






 本文通过对北京市朝阳医院2018年1-7月药品销售数据的预处理,包括数据清洗、规范化、缺失值处理、异常值处理等,然后使用Excel、Tableau、Echarts等工具进行数据可视化,分析感冒类药品和药品销售排行,揭示了高血压、心绞痛等相关药品的高销量,为医院库存管理和疾病预防提供了参考。
本文通过对北京市朝阳医院2018年1-7月药品销售数据的预处理,包括数据清洗、规范化、缺失值处理、异常值处理等,然后使用Excel、Tableau、Echarts等工具进行数据可视化,分析感冒类药品和药品销售排行,揭示了高血压、心绞痛等相关药品的高销量,为医院库存管理和疾病预防提供了参考。
目录
第1章绪论
1.1研究背景
随着社会的不断发展进步,人们的衣食住行得到很大的改善,但同时,正是因为生活质量的不断提高,人们的饮食更加复杂化,由于不健康的饮食和生活习惯,导致身体的致病因素也随之增多,其次,工作压力,生活环境,体育运动等原因也是导致身体患病的因素之一。根据《中国卫生健康统计年鉴》的统计数据,近年来中国平均每人每年去医院看病6次左右。当然,有的人一年去医院看病十几次甚至几十次,有的人几年也不去医院看病一次,人们身体健康至关重要需引起全面重视。
下列年份的总诊疗人次数和平均每人就诊次数(按照总诊疗人次数除以当年总人口而得出)如图1-1所示:

图1-1
总诊疗人次数:指所有诊疗工作的总人次数,统计界定原则为:①按挂号数统计,包括门诊、急诊、出诊、预约诊疗、单项健康检查、健康咨询指导(不含健康讲座)人次。患者一次就 诊多次挂号,按实际诊疗次数统计,不包括根据医嘱进行的各项检查、治疗、处置工作量以及免 疫接种、健康管理服务人次数;②未挂号就诊、本单位职工就诊及外出诊(不含外出会诊)不收取挂号费的,按实际诊疗人次统计。
1.2 研究目的与意义
通过研究医院的药品销量,从而分析患者的致病原因,为此提出解决措施,可以从源头有效的预防此类疾病的发生。以及根据医院的药品销售数量,对医院药品库存提出参考,对于销量较高的药品应加大库存量,对于销量较低的药品适当减少库存,将医院资源更加合理化应用。避免出现供不应求的现象产生。同时,对于药品生产商,可以根据医院药品销售数量的反馈,从而适当的调整药品的生产,将销量居高的药品加大生产,对于销量较低的药品减少生产,避免因长时间库存而影响药品质量,同时,可以根据季节性疾病,地区性患者疾病特征,以及具有传染性疾病的药品根据医院药品销量结合外界因素(气候,地域特点等)预测药品需求,更加科学的控制各药品生产数量,将资源合理化应用。如,2022年底,全国疫情解封之后,患者对感冒类药品的需求远远大于供给,各种感冒药出现断货现象。
同时,药品价格指数是反映不同时期药品价格变动方向和程度的相对数指标,可用于测算药品价格变动对医院药品成本和病人药品费用的影响。医院药品销售指教包括药品购进价格指数、药品零售价格指数,单纯计算药品价格指数不能完整反映引起医院药品成本费用的变化原因,还需要计算药品购进量作数、药品销售量指数、药品费用指数。医院药品销售指教体系包括药品价格指数、药品数量指教和药品费用指数及其相对关联关系。在资料充足的情况下,根据不同的目的可计算不同的药品价格指数,如门诊药品价格指教、住院药品价格指教,或者计算西药价格指教、中药价格指数,为了反映基本药物和抗生素药品的价格变化情况,可计算基本药品价格指数、抗生素药品价格指数。[1]
1.3研究内容
本文以北京市朝阳医院为例,获取2018年1月-7月的药品销售数据,通过对所售药品进行归类,数量统计,药品的成分组成分析等,来分析患者的购药需求及深层分析致病原因,为患者,医院,药品生产商提出参考。
主要内容包括以下两大方面,如图2-1所示:
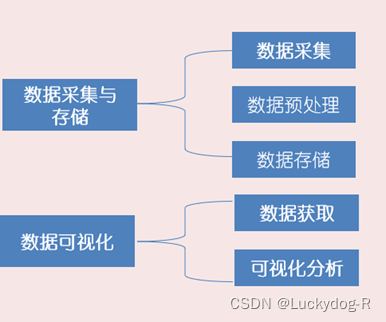
图2-1
2.1数据采集
2.1.1源数据下载
确定数据源,我的数据源是通过网页下载“朝阳医院2018年销售数据”。下载地址:
![]()
进入到所在页面后,CSDN用户为我们提供了一个数据下载链接和密码
数据下载:链接:https://pan.baidu.com/s/1NFCMP8QbIsMCgDrXEq5GCw
密码:o558
2.2.2源数据存储
我将下载好的源数据保存到电脑本地,保存路径为:"D:\学习\大数据分析及应用\朝阳医院2018年销售数据.xlsx"
打开下载好的文件,我们会发现文件文件中存在一些空值,重复值,数据格式错位等一些问题,所以我们需进一步对数据进行预处理。如下图是截取的数据表中存在问题的一部分。

2.2数据预处理
2.2.1数据预处理工具介绍及操作
我们对数据采取预处理使用的工具是jupyter notebook,以下是简单介绍:
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。
Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享程序文档,支持实时代码,数学方程,可视化和 markdown。 用途包括:数据清理和转换,数值模拟,统计建模,机器学习等。
进入软件:
简单操作:
1.键盘输入模式
Jupyter Notebook 有两种键盘输入模式。
编辑模式,允许用户往单元中键入代码或文本;这时的单元框线是绿色的。
命令模式,键盘输入运行程序命令;这时的单元框线是灰色。
Shift+Enter : 运行本单元,选中下个单元
Ctrl+Enter : 运行本单元
Alt+Enter : 运行本单元,在其下插入新单元
Y:单元转入代码状态
M:单元转入markdown状态
A:在当前单元格上方插入新单元格
B:在当前单元格下方插入新单元格
X:剪切选中的单元
Shift +V:在上方粘贴单元
2.2.2读取数据
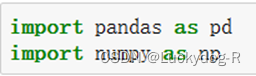
1.首先导入数据分析数据库Pandas和科学计算基础工具包Numpy
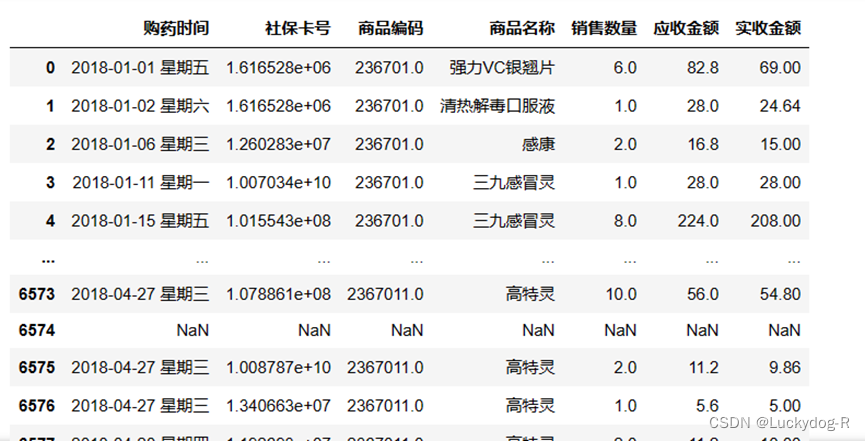
2.通过read_excel()方法读取本地的数据表

