







计算机是如何执行程序的,可以用下面的图来形象的表示一下:
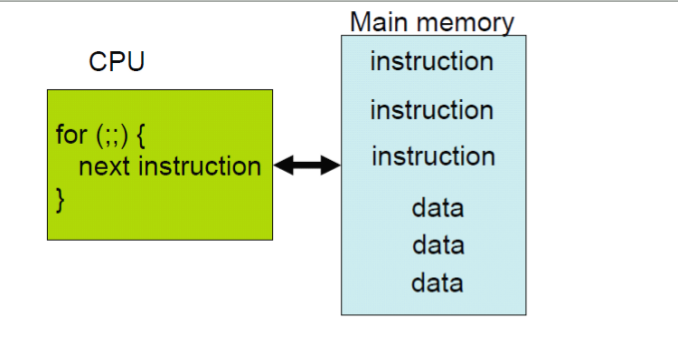
内存中存放指令和数据。CPU的EIP寄存器存放下一个CPU指令存放的内存地址,当CPU执行完当前的指令后,从EIP寄存器中读取下一条指令的内存地址,然后继续执行。
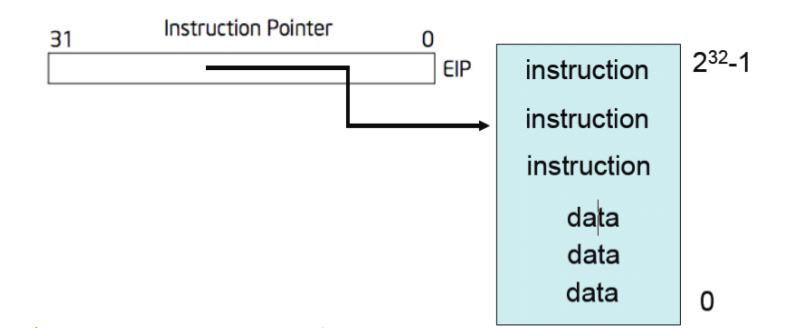
EIP寄存器中的指令地址是递增的,但是它可以由CALL ,RET ,JMP 来更改的。指令的长度也是不一样的。
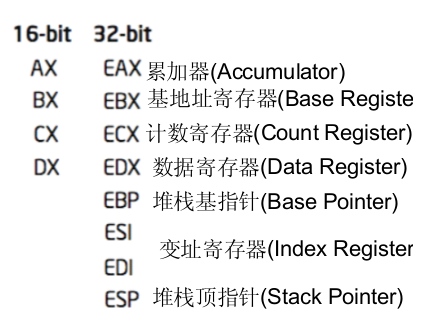
可以由我们来看一下 CPU中的几个基本寄存器。

问题:在一段简单的代码上分析计算机是如何工作的
#include <stdio.h>
int g(int x)
{
return x + 3;
}
int f(int x)
{
return g(x);
}
int main(void)
{
printf("%d",f(8) + 1);
return f(8) + 1;
} 第一步任务:使用exampe 的c代码分别生成.cpp , .s ,.o, 和ELF 可执行文件,并加载运行。分析.s汇编代码在CPU的执行过程。
1.预处理:使用-E参数,输出文件后缀 为 .cpp
gcc -E -o example.cpp example.c 
wc example.c example.cpp 执行之后:

预处理的作用:文件包含、宏替换、条件编译等
1. 一般在宏定义的结尾不加分号。
我们在使用的时候,要加上分号,像我们平时写语句一样。
2. 注意加括号。
在有参数的空定义中,如果含有数值运算,那么就要在“宏整体”和“宏参数”两端都要加上括号。 如:#define max(a, b) ((a)+(b));
3. 注意空格。
在有参数的宏定义中,注意“宏名称”和“参数列表”之间不能有空格。 如:#define max (a, b) ((a)+(b)); 在"max”和”(a, b)”之间不能有空格。
4. 不要使用有副作用的参数区调用宏。 常见的有副作用的参数有:a++,getchar()等。
如:宏定义为#define max (a, b) ((a)+(b)); 那么使用max(i++, j++)调用该宏,会造成 i 或 j 中的一个值增加2,而不是我们期望的 1。
5. 可以使用编译器选项 添加宏 和 移除宏。 我使用的是gcc,添加宏的指令是”-D”,移除宏的指令是”-U”。
6. 宏参数替换的时候,不会替换字符串中的字符。即不会替换双引号之间的字符,其他的都会被替换,包括单引号之间的。
、 3、条件编译
一般情况下,在进行编译时对源程序中的每一行都要编译,但是有时希望程序中某一部分内容只在满足一定条件时才进行编译,如果不满足这个条件,就不编译这部分内容,这就是条件编译。条件编译主要是进行编译时进行有选择的挑选,注释掉一些指定的代码,以达到多个版本控制、防止对文件重复包含的功能。#if,#ifndef,#ifdef,#else,#elif,#endif是比较常见条件编译预处理指令,可根据表达式的值或某个特定宏是否被定义来确定编译条件。
2.编译成汇编代码:预处理文件 --> 汇编代码。
2). 使用-S说明生成汇编代码后停止工作gcc -x cpp-output -S -o gcctest.s gcctest.cpp 也可以直接编译到汇编代码
gcc -S gcctest.c
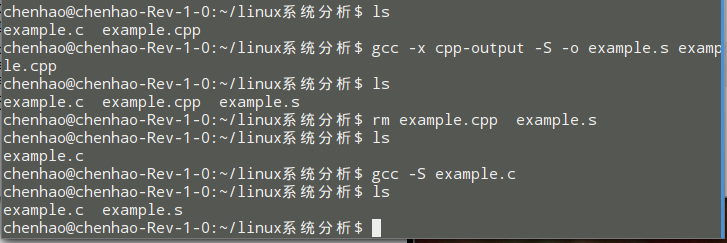
gcc -x cpp-output -S -o example.s example.cpp
rm example.cpp example.s
gcc -S example.c 执行之后:
3.编译成目标代码
gcc -x assembler -c example.s
gcc -c example.c
as -o example.o example.s执行过程:
4.编译生成可执行文件。
gcc -o example example.o
gcc -o example example.c执行过程:
5.运行可执行文件
./example6.gcc 的高级选项
#include <stdio.h>
#include <math.h>
int main(void)
{
int i,j;
double k=0.0,k1=k2=k3=1.0;
for (i=0;i<50000;i++)
for (j=0;j<50000;j++)
{
k+=k1+k2+k3;
k1 += 0.5;
k2 += 0.2;
k3 = k1+k2;
k3 -= 0.1;
}
return 0;
} gcc -O0 -o m0 example.c
gcc -O1 -o m1 example.c
gcc -O2 -o m2 example.c
gcc -O3 -o m3 example.c
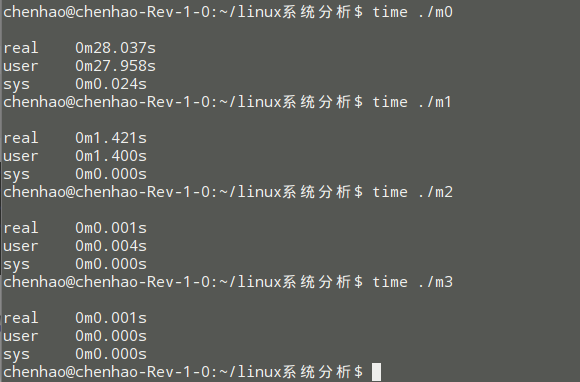
任务二:分析 .s汇编代码 在CPU上的执行过程
.file "example.c"
.text
.globl g
.type g, @function
g:
.LFB0:
.cfi_startproc
pushl %ebp //ebp寄存器内容压栈,保存f函数的入口地址
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp //esp值赋给ebp,设置f函数的栈基址
.cfi_def_cfa_register 5
movl 8(%ebp), %eax //将参数从ebp地址+8的地址中取出(这个地址中存放形参数),并放入到eax寄存
addl $3, %eax //将3与eax寄存器的内容相加结果保存到eax寄存器中
popl %ebp //将esp中内容出栈,存放到ebp中,ebp中此时存放f函数堆栈的栈底地址,然后栈顶上移
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size g, .-g
.globl f
.type f, @function
f: //f函数入口地址
.LFB1:
.cfi_startproc
pushl %ebp //ebp寄存器内容压栈
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp //esp值 赋给ebp,设置f函数的栈基址
.cfi_def_cfa_register 5
subl $4, %esp //esp指针下移
movl 8(%ebp), %eax //eax是累加寄存器,将参数从ebp地址+8的地址中取出(这个地址中存放形参数),并放入到eax寄存器中
movl %eax, (%esp) //将eax寄存其中存放的数据放到esp地址中
call g //调用g函数
leave //相当与movl %ebp %esp, popl ebp,退出当前堆栈,返回上一级函数堆栈
.cfi_restore 5
.cfi_def_cfa 4, 4
ret //函数返回,回到上一级调用
.cfi_endproc
.LFE1:
.size f, .-f
.globl main
.type main, @function
main:
.LFB2:
.cfi_startproc
pushl %ebp //ebp寄存器内容压栈,保存main函数的上级调用函数的栈基地址
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp //esp值 赋给ebp,设置main函数的栈基址
