







 本教程介绍了如何在 DataCamp Workspace 中使用 SQL,从上传数据集到处理 CSV 文件,再到使用内置示例数据库。教程涵盖连接到外部数据库、使用 AI 生成和解释 SQL 查询,以及在 Python 和 R 中进一步处理结果。
本教程介绍了如何在 DataCamp Workspace 中使用 SQL,从上传数据集到处理 CSV 文件,再到使用内置示例数据库。教程涵盖连接到外部数据库、使用 AI 生成和解释 SQL 查询,以及在 Python 和 R 中进一步处理结果。
DataCamp Workspace 基于 Jupyter 笔记本构建,优化体验以提高您的工作效率。
数据分析师和数据科学家的一个常见痛点是,将 Jupyter 笔记本连接到数据库并开始工作可能很棘手。对于初学者来说,这个问题可能更加严重:如果你连数据库都连接不了,如何学习编写 SQL?
Workspace 使编写 SQL 变得毫不费力 - 无论您是在练习技能还是在工作。本教程向您展示如何在几秒钟内在 Workspace 中编写 SQL。
本教程假设您以前使用过 SQL。如果您还没有,
入门
要使用 Workspace,您需要注册 DataCamp。(免费帐户就可以开始使用。)
拥有帐户后,请使用顶部导航栏转到工作区。

本教程将使用内置的 NBA 投篮数据数据集。如果您更喜欢使用自己的数据集,请跳到下面的部分。
使用左侧导航转到数据集页面。
在搜索框中输入“nba”并单击数据集。
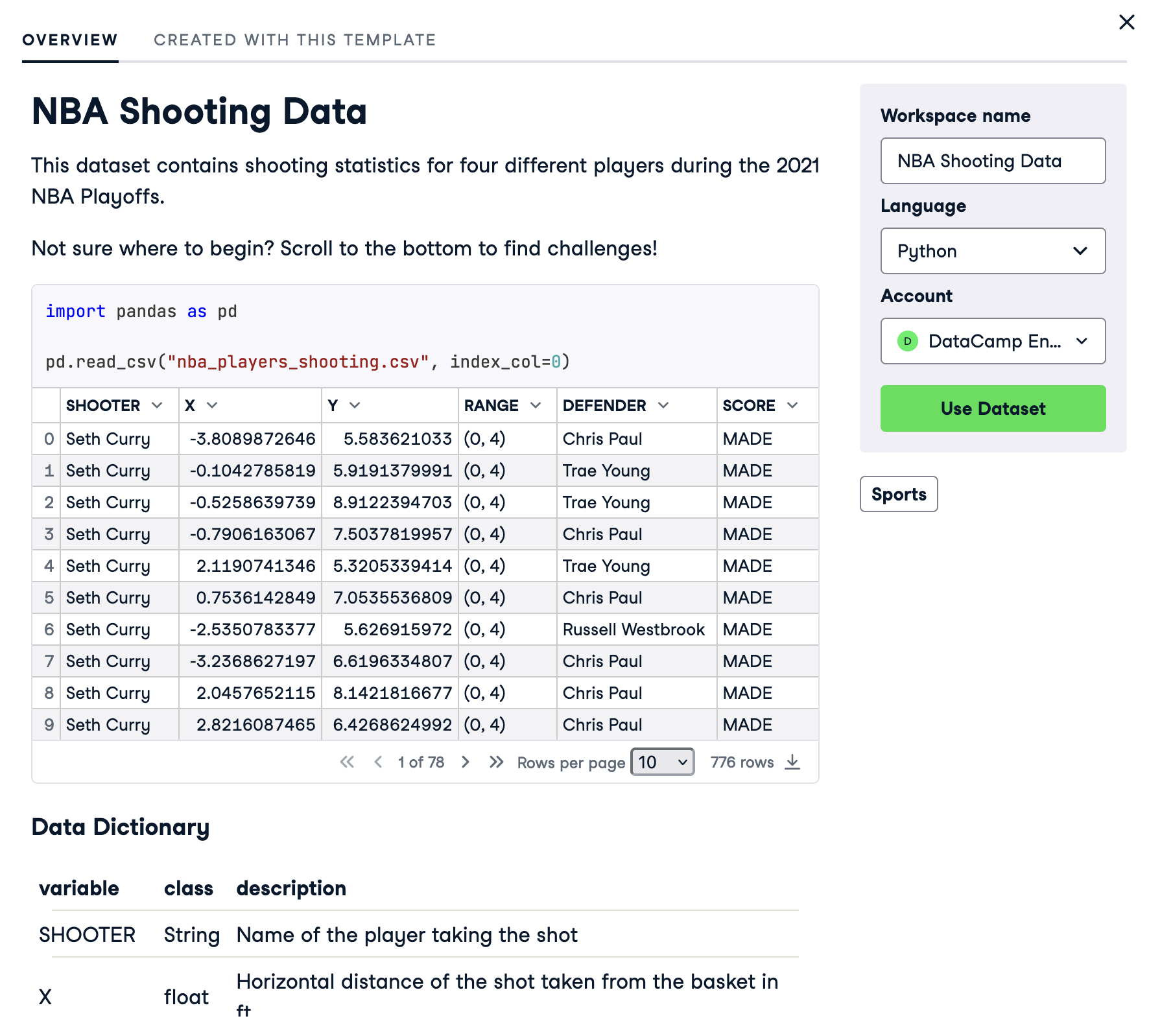
您将看到数据集的预览。通读它,然后单击“使用数据集”。
上传您自己的数据集
您可以使用 SQL 分析 Workspace 中的任何表状数据。目前,最好支持 CSV 文件,因此出于学习目的,如果您提供自己的数据集,建议使用 CSV 文件。
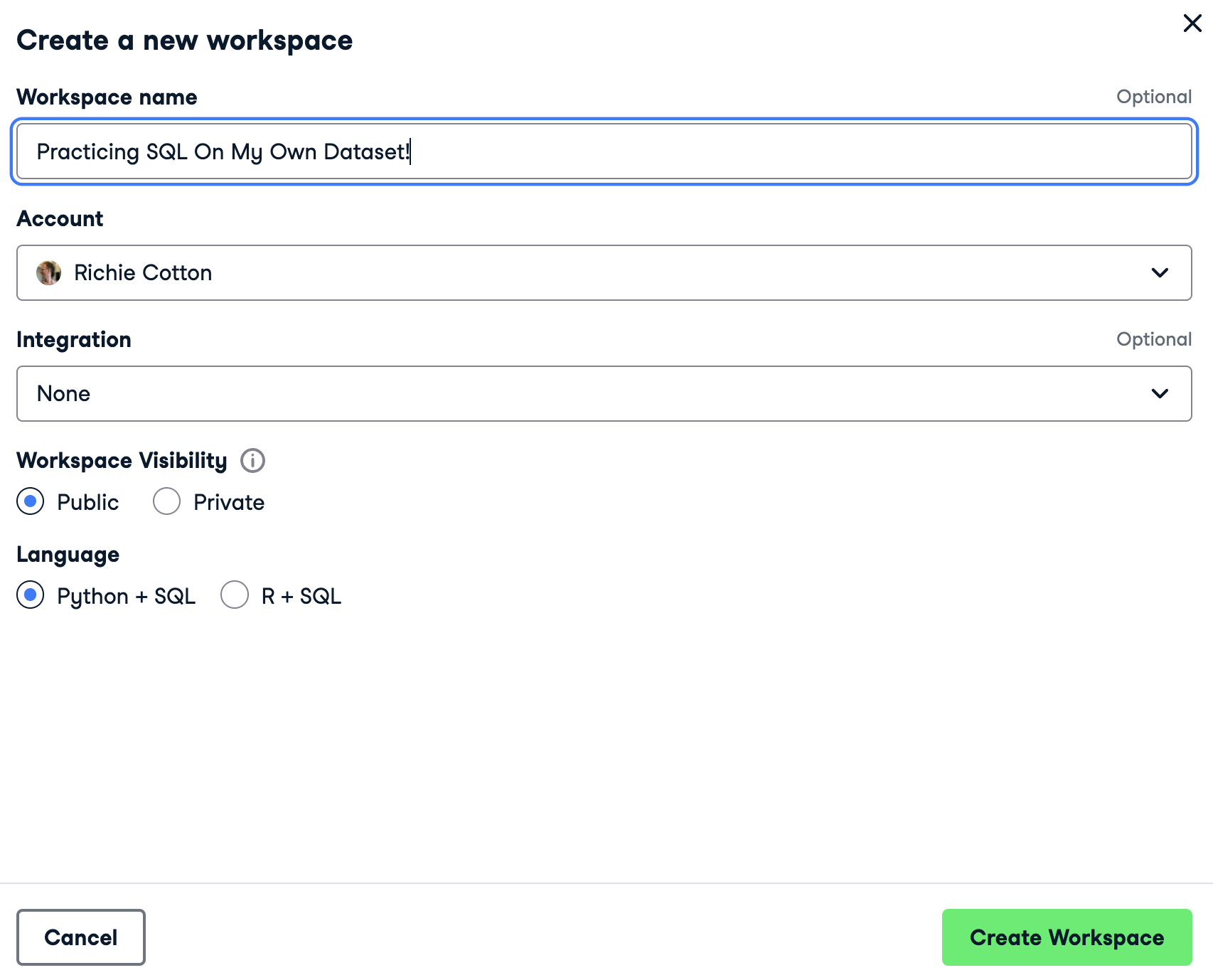
在“概述”页面中,单击“清空”以创建一个空工作区。

为您的工作区命名,然后单击“创建工作区”。
在左侧工具栏中,打开“文件”工具。
在该工具的左上角,将数据文件拖到文件窗格中进行上传。(您也可以单击“浏览文件”或单击⊕按钮然后上传)。
使用 SQL 处理 CSV 文件中的数据
NBA投篮数据在nba_players_shooting.csv文件中。在左侧工具栏中,打开“文件”工具以查看该文件。
工作区中的笔记本包含一些用于导入数据集的 Python 代码。然而,在本例中,我们想要使用 SQL。
