






文章目录
一、环境配置
1、查询版本
//查询cuda版本(cmd)
nvcc -V 或 nvcc --version
//查询python版本(cmd)
python
//查询cuda可安装版本版本(cmd)
nvidia-smi // CUDA Version后显示的就是
2.安装环境
1.安装Visual Studio
1.查找版本
设定要安装cuda11.8.0(版本能高于电脑要求的版本)
去CUDA官网查看相应版本vs ,网址:https://developer.nvidia.com/cuda-toolkit-archive
找到cuda11.8,然后点击版本在线文档
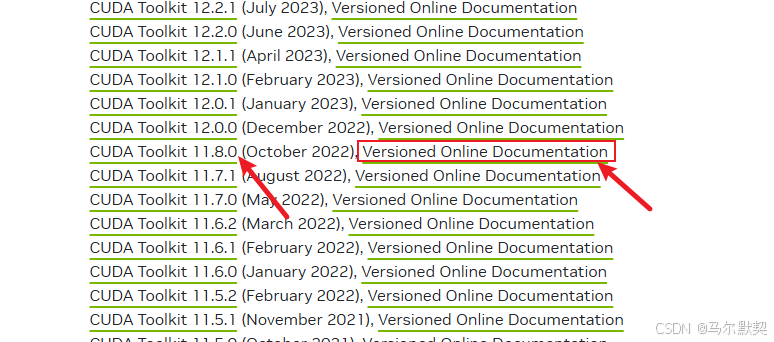
点击左边栏的“Installation Guide Windows”
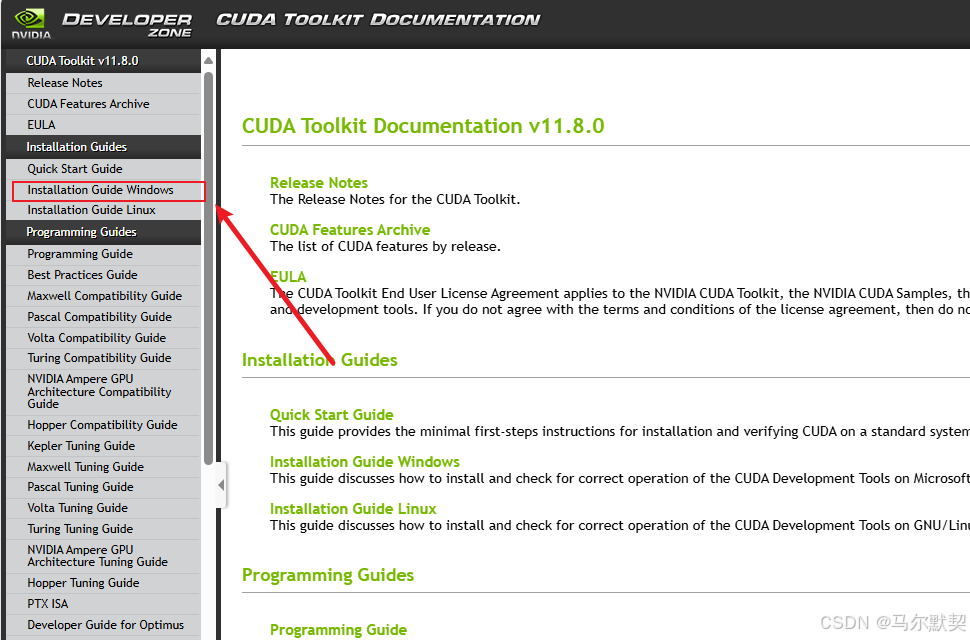
查看适合该版本的编译器,去下载vs对应版本,一定要从里边找一个版本下载,vs版本太高也不行。
2.下载Visual Studio
地址:https://visualstudio.microsoft.com/zh-hans/
https://visualstudio.microsoft.com/zh-hans/downloads/
下载2022社区版
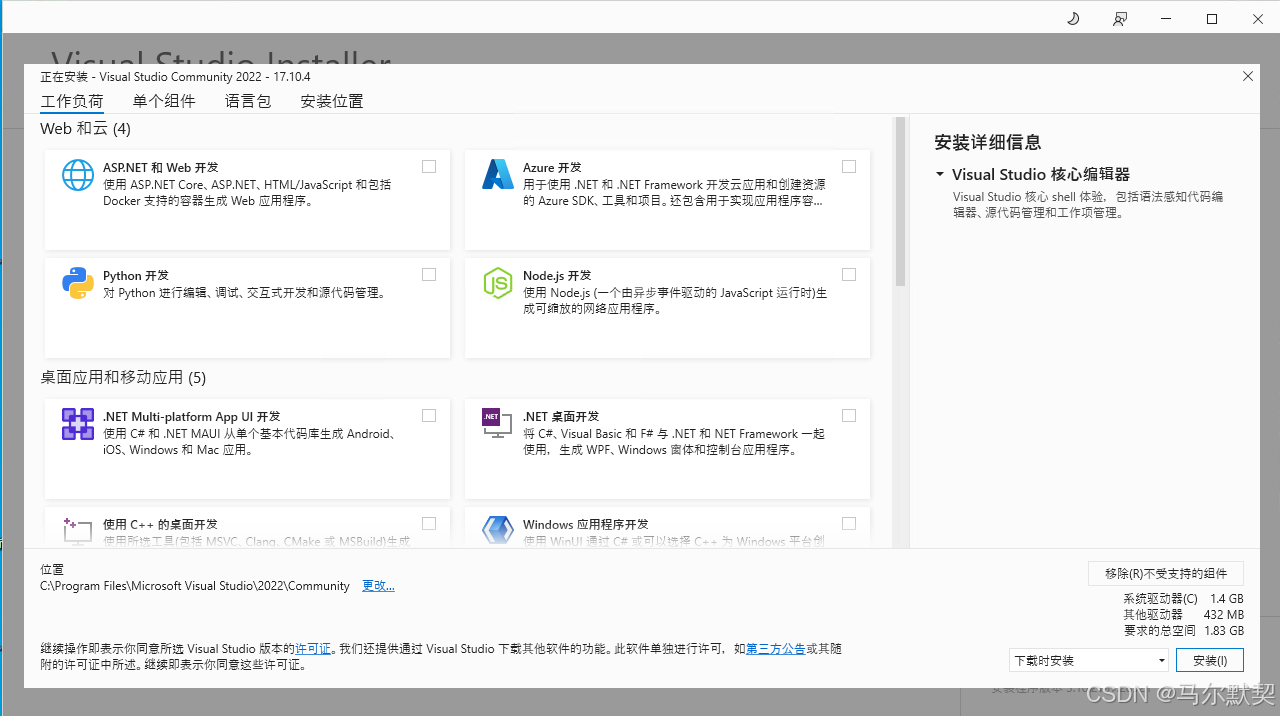
3.双击打开后,会加载一些东西。最后出现下面的界面
4.更改安装路径
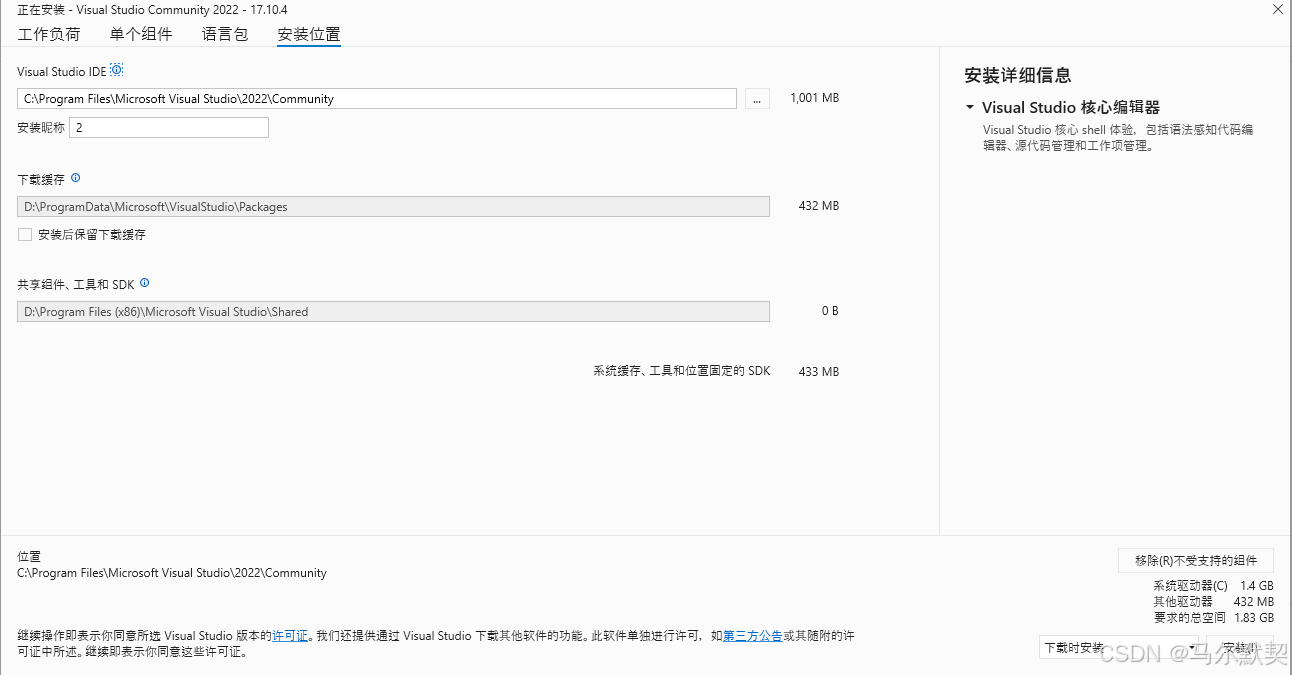
因为visual studio占用的空间十分大,我们可以不把它一股脑地安装在C盘,切换到安装位置,将下述三项的路径改成D盘或其他非系统盘
5.自定义安装组件
这时我们就可以自定义选择组件进行下载
因为我是需要使用使用深度信息,所以这里选择了使用C++的桌面开发和Python开发
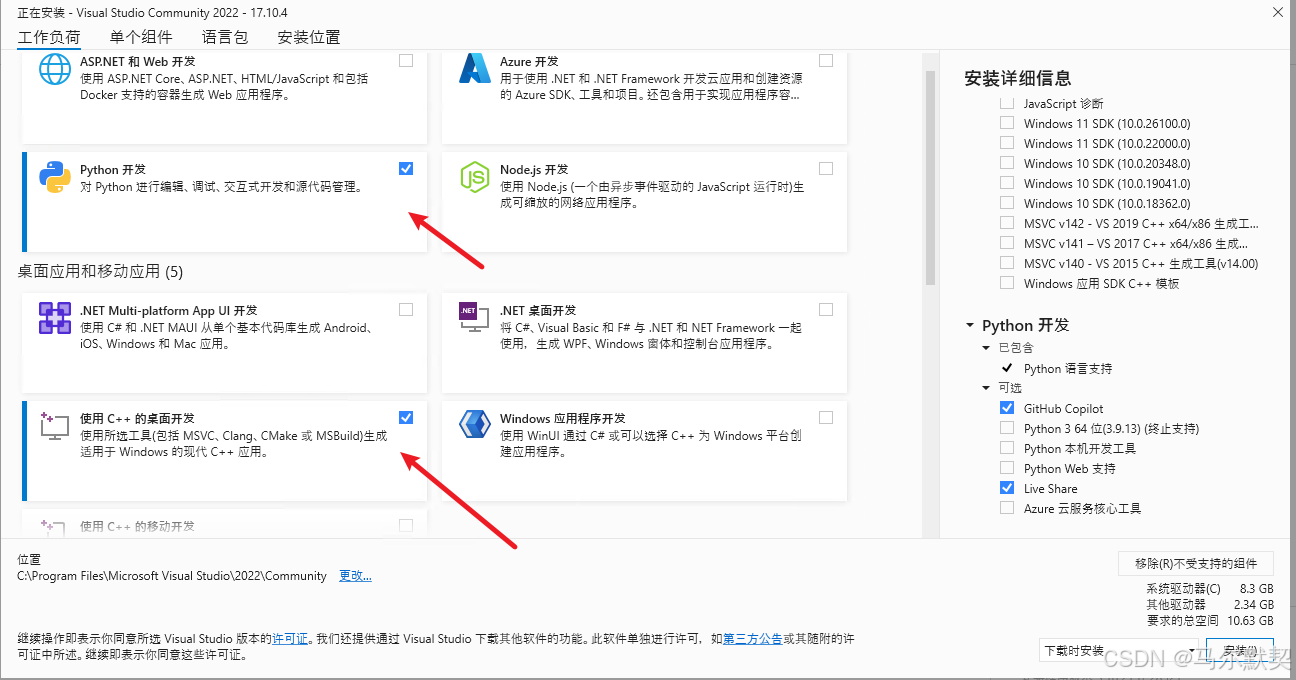
