针,代表着数组的首地址
具体一维指针数组结构图:(res是一维数组)
二维指针数组,参考代码如下:
#include <iostream>
const unsigned int row=3;
const unsigned int cow=4;
int main(int argc,char **argv){
int aa[row][cow]={{1,2,3,4},{5,6,7,8},{9,10,11,12}};
int *ptr[3];
for(unsigned int i=0;i<row;i++){
ptr[i]=aa[i];
}
//遍历,打印二维数组
for(unsigned int i=0;i<row;i++){
for(unsigned int j=0;j<cow;j++){
std::cout<<*(ptr[i]+j)<<" ";
/*
std::cout<<ptr[i][j]<<" ";
std::cout<<*(*(ptr+i)+j)<<" ";
std::cout<<(*(ptr+i))[j]<<" ";(同上)
*/
}
std::cout<<std::endl;
}
return 0;
}运行结果:
1 2 3 4
5 6 7 8
9 10 11 12
具体二维指针数组结构图:
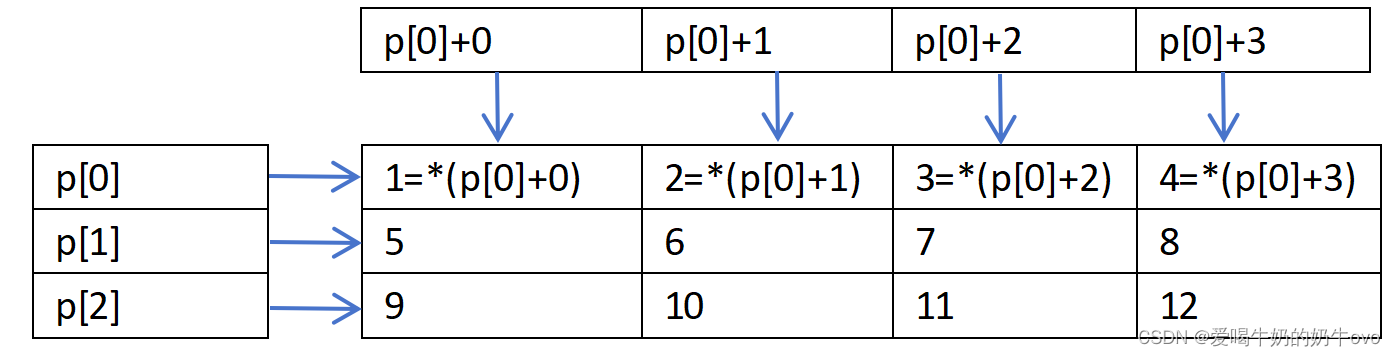
备注:指针数组就是存储指针的数组(指针存储存储对象的地址)
- 函数指针:
一般形式:数据类型+(*指针名(函数名))+(数据类型+数据名,数据类型+数据名,......)
数据类型+(*指针名(函数名))+(数据类型,数据类型,......)
备注:省略*也行
参考代码如下:
#include <iostream>
float add(float x,float y){
return x+y;
}
float mutiply(int &value,float &x,float &y, float (*ptr)(float ,float)){
return value*ptr(x,y);
}
int main(int argc,char **argv){
int value=10;
float x=1.1,y=2.2;
// auto function=[](float x,float y)->float{
// return x+y;(同下)
// };
// float res=mutiply(value,x,y,[](float x,float y)->float{
// return x+y;
// });(同下)
float res=mutiply(value,x,y,add);
std::cout<<res<<std::endl;
return 0;
}运行结果:
33
备注:函数指针实质是指向函数的指针,搭配lambda逼格会提升一个档次哦!!!