在笔记本末尾,单击“添加 SQL”。

在“选择源”下拉列表中,选择“DataFrames 和 CSV”。
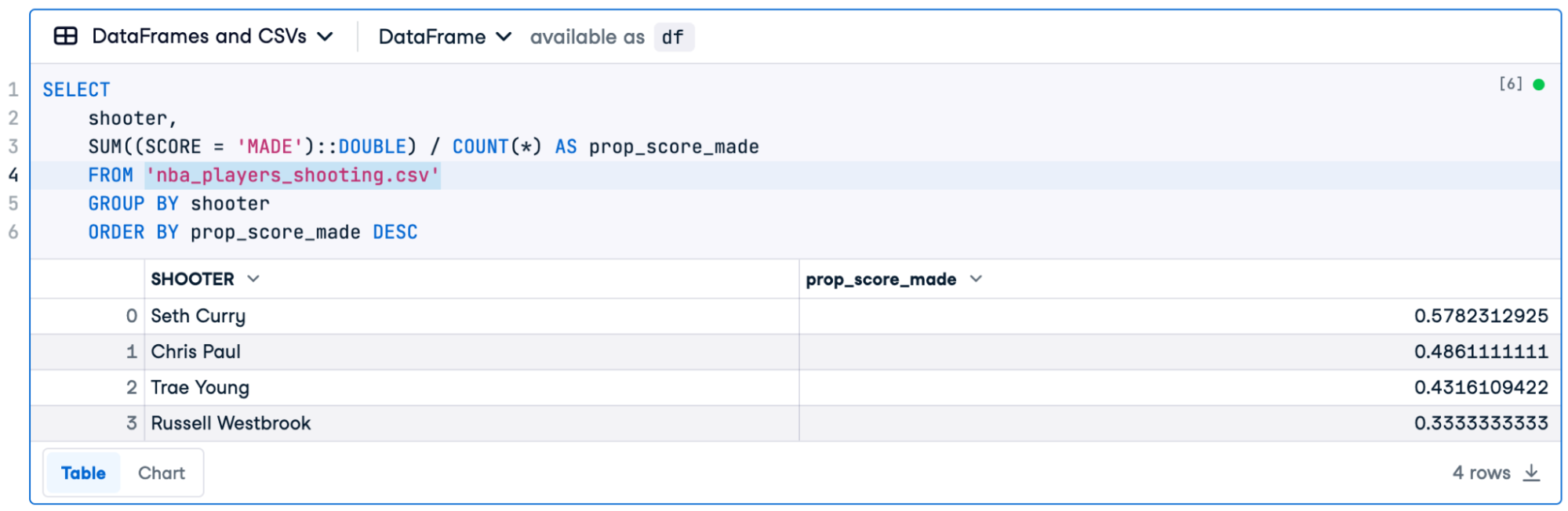
要针对 CSV 文件编写 SQL 查询,只需对标准 SQL 进行一处更改。在该FROM子句中,不要命名表,而是用单引号写入 CSV 文件的路径。
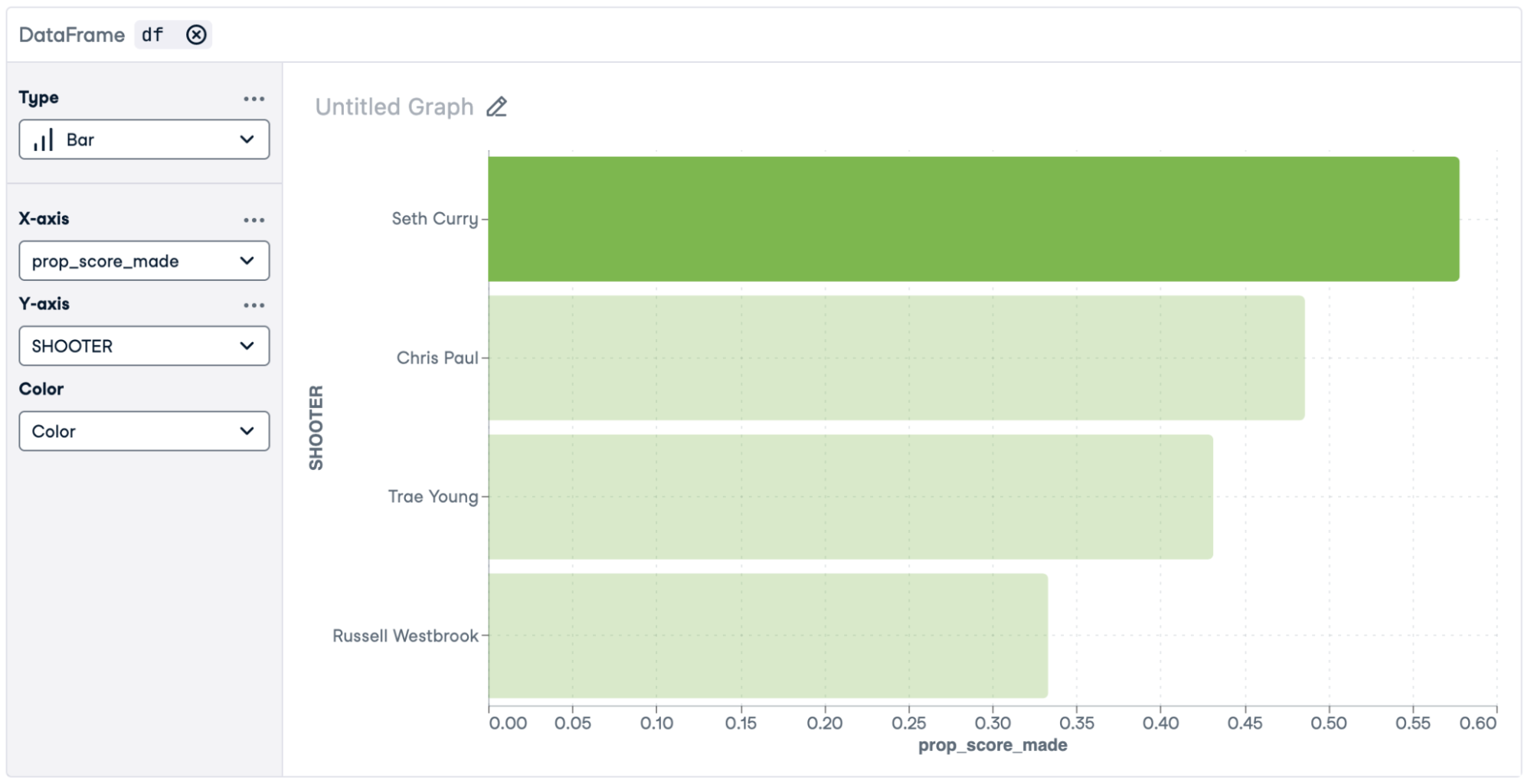
让我们按从最好到最差的顺序计算每个射手的投篮比例。在 SQL 单元中,键入以下代码。
SELECT shooter, SUM((SCORE = 'MADE')::DOUBLE) / COUNT(*) AS prop_score_made FROM 'nba_players_shooting.csv' GROUP BY shooter ORDER BY prop_score_made DESC
请注意,使用 CSV 文件时使用的 SQL 方言是 DuckDB。有关此内容的更多信息,请参阅DuckDB 让 SQL 成为 DataCamp Workspace 上的一等公民。
继续使用 Python、R 或无代码图表