3.导入后查看结果显示:
2.2.3数据规范化处理
通过输出结果显示,“社保卡号”和“商品编码”这两列数据应该是字符串类型,却被转换成为数据值类型,为了正确地处理数据,需要对数据类型进行规范化处理。再次使用read_excel()方法读取本地的数据表,设置参数dtype={‘社保卡号’:str,’商品编码’:str}指定“社保卡号”和“商品编码”两列的数据为字符串类型。

查看数据规范化处理后的前5行数据,可以通过下图发现数据类型已转换
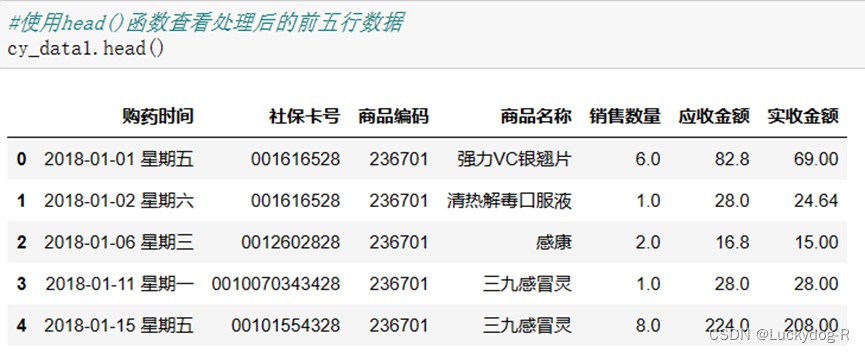
接下来我们查看数据的shape属性,结果显示为6578行x7列

从输出的前五行数据分析,我们发现“购药时间”存在歧义,将“购药时间”改为“销售时间”,通过rename()将其重命名,具体操作及处理结果如下图所示:
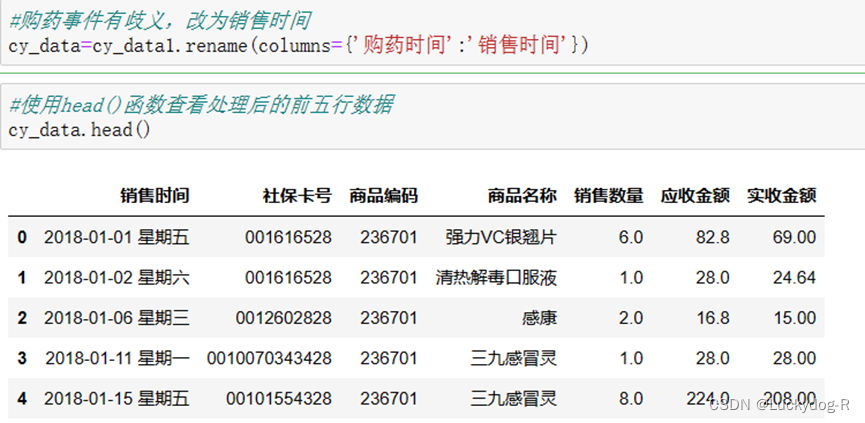
通过上图发现,已成功将购药时间改为销售时间。
2.2.4 检测空值和缺失值及处理
使用isnull()检测空值和缺失值,返回True(存在)和False,并使用sum()统计每列缺失值个数,具体操作如下图所示:

通过上图我们可以看出,每列都存在空值和缺失值,因为缺失值的数量并不多,不会对总体数据造成太大影响,我们采取删除的方法来处理空值和缺失值。使用dropna()方法并给其设置参数how=any,any表示如果存在NaN值,则删除该行或该列。

处理完成后我们再次.isnull().sum()来进行一次检测,检查是否删除成功。

上图所示,每列空值、缺失值为0,则删除成功。
查看删除后数据的shape属性,可以发现由6578行变成了6575行,可以看出,有些列的缺失值和空值在同一行。

2.2.5重复值检测及处理
我们通过.duplicated().sum()统计数据表中是否存在重复的行,.duplicated()的返回结果是布尔数组,再通过sum方法统计.duplicated().sum()中True的个数。从输出结果可以看出不存在重复数据。

2.2.6时间数据处理
由于data中的“销售时间”列的数据包含日期和星期,一般分析时间数据只需日期即可。通过Series.str.split方法将“销售时间”数据进行了分隔,data. loc[:,'销售时间']通过标签切片提取了data的“销售时间”列,再通过Series.str.sp1it方法将“销售时间”列的数据以字符串形式进行分隔,分隔符设定为空格,参数expand=true表示将字符串分割成单独的列,并以DataFrame形式返回。time是一个6575行×2列的DataFrame对象,index与data相同,第一列为“销售时间”的日期数据,第二列为“销售时间”的星期数据。
通过time.1oc[:,0]提取了time的第一列数据,并赋值给data. loc[:,'销售时间'],用time中的日期数据更新了data的“销售时间”列。
通过Pandas提供的to_datetime方法将“销售时间”列的数据类型从object 转换成datetime。format='%Y-%m-%d',指定要转换的原始数据的格式,errors='coerce'表示原始数据中无法解析成datetime格式的数据被设置为NaT。
注意:如果该行代码改写成data. data. loc[:,'销售时间']=pd.to_datetime(data.1oc[:,’销售时间‘],format='%Y-%m-%d'),运行时会报告ValueError:time data 2018-02-29 doesn't match format specified,说明data的销售时间中存在2018-02-29数据,而2018年是平年,不存在这个日期,因此该数据存在错误,需要将其设置为NaT,再进一步进行处理。

再次通过使用isna()和sum()统计dataframe每个数据列所包含的缺失值个数,通过结果可以发现“销售时间”存在23个缺失值。
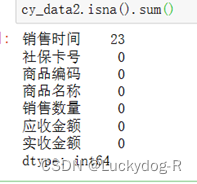
再次采用dropna()方法删除“销售时间”列存在缺失值的行,并将结果赋给新的对象cy_data3

