






1、研究内容
本文主要分析2023年3月-2024年1月西安地铁客流数据。主要内容有以下两方面:
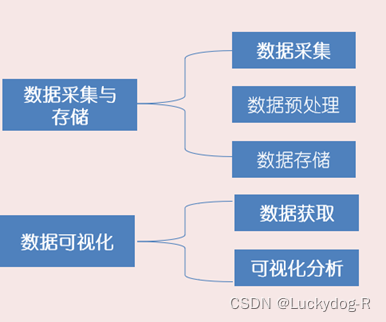
2、数据采集
2.1.确定数据源
本文采用的数据源是微博官网中西安地铁,客流数据。此数据为西安地铁官网数据,具有准确性和时效性。
2.2.数据采集工具介绍
Web Scraper是一款浏览器插件,主要用于简单的数据爬取,一定程度上可以代替selenium,减少代码编写。它是一款免费的,适用于普通用户的爬虫工具,可以方便的通过鼠标和简单配置获取网页上的内容,如文字、链接、图片、表格等,无需写一行代码。
Web Scraper的安装步骤如下:
1.打开Chrome浏览器设置,找到扩展程序。
2.打开浏览器开发者模式。
3.将crx的后缀名改为zip格式并解压。
4.点击拓展程序里面的按钮“加载已解压的拓展程序”。
5.成功部署Web Scraper。
具体操作参考:http://t.csdnimg.cn/9QOu2
2.3.数据爬取
采用Web Scraper框架爬取微博页面中的西安地铁客流数据。
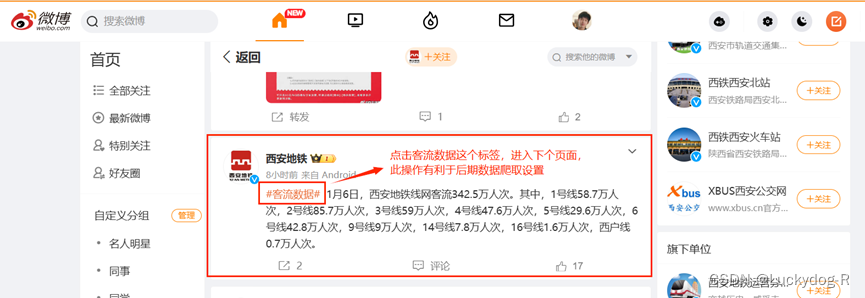
注意:Web Scraper插件是装在谷歌浏览器中的,但是谷歌浏览器中搜索关键字无法加载界面,可以采用本地浏览器,进入微博官网,搜索西安地铁,找到如下如页面。
然后复制URL地址:微博搜索 (weibo.com),之后打开谷歌浏览器,在地址栏中粘贴复制的网址,即可进入我们所要查找的界面。