在上一个示例中,我们保留查询返回格式的默认设置。仔细观察 SQL 单元的顶部,您会发现它将返回值显示为名为 的 DataFrame df。这意味着您可以继续在 Python(或在 R 中,对于 R 工作区)处理结果或绘制无代码图。

单击“添加图表”以添加无代码图表。

设置以下选项。
- 类型: 酒吧
- X 轴:prop_score_made
- Y轴:射手
对数据框中的数据使用 SQL
针对 CSV 文件运行的 SQL 查询创建了一个名为 的数据框df。您还可以针对这些 pandas 或 R 数据框编写 SQL 查询。与标准 SQL 的唯一区别是,在FROM子句中,您提供数据框名称而不是表名称。
在这里,我们将重用以前的结果df并将该列拆分shooter为单独的名字和姓氏。添加 SQL 单元,选择“DataFrames 和 CSV”作为源,然后使用以下代码。
SELECT str_split(shooter, ' ')[1] AS first_name, str_split(shooter, ' ')[2] AS last_name, prop_score_made FROM df
使用示例数据库
Workspace 还提供了多个示例数据库,您可以使用它们来练习 SQL 技能。
添加 SQL 单元,然后在源下拉列表中向下滚动到“示例集成”部分。在这里,我们将使用“自行车销售”。
将出现默认查询。对于本教程,我们将其替换为更简单的查询。
SELECT
product_name,
MIN(list_price) AS cheapest_list_price
FROM products
GROUP BY product_name
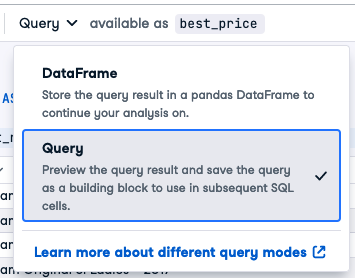
当您使用数据库连接(而不是针对 CSV 文件或数据帧编写 SQL)时,您可以选择将结果作为查询返回。在下拉列表中,选择“查询”。您还可以命名结果值。在这里,将“query”更改为“best_price”。
运行查询会给出以下输出。

您现在可以使用此结果来编写进一步的 SQL,而无需使用公用表表达式语法。
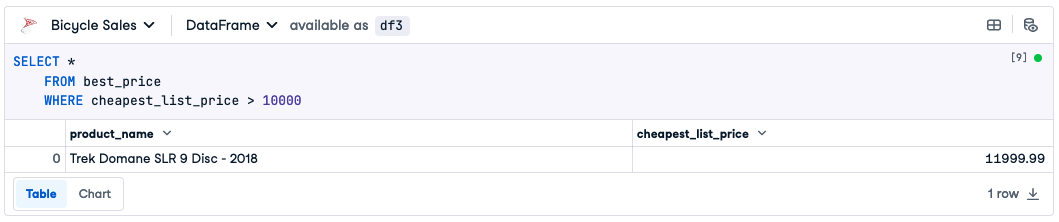
添加另一个 SQL 单元,并编写进一步的查询。
SELECT * FROM best_price WHERE cheapest_list_price > 10000
运行此查询将返回以下结果。
连接到其他数据库
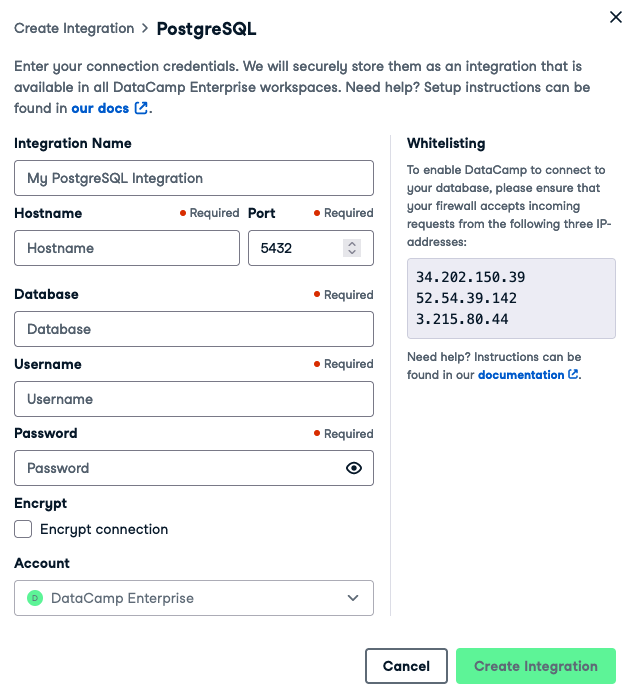