查看删除后的数据属性,此时是6552行x7列

查看处理后的数据类型

2.2.7异常值数据处理
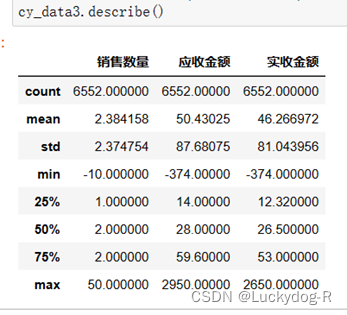
通过describe()方法计算cy_data3的描述统计信息,默认是销售时间,应收金额和实收金额这三列并对其进行统计分析,包括数据汇总(count)、平均值(mean)、标准差(std)、最小值(min)、第一四分位(25%)、第二四分位(50%)、第三四分位(75%)、最大值(max)等,从结果可以看出,这三列数据最小值存在负数,原因是销售数量存在负数,因此需要删除销售量小于0的值
定义一个布尔数组对象,通过cy_data3.loc[:,'销售数量']>0判断销售数量列中的数据是否大于0,大于0的显示True,小于0的显示False.
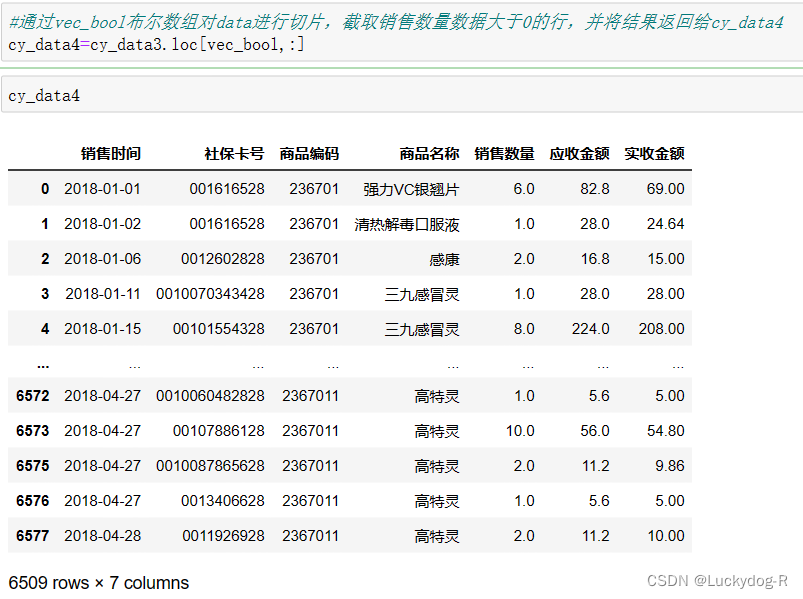
通过vec_bool布尔数组对data进行切片,截取销售数量数据大于0的行,并将结果返回给cy_data4
通过describe()方法计算处理后cy_data4的描述统计信息,默认是销售时间,应收金额和实收金额这三列并对其进行统计分析,包括数据汇总(count),标准差(std)。
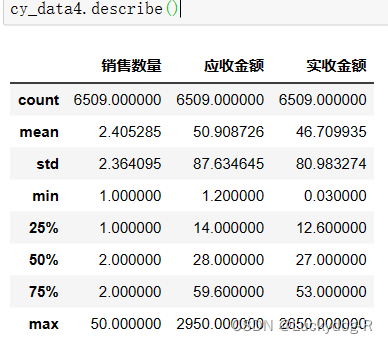
从结果可以看出刚刚min存在负数的问题已解决,也可以看出这3列数据都在正常范围之内。
2.2.8重置索引
由于前面处理数据时删除了很多行,所以需重置索引并赋给新的对象,设置参数drop=True表示不再保留原有的index数据。
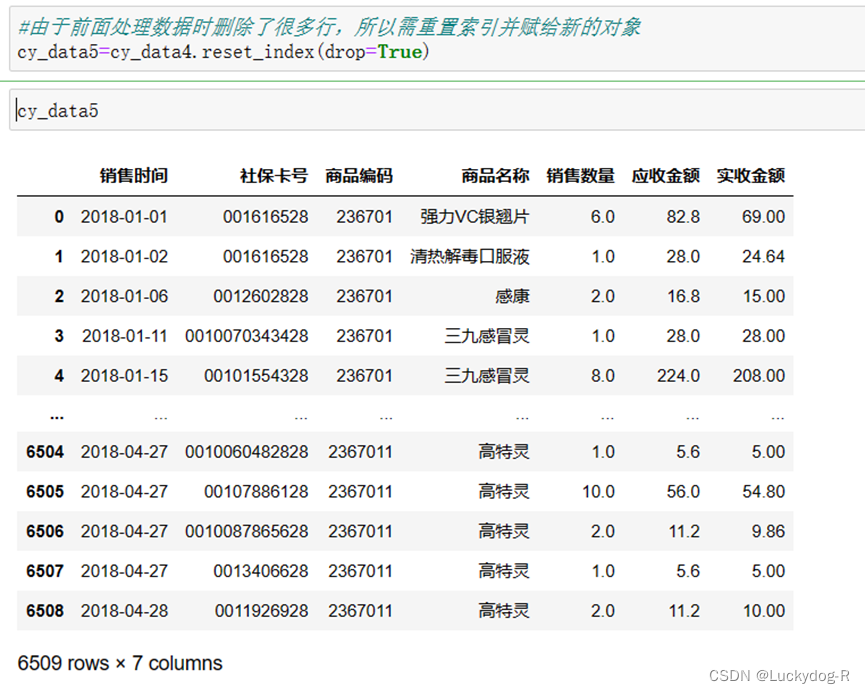
此时数据预处理已经完成。
2.3数据存储
将前面预处理完成的数据存在电脑本地。存储地址:
"D:\学习\大数据分析及应用\朝阳医院2018年销售数据(处理后).xlsx"

此时,电脑本地存在两个文件,如图所示:

2.4本章小结
本章主要是在jupyter notebook中对数据进行预处理,包括了数据工具介绍及操作,数据的读取,将数据从本地导入到jupyter notebook中,对数据进行规范化处理,以及空值,缺失值的检测和处理,还有重复值的检测及处理,以及对时间进行切片处理,保留我们需要的数据,还有异常数据处理,对一些不符合规定的数据进行删除,然后对修改后的表进行了重置索引,最后将预处理完成后的数据导入到本地。
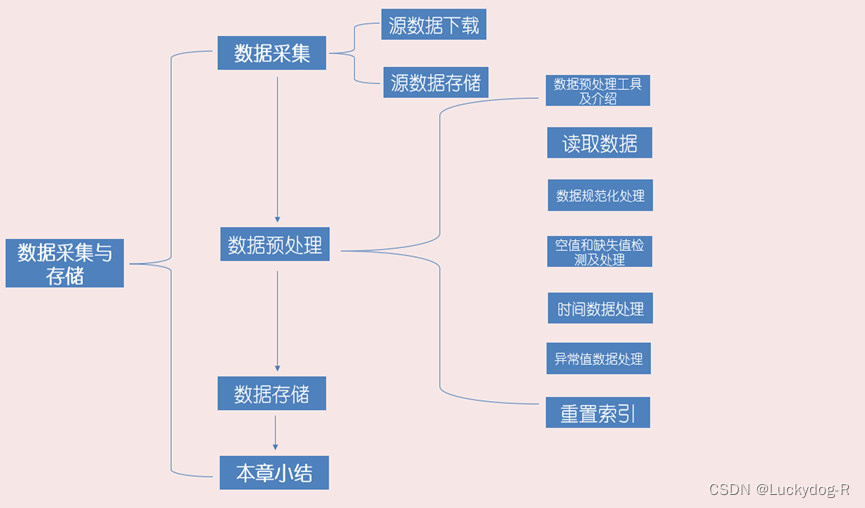
3.1可视化工具介绍
3.1.1Excel可视化工具
Excel是微软公司为使用Windows和Apple Macintosh操作系统的计算机用户编写的一款电子表格软件,直观的界面、出色的计算功能和图表工具,再加上成功的市场营销,使Excel成为最流行的个人计算机数据处理软件。
作为一个入门级工具,Excel拥有强大的函数库,也能创建供内部使用的数据图,因此是快速分析数据的理想工具。但是Excel的图形化功能并不强大,并且在制作可视化图表时图表中的颜色、线条和样可选择的范围有限,这也意味着用Excel很难制作出符合专业出版物和网站需要的数据图。
操作界面如下图3-1所示:
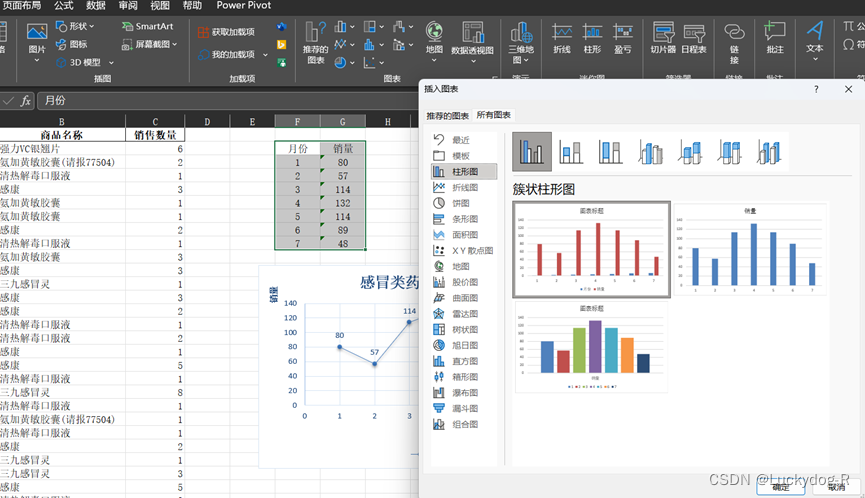
图3-1
3.1.2Tableau可视化工具
Tableau公司将数据运算与美观的图表完美地嫁接在一起。它的程序很容易上手,各公司可以用它将大量数据拖放到数字“画布”上,转眼间就能创建好各种图表。这一软件的理念是,界面上的数据越容易操控,公司对自己在所在业务领域里的所作所为到底是正确还是错误,就能了解得越透彻。
特点:拖放功能达到可视化任何数据的目的。
注意:维度(列)x轴,类别名称
度量(行)y轴,数值
特征:1.速度快,效率高。
2.简单易用。
3.可以连接多种数据源并实现数据融合。
4.高效接口集成与可扩展性强。
操作界面如图3-2所示:
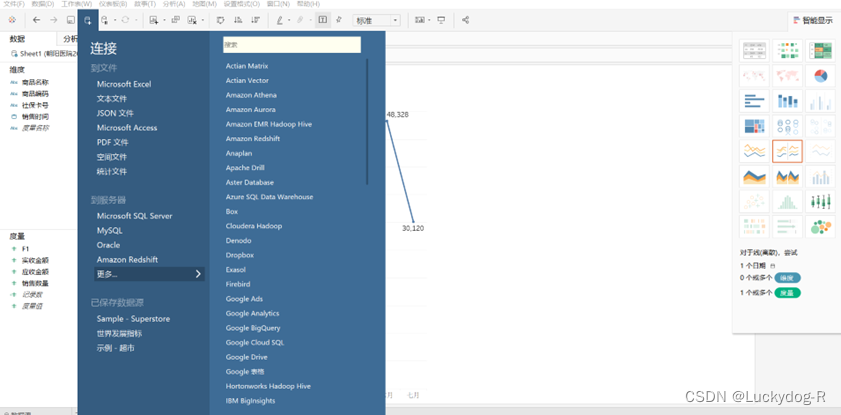
图3-2
3.1.3Echarts可视化工具
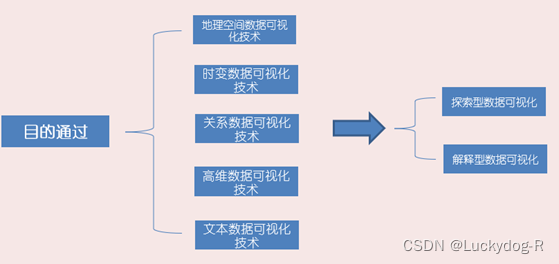
ECharts是一款基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。ECharts最初由百度团队开源,并于2018年初捐赠给Apache基金会,成为ASF孵化级项目。2021年1月26日晚,Apache基金会官方宣布ECharts项目正式毕业。1月28日,ECharts 5线上发布会举行。
主要功能:ECharts 提供了常规的折线图、柱状图、散点图、饼图、K线图,用于统计的盒形图,用于地理数据可视化的地图、热力图、线图,用于关系数据可视化的关系图、treemap、旭日图,多维数据可视化的平行坐标,还有用于 BI 的漏斗图,仪表盘,并且支持图与图之间的混搭。
运行环境:ECharts,一个使用 JavaScript 实现的开源可视化库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari等),底层依赖矢量图形库ZRender,提供直观,交互丰富,可高度个性化定制的数据可视化图表。
做图步骤:1.引入Echarts.js文件 ——图表依赖这个库
2.准备一个呈现图标的盒子——生成图标会放入这个容器内
3.初始化Echarts实例化对象——实例化Echarts对象
4.准备配置项——根据具体需求修改配置项
5.将配置项设置给Echarts实例对象——让Echarts对象根据修改好配置项生效。
操作界面,如图3-3所示:
3.1.4PyEcharts可视化工具
pyecharts=python+echarts
而Echarts 是一个由百度开源的数据可视化工具,有着良好的交互性,精巧的图表设计能力。当Python与Echarts结合就形成了pyecharts.
pyecharts是一种交互式的可视化库,图形展示跟matplotlib相比就好比河流与池塘。pyecharts更加灵活美观,作图更加灵活、巧妙。
做图步骤:1.导入模块;2.输入数据;3.设置全局变量;4.显示图片
3.1.5Matplotlib可视化工具
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
通过Matplotlib做图可将图像分为4层:
画板——位于最底层,导入Matplotlib库时就自动存在。
画布——建立在canvas之上,从这层就开始设置其参数。
子图——将figure分成不同块,实现分图绘图。
图表信息——添加或修改axes上的图形信息优化图表的显示效果。
做图步骤:
- 导入模块,计算模块:import numpy as np
绘图架构:import matplotlib.pyplot as plt
2.创建画布与创建子图。
3.添加画布内容。
4.图形的保存与展示.
3.2感冒类药品销售可视化
3.2.1数据获取
为了分析北京朝阳医院2018年1月-7月感冒类药品的销售情况,我们针对数据表进行处理,然后通过处理后的数据表进行可视化并加以分析。
前期,我们将下载好的源数据导入到jupyter notebook中进行了预处理,然后将预处理后的信息以.xlsx文件形式存储在本地:
"D:\学习\大数据分析及应用\朝阳医院2018年销售数据(处理后).xlsx"
打开数据表,我们对感冒类药品的销售情况进行分析,首先,通过筛选,将感冒类药品显示出来,然后通过求和公式,计算出感冒类药品每个月的销量。再将每种感冒药的销售数量进行求和处理,处理后的部分数据结果如图3-4所示:
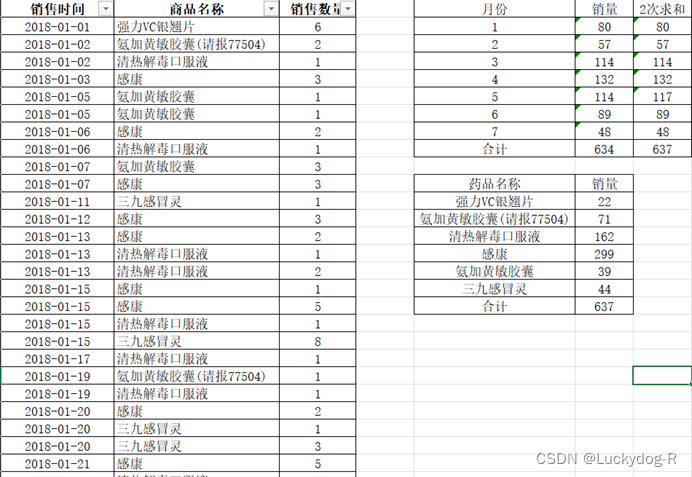 图3-4
图3-4
3.2.2可视化分析
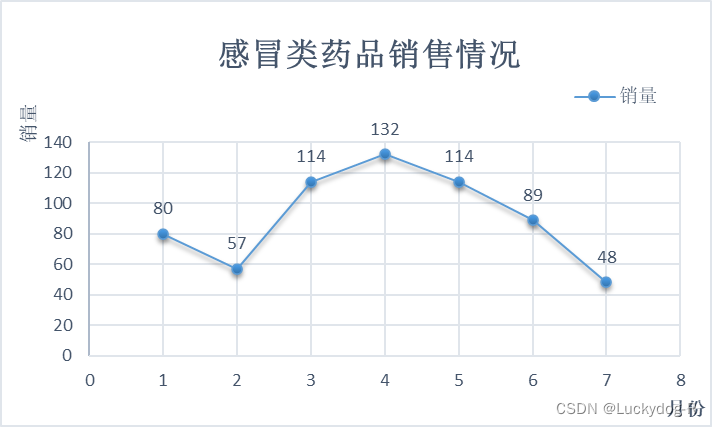
图3-5折线图
数据分析:如图3-5,从折线图中,我们可以更加直观清楚的看到,北京朝阳医院2018年1-7月感冒药的销售情况,由于数据表中7月份的销售数据不完整,所以只考虑前6个月,2月份的销售数量最低,原因可能是由于春节(2018年2月15日)期间,医院休假调整,以及人们回家过节,而导致的销量低,从2月份到4月份感冒药销量逐步增加,原因是春季流感高发季节,以及换季天气早晚温差较大,从而导致感冒人数较多,药品销量增加。4月份过后,天气逐渐变暖,也较为稳定,感冒人数较之前有所减少,呈下降趋势。
当季节变换时,周围的温度会发生改变,这时如果不注意更换衣物,就容易导致机体受到冷热空气的刺激,促使机体的免疫力下降,更容易受到周围病毒或者细菌的感染而引发感冒。同时在温差较大,气温骤降的时候,如果不注意保暖也会诱发感冒。
解决措施:
预防普通感冒以及流行性感冒的措施主要有注意个人锻炼、注意充分休息、注意日常饮食、注意防寒保暖等。
1.注意个人锻炼:积极锻炼身体可以有效增强身体抵抗疾病能力,能够有效预防流行性感冒发生,比如可以跑步、爬山、骑自行车等都是不错的运动方式,大家可以选择适合自己的方式来进行锻炼。
2.注意充分休息:人需要及时锻炼,同时也需要注意休息,人的睡眠状态不好会直接影响到人抵抗疾病的能力,所以一定要保持充分的休息,避免熬夜等情况发生,身体感觉到疲劳的时候就一定要及时的休息,保持充沛的精力才能够抵御外邪的入侵。
3.注意日常饮食:合理安排饮食也可以有效提高身体抵抗力,荤多素少,高脂肪、高热量的食物能够降低身体的免疫能力,所以尽量减少这些食物,一定要合理安排自己饮食,均衡搭配各种营养。
4.注意防寒保暖:
冷暖交替的时候人体可能不能很好地适应剧烈的冷暖变化,抵抗能力就会出现下降,这样就比较容易使得流行性感冒病毒侵袭人体,造成流行性感冒的发生,人一定要及时的注意天气的冷暖变化及时增加衣物,阳光不仅仅可以促进室内的保暖,而且有利于杀菌消毒,保持室内充分的日光照射。
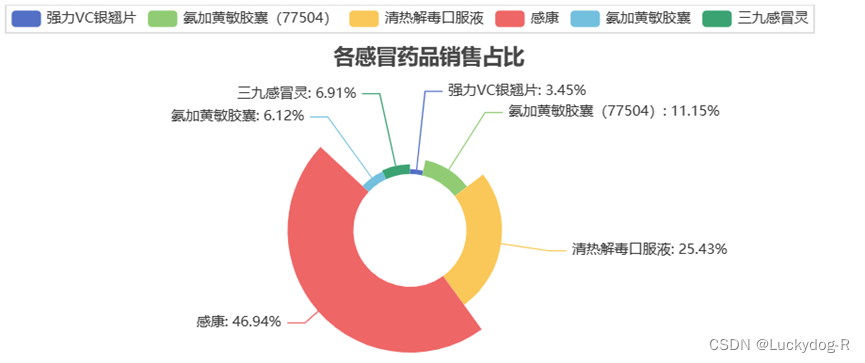
图3-6玫瑰饼图
数据分析:如图3-6所示,针对感冒药销量,我们将每种感冒药的销量进行了分析,发现感冒的销量最高,占到47%,清热解毒口服液销量仅次于感康,占比25%。对于感康等药品的详细信息,通过查阅资料发现:
感康:适用于缓解普通感冒及流行性感冒引起的发热、头痛、四肢触痛、打喷嚏、流鼻涕、鼻塞、咽喉痛等症状。
清热解毒口服液:用于热毒壅盛所致发热面赤,烦躁口渴,咽喉肿痛等症;流感、上呼吸道感染。
占比最大的两种感冒药,虽然都为感冒药,但作用却略有不同,可以发现,共同点都可以治疗流感,说明众多人因流感而导致感冒。
建议:在临床上,西药感冒药类型较多,每种感冒药的成分不,治疗效果不同,对患者的影响也存在着很大差异,由于西药感冒药药效发挥较快,进而在临床应用中,由于多种因素的共同作用,很多患者会发生不良反应,影响到临床用药的合理性,因此,需要对西药感冒药的不良反应进行研究 ,总结哪些感冒药容易发生不良反应,进而制定相应的应用对策,避免不良反应情况的发生,最大程度的确保临床用药的安全性[2]。患者应去医院听医生嘱咐,不可私自混买感冒类西药,避免因混吃而导致不良反应。
同时,针对销量较好的药品,医院应增加进货量,以最大程度满足供需,对于销量较差的药品,应减少进货量,进行库存优化,达到资源最大化利用。
3.3药品销售数量排行可视化
3.3.1数据获取
为了分析2018年北京朝阳医院1月-7月药品销量的排行,方便统计销量最高的药品和最低的药品数量,进一步分析病因以采取科学治疗及预防,和医院药品进货量的调整,我们使用Tableau连接本地数据库Excel表,采取柱形图进行分析。导入数据界面如图3-7所示:
图3-7
3.3.2可视化分析
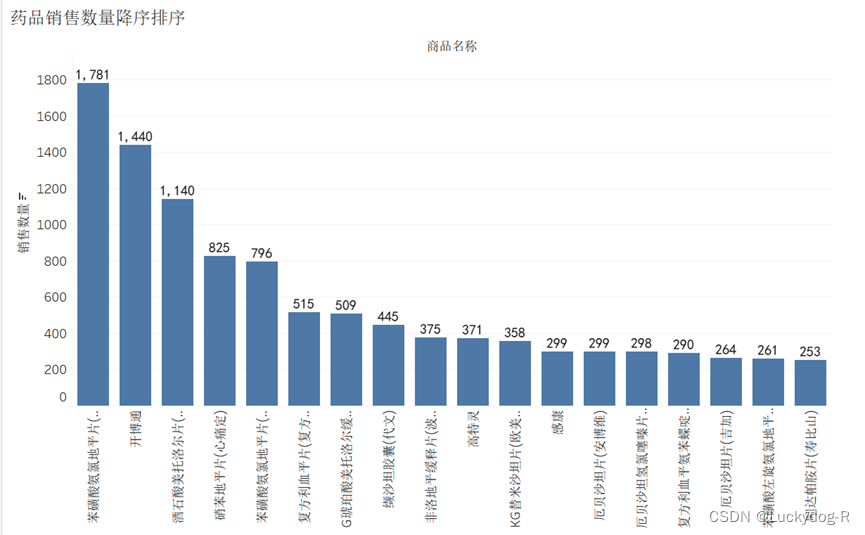
图3-8柱形图
数据分析:如图3-8所示,通过药品销售数量降序排序柱形图,我们直观的发现,1月-7月,苯磺酸氨氯地平片销量最高,达到1781,开博通、酒石酸美托洛尔片的销量也达到1000以上,我们进一步排行前五的药品进行分析研究。
Top1: 苯磺酸氨氯地平片, 适应症为
a.高血压本品适用于高血压的治疗。可单独应用或与其他抗高血压药物联合应用。
b.冠心病(CAD)慢性稳定性心绞痛本品适用于慢性稳定性心绞痛的对症治疗。可单独应用或与其他抗心绞痛药物联合应用。血管痉挛性心绞痛(Prinzmetal's 或变异型心绞痛)本品适用于确诊或可疑的血管痉挛性心绞痛的治疗。可单独应用也可与其他抗心绞痛药物联合应用。经血管造影证实的冠心病经血管造影证实为冠心病,但射血分数≥40%且无心衰的患者,本品可减少因心绞痛住院的风险以及降低冠状动脉重建术的风险。
本品主要成份为苯磺酸氨氯地平,其化学名称为:3-乙基-5-甲基-2-(2-氨基乙氧甲基)-4-(2-氯苯基)-1,4-二氢-6-甲基-3, 5-吡啶二羧酸酯苯磺酸盐。