具体函数指针结构图:
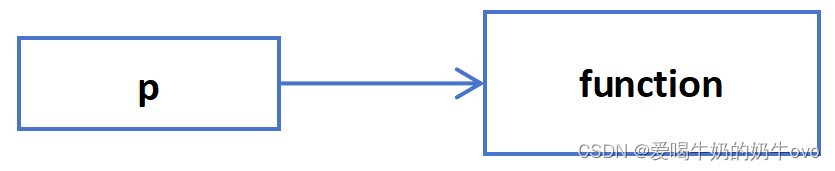
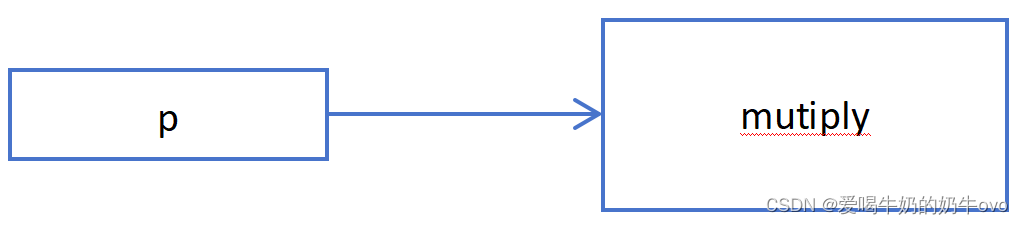
- 指针函数:
一般形式:数据类型+*+指针名(函数名)+(数据类型+数据名,数据类型+数据名,......)
数据类型+*+指针名(函数名)+(数据类型,数据类型,......)
备注:一般通过函数返回指针
参考代码如下:
#include <iostream>
float (*mutiply(const char *ch,float(*p)(float,float)))(float x,float y){
if(ch=="mutiply")
return p;
return nullptr;
}
int main(int argc,char **argv){
auto func=mutiply("mutiply",[](float x,float y)->float{
return x*y;
});
std::cout<<func(1.1,10.0)<<std::endl;
return 0;
}运行结果:
11
指针函数具体结构图:
备注:指针函数实质就是返回指向函数的指针
- 多级指针:
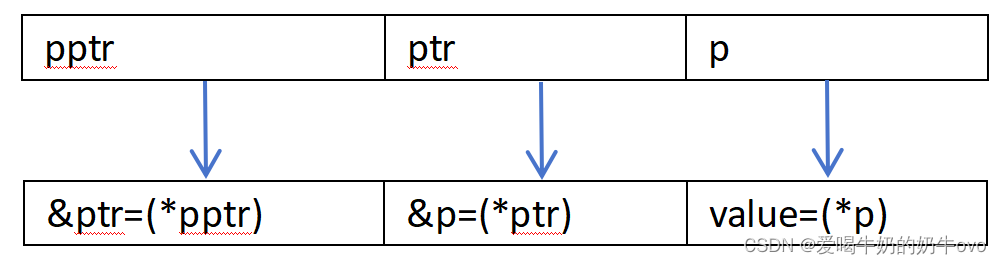
二级指针:指向指针的指针,存储的是指针的地址
一般形式:加两个*号
参考代码如下:
#include <iostream>
#include <sstream>
int main(int argc,char **argv){
unsigned int value=8;
unsigned int *p=&value;
unsigned int **ptr=&p;
unsigned int ***pptr=&ptr;
std::stringstream stream;
stream<<"value's address:"<<&value<<" "<<"value's value:"<<value<<std::endl;
stream<<"p="<<p<<" "<<"p's address:"<<&p<<" "<<"p's content:"<<*p<<std::endl;
stream<<"ptr="<<ptr<<" "<<"ptr's address:"<<&ptr<<" "<<"ptr's content:"<<*ptr<<std::endl;
stream<<"pptr="<<pptr<<" "<<"pptr's address:"<<&pptr<<" "<<"pptr's content:"<<*pptr<<std::endl;
std::cout<<stream.str();
return 0;
}运行结果:
value's address:0x9e085ff86c value's value:8
p=0x9e085ff86c p's address:0x9e085ff860 p's content:8
ptr=0x9e085ff860 ptr's address:0x9e085ff858 ptr's content:0x9e085ff86c