1.本地浏览器微博页面如下图所示:
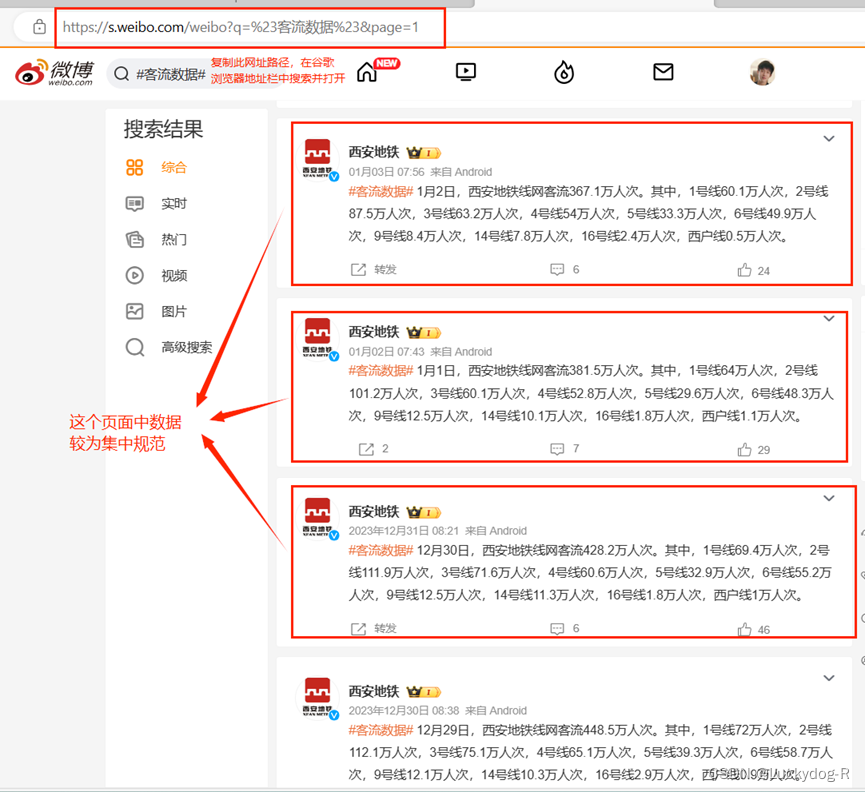
2.打开谷歌浏览器,在地址栏粘贴复制的网址并打开
https://s.weibo.com/weibo?q=%23%E5%AE%A2%E6%B5%81%E6%95%B0%E6%8D%AE%23&page=1
3.打开开发者工具
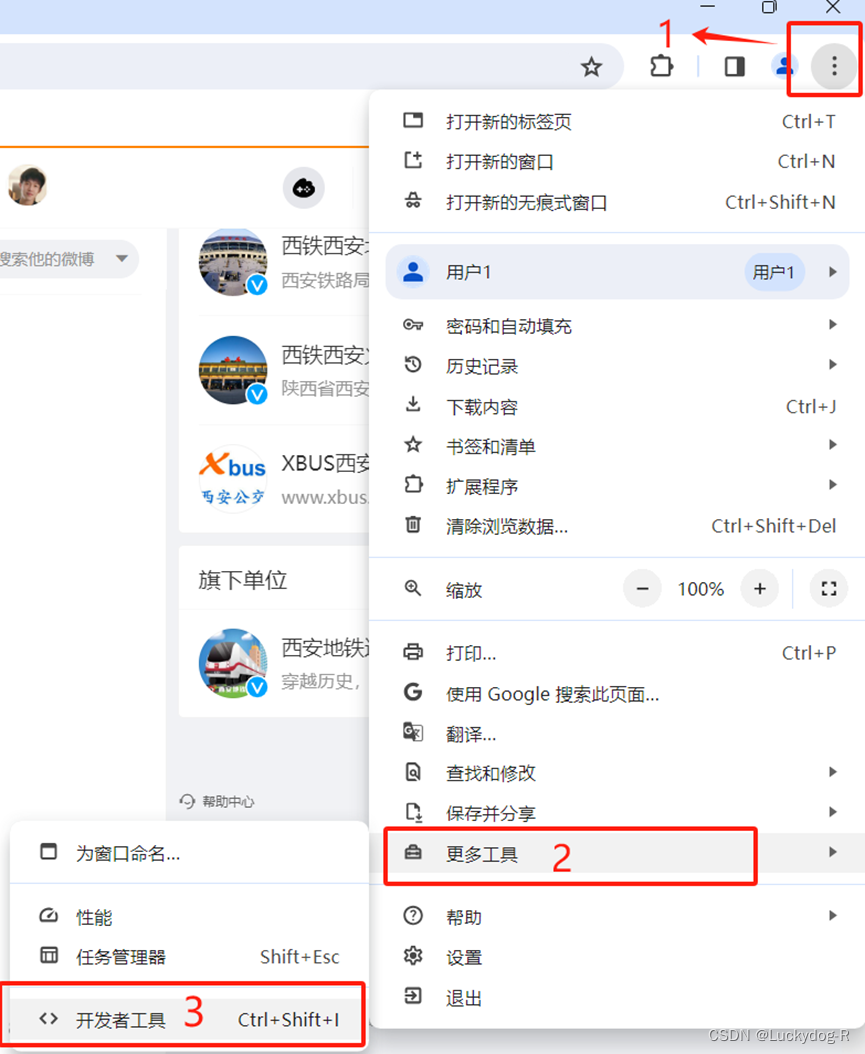
4.在开发者工具中,可以看到Web Scraper一栏。

5.点击Creat new sitemap,然后点击create sitemap,创建一个新项目。

6.创建一个选择器
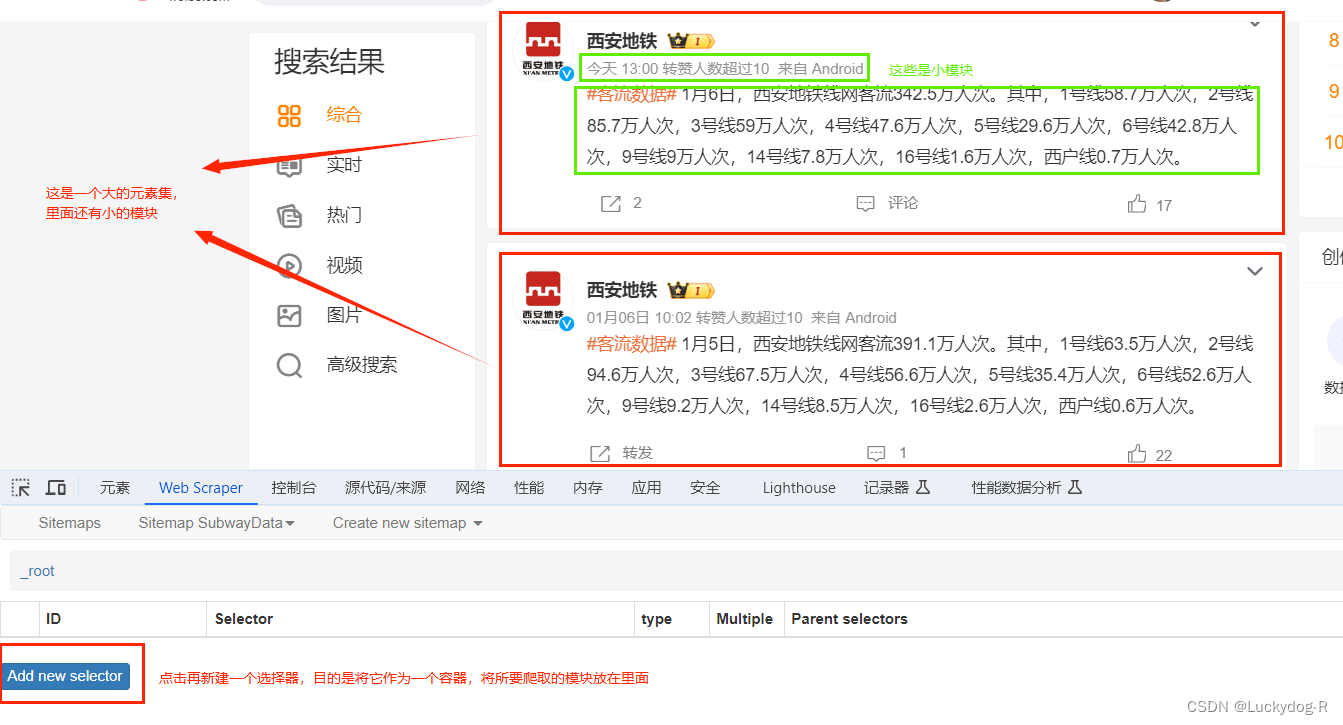
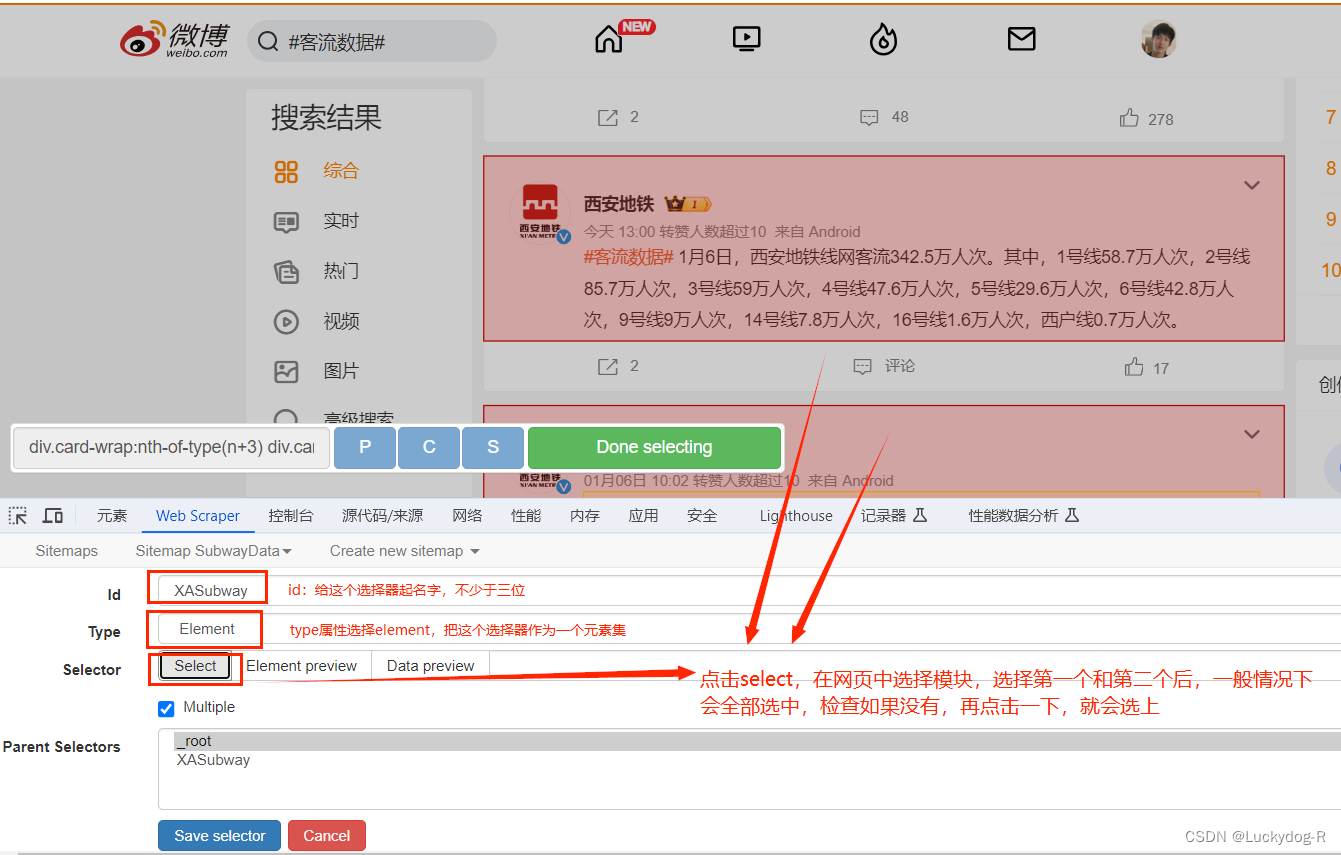
注意:选中模块后点击DoneSelecting
Multiple后面需要选上,大致意思为可以多个选择
然后点击save selector保存
7.点击XASubway,继续创建selector
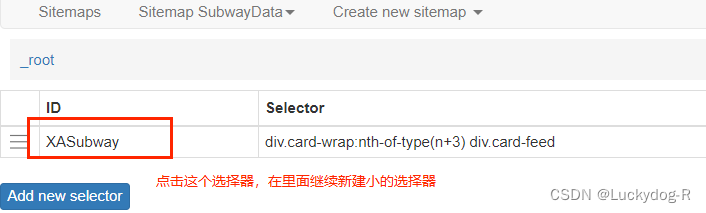
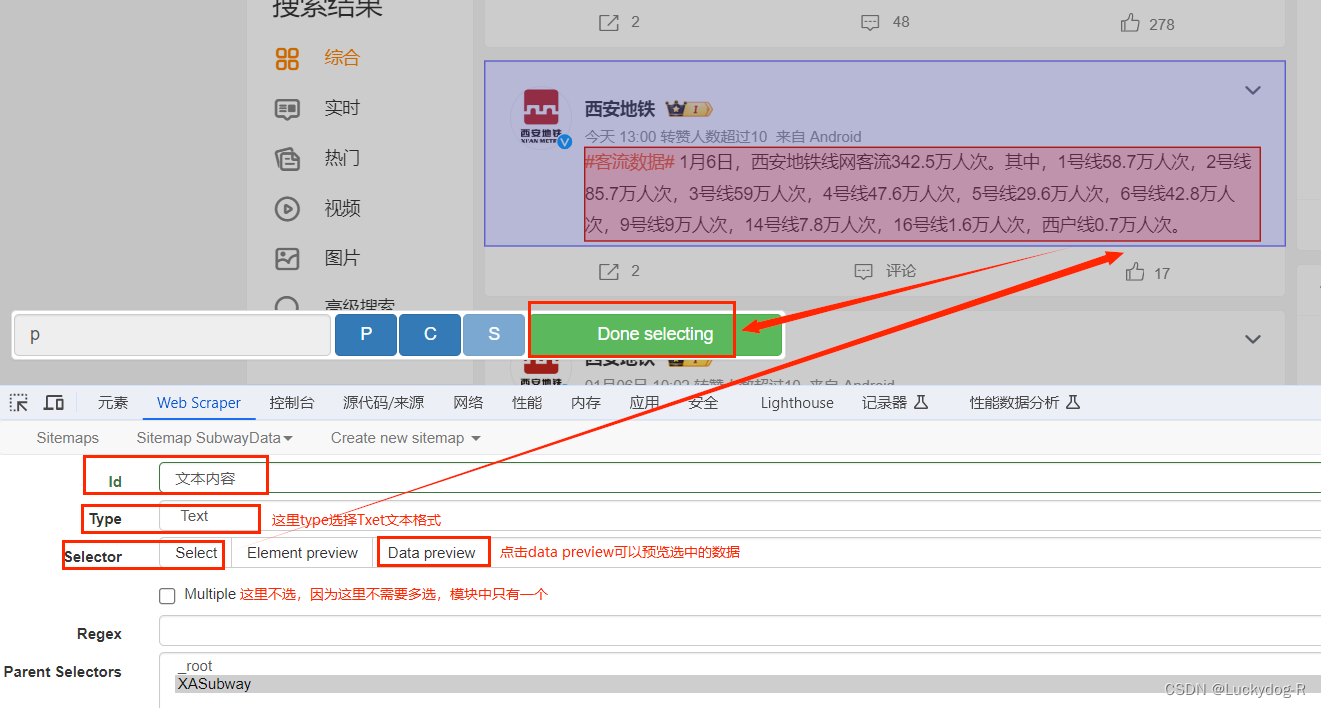

注意:因为我们需要的信息(文本内容)在一个模块中,所以此处设置一个selector即可,如果爬取别的网页(如需要价格、名称、销售量等,可以设置多个二级选择器)
8.点击selector graph,可以查看我们创建的节点目录
