







接下来将用IBM SPSS对finebi中提取的理财产品数据实现分类算法数据挖掘和数据分析,以及可视化图表呈现。
1.知识准备
数据在当今世界意味着金钱。随着向基于app的世界的过渡,数据呈指数增长。然而,大多数数据是非结构化的,因此需要一个过程和方法从数据中提取有用的信息,并将其转换为可理解的和可用的形式。
数据挖掘或“数据库中的知识发现”是通过人工智能、机器学习、统计和数据库系统发现大数据集中的模式的过程。
免费的数据挖掘工具包括从完整的模型开发环境如Knime和Orange,到各种用Java、c++编写的库,最常见的是Python。数据挖掘中通常涉及到四种任务:
分类: 将熟悉的结构概括为新数据的任务
聚类: 在数据中以某种方式查找组和结构的任务,而不需要在数据中使用已注意的结构。
关联规则学习: 查找变量之间的关系
回归: 旨在找到一个函数,用最小的错误来模拟数据。
2.基于决策树分析亏损顾客特征
2.1 预测变量重要性
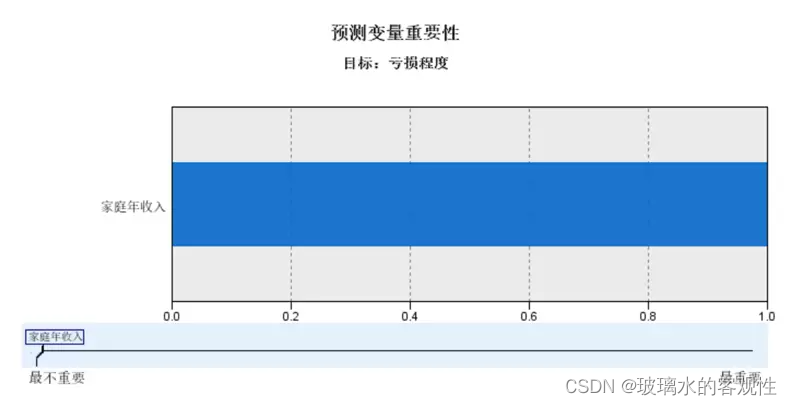
在预测变量重要性中,我们可以观察到“家庭年收入”预测变量重要性占比为100%,直接影响“亏损程度”,而其他输入变量被剔除掉。说明“家庭年收入”对于购买理财产品亏损程度的影响非常大。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2916
2916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









