






一、程序结构
1. 模块Module
1.1 定义
包含一系列数据、函数、类的文件,通常以.py结尾
1.2 作用
让一些相关的数据,函数,类有逻辑的组织在一起,使逻辑结构更加清晰。
有利于多人合作开发。
1.3 导入
1.3.1 import
(1)语法
import 模块名
import 模块名 as 别名
(2) 作用
将其他模块导入到本模块中
(3) 使用
模块名.成员
1.3.2 from import
(1)语法
from 模块 import 成员名
from 模块 import 成员名 as 别名
from 模块 import * ----将模块中的所有成员都导入到当前模块中
(2) 作用
将模块内的成员导入到当前模块作用域中
(3) 使用
直接使用成员名
1.3.3 两种导入方式的区别
第一种导入方式:适合面向过程(函数、变量)
第二种导入方式:适合面向对象(类)
1.4 模块变量
__name__变量:模块自身名字,可以判断是否为主模块。
当前模块是主模块时:__name__ = __main__
当前模块是被导入模块时:__name__ = 模块名
1.5 加载过程
在模块导入时,模块的所有语句都会执行
如果一个模块已经导入,再次执行模块时不会执行模块内的语句
1.6 分类
(1)内置模块:在解释器的内部 可以直接使用,无需导入
(2)标准库模块:安装Python时自带,导入后使用
(3)第三方模块:通常是开源,需要自己安装,导入后使用
(4)自己编写的模块:可以作为其他人的第三方模块,自定义后导入使用
'''
标准库模块
'''
import time
#人类时间:2024年5月9日
#---时间元组(年,月,日,时,分,秒,星期,年的第几天,夏令时)
tupletime = time.localtime()
print(time.localtime()[0:3])
#机器时间:1970年到现在经过的秒数--时间戳
print(time.time())
#记录时间是用时间元组还是时间戳? ---时间戳
#时间戳-->时间元组
print(time.localtime(1715216789.165719))
#时间元组-->时间戳,转换的时候会有精度的丢失
print(time.mktime(tupletime))
#时间格式化处理
#时间元组-->字符串
#语法:t = time.strftime(格式,字符串)
t1 = time.strftime("%y/%m/%d %H:%M:%S",tupletime)
t2 = time.strftime("%Y/%m/%d %H:%M:%S",tupletime)
t3 = time.strftime("%Y年%m月%d日 %H:%M:%S",tupletime)
print(t1)
print(t2)
print(t3)
#字符串-->时间元组
#语法:t = time.strptime(字符串,格式)
t = time.strptime("2024年 09秒","%Y年 %S秒")
print(t)
2.包package
2.1 定义
将模块以文件夹的形式进行分组管理。
根目录
主模块
包
模块
类
函数
语句
2.2 作用
让一些相关的模块组织在一起,使逻辑结构更加清晰。
2.3 导入
2.3.1 import
(1) 语法:
import 路径.模块名
import 路径.模块名 as 别名
(2) 作用:将模块整体导入到当前模块中
(3) 使用:模块名.成员
2.3.2 from import
(1) 语法:
from 路径.模块名 import 成员名
from 路径.模块名 import 成员名 as 别名
from 路径.模块名 import *
(2) 作用:将模块内的成员导入到当前模块作用域中
(3) 使用:直接使用成员名
注意:路径从项目根目录开始计算
二、异常处理
1.异常
(1) 定义:运行时检测到的错误。
(2) 现象:当异常发生时,程序不会再向下执行,而转到函数的调用语句。
(3) 常见异常类型:
-- 名称异常(NameError):变量未定义。
-- 类型异常(TypeError):不同类型数据进行运算。
-- 索引异常(IndexError):超出索引范围。
-- 属性异常(AttributeError):对象没有对应名称的属性。
-- 键异常(KeyError):没有对应名称的键。
-- 异常基类Exception。
2.处理
'''
异常处理:
适用性:不处理语法错误,而是针对逻辑错误(往往因为数据超过有效范围导致的)
'''
#语法1:包治百病
def div(count):
try:
i = int(input("人数:"))
re = count/i
print(re)
except:
print("程序出错了")
#div(1)
#语法2:对症下药
def div1(count):
try:
i = int(input("人数:"))
re = count/i
print(re)
except ZeroDivisionError:
print("程序出错了,输入非整数")
#div1(1)
#语法3:无论对错都必须执行的逻辑
def div2(count):
try:
i = int(input("人数:"))
re = count/i
print(re)
finally:
print("无论对错都必须执行的逻辑")
div2(1)异常处理价值:让程序按照既定的流程执行,不紊乱
三、迭代
每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。例如:循环获取容器中的元素。
1.可迭代对象
(1) 定义:具有__iter__函数的对象,可以返回迭代器对象。
(2) 语法
# 创建:
class 可迭代对象名称:
