







一 K—近邻分类
K—近邻算法是一种基于实例的非参数的分类方法。其作用原理是计算每个训练样例到待分类样品间的距离,取和待分类样品距离最近的看k个训练样例,k个样品中那个类别的训练样例占多数,则待分类元组就属于该类。
2.1 K-NN算法具体步骤
- 初始化距离为最大值;
- 计算未知样本和每个训练样本的距离dist;
- 得到目前k个最临近样本中的最大距离maxdist;
- 如果dist小于maxdist,则将该训练样本作为K-近邻样本;
- 重复步骤2、3、4,直到未知样本和所有训练样本的距离都计算完;
- 统计k个最近邻样本中每个类别出现的次数;
- 选择出现频率最大的类别作为未知样本中每个类别出现的次数。
2.2 编写程序
数据的预处理
clc,clear all,close all;
load F:\MATLAB_test\bank.mat
names=bank.Properties.VariableNames;
提取表格中的数据并将bank文件中的属性名称给names;
category=varfun(@iscellstr,bank,'Output','uniform');
for i=find(category) %找到非零元素的索引向量
bank.(names{i})=categorical(bank.(names{i})); %建立分类数组
end
catPred=category(1:end-1);
rng('default'); %产生随机数,方式为default
figure(1)
gscatter(bank.balance,bank.duration,bank.y,'br','xo')
xlabel('年平均余额/万元','fontsize',12)
ylabel('上次接触时间/秒','fontsize',12)
title('数据可视化效果','fontsize',12)
set(gca,'linewidth',2)
处理数据,将字符串与数组分类处理。并将余额以及接触时间作为对顾客是否愿意购买新产品的重要标准建立可视化图;
X=table2array(varfun(@double,bank(:,1:end-1)));
Y=bank.y;
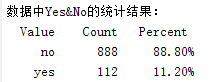
disp('数据中Yes&No的统计结果:')
tabulate(Y)
XNum=[X(:,~catPred) dummyvar(X(:,catPred))];
YNum=double(Y)-1;
将字符串转化为数组,并将X中的数据数组为虚拟变量方便后续处理;
结果如下:
|
|
|

cv=cvpartition(height(bank),'holdout',0.58);%创建交叉验证分区
Xtrain=X(training(cv),:);
Ytrain=Y(training(cv),:);
XtrainNum=XNum(training(cv),:);
YtrainNum=YNum(training(cv),:);Xtest=X(test(cv),:);
Ytest=Y(test(cv),:);
XtestNum=XNum(test(cv),:);
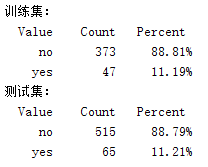
YtestNum=YNum(test(cv),:);disp('训练集:')
tabulate(Ytrain)
disp('测试集:')
tabulate(Ytest)
交叉验证分区中选择58%的样本作为测试样本,可以很大程度上使得测试结果接近总体水准。(不同总体样本大小所选的测试样本比例不同)
结果如下:
knn=ClassificationKNN.fit(Xtrain,Ytrain,'Distance','seuclidean','NumNeighbors',5);
[Y_knn,Yscore_knn,Cost]=knn.predict(Xtest);
Yscore_knn=Yscore_knn(:,2);
disp('最近邻方法分类结果:')
C_knn=confusionmat(Ytest,Y_knn)
训练K-NN分类器后,通过混淆矩阵计算出结果:

K-NN分类只与极少量相邻样本有关,可以避免样本不平衡问题。但是,只适合样本不大的情况,由于计算量大可以对样本进行剪辑,去除作用不大的样本,或者对样本分类整理计算样本领域小范围内的数据。
???
kk=training(cv);
ka=Y(training(cv),:);
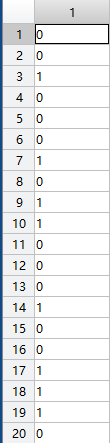 | 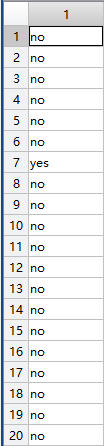 |
| kk | ka |
通过图可以看出kk的值是逻辑值0和1,而ka表示的是元包中的字符串。trainning发生了变化。或者可以理解为在用cvpartition中返回的training和test直接表示数组时作为逻辑量,但是在数组中作为间接量时返回的是数组的指针。
seuclidean—标准化欧式距离
首先将所计算的数据X进行标准化:
mean:表示数据的均值;
std:表示数据的标准差。
计算标准化欧式距离:
将已知的两个N维向量X(x11,x12,x13,……,x1n)和Y(y21,y22,y23,……,y2n),公式如下:
:表示对应标准差。
[1]卓金武,王鸿钧等,《MATLAB数学建模方法与实践》(第三版)















 3775
3775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