选好就可以点击右下角的安装按钮
2.安装cuda
1.下载
地址:https://developer.nvidia.com/cuda-toolkit-archive
选择合适的版本
2.安装
下载得到.exe文件双击运行

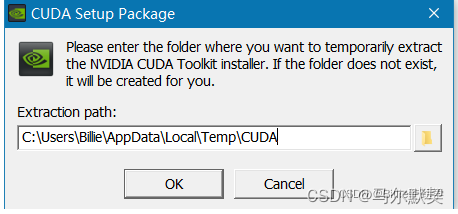
路径是临时文件存放地址,可修改,但不要和最终cuda安装的地址相同(临时文件安装后会删除,在一个地址,会导致安装的cuda在安装结束后被删除,导致安装无效)
后续按照默认选项来就行
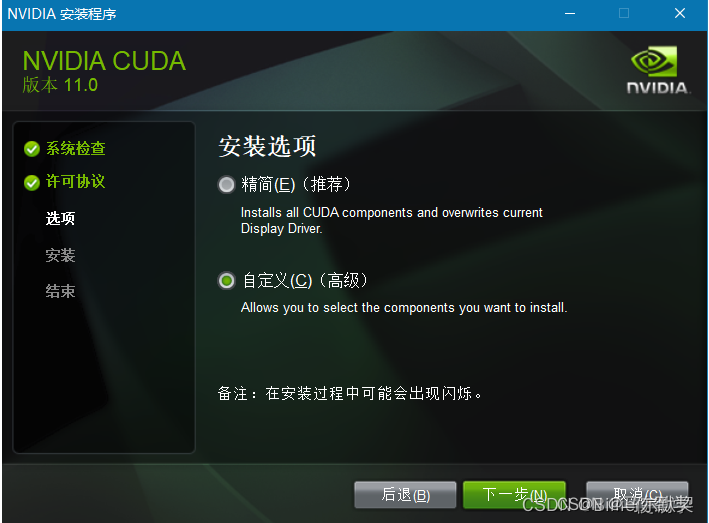
自定义安装,精简版本是下载好所有组件,并且会覆盖原有驱动,所以在这里推荐自定义下载
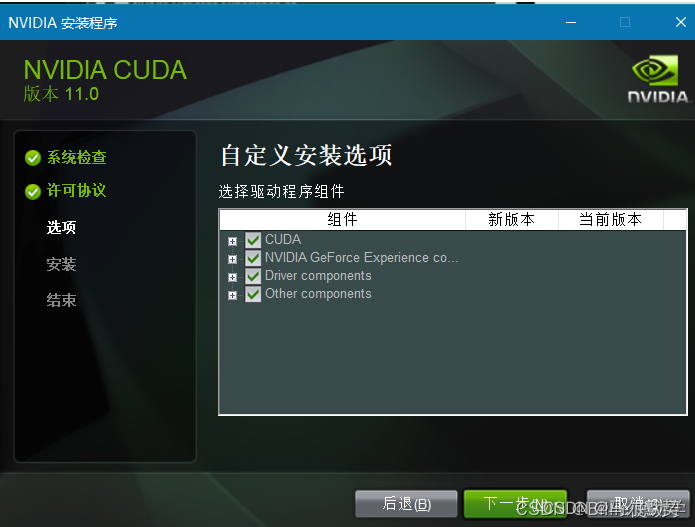
如果你是第一次安装,尽量全选
如果你是第n次安装,尽量只选择第一个,不然会出现错误
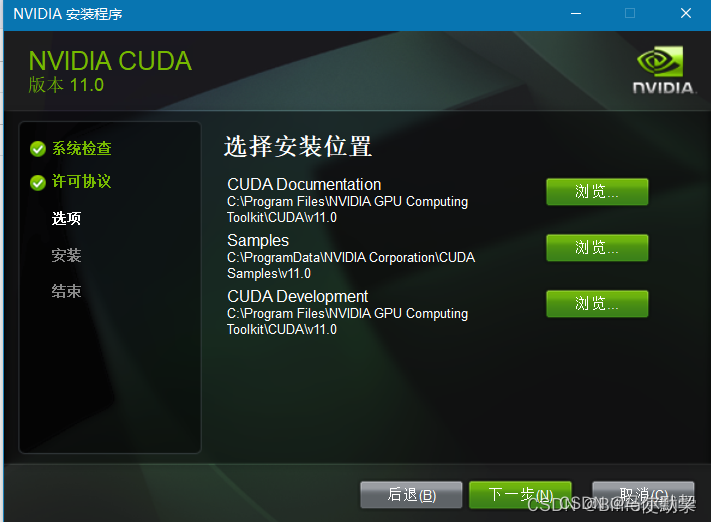
记住默认的安装路径,后续要使用
3.环境配置
查看环境变量
点击设置–>搜索高级系统设置–>查看环境变量
系统变量会自动生成(V11_0会根据安装的版本发生变化)

还有两个这个(V11_0要根据安装的版本发生变化)
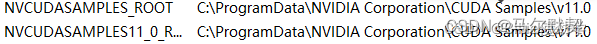
如果后两个变量没有自动生成,没有生成的手动添加就行,注意自己的路径
这两个变量变量名如下,
NVCUDASAMPLES_ROOT
NVCUDASAMPLES11_0_ROOT
4.验证
在cmd
使用nvcc --version 即可查看版本号
set cuda,可以查看 CUDA 设置的环境变量
3.安装cuDNN
1.地址:https://developer.nvidia.com/rdp/cudnn-archive
可能需要挂梯子
选择与安装的cuda适配的版本
2.安装
下载得到压缩包
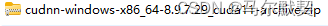