def __iter__(self):
return 迭代器
# 使用:
for 变量名 in 可迭代对象:
语句(3) 原理:
迭代器 = 可迭代对象.__iter__()
while True:
try:
print(迭代器.__next__())
except StopIteration:
break2.迭代器对象iterator
(1) 定义:可以被next()函数调用并返回下一个值的对象。
(2) 语法
class 迭代器类名:
def __init__(self, 聚合对象):
self.聚合对象= 聚合对象
def __next__(self):
if 没有元素:
raise StopIteration()
return 聚合对象元素(3) 说明:聚合对象通常是容器对象。
(4) 作用:使用者只需通过一种方式,便可简洁明了的获取聚合对象中各个元素,而又无需了解其内部结构。
(5) 演示:
'''遍历商品控制器'''
class CommdityController:
def __init__(self):
self.commdity_list = []
def add_commdity(self, commdity):
self.commdity_list.append(commdity)
def __iter__(self):
return CommdityIteration(self.commdity_list)
class CommdityIteration():
def __init__(self, data):
self.data = data
self.index = -1
def __next__(self):
self.index += 1
if self.index == len(self.data):
raise StopIteration() #发送异常
return self.data[self.index]
controller = CommdityController()
controller.add_commdity("屠龙剑")
controller.add_commdity("倚天剑")
controller.add_commdity("芭比娃娃")
'''for item in controller:
print(item)'''
iterator = controller.__iter__()
while True:
try:
item = iterator.__next__()
print(item)
except StopIteration:
break四、生成器generator
(1) 定义:能够动态(循环一次计算一次返回一次)提供数据的可迭代对象。
(2) 作用:在循环过程中,按照某种算法推算数据,不必创建容器存储完整的结果,从而节省内存空间。数据量越大,优势越明显。以上作用也称之为延迟操作或惰性操作,通俗的讲就是在需要的时候才计算结果,而不是一次构建出所有结果。
4.1 生成器函数
(1) 定义:含有yield语句的函数,返回值为生成器对象。
(2) 语法
# 创建:
def 函数名():
…
yield 数据
…
# 调用:
for 变量名 in 函数名():
语句(3) 说明:
-- 调用生成器函数将返回一个生成器对象,不执行函数体。
-- yield翻译为”产生”或”生成”
(4) 执行过程:
a. 调用生成器函数会自动创建迭代器对象。
b. 调用迭代器对象的next()方法时才执行生成器函数。
c. 每次执行到yield语句时返回数据,暂时离开。
d. 待下次调用next()方法时继续从离开处继续执行。
(5) 原理:生成迭代器对象的大致规则如下
a. 将yield关键字以前的代码放在next方法中。
b. 将yield关键字后面的数据作为next方法的返回值。
def my_range(stop):
number = 0
while number < stop:
yield number
number += 1
for number in my_range(5):
print(number) # 0 1 2 3 44.2内置生成器
4.2.1 枚举函数enumerate
(1)语法
for快捷键
iter + 回车 :for in list01:
itere + 回车: for i, in enumerate(list01):
for 变量 in enumerate(可迭代对象):
语句
for 索引, 元素in enumerate(可迭代对象):
语句(2) 作用:遍历可迭代对象时,可以将索引与元素组合为一个元组。
(3) 演示
list01 = [43, 43, 54, 56, 76]
# 从头到尾读 -- 读取数据
for item in list01:
print(item)
# 非从头到尾读 -- 修改数据
for i in range(len(list01)):
if list01[i] % 2 == 0:
list01[i] += 1
for i, item in enumerate(list01): # -- 读写数据
if item % 2 == 0:
list01[i] += 14.2.2 zip
(1) 语法:
for item in zip(可迭代对象1, 可迭代对象2):
语句(2) 作用:将多个可迭代对象中对应的元素组合成一个个元组,生成的元组个数由最小的可迭代对象决定。
(3) 演示:
list_name = ["悟空", "八戒", "沙僧"]
list_age = [22, 26, 25]
# for 变量 in zip(可迭代对象1,可迭代对象2)
for item in zip(list_name, list_age):
print(item)
# ('悟空', 22)
# ('八戒', 26)
# ('沙僧', 25)
# 应用:矩阵转置
map = [