8.爬取
9.爬取完成
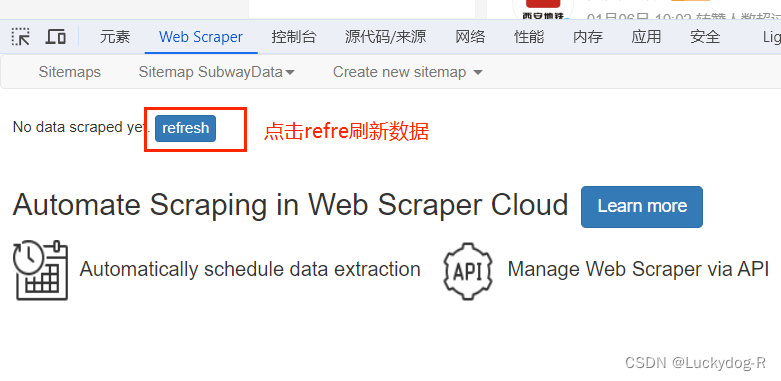
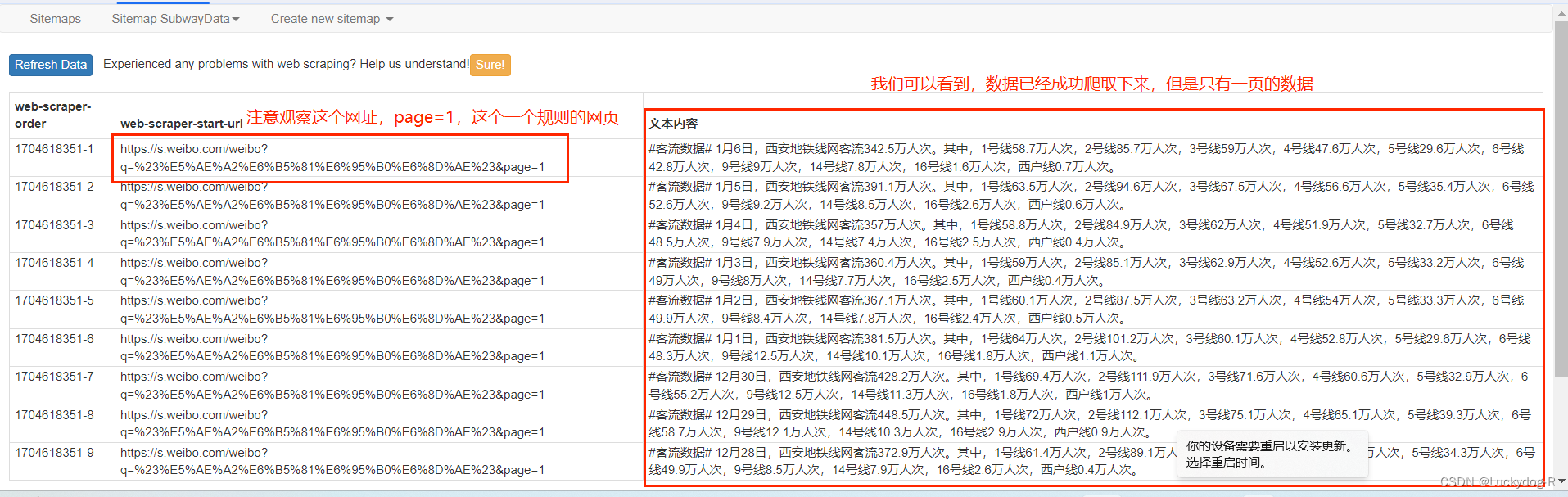
10.由于我们没有设置爬取范围,所以只爬取到了第一页的数据,观察网址,我们发现此网址较为规律,可以通过设置start url来实现多页爬取
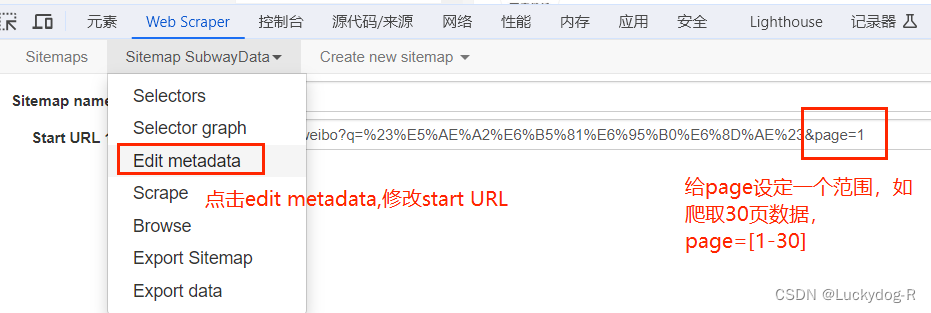
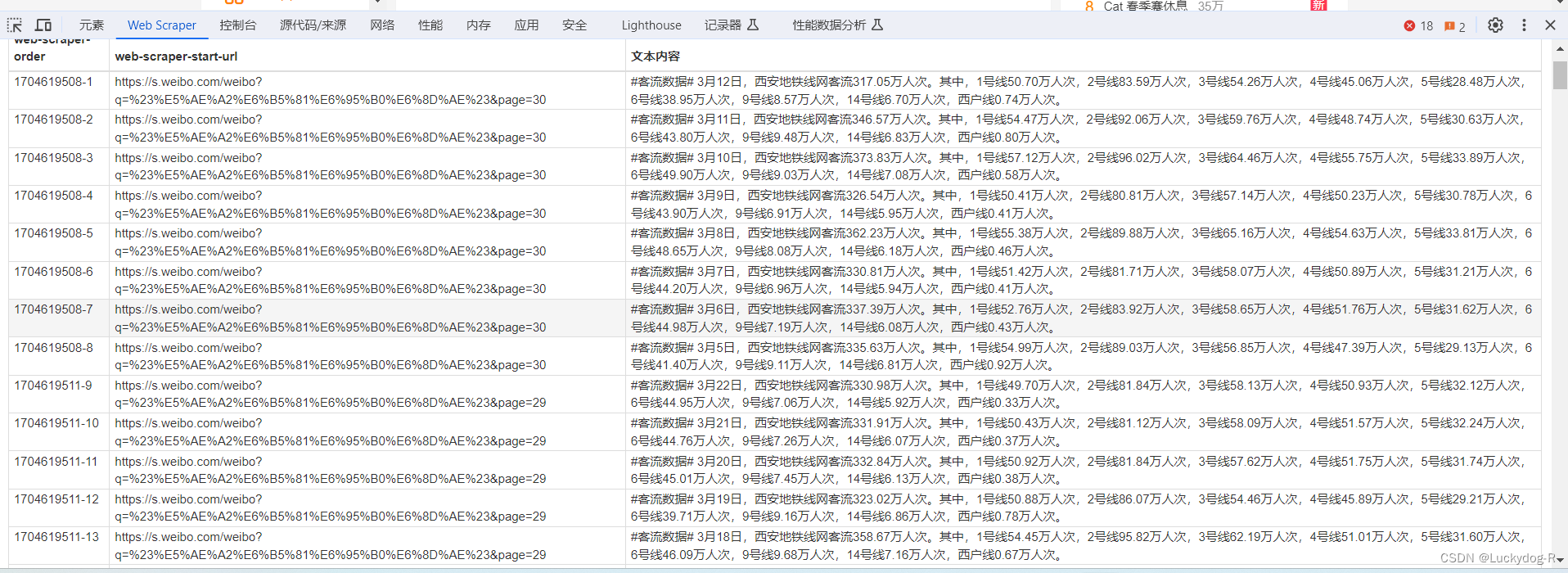
11.修改完成后,进行保存,然后进行爬取,方法同上,爬取完成后,点击刷新,发现数据已经采集到了,如下图所示:
12.将爬取的文件存储到本地
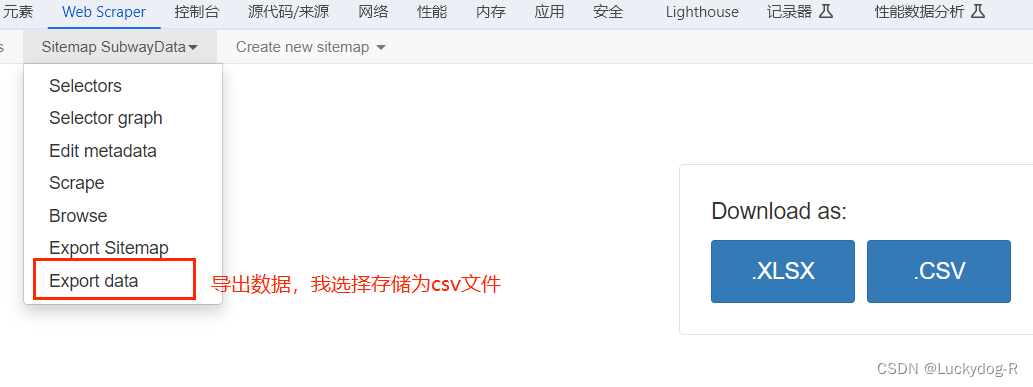
3、数据预处理
3.1.Excel处理数据
1.打开存在本地的csv文件,删除多余的列和行,只需保留“文本内容”即可

2.删除掉多余的列与行之后,我们发现所需的数据都在一列,接下来进行分列处理。
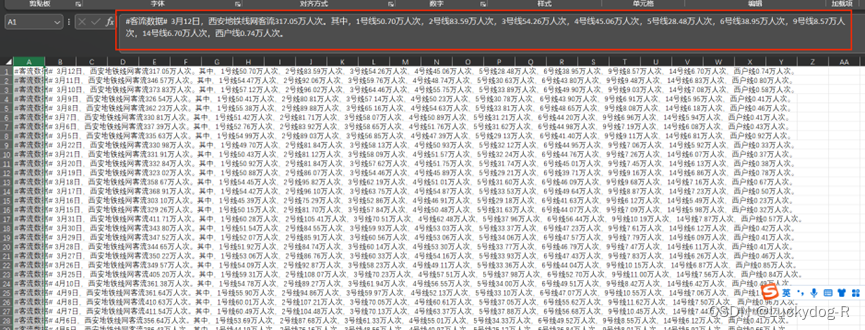
3.选中A列,点击工具栏中的分列。
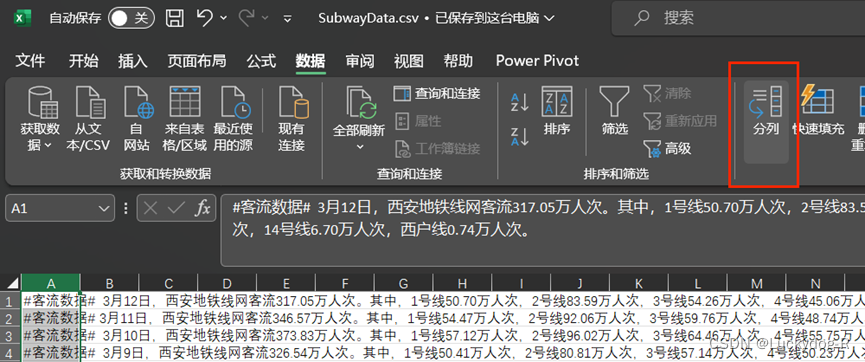
4.分列有两种方式,分隔符号和固定宽度,这里比较简单,注意分列时候,此列的后面要插入新一列,来存放分列后的数据,具体操作此处省略。
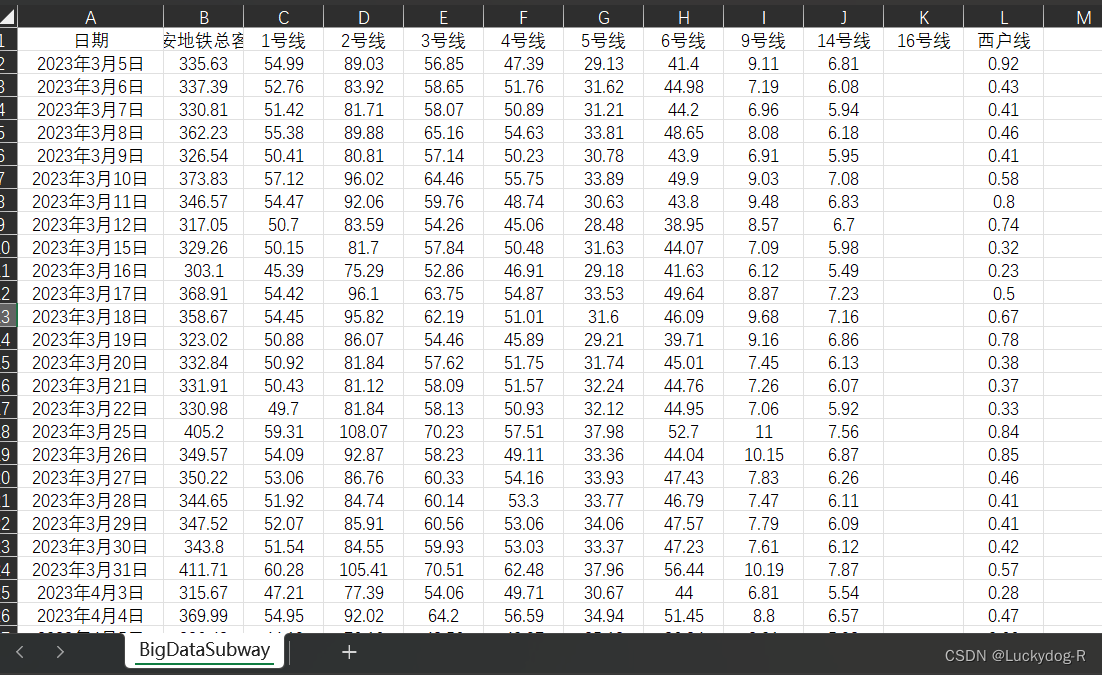