解压后,有三个文件夹,把三个文件夹拷贝到cuda的安装目录下

CUDA 的安装路径在前面截图中有,或者打开电脑的环境变量查看,默认的安装路径如下:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
3.配置环境
往系统环境变量中的 path 添加如下路径
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp
4.验证
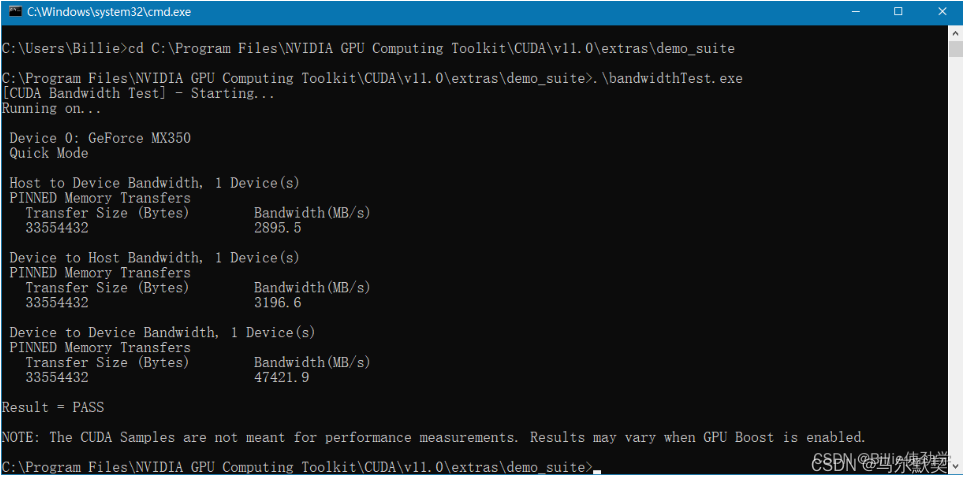
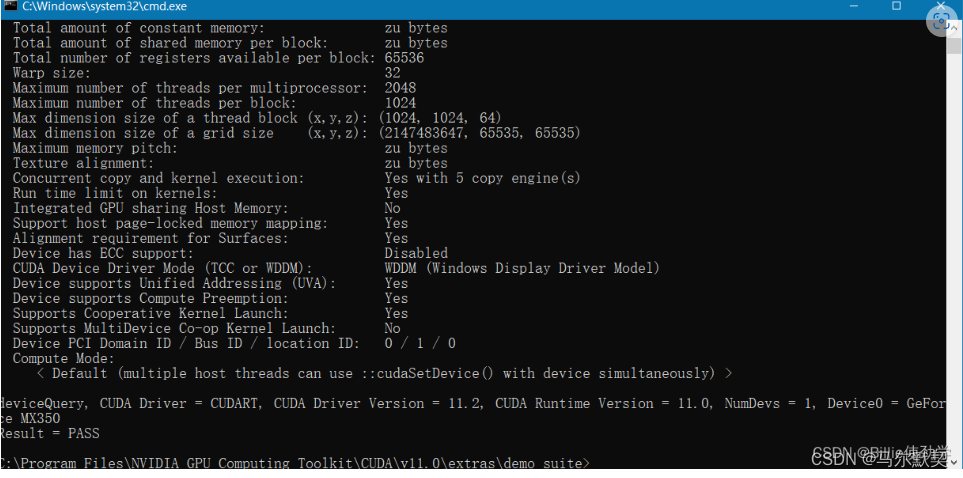
启动cmd,cd到安装目录下的 …\extras\demo_suite,然后分别执行bandwidthTest.exe和deviceQuery.exe(进到目录后需要直接输“bandwidthTest.exe”和“deviceQuery.exe”),应该得到下图:
4.conda配置python环境
打开Anacoda Powershell Prompt
//查询环境
conda env list
//创建环境(名称:MC python版本:3.8)
conda create --name MC python=3.8
//指定目录创建环境(名称:MC 目录:D:/env python版本:3.8)会导致环境没有名称
conda create --name MC --prefix D:/env python=3.8
//切换到MC环境
conda activate MC
source conda actvate MC //Linux
//删除环境
conda remove --name MC --all
5、安装pycharm
安装Community版本
地址:https://www.jetbrains.com/pycharm/download/?section=windows#section=windows.