[2, 0, 0, 2],
[4, 2, 0, 2],
[2, 4, 2, 4],
[0, 4, 0, 4]
]
# new_map = []
# for item in zip(map[0],map[1],map[2],map[3]):
# new_map.append(list(item))
# print(new_map)
# new_map = []
# for item in zip(*map):
# new_map.append(list(item))
new_map = [list(item) for item in zip(*map)]
print(new_map)
# [[2, 4, 2, 0], [0, 2, 4, 4], [0, 0, 2, 0], [2, 2, 4, 4]]'''练习:将两个列表合并为一个字典'''
list_student_name = ["悟空", "八戒", "白骨精"]
list_student_age = [28, 25, 36]
'''dict = {}
for item in zip(list_student_name,list_student_age):
dict[item[0]] = item[1]
print(dict)'''
'''字典推导式'''
dict_result = {item[0] : item[1] for item in zip(list_student_name,list_student_age) }
print(dict_result)
dict_rest = dict(zip(list_student_name,list_student_age))
print(dict_rest)
4.3 生成器表达式
(1) 定义:用推导式形式创建生成器对象。
(2) 语法
变量 = (表达式 for 变量 in 可迭代对象 if 条件)五.函数式编程
(1) 定义:用一系列函数解决问题。
-- 函数可以赋值给变量,赋值后变量绑定函数。
-- 允许将函数作为参数传入另一个函数。
-- 允许函数返回一个函数。
(2) 高阶函数:将函数作为参数或返回值的函数。
5.1 函数作为参数
'''
函数式编程思想
分:将变化点单独定义在函数中
适用性:多个函数主体结构相同,核心算法不同
隔:使用参数隔离变化点和不变
好在哪?
'''
list01 = [40,5,60,7,87,89]
'''变化点函数'''
def condition01(item):
return item > 50
def condition02(item):
return item < 10
'''通用函数'''
def find_single(condition):
for item in list01:
#if condition02(item):
if condition(item):
return item
a = find_single(condition02)
print(a)
练习1
定义函数,在列表中查找第一个奇数
定义函数,在列表中查找第一个能被3或5整除的数字
练习1:
需求:
定义函数,在列表中查找第一个奇数
定义函数,在列表中查找第一个能被3或5整除的数字
'''
list01 = [40,5,60,7,87,89]
def fun(condition):
for item in list01:
if condition(item):
return item
def condition01(item):
return item % 2 != 0
def condition02(item):
return item % 3 == 0 or item % 5 == 0
print(fun(condition01))
print(fun(condition02))练习2:
定义函数,在员工列表中查找所有部门是9001的员工
定义函数,在员工列表中查找所有姓名是2个字的员工
练习2:
需求:
定义函数,在员工列表中查找所有部门是9001的员工
定义函数,在员工列表中查找所有姓名是2个字的员工
'''
class Employee:
def __init__(self, eid, did, name, money):
self.eid = eid # 员工编号
self.did = did # 员工编号
self.name = name # 员工编号
self.money = money # 员工编号
def __str__(self):
return f'员工编号是:{self.eid},部门是{self.did},姓名是{self.name},薪资是{self.money}'
def __repr__(self):
return 'Employee(%s,%s,%s,%s)'%(self.eid,self.did,self.name,self.money)
list_employees = [
Employee(1001, 9002, "师父", 60000),
Employee(1002, 9001, "孙悟空", 50000),
Employee(1003, 9002, "猪八戒", 20000),
Employee(1004, 9001, "沙僧", 30000),
Employee(1005, 9001, "小白龙", 15000),
]
def condtion01(employe):
return len(employe.name) == 2
def condtion02(employe:Employee): #employe:Employee 类型标注
return employe.did== 9001
def find_all(condtion):
'''