Top2: 开博通,又名卡托普利,是一种有机化合物,化学式为C9H15NO3S,主要用作血管紧张素转移酶抑制药,被应用于治疗高血压和某些类型的充血性心力衰竭。
本品主要成份为:卡托普利。
适应症本品主要功效:1.高血压。2.心力衰竭。
Top3: 酒石酸美托洛尔片,适应症为用于治疗高血压、心绞痛、心肌梗死、肥厚型心肌病、主动脉夹层、心律失常、甲状腺功能亢进、心脏神经官能症等。近年来尚用于心力衰竭的治疗,此时应在有经验的医师指导下使用。
本品主要成份为酒石酸美托洛尔;化学名称为:1-异丙氨基-3-【对-(2-甲氧乙基)苯氧基-2-丙醇L(+)-酒石酸盐。
Top4: 硝苯地平片.
适应症为:1.心绞痛:变异型心绞痛;不稳定型心绞痛;慢性稳定型心绞痛。
2.高血压(单独或与其它降压药合用)。
本品主要成份为硝苯地平。
化学名称:2,6-二甲基-4(2-硝基苯基)-1,4-二氢-3,5-吡啶二甲酸二甲酯
Top5: 苯磺酸氨氯地平片。
适应症为:1、高血压本品适用于高血压的治疗。可单独应用或与其他抗高血压药物联合应用。
2、冠心病(CAD)慢性稳定性心绞痛本品适用于慢性稳定性心绞痛的对症治疗。可单独应用或与其他抗心绞痛药物联合应用。血管痉挛性心绞痛(Prinzmetal's 或变异型心绞痛)本品适用于确诊或可疑的血管痉挛性心绞痛的治疗。可单独应用也可与其他抗心绞痛药物联合应用。经血管造影证实的冠心病经血管造影证实为冠心病,但射血分数≥40%且无心衰的患者,本品可减少因心绞痛住院的风险以及降低冠状动脉重建术的风险。
本品主要成份为苯磺酸氨氯地平,其化学名称为:3-乙基-5-甲基-2-(2-氨基乙氧甲基)-4-(2-氯苯基)-1,4-二氢-6-甲基-3, 5-吡啶二羧酸酯苯磺酸盐。
结合柱状图对排行前五的药品进一步的研究发现,排行前五的药品全是针对于高血压,冠心病,心绞痛等患者,为此,我查阅资料,了解北京市朝阳区成人高血压患者的血脂异常流行现况及影响因素,为成人高血压合并血脂异常的防控提供科学依据。于2017年9月至2018年1月采用多阶段分层随机整群抽样方法,对调查对象进行面对面卷调查、体格检查与实验室检测。结果 朝阳区成年居民高血压合并血脂异常患病率51.57%(图3-9),且以高1G血症及低HDL-C血症型血脂异常为主,不同人口学特征居民高血压合并血脂异常患病情况比较结果显示:城究生别、年龄、文化程度、吸烟情况、饮酒情况、BMI和是否惠有糖尿病的居民高血压合并血脂异常患病情况的差异均有统计学意义(P均<0.05),多因素looistic回日分析结果易示,城区(0R=0.837,95%C:0.741 945)女性0R=0.822.95%CI0.688 0982,中学及中专0R=0.771.95%C:0.614~0.967)、大专及以上(OR=.822,95%C:0.686 .985)的文化程度和和不吸烟者0R=0.753,95%C1:.593 ~ 0.956)惠高血压合血脂异常的风险较低而超重、肥胜和糖尿病者的患病风险较高,超重和肥胖的高血压人群的患病风险是体重正常及偏瘦的1.53倍(OR=1.529.95%C:1.312 ~1782)和1.95(0R=1.948,95%C:1.652 ~2296)糖尿病者惠病险是未患糖尿病者的1.58倍0R=1.582,95%C:1.381 ~ 1.812)均有统计学意义(P<0.05)。结论 北京市朝阳区高血压患者血脂异常患病率较高,在高血压合并血脂异常管理中建议将超重、肥胖及糖尿病者作为防治高血压合并血脂异常的重点人群。(来源:知网)
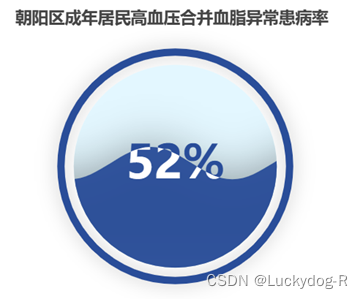
图3-9水球图
建议:对于高血压患者应该注意如下事项。
1、保持生活作息规律,避免熬夜,早睡、早起有利于控制血压,对血管起到保护作用。
2、适当运动,提倡有氧运动,如慢跑、快走,避免剧烈运动,以免导致血压突然升高,诱发脑出血、心衰等并发症。
3、养成良好的饮食习惯,避免暴饮暴食,饮食以清淡、低脂、低盐为原则,避免饮用咖啡、浓茶,戒烟限酒。
4、密切监测血压,同时定期检测血糖、血脂。
5、保持情绪稳定,避免大喜大悲。
对于医院而言,针对销量较好的药品,应增加进货量,以最大程度满足供需,对于销量较差的药品,应减少进货量,进行库存优化,达到资源最大化利用。
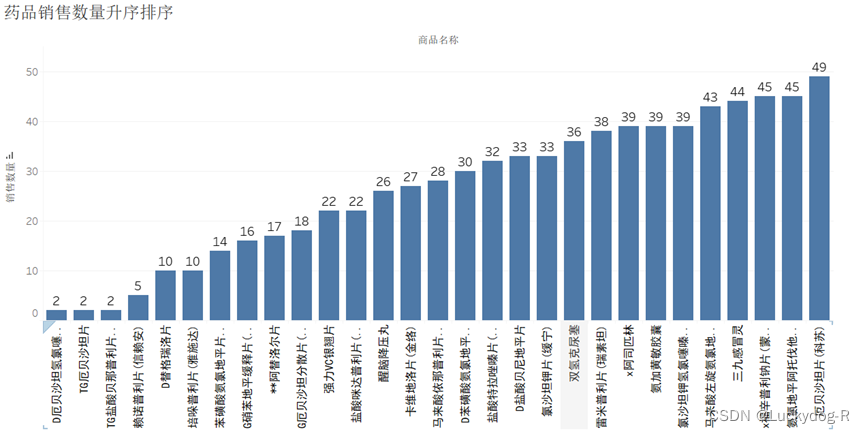
图3-10柱形图
数据分析,图3-10为药品销售数量升序排序,可以看出1-7月,销量低于50的药品达到29种,D厄贝沙坦氢氯噻嗪片(倍悦)等药品的销量不足10,医院可以根据此数据,适当的减少此类药品的进货,减少对库房资源的占用,也避免长时间库存而影响药品质量。对于药品生产商而言,也可以适当的减少此类药品的生产数量。
3.4药品销售金额趋势可视化
3.4.1数据获取
为了分析2018年北京市朝阳医院1-7月药品销售金额变化趋势,我采取使用Matplotlib制作折线图,通过图中线的变化来分析数据,我们直接在数据预处理的界面中,调用处理后的对象cy_data5,将cy_data5 赋给新的对象groupDf2,目的是防止做图时对之前清洗过的数据造成影响。
第一步:重命名行名(index)为销售时间所在列的值
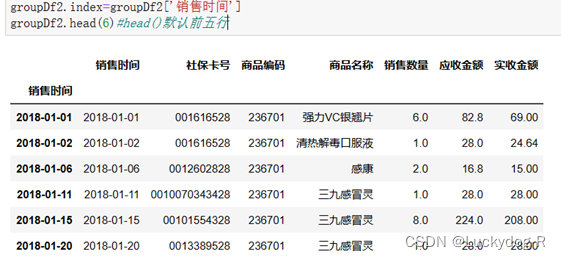
第二步:将索引按月进行分组