5.处理完成后,给数据添加列标题,结果如下图所示:
16号线这一列有空值,是因为16号线为2023年6月份新开通的线路,所以前期没有数据正常。
3.1.Jupyter Notebook处理数据
为了确保数据正常,我们在jupyter notebook中进行重复值、异常值等问题的检测与处理。以下是简单介绍:
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。
Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享程序文档,支持实时代码,数学方程,可视化和 markdown。 用途包括:数据清理和转换,数值模拟,统计建模,机器学习等等。
进入软件:
简单操作:
a.键盘输入模式
Jupyter Notebook 有两种键盘输入模式。
编辑模式,允许用户往单元中键入代码或文本;这时的单元框线是绿色的。
命令模式,键盘输入运行程序命令;这时的单元框线是灰色。
Shift+Enter : 运行本单元,选中下个单元
Ctrl+Enter : 运行本单元
Alt+Enter : 运行本单元,在其下插入新单元
Y:单元转入代码状态
M:单元转入markdown状态
A:在当前单元格上方插入新单元格
B:在当前单元格下方插入新单元格
X:剪切选中的单元
Shift + V:在上方粘贴单元
1.首先导入科学计算库Numpy和数据分析库Pandas
import pandas as pd
import numpy as np读取数据
XA_data= pd.read_csv(r'D:/学习/大数据分析及应用/西安地铁人流数据/BigDataSubway.csv')
XA_data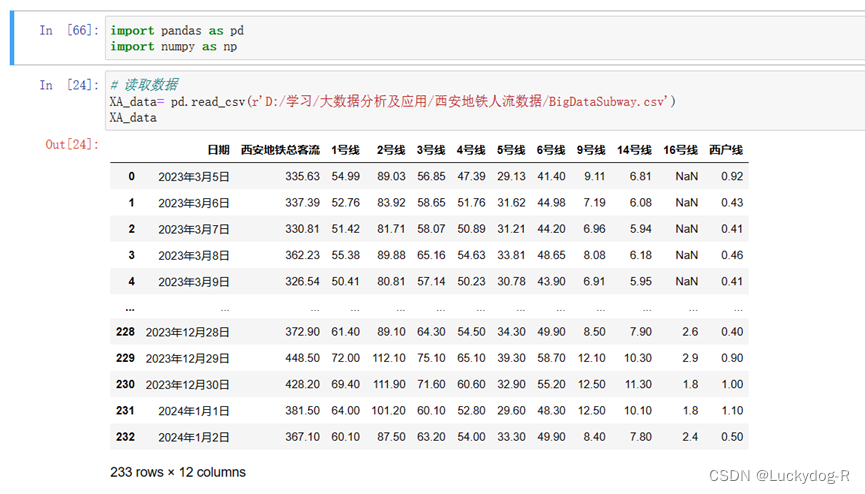
2.使用duplicated()检测cy_data中的数据,返回True的表示是重复数据,并统计每列重复值个数,显示0,表示不存在重复数据,下图显示有两个重复值
XA_data.duplicated().sum()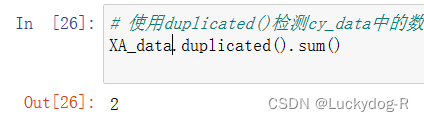
3.查看哪些行的数据是重复的
XA_data[XA_data.duplicated()]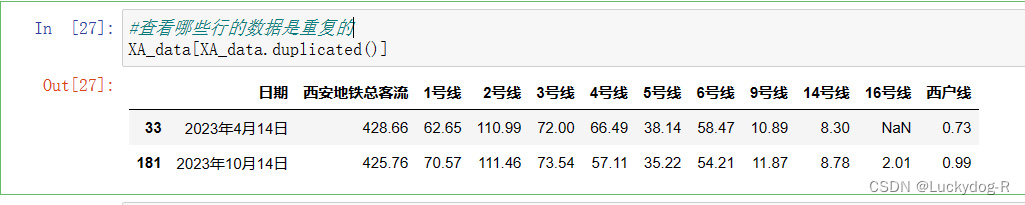
4.删除重复行
XA_data1=XA_data.drop_duplicates()
XA_data1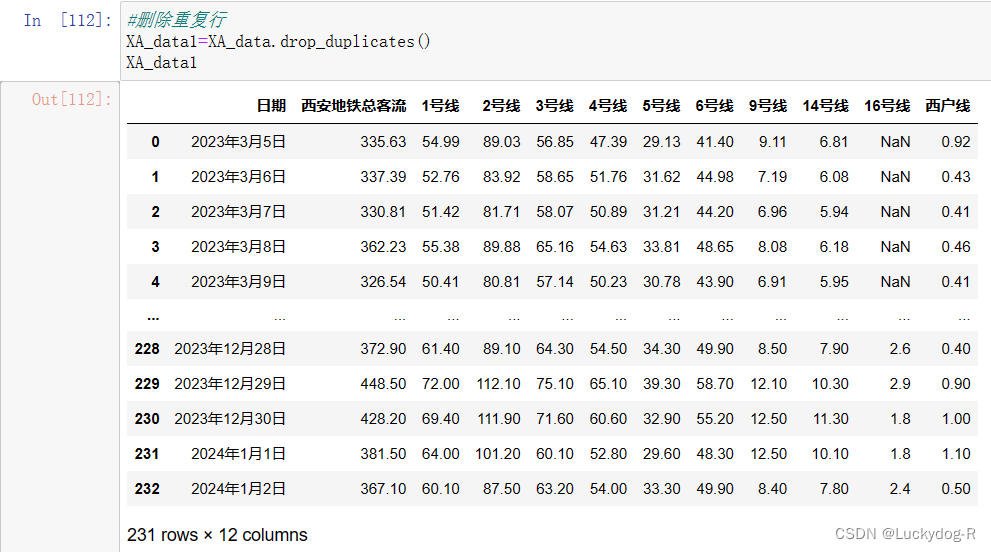
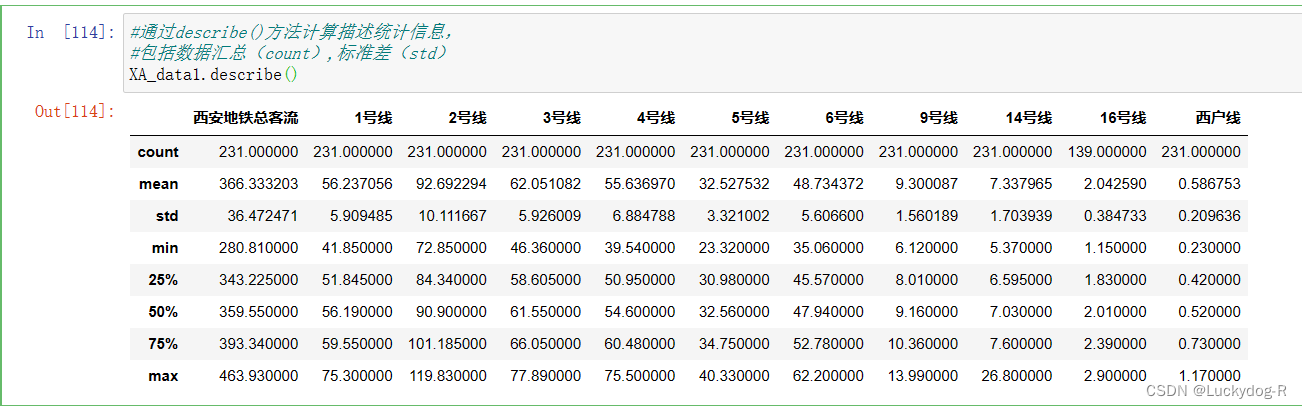
5.通过describe()方法计算描述统计信息,包括数据汇总(count),标准差(std)等
XA_data1.describe()
4、数据存储
4.1.数据存储在本地
将处理完的数据存入本地
XA_data1.to_excel(r'D:/学习/大数据分析及应用/西安地铁数据(处理后).xlsx')4.2.数据存储在MySQL
1.通过pycharm读取并将数据存储到MySQL