pptr=0x9e085ff858 pptr's address:0x9e085ff850 pptr's content:0x9e085ff860
备注:通过上述代码,得出结论,二级指针存储的是一级指针的地址,指向一级指针,三级指针存储的是二级指针的地址,指向二级指针,依次类推。
多级指针具体结构图:
补充:指针作为形参应用(一级指针与二级指针)+(指针引用混用)
一级指针应用:
经典题:比较三数大小,输出最大的数,代码如下:
#include <iostream>
void cout_max_value(float *x,float *y,float *z){
float *max_ptr=x;
if(*max_ptr<*y)
max_ptr=y;
if(*max_ptr<*z)
max_ptr=z;
std::cout<<*max_ptr<<std::endl;
}
int main(int argc,char **argv){
float x=10,y=4,z=18;
cout_max_value(&x,&y,&z);
return 0;
}运行结果:
18
备注:一级指针作为形参,将实参地址传入即可
二级指针应用:
经典题:比较两个字符串是否相等,若为真返回1,否则返回0,代码如下:
#include <iostream>
const int len=12;
bool compare_strs(char **s1,char **s2){
for(unsigned int i=0;i<len;i++){
if(*(*s1+i)==*(*s2+i)) continue;
return false;
}
return true;
}
int main(int argc,char **argv){
char s1[len]="hello world";
char s2[len]="hello werld";
char ss1[len]="hello world";
char *p1=s1;
char *p2=s2;
char *p3=ss1;
std::cout<<compare_strs(&p1,&p2)<<std::endl;
std::cout<<compare_strs(&p1,&p3)<<std::endl;
return 0;
}运行结果:
0
1
备注:二级指针作为形参,将指向实参的指针地址传入即可
引用与指针混用作为形参:
一般形式:数据类型+*+&+指针名(形参名)
上述代码修改为,如下:
#include <iostream>
const int len=12;
bool compare_strs(char *&s1,char *&s2){
for(unsigned int i=0;i<len;i++){
if(*(s1+i)==*(s2+i)) continue;
return false;
}
return true;
}
int main(int argc,char **argv){
char s1[len]="hello world";
char s2[len]="hello werld";