第三步:应用函数,计算每个月的消费总额
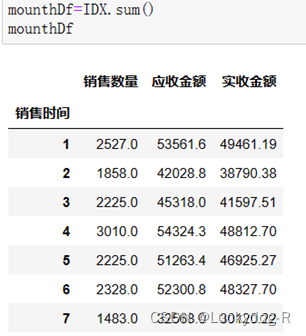
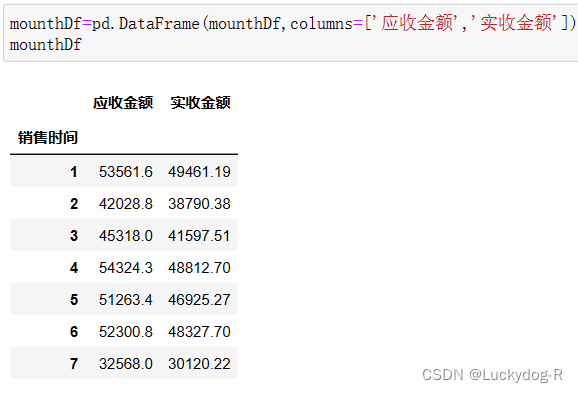
第四步:选取每个月的应收金额和实收金额的消费总额
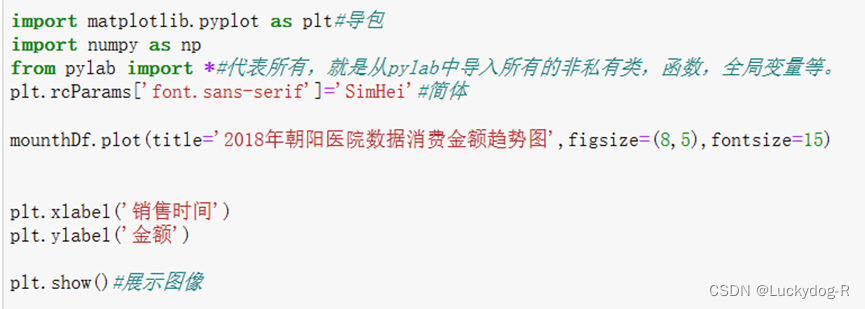
第五步,做图,首先,导入模块绘图架构:import matplotlib.pyplot as plt。然后创建画布与创建子图。再对画布添加内容。最后进行图像的展示。操作代码如下:
3.4.2可视化分析
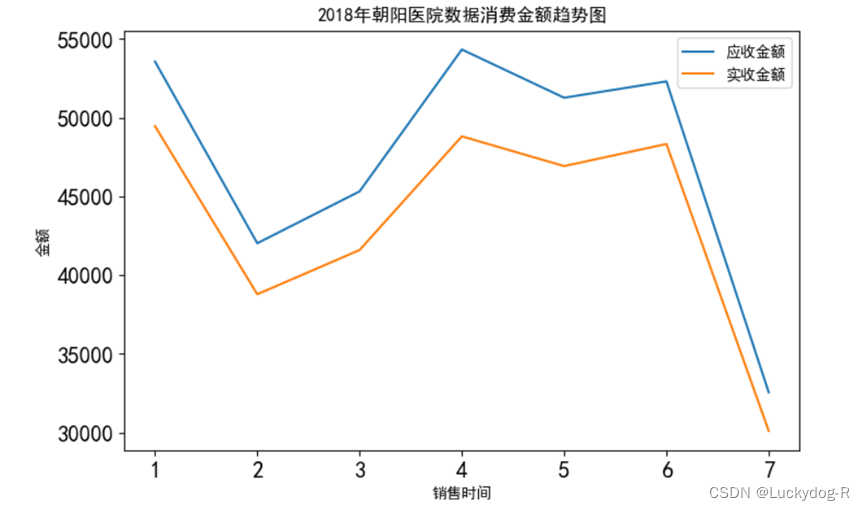
图3-11折线图
数据分析:如图3-11所示,通过折线图,我们发现,从1月到2月,销售金额有所下降,原因是春节期间,医院休假以及大部分人们返乡回家过节,前往医院购药人数较少,2-4月,春节后人们复工复产,城市人员有所上升,会导致医院的药品销售上涨,加之换季时候,普通感冒以及流感的爆发会使人们需要购买药品,从而使得销售金额有所上涨,4-6月销售金额变化不大,7月份数据不完整,所以不具备参考价值。同时可以看出,应收金额和实收金额之间的高度差反应了折扣率的大小,应收金额和实收金额差距越大,折扣率越大。可以看出4月份的折扣率最大,销售金额最高,药品打折在一定程度上会刺激销售量的增加。医院可以根据此图,来预测医院的输入,为医院的财政做出参考价值。
3.5 问题与措施
3.5.1 问题总结
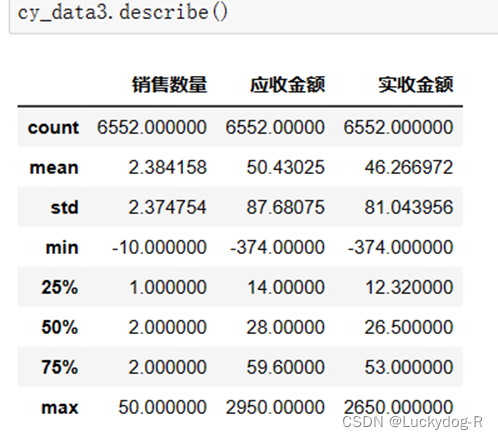
问题1:处理数据时,我使用describe()方法统计信息,发现销售数量存在负数,而导致销售金额出现负值,因此需要删除销售量小于0的值,问题截图如下:
3.5.2 相关措施
处理问题1:定义一个布尔数组vec_bool,将cy_data3赋给vec_bool,通过cy_data3.loc[:,'销售数量']>0判断销售数量列中的数据是否大于0,大于0的显示TRUE,小于0的显示FALSE,然后通过vec_bool布尔数组对data进行切片,截取销售数量数据大于0的行,并将结果返回给cy_data4。最后再利用describe()进行数量统计,发现销售数量存在的负值的问题已解决。