.cfi_def_cfa_register 5
subl $4, %esp //esp指针下移
movl $8, (%esp) //将8 存放到esp指针所指向的空间
call f //调用f函数
addl $1, %eax //将 f(8)运行结果在eax的值 与 1相加然后哦存放在累加其eax 中
leave //相当与movl %ebp %esp, popl ebp,将ebp值赋给esp,pop先前栈内的上级函数栈的基地址给ebp,恢复原栈基址
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE2:
.size main, .-main
.ident "GCC: (Ubuntu/Linaro 4.7.2-2ubuntu1) 4.7.2"
.section .note.GNU-stack,"",@progbits分析
第1行为gcc留下的文件信息;第2行标识下面一段是代码段,第3、4行表示这是g函数的入口,第5行为入口标号;6~20行为 g 函数体,稍后 分析;21行为 f 函数的代码段的大小;22、23行表示这是 f 函数的入口;24行为入口标识,25到41为 f 函数的汇编实现;42行为f函数的代码段的大小;43、44行表示这是main函数的入口;45行为入口标识,46到62为main函数的汇编实现;63行为main函数的代码段的大小;54到67行为 gcc留下的信息。
汇编中的push和pop:
pop系列指令的格式是:
pop destination
pop指令把栈顶指定长度的数据存放到destination中,并且设置相应的esp的值使它始终指向栈顶位置。
push刚好相反。
pushl %eax 等价于
subl $4 %esp //栈顶指针下移
movl %eax (%esp)//将%eax 存放在 esp指针指向的空间
popl %eax 等价于
movl (%esp) %eax //将esp指向空间的内容存放到eap中
addl %4 %esp //栈顶指针上移
LEAVE是释放当前函数或者过程的栈框架,即相当于以下两条指令:
movl %ebp %esp
popl ebp
ret指令:
等于 pop %ebp 即恢复ebp的值。
流程图下:
main的执行过程:
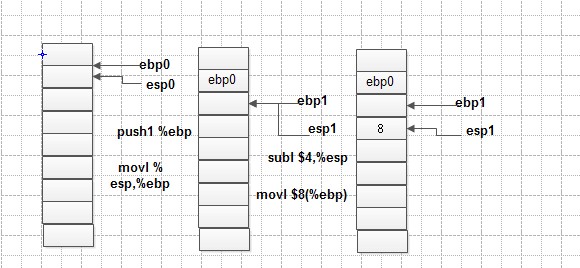
f的执行过程:
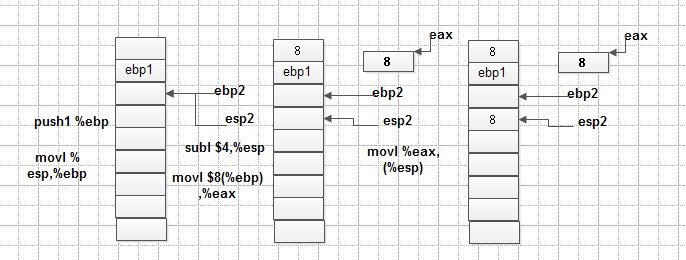
g的执行过程:
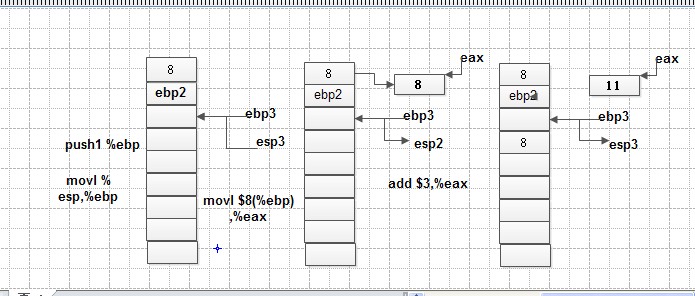
pop ebp完了之后,返回到上一个堆栈,其余类似。
单任务计算机是怎样工作的:计算机的最小模型由cpu和内存组成,对于单任务,计算机先将机器码加载入内存,然后控制器将eip所指向的内容取出即取指,然后顺序执行。执行过程中遇到控制指令,可能跳转。在指令执行过程中,如果遇到函数调用,要借助堆栈来实现,先将调用栈基地址压入堆栈,再压入调用函数的返回地址(下一条指令的地址即当前eip中的内容),此时的栈顶esp作为被调用函数栈的栈底ebp1,之后进入被调用函数继续执行。函数返回时栈的操作是相反的过程。通常函数的返回值由eax寄存器来保存。
多任务计算机是怎样工作的:多任务的顺利工作要借助中断,进程间调度机制时间片轮转方法等来实现多任务在计算机上工作,在多任务计算机工作过程中,由于要在多个任务间进行切换,所以由单任务计算机工作中函数调用得到启发。在各个任务之间进行切换之前,要保存前一个任务的栈顶,eip,标志位等信息,以保证该任务能够恢复。















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