1.下载
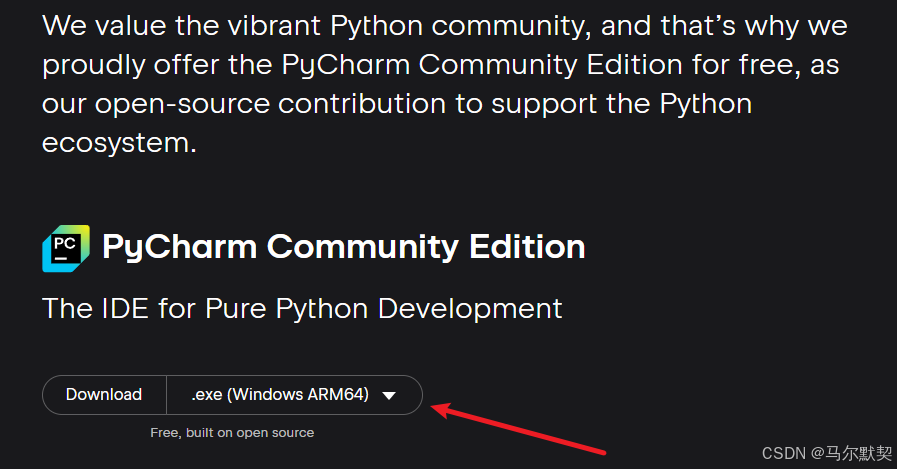
安装后运行如果提示

可以选择.exe(Windows)版本
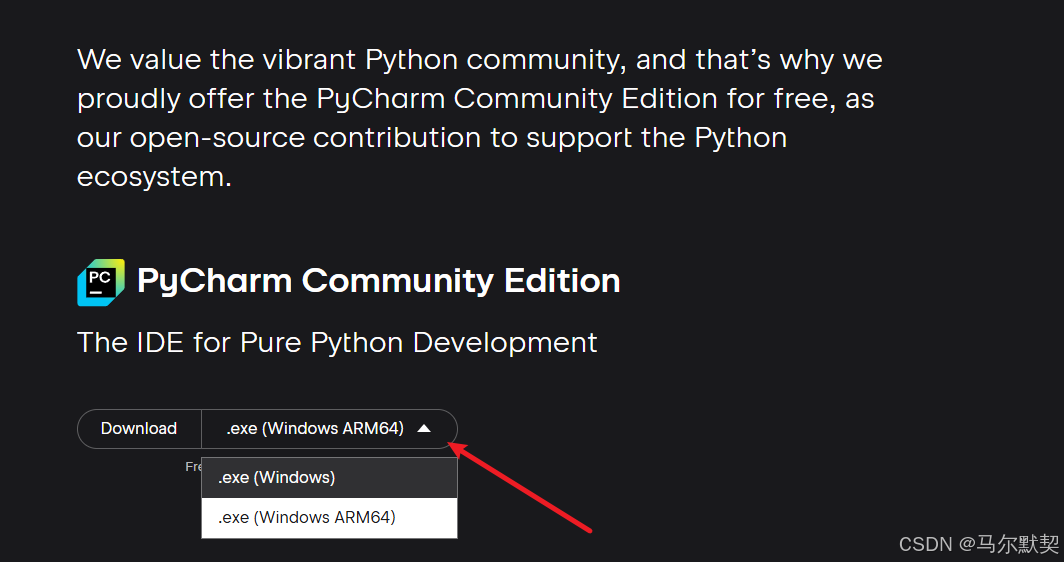
2.双击安装.exe文件

3.安装地址(可以使用默认地址)
4.一般全选
6、安装python
地址:https://www.python.org/downloads/
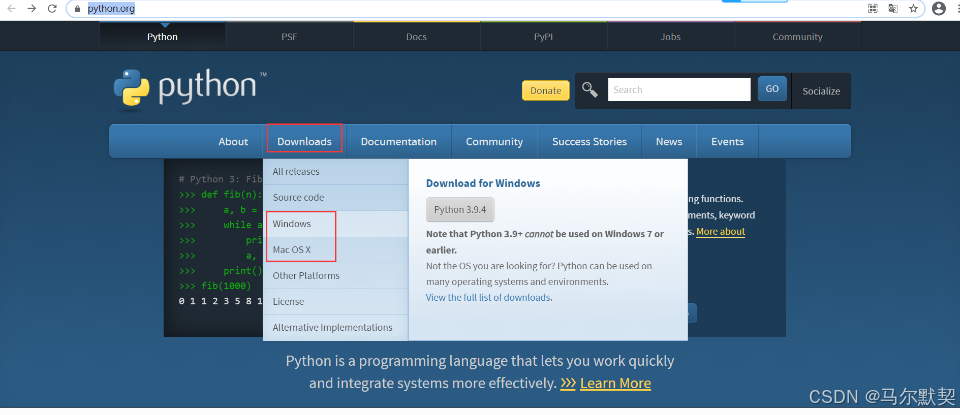
1.进入Windows以后,选择左侧的列表,然后选择你要安装的版本(不建议安装最新的),然后再根据该电脑系统安装对应的位数的版本。(选择installer结尾的)
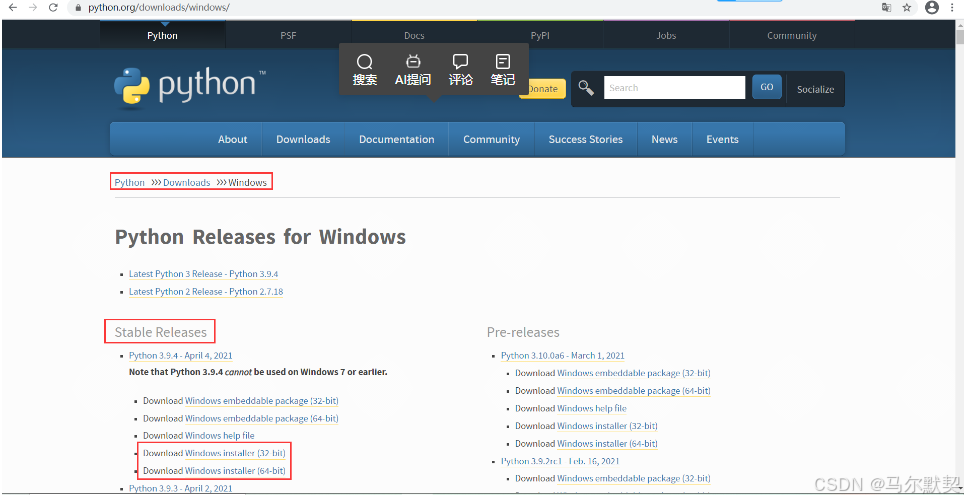 2.然后找到你下载好的安装包,双击打开。(首次打开,窗口右下角会有一个 add Path,可以勾选上,不勾的话,后面得需要自己配置环境变量)
2.然后找到你下载好的安装包,双击打开。(首次打开,窗口右下角会有一个 add Path,可以勾选上,不勾的话,后面得需要自己配置环境变量)

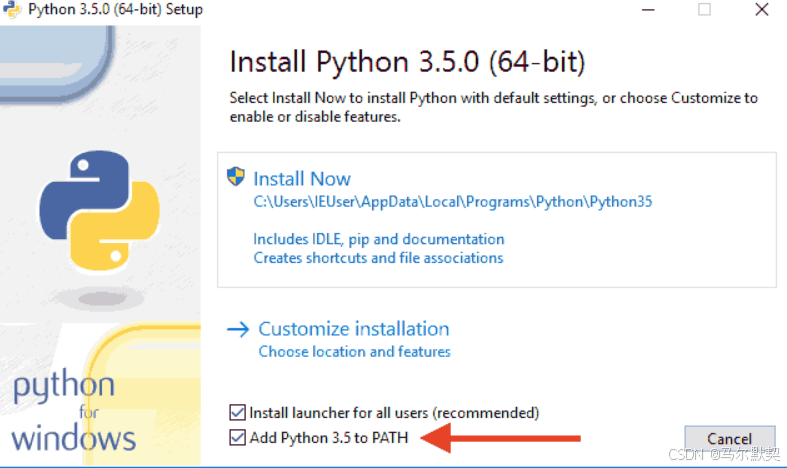
3.打开的过程中,默认选项就好,不用勾选其他
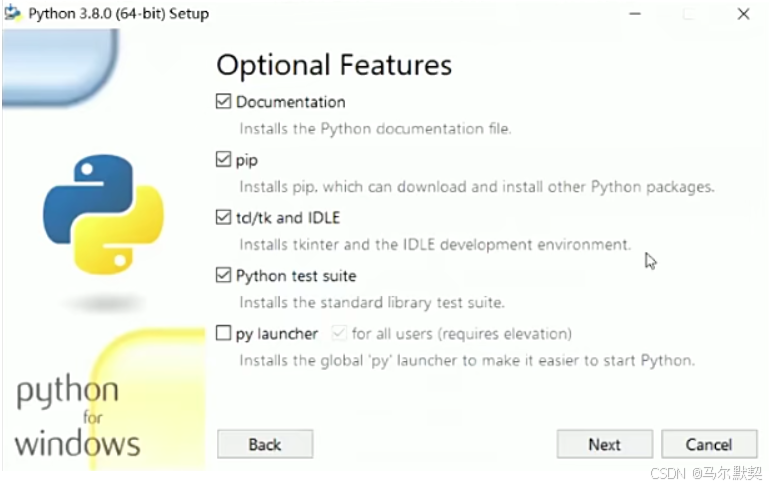
4.但是要选择你要安装的目录,并且要记住该目录,后面配置环境变量时用的到
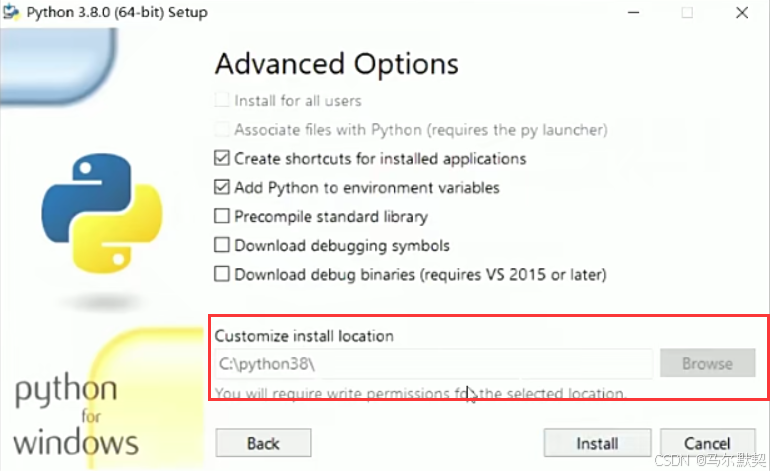
5.在电脑中找到安装路径
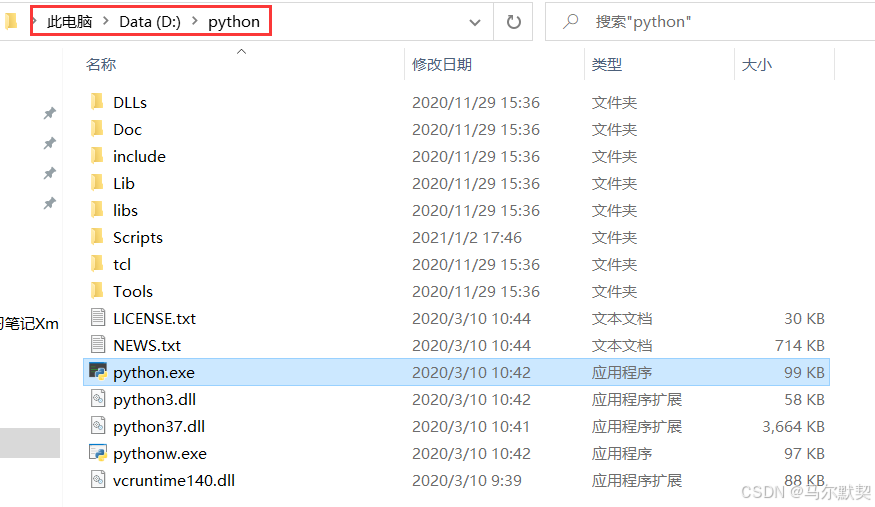
6.然后打开cmd窗口,分别输入 python 与 pip ,来检查python是否安装好
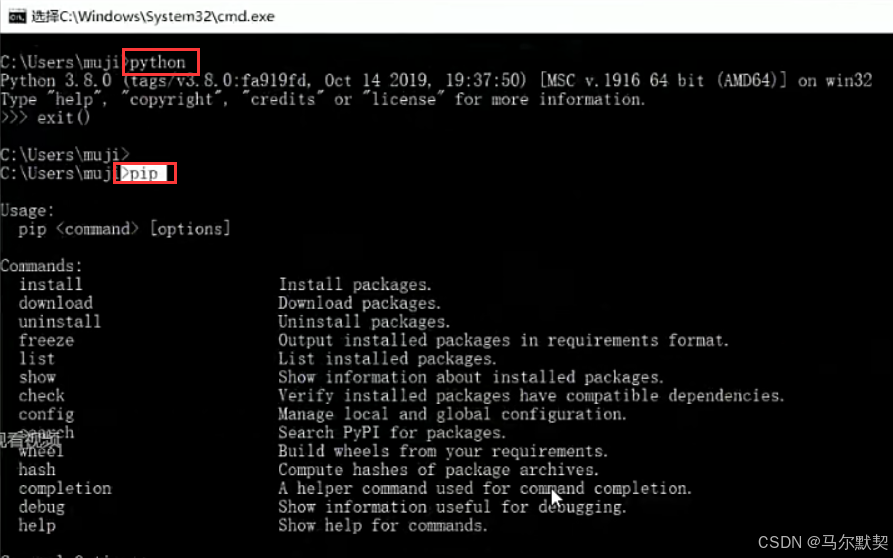
7.把安装好的路径,配置到环境变量里
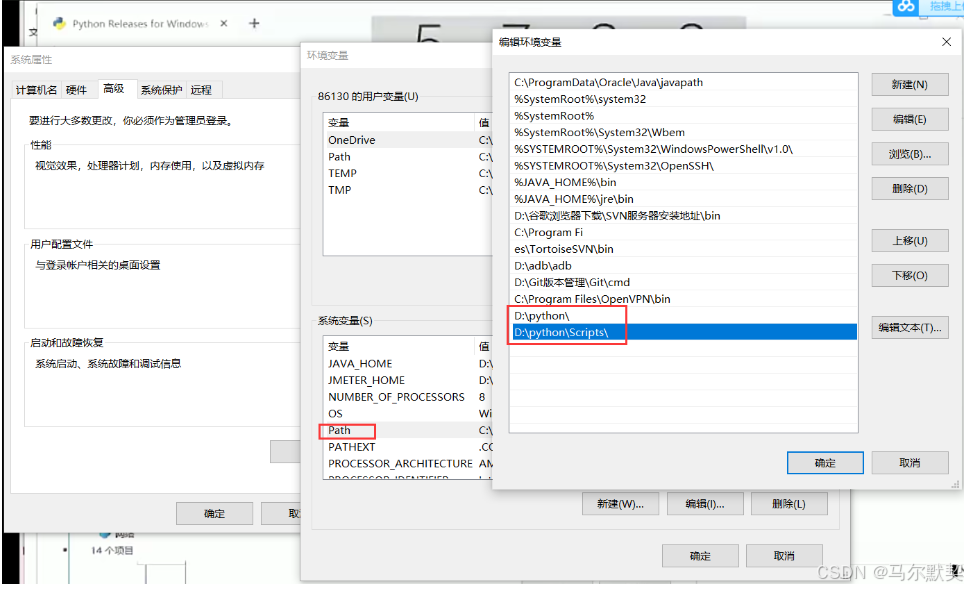
8.配置好环境变量后,一定要重启电脑,然后cmd窗口里,再次输入python 与 pip 检查一下。此时python的安装流程完毕
7、安装torch