:param condtion: 函数类型,查找条件
:return: 生成器对象,推算所有满足条件的元素
'''
for employe in list_employees:
if condtion(employe):
yield employe
for item in find_all(condtion01):
print(item)
print(list(find_all(condtion01)))5.1.1 lambda 表达式
(1) 定义:是一种匿名方法
(2) 作用:
-- 作为参数传递时语法简洁,优雅,代码可读性强。
-- 随时创建和销毁,减少程序耦合度。
(3) 语法
# 定义:
变量 = lambda 形参: 方法体
# 调用:
变量(实参)(4) 说明:
-- 形参没有可以不填
-- 方法体只能有一条语句,且不支持赋值语句。
'''
lambda匿名函数
lambda能完成的功能,def都可以完成
但是lambda只能有一条语句,且不能是赋值语句
lambda函数的应用
——作为高阶函数的实参
'''
#1.有参数有返回值
func01 = lambda p1,p2 : p1>p2
print(func01(1,2))
#2.无参数有返回值
func02 = lambda :250
print(func02())
#3.无参数无返回值
func03 = lambda :print("helloword")
func03()
# 4.有参数无返回值
func04 = lambda p:print("参数是:",p)
func04(3)
#注意1 lambda不支持多条语句
def func05():
for item in range(10):
print(item)
#注意2:不能是赋值语句
def func06(p):
p[0] = 200
list = [10]
func06(list)
print(list[0])
# lambda p:p[0] = 200练习
'''
作业
1. 当天练习独立完成
2. 使用IterableHelper实现下列功能
-- 在商品列表,获取所有名称与单价
-- 在商品列表中,获取所有单价小于10000的商品
-- 在商品列表中,累加所有商品单价
-- 在商品列表中,删除编号是1002的商品
-- 在商品列表中,删除所有单价小于100的商品
-- 在商品列表中,查找“金箍棒”商品对象
'''
from IterableTools import IterableHelper
class Commodity:
def __init__(self, cid=0, name="", price=0):
self.cid = cid
self.name = name
self.price = price
def __repr__(self):
return f'Commodity(cid={self.cid},name={self.name}, price={self.price})'
list_commodity_infos = [
Commodity(1001, "屠龙刀", 10000),
Commodity(1002, "倚天剑", 10000),
Commodity(1003, "金箍棒", 52100),
Commodity(1004, "口罩", 20),
Commodity(1005, "酒精", 30),
]
print(list(IterableHelper.get_info(list_commodity_infos,lambda c:(c.name,c.price))))
print(list(IterableHelper.select(list_commodity_infos,lambda c:c.price<10000)))
print(IterableHelper.sum(list_commodity_infos,lambda c:c.price))
#print(IterableHelper.sum(list_commodity_infos,lambda c:c.cid == 1002))
#print(IterableHelper.sum(list_commodity_infos,lambda c:c.price < 100))
print(list(IterableHelper.select(list_commodity_infos,lambda c:c.name == "金箍棒")))'''可迭代对象工具集'''
class IterableHelper:
''''''
@staticmethod
def get_info(iterate,condition):
for item in iterate:
'''根据条件,获取商品的指定信息'''
yield condition(item)
@staticmethod
def select(iterate,condition):
'''根据条件筛选指定的商品'''
for item in iterate:
if condition(item):
yield item
@staticmethod
def sum(iterate,condition):
'''根据条件,进行累加'''
sum = 0
for item in iterate:
sum += condition(item)
return sum
def delete(iterate,condition):
'''根据条件,进行删除'''
count = 0
for i in range(len(iterate)-1,-1,-1):
if condition(iterate[i]):
del iterate[i]
count+=1
return count
'''
1.找出money最大的和eid最大的
2.根据工资和部门编号对员工进行升序排序