Workspace 还允许您连接到多种类型的数据库,包括 PostgreSQL、MySQL、Redshift、bigQuery、Athena、SQL Server、MariaDB 和 Oracle 数据库。Workspace 文档中提供了有关如何连接的完整详细信息。
在左侧工具栏中,单击“集成”,然后单击 ⊕ 按钮创建新集成。
选择您要连接的数据库类型。

系统会要求您提供连接详细信息(这些详细信息因数据库类型而异)。
使用人工智能助手
虽然编写 SQL 既有趣又有用,但让 AI 为您编写 SQL 可以帮助您学习并提高工作效率。
添加 SQL 单元。在右侧上下文菜单中,单击“生成”。
SQL 单元顶部会出现一个文本框。在此,为 AI 编写一个任务。选择您自己的任务,或尝试以下操作。
Return the product names and list prices for all mountain bikes made by Trek that are in stock.
输入查询后,按 Enter 键让 AI 生成 SQL 代码。
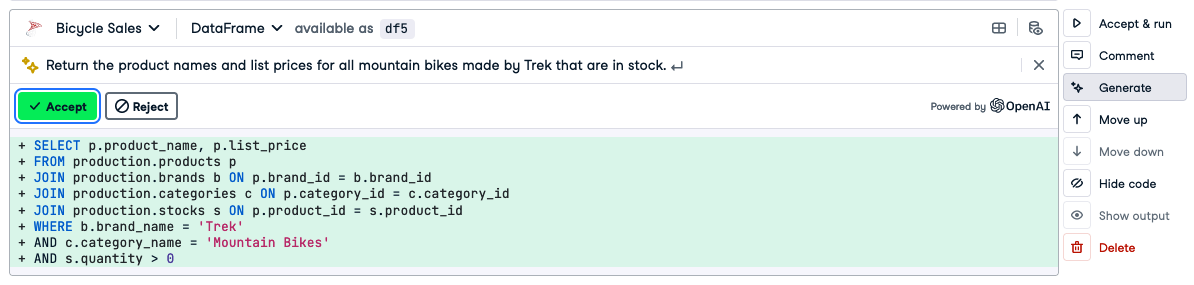
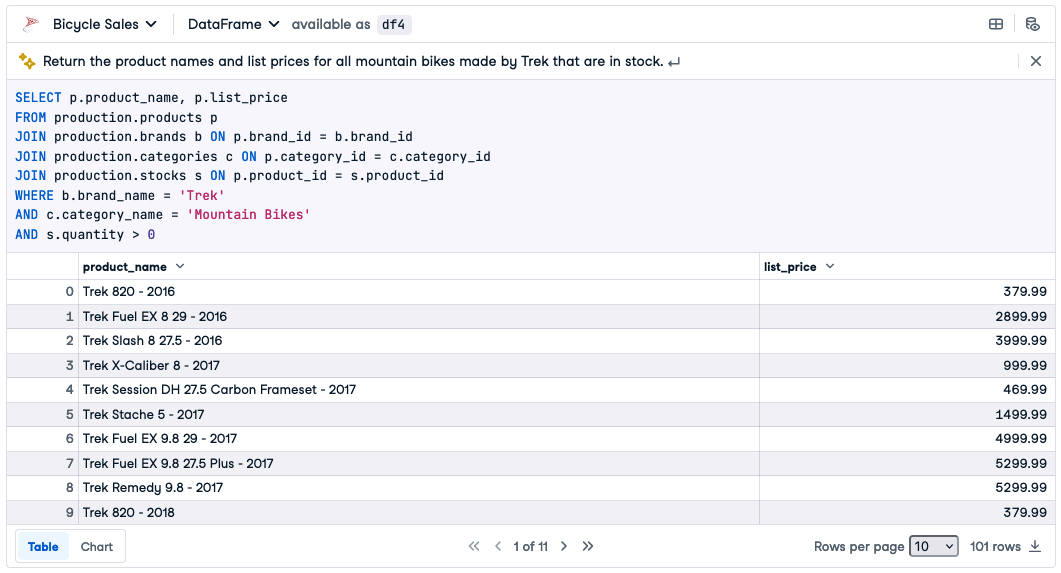