地址:https://pytorch.org/get-started/previous-versions/
选择适合自己的版本进行下载(我需要2.0.1版本)
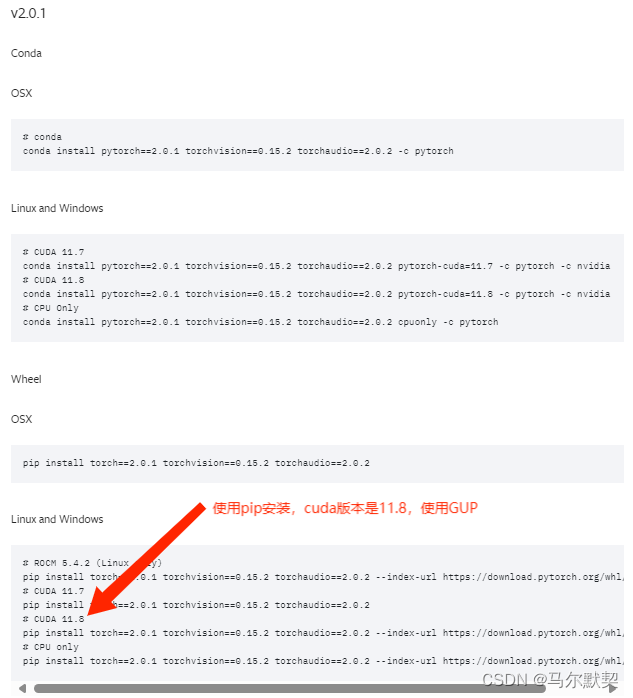
# CUDA 11.8
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
复制代码在pycharm的terminal输入进行安装
可能出现下载不了的情况
或许是镜像的问题,可以配置其他镜像试一下
如果还不行,可以把安装包下载下来(.whl文件),然后使用pip安装
使用此法,安装了torch==2.0.1,其他的包任需安装
2.镜像配置
在pycharm的terminal中配置镜像
//查询镜像
pip config list
//配置镜像
// 配置使用清华镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
// 配置信任该镜像源
pip config set install.trusted-host pypi.tuna.tsinghua.edu.cn
//常用镜像源
//清华镜像 https://pypi.tuna.tsinghua.edu.cn/simple
//豆瓣镜像 https://pypi.douban.com/simple/
//阿里云镜像 https://mirrors.aliyun.com/pypi/simple/
3.pip命令
//查询包
pip list
//安装包xx
pip install xx
//安装包xx的1.1.1版本
pip install xx==1.1.1
//删除包xx
pip uninstall xx
//更新包xx
pip install --upgrade xx
//查看安装的xx的信息
pip show xx
//安装D://package/AA.whl文件(AA包,使用pip无法正常安装,可以将其下载下来,然后使用pip安装)
cd D:
cd package
pip install AA.whl
二、运行项目
1.数据集
1.RTTS
目录结构
\---RTTS
+---images