3.判断员工列表中是否存在相同的编号、工资
'''
class Employee:
def __init__(self, eid, did, name, money):
self.eid = eid # 员工编号
self.did = did # 部门编号
self.name = name
self.money = money
def __repr__(self):
return f"Employee(eid={self.eid}, did={self.did}, name={self.name}, money={self.money})"
def __gt__(self, other):
return self.money >other.money
# 员工列表
list_employees = [
Employee(1001, 9002, "师父", 60000),
Employee(1002, 9001, "孙悟空", 50000),
Employee(1003, 9002, "猪八戒", 20000),
Employee(1004, 9001, "沙僧", 30000),
Employee(1005, 9001, "小白龙", 15000),
]
def get_max(condition):
'''
:param condition:
:return:
'''
max_employe = list_employees[0]
for employe in list_employees:
if condition(employe)>condition(max_employe):
max_employe = employe
return max_employe
def sort_employe(condition):
for i in range(len(list_employees)-1):
for j in range(i+1,len(list_employees)):
#if list_employees[i].money > list_employees[j].money:
if condition(list_employees[i])> condition(list_employees[j]):
list_employees[i],list_employees[j] = list_employees[j],list_employees[i]
def is_repeat(condition):
for i in range(len(list_employees) - 1):
for j in range(i + 1, len(list_employees)):
if condition(list_employees[i]) == condition(list_employees[j]):
return True
return False
#sort_employe(lambda e:e.money)
#sort_employe(lambda e:e.did)
print(is_repeat(lambda e:e.money))
print(is_repeat(lambda e:e.did))
5.1.2内置高阶函数
(1) map(函数,可迭代对象):使用可迭代对象中的每个元素调用函数,将返回值作为新可迭代对象元素;返回值为新可迭代对象。
(2) filter(函数,可迭代对象):根据条件筛选可迭代对象中的元素,返回值为新可迭代对象。
(3) sorted(可迭代对象,key = 函数,reverse = bool值):排序,返回值为排序结果。
(4) max(可迭代对象,key = 函数):根据函数获取可迭代对象的最大值。
(5) min(可迭代对象,key = 函数):根据函数获取可迭代对象的最小值。
从性能角度:内置高阶函数性能更好
class Employee:
def __init__(self, eid, did, name, money):
self.eid = eid # 员工编号
self.did = did # 部门编号
self.name = name
self.money = money
def __repr__(self):
return f"Employee(eid={self.eid}, did={self.did}, name={self.name}, money={self.money})"
def __gt__(self, other):
return self.money >other.money
# 员工列表
list_employees = [
Employee(1001, 9002, "师父", 60000),
Employee(1002, 9001, "孙悟空", 50000),
Employee(1003, 9002, "猪八戒", 20000),
Employee(1004, 9001, "沙僧", 30000),
Employee(1005, 9001, "小白龙", 15000),
]
print(list(map(lambda e:e.name,list_employees)))
print(list(filter(lambda e:e.did == 9001,list_employees)))
print(max(list_employees,key=lambda e:e.money))
#升序
list_employees.sort(key=lambda e:e.did)
#降序
list_employees.sort(key=lambda e:e.did,reverse=True)
print(list_employees)
#排序,返回新列表,不改变旧列表
new_list = sorted(list_employees,key=lambda e:e.did)