# 读取CSV文件
import pandas as pd
from sqlalchemy import create_engine
data = pd.read_csv("D:\学习\大数据分析及应用\西安地铁人流数据\西安地铁数据(处理后).csv") # 从CSV文件中读取数据
# 创建数据库连接
# 格式: engine = create_engine('mysql+pymysql://<username>:<password>@<host>/<database>')
engine = create_engine('mysql+pymysql://root:123456@localhost/xiansubway') # 创建一个连接到MySQL数据库的引擎
# 将数据写入数据库
# 注意: 'table_name' 需要替换为你想要写入的表名,if_exists='replace' 意味着如果表存在,则替换该表,追加append
data.to_sql('xiansubwaydata', con=engine, index=False, if_exists='replace') # 将数据写入数据库中的指定表
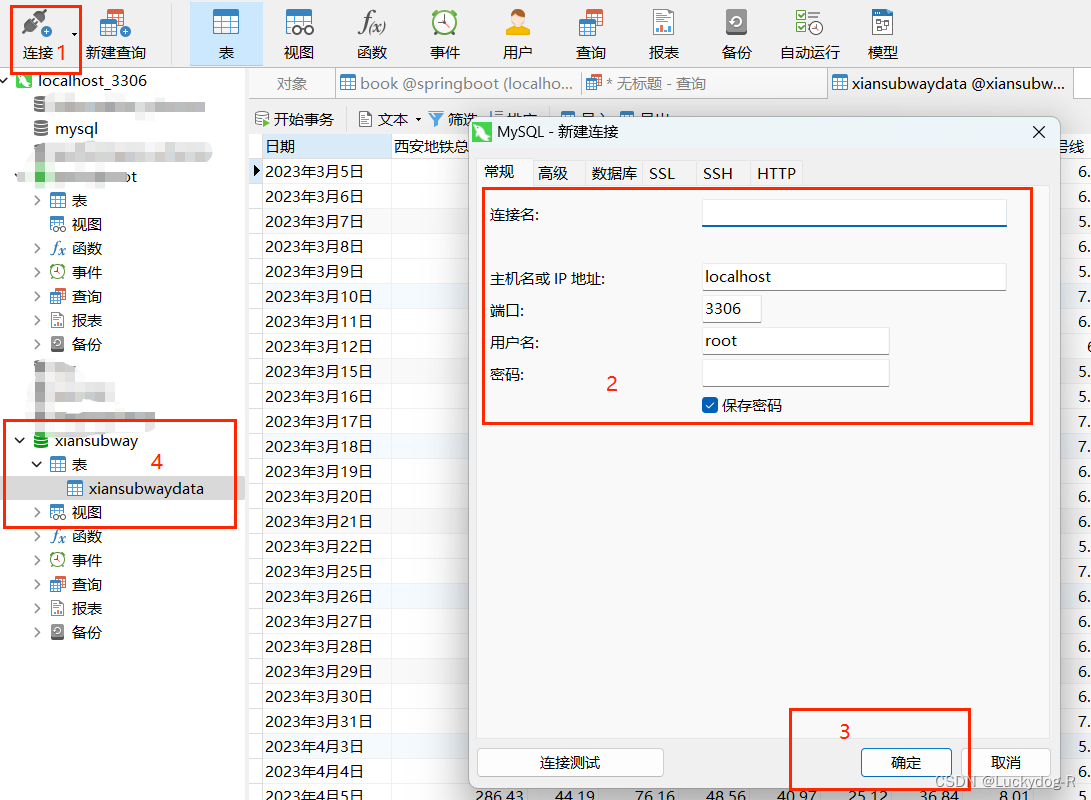
2.在navicat中连接MySQL查看数据
5、数据可视化与分析
1.利用pyecharts绘制玫瑰饼图,分析西安地铁2023年6月2日到2024年1月2日各路线乘客占比,可以看出2号线乘客最多,占比最大,达到25.21%,西户线占比最小,为0.16%。