| +---train
+---AM_Bing_211.png
\---AM_Bing_217.png
| \---val
\---labels
+---train
+---AM_Bing_211.txt
\---AM_Bing_217.txt
\---val
\---rtts.json
\---rtts_100_val.json
2.DINO
1.库安装
其他库按需安装,此处只解决安装中有问题的库
1.库安装—panopticapi
先克隆代码
git clone https://github.com/cocodataset/panopticapi.git
将克隆的代码放到项目里
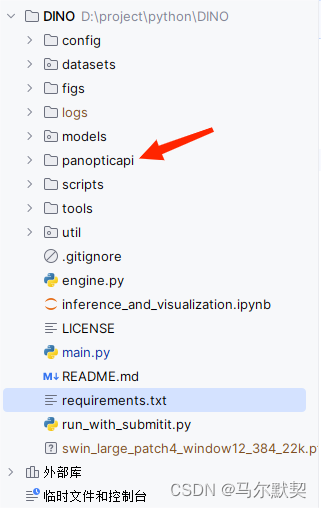
使用pycharm终端(terminal)打开panopticapi,并执行命令
cd .\panopticapi\
python setup.py build_ext --inplace
python setup.py build_ext install
2.库安装—MultiScaleDeformableAttention
使用pycharm终端(terminal)打开ops

并执行命令
cd .\models\dino\ops\
python setup.py build install
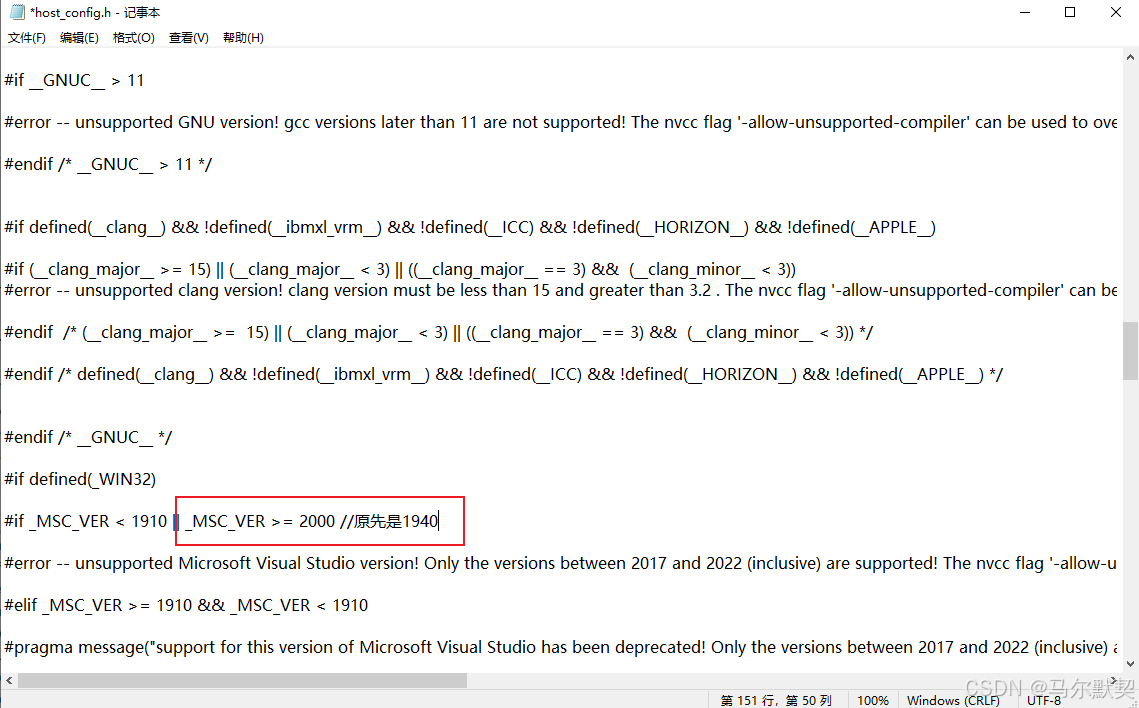
若无法安装,出现
unsupported Microsoft Visual Studio version! Only the versions between 2017 and 2022 (inclusive) are supported! The nvcc flag ‘-allow-unsupported-compiler’ can be used to override this version check; however, using an unsupported host compiler may cause compilation failure or incorrect run time execution. Use at your own risk.