char ss1[len]="hello world";
char *p1=s1;
char *p2=s2;
char *p3=ss1;
std::cout<<compare_strs(p1,p2)<<std::endl;
std::cout<<compare_strs(p1,p3)<<std::endl;
return 0;
}运行结果:
0
1
备注:指针与引用混合作为形参,将指向实参的指针传入即可
本质:给指针起别名,传入实参是指针
19.C++内存管理(大厂必问面试题,重要!重要!重要!)
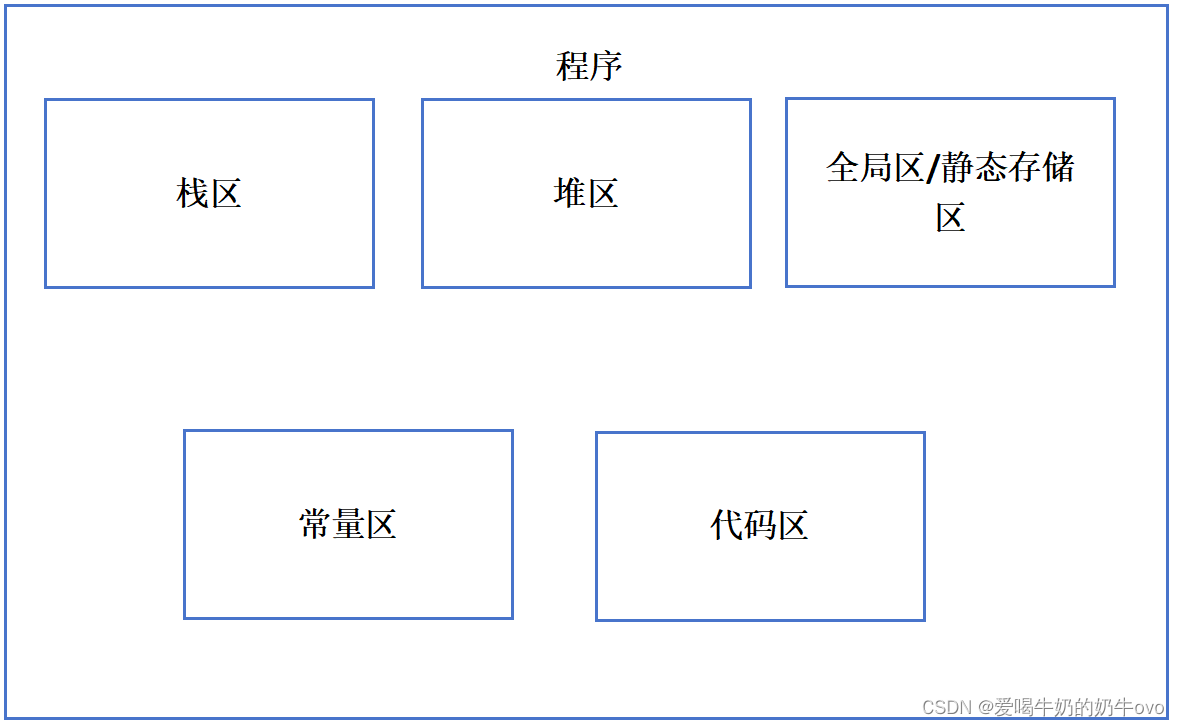
- 栈区:栈中主要存放函数的局部变量,函数参数,返回地址等等,栈空间一般由操作系统进行默认分配或者程序指定分配,栈空间在进程声明周期一直都存在,当进程退出时,操作系统才会对栈空间进行回收。(栈空间一般由操作系统分配回收)
- 堆区:动态申请的内存空间,就是由malloc函数(c语言)或者new函数(c++语言)分配的内存块,由程序控制它的分配和释放,可以在程序运行周期内随时进行申请和释放,如果进程结束还没有释放,操作系统将回自动回收。(堆空间由我们程序员自己手动分配回收)
备注:malloc函数申请堆空间,与之对应free函数释放空间(C特有的);new函数申请堆空间,与之对应的delete函数释放空间(C++特有的)。(new与delete用法将在中阶篇进行深入探讨)
- 全局区/静态存储区:主要是存放全局变量与静态变量,程序运行结束后,操作系统自动释放。(全局区/静态存储区由操作系统进行回收)
备注:静态(static)修饰变量为静态变量,static关键字在中阶篇进行深入探讨
- 常量存储区:存放的是常量,不允许修改,程序运行结束自动释放。
备注:const修饰变量作为常量,const关键字将在中阶篇进行深入探讨
- 代码区:存放代码,不允许修改,但可以执行。编译后的二进制存放在这里。
- 内存泄漏(大厂面试高频题):程序中已动态分配的堆内存由于某种原因程序未释放,或者无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重问题。(通常情况下,一般是程序员未进行及时释放导致的内存泄漏)
例如:当使用new函数动态申请一块内存后,并未及时使用delete函数进行释放回收,久而久之,内存泄漏就相当严重了。
解决内存泄漏方法:智能指针
智能指针:使用时分配内存,不使用时,自动释放内存。(减少程序员担心内存泄漏的烦恼)
备注:智能指针将在高阶篇中进行深入探讨
结束语:本文较适合有一点点基础C语言的人,通过本文可以查缺补漏,当然作者的功底有限,本文也有可能不太好的地方,或者不完善的地方,也请大家在阅读本文的同时,能够提出批评和建议,我会进行弥补以及纠正。同时作者希望大家能够在阅读本文时,既能够收获知识还能收获快乐。最后作者希望大家能够热爱编程,不单是应付面试或者工作本身,更希望地是能够保持热爱,闪闪发光!!!
















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