如果您认为代码合理,请单击“接受并运行”(或单击“接受”,然后单击“运行”)以查看查询结果。
让人工智能来解释你的错误
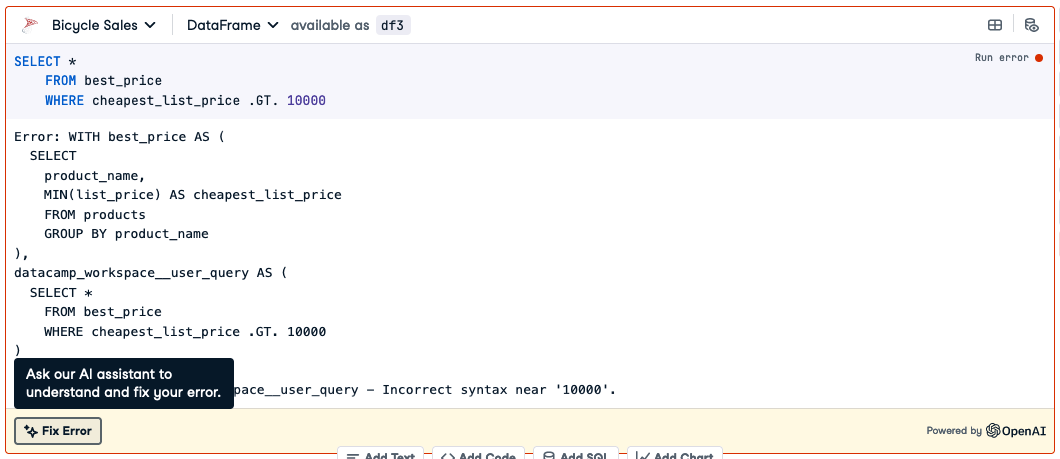
您还可以使用 Workspace 内置的 AI 来解释 SQL 中出现错误的原因。假设您在编写昂贵自行车的查询时感到困惑并使用了 Fortran 风格的.GT. 而不是`>`。
SELECT * FROM best_price WHERE cheapest_list_price .GT. 10000
这会导致错误。在 SQL 单元格的左下角,单击“修复错误”。
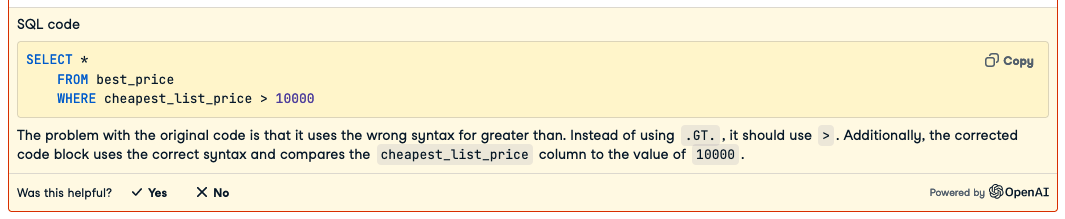
AI 提供正确的代码,然后解释你做错了什么。
概括
您已经了解了如何通过针对 CSV 文件和数据框编写 SQL 查询来避免设置数据库。您使用示例数据库来练习编写代码。您还了解了如何使用 AI 用自然语言生成 SQL 并修复错误。
这些功能使您可以更轻松地开始编写 SQL,并在学习和工作时提高工作效率。


















 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