dict01 = {'a':1,'c':2,'b':3}
print(sorted(dict01))
print(dict(sorted(dict01.items(),key=lambda item:item[1])))5.2 函数作为返回值
5.2.1闭包函数
(1)三要素
- 必须有一个内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数返回值必须是内嵌函数
(2)语法
# 定义:
def 外部函数名(参数):
外部变量
def 内部函数名(参数):
使用外部变量
return 内部函数名
# 调用:
变量 = 外部函数名(参数)
变量(参数)(3) 定义:是由函数及其相关的引用环境组合而成的实体。
(4) 优点:内部函数可以使用外部变量。
(5) 缺点:外部变量一直存在于内存中,不会在调用结束后释放,占用内存。
(6) 作用:实现python装饰器。
def give_gife_money(money):
print("获得", money, "元压岁钱")
def child_buy(commodity, price):
nonlocal money
money -= price
print("购买了", commodity, "花了", price, "元,还剩下", money)
return child_buy
action = give_gife_money(500)
action("变形金刚", 200)
action("芭比娃娃", 300)5.2.2函数装饰器decorator
(1)定义:在不改变原函数的调用以及内部代码情况下,为其添加新功能
(2)语法:
def 函数装饰器名称(func):
def wrapper(*args,**kwargs):
需要添加的新功能
res = func(*args,**kwargs)
return res
return wrapper
@函数装饰器名称
def 原函数名称(参数):
函数体
原函数(参数)(3)本质:
使用“@函数装饰器名称”修饰原函数,等于创建与原函数相同名称的变量,关联内嵌函数;故调用原函数时执行内嵌函数
原函数名称 = 函数装饰器名称(原函数名称)
(4)装饰器链:
一个函数可以被多个装饰器修饰,执行顺序为从近到远。
'''
装饰器--原理
在不改变旧功能定义与调用的情况下,为其增加新功能
闭包:
有外有内:
外函数负责接收旧功能
内函数负责包装新旧功能
内使用外:
需要新旧功能同时执行
外返回内:
希望在调用旧功能时执行内函数
'''
#缺点
def old_fun():
print("旧功能")
'''#缺点:新旧函数执行时机太早
def new_fun(func):
print("新功能")
func()
'''
def new_fun(func):
def wapper():
print("新功能")
func()
return wapper
old_fun = new_fun(old_fun)
old_fun()
old_fun()
'''
装饰器——标准装饰器
内函数的返回值,必须是就旧功能的返回值
'''
def new_fun(func):
# *args星号元组形参-----多合一
def wapper(*args,**kwargs):
print("新功能")
# *args星号序列形参---一拆多
res = func(*args,**kwargs)
return res
return wapper
#old_fun1 = new_fun(old_fun1) == @new_fun
@new_fun
def old_fun1(a):
print("参数是:",a)
return 100
@new_fun
def old_fun2(a,b):
print("参数是:",a,b)
return 100
@new_fun
def old_fun3(a,b,c):
print("参数是:",a,b,c)
return 100
print(old_fun1(10))
print(old_fun2(10,b=20))
print(old_fun3(10,b=20,c=30))
练习1:不改变插入函数与删除函数代码,为其增加验证权限的功能
'''
练习1:不改变插入函数与删除函数代码,为其增加验证权限的功能
'''
def verify_permissions(func):
def wrapper():
func()
print("验证权限")
return wrapper
def insert():
print("插入")
def delete():
print("删除")
insert = verify_permissions(insert)
insert = verify_permissions(insert)
#delete = verify_permissions(delete)
insert()
delete()'''
练习1:不改变插入函数与删除函数代码,为其增加验证权限的功能
'''
def verify_permissions(func):
def wrapper():
func()
print("验证权限")
return wrapper
@verify_permissions
def insert():
print("插入")
@verify_permissions
def delete():
print("删除")
insert()
delete()练习2:为sum_data,增加打印函数执行时间的功能.
函数执行时间公式: 执行后时间 - 执行前时间
'''
为sum_data,增加打印函数执行时间的功能.
函数执行时间公式: 执行后时间 - 执行前时间
def sum_data(n):