from pyecharts.charts import Pie
from pyecharts import options as opts
cate = ["一号线","二号线","三号线","四号线","五号线","六号线","九号线","十四号线","十六号线","西户线"]
data = [7922.35,12825.61,8554.88,7665.67,4500.93,6719.97,1296.96,1021.95,277.33,80.21]
c=(
Pie(init_opts=opts.InitOpts(width='700px',height='320px'))
.add('',[list(z) for z in zip(cate, data)],center = ['50%', '60%'],radius=["30%","70%"],rosetype="radius")
.set_global_opts(legend_opts=opts.LegendOpts(type_="scroll",pos_left="right", pos_top="middle",orient="vertical"))
.set_global_opts(title_opts=opts.TitleOpts(title="西安地铁23年6月2日-24年1月2日各路线乘客占比", pos_top = '5%', pos_left = '20%'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
c.render_notebook() 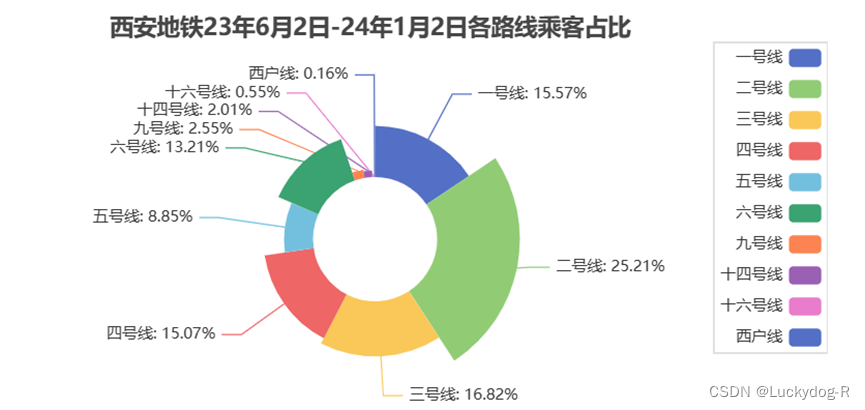
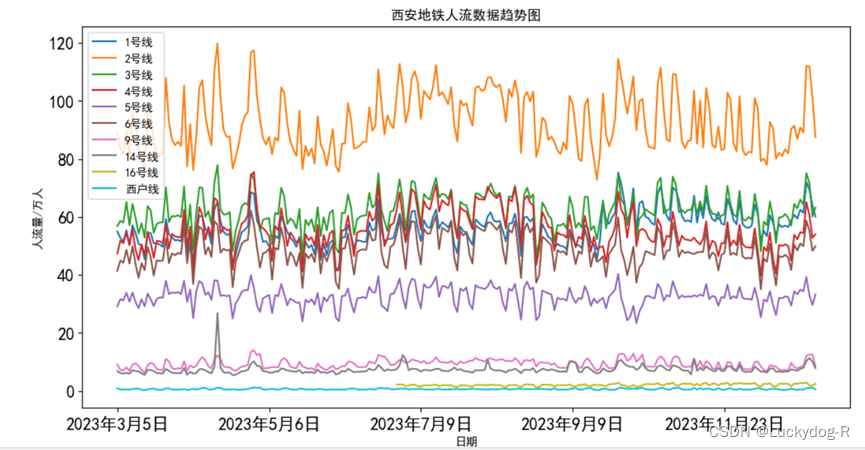
2.利用matplotlib绘制西安地铁人流数据趋势图,可以发现2号线客流量一直遥遥领先,最高单日客流接近120万人次。可以发现16号线数据只有一半,是因为16号线是23年6月下旬开通的。
3.利用tableau绘制西安地铁总客流量柱形图并排序,发现2023年4月15日西安地铁达到最高值,当天地铁客流达到463.9万人。分析原因,2023年4月15日当天,张杰在西安开演唱会。
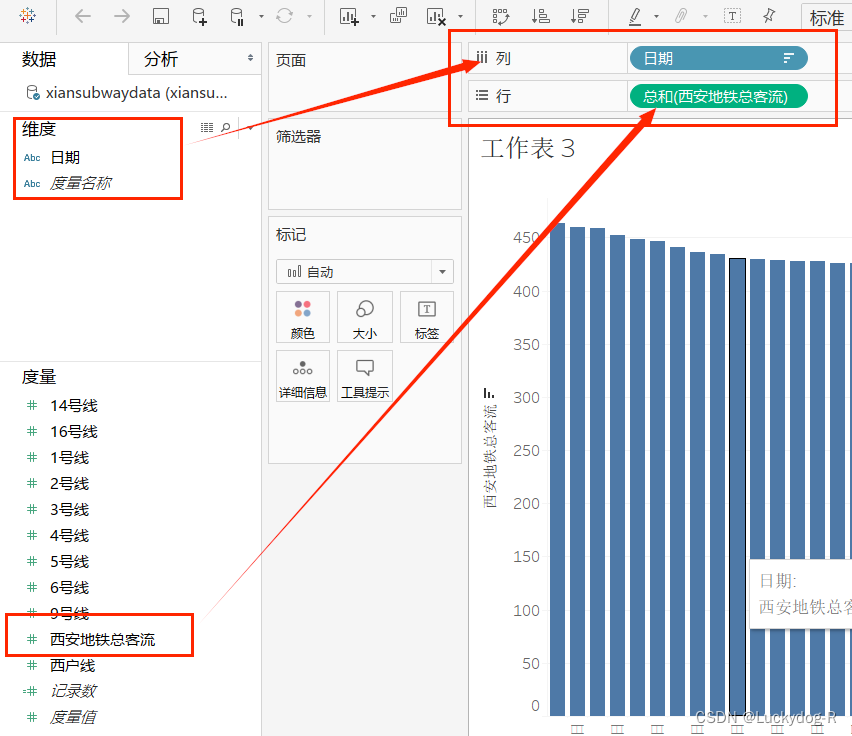
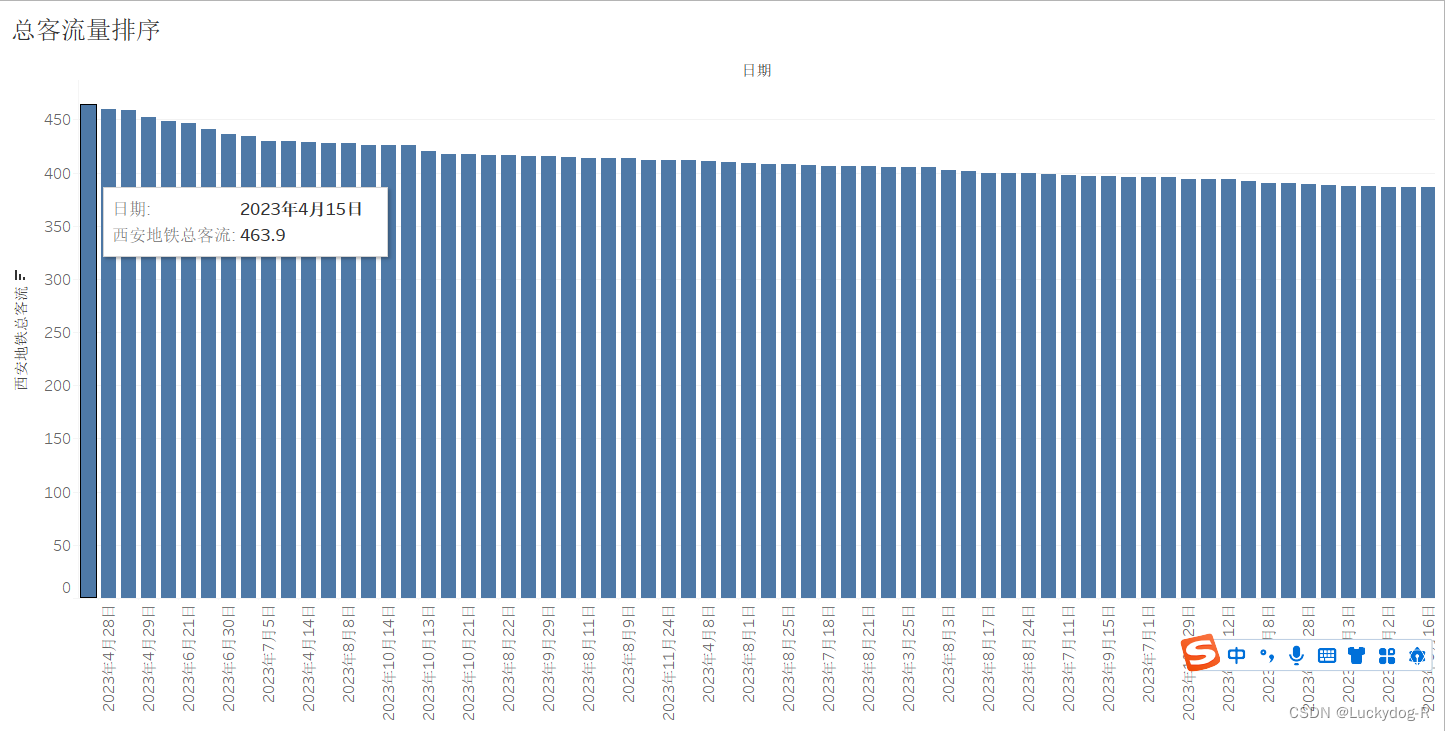
6、数据预测分析
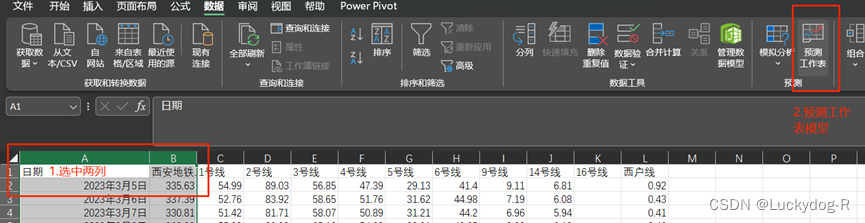
利用Excel制作一个简单的西安地铁总客流数据预测。其中包括现有数据,预测数据趋势,及置信上限和置信下限。
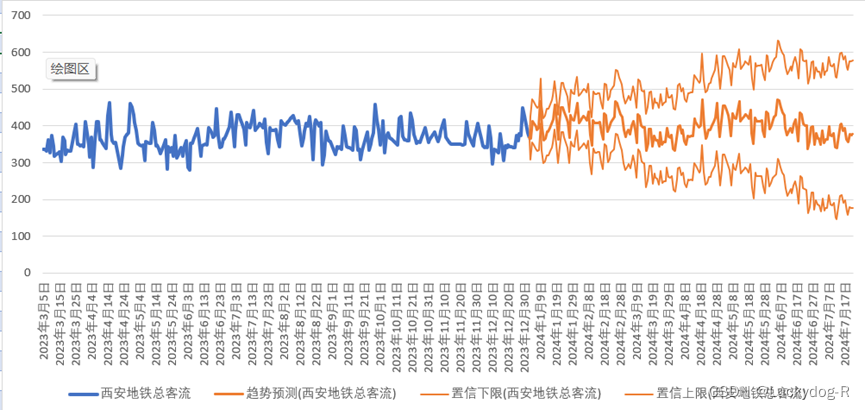 预测图
预测图
7、总结
分析数据及采用方法仅供参考学习,文中存在诸多不足,如有疑问或好的建议,请大家和我多多沟通,共同学习。


















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