找到cuda的文件:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\include\crt\host_config.h
将其中的“_MSC_VER >=”后的数字该为2000,然后再安装
2.库展示
//显示为NO73的MC解释器
(MC) PS D:\MC\code\DINO> pip list
Package Version
----------------------------- ------------
addict 2.4.0
certifi 2022.12.7
charset-normalizer 2.1.1
cloudpickle 3.0.0
colorama 0.4.6
contourpy 1.1.1
cycler 0.12.1
Cython 3.0.10
filelock 3.9.0
fonttools 4.51.0
fsspec 2024.3.1
huggingface-hub 0.22.2
idna 3.4
importlib_metadata 7.1.0
importlib_resources 6.4.0
Jinja2 3.1.2
kiwisolver 1.4.5
markdown-it-py 3.0.0
MarkupSafe 2.1.3
matplotlib 3.7.5
mdurl 0.1.2
mmcv 2.1.0
mmdet 3.3.0
mmengine 0.10.3
mpmath 1.3.0
MultiScaleDeformableAttention 1.0
networkx 3.0
numpy 1.24.1
opencv-python 4.4.0.46
packaging 24.0
panopticapi 0.1
pillow 10.2.0
pip 24.0
platformdirs 4.2.0
pycocotools 2.0.7
Pygments 2.17.2
pyparsing 3.1.2
python-dateutil 2.9.0.post0
PyYAML 6.0.1
regex 2024.4.16
requests 2.28.2
rich 13.4.2
safetensors 0.4.3
scipy 1.10.1
setuptools 69.2.0
shapely 2.0.4
six 1.16.0
submitit 1.5.1
sympy 1.12
termcolor 1.1.0
terminaltables 3.1.10
timm 1.0.7
tomli 2.0.1
torch 2.0.1+cu118
torchaudio 2.0.2+cu118
torchvision 0.15.2+cu118
tqdm 4.65.2
typing_extensions 4.8.0
urllib3 1.26.13
wheel 0.43.0
yapf 0.40.0
zipp 3.18.1
//显示为实验室的model解释器
(D:\project\env\model) PS D:\project\python\DINO> pip list
Package Version
----------------------------- ------------
absl-py 2.1.0
addict 2.4.0
aliyun-python-sdk-core 2.15.1
aliyun-python-sdk-kms 2.16.2
attrs 23.2.0
cachetools 5.3.3
certifi 2022.12.7
cffi 1.16.0
charset-normalizer 2.1.1
click 8.1.7
cloudpickle 3.0.0
colorama 0.4.6
coloredlogs 15.0.1
contourpy 1.1.1
crcmod 1.7
cryptography 42.0.5
cycler 0.12.1
Cython 3.0.10
filelock 3.9.0
flatbuffers 24.3.25
fonttools 4.51.0
fsspec 2024.3.1
google-auth 2.29.0
google-auth-oauthlib 1.0.0
grpcio 1.62.2
huggingface-hub 0.22.2
humanfriendly 10.0
idna 3.4
importlib_metadata 7.1.0
importlib_resources 6.4.0
Jinja2 3.1.2
jmespath 0.10.0
joblib 1.4.0
jsonschema 4.21.1
jsonschema-specifications 2023.12.1
kiwisolver 1.4.5
lmdb 1.4.1
Markdown 3.6
markdown-it-py 3.0.0
MarkupSafe 2.1.3
matplotlib 3.7.5
mdurl 0.1.2
mmcv 2.1.0
mmdet 3.3.0
mmengine 0.10.3
model-index 0.1.11
mpmath 1.3.0
MultiScaleDeformableAttention 1.0
networkx 3.0
numpy 1.24.1
oauthlib 3.2.2
onnx 1.14.0
onnxruntime 1.15.1
opencv-python 4.4.0.46
opendatalab 0.0.10
openmim 0.3.9
openxlab 0.0.38
ordered-set 4.1.0
oss2 2.17.0
packaging 24.0
pandas 2.0.3
panopticapi 0.1
pillow 10.2.0
pip 23.3.1
pkgutil_resolve_name 1.3.10
platformdirs 4.2.0
prettytable 3.10.0
protobuf 5.26.1
pyarrow 16.0.0
pyasn1 0.6.0
pyasn1_modules 0.4.0
pycocotools 2.0.7
pycparser 2.22
pycryptodome 3.20.0
Pygments 2.17.2
pyparsing 3.1.2
pyproject 1.3.1
pyproject-toml 0.0.11
pyreadline3 3.4.1
python-dateutil 2.9.0.post0
pytz 2023.4
pywin32 306
PyYAML 6.0.1
referencing 0.34.0
regex 2024.4.16
requests 2.28.2
requests-oauthlib 2.0.0
rich 13.4.2
rpds-py 0.18.0
rsa 4.9
safetensors 0.4.3
scikit-learn 1.3.2
scipy 1.10.1
setuptools 60.2.0
shapely 2.0.4
six 1.16.0
submitit 1.5.1
sympy 1.12
tabulate 0.9.0
tensorboard 2.14.0
tensorboard-data-server 0.7.2
termcolor 1.1.0
terminaltables 3.1.10
threadpoolctl 3.4.0
timm 0.5.4
tokenizers 0.19.1
toml 0.10.2
tomli 2.0.1
torch 2.0.1+cu118
torchaudio 2.0.2+cu118
torchtoolbox 0.1.8.2
torchvision 0.15.2+cu118
tqdm 4.65.2
transformers 4.40.0
typing_extensions 4.8.0
tzdata 2024.1
urllib3 1.26.13
wcwidth 0.2.13
Werkzeug 3.0.2
wheel 0.41.2
yacs 0.1.8
yapf 0.40.0
zipp 3.18.1
2.修改(resnet50主干)
1.修改数据集配置
修改coco.py
DINO\datasets\coco.py
在大概615行
# PATHS = {
# "train": (root / "train2017", root / "annotations" / f'{mode}_train2017.json'),
# "train_reg": (root / "train2017", root / "annotations" / f'{mode}_train2017.json'),
# "val": (root / "val2017", root / "annotations" / f'{mode}_val2017.json'),
# "eval_debug": (root / "val2017", root / "annotations" / f'{mode}_val2017.json'),
# "test": (root / "test2017", root / "annotations" / 'image_info_test-dev2017.json' ),
# }
# machao
PATHS = {
"train": (root / "images/train", root / "labels/rtts.json"),
"train_reg": (root / "images/train", root / "labels/rtts.json"),
"val": (root / "images/val", root / "labels/rtts_100_val.json"),
"eval_debug": (root / "images/val", root / "labels/rtts_100_val.json"),
"test": (root / "images/val", root / "labels/rtts_100_val.json"),
}
2.修改训练超参数
DINO\config\DINO\DINO_4scale.py
可以复制一份:DINO_4scale_mc.py然后再修改
num_classes=5 //目标类别
batch_size = 2
epochs = 12
3.修改训练文件
远代码是在linux运行的,所遇使用DINO_train.sh文件进行训练
DINO\scripts\DINO_train.sh
DINO_train.sh内容如下
coco_path=$1 #要输入数据集地址
python main.py \
--output_dir logs/DINO/R50-MS4 -c config/DINO/DINO_4scale.py --coco_path $coco_path \
--options dn_scalar=100 embed_init_tgt=TRUE \
dn_label_coef=1.0 dn_bbox_coef=1.0 use_ema=False \
dn_box_noise_scale=1.0
我们不使用,所以要参照DINO_train.sh对main.py和DINO_4scale_mc.py文件进行修改
DINO\main.py 修改:
parser.add_argument('--config_file', '-c', type=str, default='config/DINO/DINO_4scale_mc.py')
parser.add_argument('--output_dir', default='logs/DINO/R50-MS4', help='path where to save, empty for no saving')
parser.add_argument('--coco_path', type=str, default='D:/project/dataset/RTTS/')
DINO\config\DINO\DINO_4scale.py 修改:
embed_init_tgt = True
use_ema = False
dn_box_noise_scale = 1.0
/#没有的添加
dn_scalar=100
dn_label_coef=1.0
dn_bbox_coef=1.0
3.修改(swin主干)
1.修改数据集配置
与上述一致
2.修改训练超参数
DINO\config\DINO\DINO_4scale_swin.py
可以复制一份:DINO_4scale_swin_mc.py然后再修改
num_classes=5 //目标类别
batch_size = 2
epochs = 12
3.修改训练文件
大致与上面一样
不同:
DINO\main.py 修改:
parser.add_argument('--config_file', '-c', type=str, default='config/DINO/DINO_4scale_swin_mc.py')
4.问题
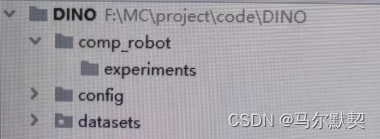
第一次train的时候出现报错 RuntimeError: No shared folder available dino
解决方法:在项目文件夹下新建一个名为comp_robot的文件夹,该文件夹内再新建一个名为experiments的文件夹,然后在根目录下的run_with_submitit.py中找到get_shared_folder()函数,将其中的 /comp_robot 换为自己的文件夹所在路径,/comp_robot/{user}/experiments 同理
4.其他注意事项
对应修改:
parser.add_argument('--num_workers', default=10, type=int)
parser.add_argument('--resume', default='logs/DINO/swin-MS4-%13276/checkpoint0005.pth', help='resume from checkpoint')#中断后恢复训练
若在官方.sh文件中有:
--job_dir logs/DINO/R50-MS4-%j
我们可以在main.py文件中改为:
parser.add_argument('--job_dir', default=f"logs/DINO/swin-MS4-%{os.getpid()}",)
5.问题
1.FormatCode() got an unexpected keyword argument ‘verify’
是三方库版本问题
pip install yapf==0.40.0
pip install mmcv==2.1.0
pip install mmengine==0.10.3
pip install mmdet==3.3.0
2.DLL load failed while importing _interpolative: 找不到指定的程序。
scipy版本问题
pip install scipy==1.10.1
若还是报这个问题,则是某个安装的包有问题,可以对照可运行的环境,修改已安装的包的版本
3.UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x80 in position 2860: illegal multibyte sequence
是编码问题:util/slconfig.py
# with open(filename) as f:
with open(filename,encoding='UTF-8') as f:
# with open(filename, 'r') as f:
with open(filename, 'r',encoding='UTF-8') as f:
注释的是原本的代码,要添加encoding=‘UTF-8’
6.训练
1.中断后恢复训练
若中断后恢复训练时只设置resume参数,会导致后续训练时选择的最好的数值(checkpoint)发生错误
"best_res": 0.36547634265724344, "best_ep": 20, "epoch": 35, "n_parameters": 46626578, "now_time": "2024-07-17 16:15:54.079634" #第36轮结果,之后发生了查询中断
"best_res": 0.36245227572591165, "best_ep": 36, "epoch": 36, "n_parameters": 46626578, "now_time": "2024-07-17 16:51:32.295919",
如上面代码训练35epoch后中断保留了checkpoint0035,只设置了resume为checkpoint0035,开始36个epoch训练,在36epoch训练中best_ep指定的是36,最好的数据(best_res)是36epoch的,并非是中断前的20epoch的数值,这导致后续的训练都有问题
解决该问题:看中断时哪个epoch是最好的,例如checkpoint0010是最好的(即使已经续联到15epoch了),使用下面设置,然后继续训练(自己看是否需要删除10之后的checkpoint和best_checkpoint)
start_epoch 11
resume checkpoint10.pth
即使这样设置,任会在第11个epoch训练后直接将checkpoint11当做最好,即使11的数据不如10的数据
3.DINOv2
是自监督学习模型
自监督学习(Self-Supervised Learning, SSL)是机器学习中的一种方法,特别是在深度学习领域。它不依赖于人工标注的数据,而是利用数据本身的结构和属性来生成伪标签,以此训练模型
4.TogetherNet
1.环境
pip install h5py==2.10.0
pip install tensorboard
2.数据集
\---RTTS
+---images
| +---train
+---AM_Bing_211.png
\---AM_Bing_217.png
| +---train_dehaze
+---AM_Bing_211_dehaze.png
\---AM_Bing_217_dehaze.png
| +---val
+---0.png
\---1.png
| +---val_dehaze
+---0_MSBDN.png
\---1_MSBDN.png
\---labels
+---train
+---AM_Bing_211.txt
\---AM_Bing_217.txt
\---val
\---rtts.json
\---rtts_100_val.json
另有配置文件
train.txt train_dehaze.txt val.txt val_dehaze.txt
配置文件内容如图(以train.txt为例):
3.修改
1.train.py
classes_path = 'model_data/rtts_classes.txt' 识别目标类别
# model_path = 'model_data/yolox_s.pth' 官方预训练权重
#batch和epoch
Freeze_batch_size = 16
UnFreeze_Epoch = 100
Unfreeze_batch_size = 16
#训练集、验证集中所有图片列表
train_annotation_path = '2007_train_fog.txt' #trian 有雾 2007_train_fog.txt内容如上述train.txt
val_annotation_path = '2007_val_fog.txt' #val 有雾
clear_annotation_path = '2007_train.txt' #trian 无雾
val_clear_annotation_path = '2007_val.txt' #val 无雾
2.utils/dataloader.py
def get_random_data(self, annotation_line, clearimage_line, input_shape, jitter=.3, hue=.1, sat=0.7, val=0.4, random=True):
# macho 2024-07-22 10时 添加注释
pic_name=line[0] #为2007_train_fog.txt获取其他3个文件中的后一行 用于读取改行文字对应的图片与标签
pic_clear_name=clearline[0]
#读取图片
line=os.path.join("D:/project/dataset/RTTS/images/" ,pic_name+ ".png")
clearline = os.path.join("D:/project/dataset/RTTS/images/", pic_clear_name + ".png")
# image = Image.open(line[0])
image = Image.open(line)
image = cvtColor(image)
# clearimg = Image.open(clearline[0])
clearimg = Image.open(clearline)
clearimg = cvtColor(clearimg)
#读取标签数据
train_label_path=os.path.join("D:/project/dataset/RTTS/labels/" ,pic_name+ ".txt")
with open(train_label_path, encoding='utf-8') as f:
train_labels_lines = f.readlines()
# box = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
box = np.array([np.array(list(map(float,box_element.split( )[1:]))) for box_element in train_labels_lines])
3.nets/yolo.py
def forward(self, input):
if self.training:
#此处input.split((4, 4)中的数值与train中的Freeze_batch_size一样???
# input, clear_x = input.split((4, 4), dim=0) # split haze and clear images (Batchsize, Batchsize)
input, clear_x = input.split((4, 4), dim=0) # split haze and clear images (Batchsize, Batchsize)
4.训练
运行train.py开始训练
训练结果显示在logs文件夹下(内容不多,只有loss,没有AP,mAP等数据)
4300多张图batch=16,训练1个epoch大约3min
可能存在哪里设置不对,因为训练3,4个epoch后,val_loss基本都只0.000几,
且train_los也在3-4个epoch就趋近收敛的数值了,
数值太小,epoch太少就得到好结果??(无mAP,AP … 值),这可能存在问题
4.RT-DETR-V2
1.环境
python 3.8
conda create --name rt python=3.8
cuda 11.7
torch 2.0.1
conda install pytorch2.0.1 torchvision0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
2.数据集
json文件的类别编号从1开始

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