sum_value = 0
for number in range(n):
sum_value += number
return sum_value
print(sum_data(10))
print(sum_data(1000000))
'''
import time
def add(func):
def wrapper(*args,**kwargs):
start = time.time()
sum = func(*args,**kwargs)
stop = time.time()
print("执行时间:",stop-start)
return sum
return wrapper
@add
def sum_data(n):
sum_value = 0
for number in range(n):
sum_value += number
return sum_value
print(sum_data(10))
print(sum_data(1000000))
六.文件操作
6.1 文件管理
6.1.1基础概念
(1)文件
定义:保存在持久化存储设备(硬盘、U盘、光盘....)上的一段数据
例如:文本、图片、视频等
(2)路径
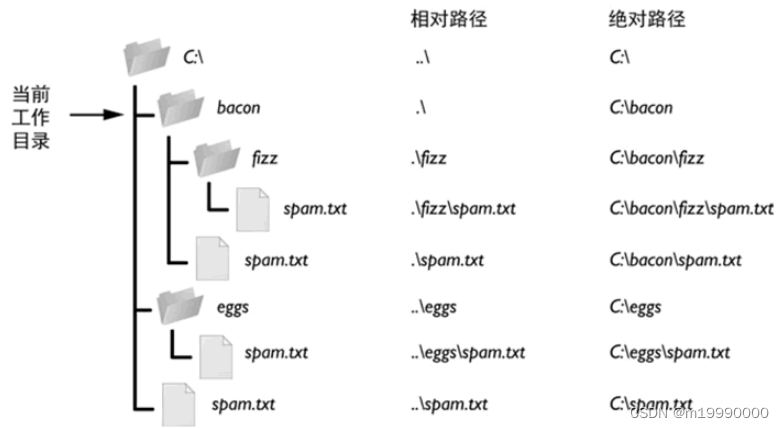
定义:对文件存储在计算机中位置的标识,除window只有反斜杠“\”以外,其他操作系统使用“/”分割
当前路径:正在执行的Python文件所在目录
绝对路径:从操作系统根目录开始,Window以盘符"C:"、"D:",OS X或Linux以斜杠"/"开始
6.1.2pathlib模块
对os模块中与文件操作相关的封装,是基于面向对象的跨平台路径操作模块pathlib --- 面向对象的文件系统路径 — Python 3.12.4 文档
'''
pathlib
'''
from pathlib import Path
print(Path.cwd().parent.joinpath("day14","demo01"))
print(Path('./demo01.py').exists())
#当前工作目录的绝对路径
print(Path.cwd())6.1.2.1创建路径
(1)语法
# 导入路径类
from pathlib import Path
# 相对路径
对象名 = Path(相对路径)
# 当前工作目录的绝对路径
对象名 = Path.cwd()
# 绝对路径 + 相对路径
对象名 = Path.cwd().joinpath("目录1","目录2")6.1.2.2路径信息
对象名.absolute() # 绝对路径(路径类型)
对象名.name # 带后缀的完整文件名(str类型)
对象名.stem # 文件名不带后缀(str类型)
对象名.suffix # 文件后缀(str类型)
对象名.parent # 上一级路径(路径类型)
对象名.parts # 分割路径(tuple类型)
对象名.exists() # 路径是否存在(bool类型)
对象名.is_file() # 是否文件(bool类型)
对象名.is_dir() # 是否目录(bool类型)
对象名.is_absolute() # 是否绝对路径(bool类型)
对象名.stat().st_ctime # 创建时间(时间戳)
对象名.stat().st_atime # 访问时间(时间戳)
对象名.stat().st_mtime # 修改的时间(时间戳)
对象名.stat().st_size # 文件大小(字节Bete)
6.1.2.3搜索目录
(1)语法
# 注意:路径对象必须是目录,不能是文件
# 搜索当前目录所有路径(一层)
生成器 = 对象名.iterdir():
# 根据通配符搜索当前目录所有路径(一层),*表示任意多个字符
# 例如:*.py表示所有Python文件
生成器 = path.glob("通配符"):
# 根据通配符递归搜索当前目录所有路径(多层)
生成器 = 对象名.rglob("通配符") ''''''
from pathlib import Path
month01 = Path.cwd().parent
#搜索当前目录所有路径
'''for item in month01.iterdir():
print(item)'''
'''#使用通配符搜索一层
for item in month01.glob("day*"):
print(item)
for item in month01.glob("day16/*"):
print(item)
for item in month01.glob("day16/*.py"):
print(item)
'''
#使用通配符搜索多层(多层递归)
for item in month01.rglob("*模块*"):
print(item)'''斐波那契数列'''
def get_fibonacci(n):
fibs = [1,1]
for __ in range(n-2):
'''for __ in range(3) 是一种常见的惯用法,用于表示一个循环,但不关心循环变量的值。
这里的双下划线 __ 只是一个命名约定,表示循环变量不会在循环体内被使用。'''
fibs.append(fibs[-1]+fibs[-2])
return fibs
print(get_fibonacci(8))
'''生成器版本'''
def get_fibonacci1(n):
num01,num02 = 1,1
yield num01
yield num02
for __ in range(n-2):
num01,num02 = num02,num01+num02
yield num02
for item in get_fibonacci1(8):
print(item)6.1.2.4新建路径