第4章总结与展望
4.1 总结
本文以2018年北京市朝阳区1-7月销售数据为例,统计了朝阳医院1-7月的药品销售排行及各药品深层分析,发现高血压类药品销售最多,且排行前五的全是高血压类药品,为此对患者,医院以及药品生产商提出了参考意见;以及感冒类药品每月的销售数量及各种感冒类药品的销售占比,发现了2-4月流感季节感冒药销量居高,且感康的销量在感冒类药品中占比最大,对患者预防感冒及患感冒后服用感康与其他药品的注意事项提出了参考意见,其注意事项内容参考了知网中的论文。还分析了医院的销售金额变化趋势等,供医院财政收入参考。
4.2 展望
由于本次课程设计的时间紧张,加之自己的知识能力有限,对于研究目的中提出的根据已有药品销量对未来药品销量等一些预测分析,还未完成,药品销量的分析可以从侧面反应出患者对不同药品的需求,以及不同季节,地域的影响对药品销量均有所影响。在后期,我将继续完成本次课设未完成的预测分析、价格指数分析等一些问题,更加深层次的挖掘数据的意义,更好的为患者,医院,及制药商提出可靠性参考意见。
同时,面对已有问题,政府应建立完善的卫生保健体系,不断增加医疗投入,完善医疗设备,提高医疗技术水平,以优质的医疗资源来保障各类人群健康需求。
建立全民健康教育体系,通过举办健康讲座、宣传疾病预防和科普普及等活动,增强公众的健康知识与意识,倡导人们树立健康的生活方式和消费观。
鼓励开展科学研究,探索更为安全、有效、快速的治疗手段和疾病控制方法。技术的应用和理论的深入研究可以为人类疾病控制和健康提供更有效的方法和方案。
中国的疾病现状绝非一朝一夕形成,需要持续地采取措施,慢慢地改善,才能为广大人民提供安全、有效的医疗服务和更好的健康保障。除此之外,还需要强调预防和早期筛查的重要性。对于诸如糖尿病、高血压、肝病、癌症等慢性疾病,及时的筛查和早期治疗可以大大提高治愈率。例如,定期检查血糖、血压、肝功能等,对于预防或者治疗疾病都有很大的帮助。而且,许多疾病的早期症状并不明显,需要及时就医才能够被发现。因此,个人主动关注自身身体状况,定期进行体检是十分必要的。
作为每个人,我们也应该树立健康意识,寻求科学的健康生活方式。尤其是在现代社会,工作和生活压力大,人们的健康情况正面临很大的挑战。减少对烟、酒、咖啡等副作用大的物质的依赖是有必要的,保持充足的睡眠、适当的锻炼以及多吃健康食品对身体健康也有很大的帮助。
切实关注中国的疾病现状是我们每一个人的责任。及时接受医学检查、改变不健康的生活习惯、培养健康的心态和信念都与一个健康的生活密不可分,而这也是我们所期望的。在促进健康状况的改善过程中,我们还需要重视的是与环境和食品卫生相关的问题。中国是世界上最大的发展中国家之一,人口众多、农村人口占比较高,在环境卫生和食品安全方面存在着很大的问题。空气污染、水污染等诸多环境问题已经成为当前中国面临的重要挑战,而食品安全问题更是广受人们关注。
针对环境问题,我们应该积极参与到环保活动中,防止污染未然。尤其是在重点区域,政府应加大治理力度,落实环保政策,加强监管执法,着力构建绿色生态环境。
食品安全问题可以通过实行科学的品种培养、农药、肥料的使用、养殖等行业规范和技术规范来改善。消费者也应该养成培养良好的食品卫生习惯、购买在法销售的商品和从正规销售机构购买食品等生活方式。
探究中国疾病现状,除了针对医疗行业重视医疗服务质量提升外,调整个人生活方式以及整体社会生态环境等方面的改善也是需要关注的。倡导健康生活方式,加强环境改善和食品安全问题解决,可以缓解疾病高发、并最终改善中国疾病现状。
参考文献:
[1]王光伟,吴咏梅,李晖.浅谈医院药品销售指数的编制及应用[J].企业导报,2012,(24):120-121.
[2]李梦琳.西药感冒药的不良反应研究[J].生物技术世界,2015,(01):64.


















 5233
5233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