#创建文件(如果存在不创建,不存在才创建)
Path("a.txt").touch()
#创建目录(如果存在也不报错)
Path("a").mkdir(exist_ok=True)
#创建目录(如果存在报错,不存在才创建)
Path("a").mkdir()
6.1.2.5重命名
'''重命名文件名'''
Path('a.txt').rename('A.txt')
'''重命名目录中的文件名'''
#文件会从目录中移除
#Path('a','b.txt').rename('a.txt')
old = Path('a','b.txt')
#创建新文件名
new_name = old.with_name('B.txt')
old.rename(new_name)6.1.2.6删除路径
'''删除'''
'''删除文件'''
#如果文件不存在会报错
Path('A.txt').unlink()
#文件不存在也不报错
Path('A.txt').unlink(missing_ok=True)
'''删除目录'''
Path('b').mkdir(exist_ok=True)
#如果b不存在会报错,且如果目录不为空也会报错
Path('b').rmdir()
import shutil
#删除目录与内部所有文件(找不回来)
shutil.rmtree('a')6.2文件读写
读 :即从文件中获取内容
写 :即修改文件中的内容
基本步骤:打开文件,读写文件,关闭文件
6.2.1文本文件
打开后会自动解码为字符,如txt文件,py文件。
6.2.1.1打开文件
(1) 语法
对象名 = open(文件路径,"操作模式",encoding="编码方式")'''文件操作'''
'''方法一:如果操作时异常无法关闭'''
#1.打开
file = open('demo03.py','r',encoding='utf-8')
#2.操作文件
file.read()
#3.关闭文件
file.close()
'''方法二:写法麻烦'''
#1.打开
file = open('demo03.py','r',encoding='utf-8')
try:
#2.操作文件
file.read()
finally:
#3.关闭文件
file.close()
'''方法三'''
#1.打开文件
with open('demo03.py','r',encoding='utf-8') as file:
#2.操作文件
print(file.read())
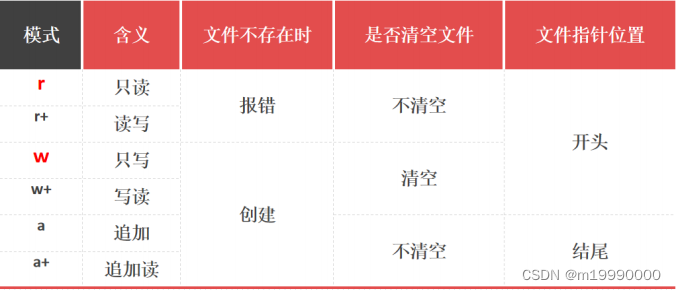
#离开缩进,解释器负责关闭文件(2) 操作模式
(3) 编码方式
Linux操作系统文本文件默认为"utf-8"
Windows操作系统文本文件默认为"gbk"
6.2.1.2读写文件
(1) 读取
# 读取文件中指定数量字符
字符串 = 对象名.read(字符数) # 省略字符数将读取至文件末尾
# 读取文件中的每行
for 行 in 对象名:
(2)写入
# 将字符串写入到文件
字符数 = 对象名.write(字符串)
6.2.1.3关闭文件
文件作为操作系统资源,打开后必须关闭,避免超出操作系统限制。
(1) close方法
对象名 = open(文件路径)
try:
操作文件对象
finally:
对象名.close()(2) with操作
对try…finally语法的简化,当with代码块全部执行完后,无论是否产生异常,都会自动释放资源
with open(文件路径) as 对象名:
通过对象名操作文件6.2.2二进制文件
内部编码为二进制,无法通过文字编码解析,如压缩包,音频,视频,图片等
6.2.2.1打开文件
(1)语法
对象名 = open(文件路径,"操作模式")
(2) 操作模式
Python内存垃圾回收机制
(1)引用计数
数据存储着变量被绑定的次数,如果为0该数据视为垃圾,等待回收
(2)标记清除
对内存空间全盘扫描,重点检测循环引用的数据,标记出不被使用的数据,等待回收
(3)分代回收
程序运行时,将内存空间分为小中大三代数据
每次创建新数据,都在小代分配空间,当内存告急时,触发"标记清除",将有用的数据升代,释放没用的数据
(4)内存优化
尽少产生垃圾
对象池优化
配置垃圾回收期器
'''
总复习
1.Python垃圾回收机制
(1)引用计数
数据存储着被变量绑定的次数
如果为0该数据视为垃圾,等待回收
(2)标记清除
对内存空间全盘扫描,重点检测循环引用的数据,标记出不被使用的数据,等待回收
(3)分代回收
程序运行时,将内存空间分为小中大三代数据
每次创建新数据,都在小代分配空间,当内存告急时,触发"标记清除",将有用的数据升代,释放没用的数据
(4)内存优化
尽少产生垃圾
对象池优化
配置垃圾回收期器
'''
data01 = 10
data02 = data01 #数据引用次数为2
del data02,data01 #数据引用次数为0
lis01 = []
lis02 = []
lis01.append(lis02)
lis02.append(lis01)
#循环引用
#虽然删除了变量,但是列表见相互引用
#由于引用计数不为0,垃圾不能回收,长期占用内存
del lis01,lis02
#对象池:创建数据时,会在池中判断是否具有相同的数据,如果有直接返回地址,没有才会开辟存储空间
#除了列表、字典和自定义对象外,其他数据类型都有对象池
#对象池可以提高内存利用率(节省内存空间)
data05 = 10
data06 =10
print(id(data05),id(data06))














 4046
4046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









