







Logistic Regression(逻辑回归)
以前在学校学到Logistic Regression的时候,虽然最后会使用,但是对于许多地方有很多的疑惑,今天在这里详细梳理一下Logistic Regression的过程:
回归的思想
Logistic Regression和线性回归一样,是回归中常见的算法。很多人刚接触Logistic Regression,不知道回归的含义。其实在念中学的时候学到的用最小二乘法求解线性回归方程,就是我们最早接触到的回归。在二维平面上有很多的点 <x1,y1>,<x2,y2>...<xn,yn> ,从这些点中选出一条直线,来很好的拟合这些点。通过求解,最后得到的回归方程形式是 y=bx+a ,然后来一个新的新的 x ,通过这个函数,能够计算得到对应的 y 的值。
所以一种常见的回归就是通过一系列的点,计算得到一条合适的线。当有新的输入时,可以直接计算得到输出。不局限于二维平面的话,点可以表示为 <x1→,y1>,<x2→,y2>...<xn→,yn> , x1→ 是一个 d 维的向量。对于线的表示都不尽相同,线性回归得到的预测函数形式是 y=w⃗ T∗x⃗ +a ,对于Logistic 回归,是一条“S”型曲线,在接下来会讲到。
还有一些回归不是通过得到一条线。比如使用决策树来回归。就是把一些点分布到树的节点上。每个节点的平均值就是作为回归值。
简单来说,回归就是根据输入预测一个值。
Logistic Regression形式
Logistic Regression最常见的应用场景就是预测概率。比如知道一个人的 年龄、性别、血压、胆固醇水平、体重,想知道这个人患心脏病的概率。首先很容易想到通过线性回归,根据这一组值来计算得到一个分数。对于病人的特征
(x0,x1,x2,...,xd)
,计算得到危险分数是
计算得到的分数越高,风险越大,分数越低,风险越小。s的取值是 [−∞,+∞] 的值,但是我们想要的是一个 [0,1] 之间的值。因此需要一个转换函数来把这个分数转换成 [0,1] 之间的值。这个函数称为Logistic 函数,Logistic函数是一个S形的函数。
形状如下图所示:

这个函数也称为sigmoid函数。函数能够把s映射到 [0,1] 之间,我们把这个函数称为 θ(s) 。Logistic函数形式为:
其中 e 即是自然常数。
因此整个Logistic Regression的函数形式为:
损失函数
在Logistic Regression函数中,我们使用最大似然方式来求解模型的参数。有关最大似然,维基百科有定义。
我们把真实模型称为
f
,学习得到的模型为
h
,
f
是未知的,要用
h
去拟合
f
。Logistic Regression的目标函数是,在已知
x
的条件下,输出
y=+1
的概率,
y=+1
即为
f(x)
,
y=−1
的概率为
1−f(x)
。对于数据集
D={(x⃗ 1,+1),(x⃗ 2,−1),...,(x⃗ n,−1)}
,抽取到该数据集的概率为
因为 f 是真正产生这个数据集的, f 产生这个数据集的概率应该是很大的(最大似然估计的思想)。如果我们用 h 来代替 f ,那么得到该数据集的概率为
其中,根据Logistic函数的对称性有 1−h(x⃗ )=h(−x⃗ ) 。从而有
我们要求解 maxhlikelihood(h) ,即需要求解 maxh∏ni=1h(yixi→) ,我们需要的是求得 w⃗ 这个参数,因此转换得到
这是一个连乘,两边取对,即可转换成连加。
求解上式的最大值,等价于求解
把 θ 函数定义代入,得到
定义
err(w⃗ ,y,x⃗ ) 为在极大似然估计下,Logistic方程的误差,称为cross entropy error。而让 Ein(w⃗ ) 最小的 w⃗ 是我们希望得到的Logistic Regression模型的参数。
最小化 Ein(w⃗ )
根据以上的推导,损失函数
Ein(w⃗ )
为
从数学上可以推导出 Ein(w⃗ ) 是连续平滑的,可微,且二次可微的,也是凸函数(来自林轩田老师视频)。要求 Ein(w⃗ ) 的最小值,就对 Ein(w⃗ ) 求微分,然后计算微分等于0的点。
对 Ein(w⃗ ) 在 w⃗ 每一个方向分量 wj 上求偏微分
把偏微分中的 xi,j 换成向量,则可以得到一阶微分:
∇Ein(w⃗ )
属于该损失函数的梯度,在二维空间的话我们称为斜率。如果直接令:
来求解的话,是很难求解出 w⃗ 的值的,因此需要使用其他方式。
梯度下降法
直接求解是无法求解出
w⃗
的,一种思想是采用迭代的方式求最小的
Ein(w⃗ )
。每次改变
w⃗
一点,尽可能使这个改变让
Ein(w⃗ )
朝着变得更小,这样逐步使
Ein(w⃗ )
趋近于最小值。如第
t
次到
t+1
次迭代,权重更新的形式如下:
其中 v⃗ 是一个单位向量, η 是步长。 Ein(w⃗ t+1) 应该要比 Ein(w⃗ t) 更小,这样的更新才有意义。因为我们是要找到 Ein(w⃗ ) 的最小值。
Ein(w⃗ t+1) 代入 w⃗ t ,得到 Ein(w⃗ t+ηv⃗ ) 。现在有 Ein(w⃗ ) 的一阶微分,可以对 Ein(w⃗ t+ηv⃗ ) 采用泰勒展开,如下:
忘记泰勒展开没关系,可以从直观上来理解这个式子。根据以上的结论,
Ein(w⃗ )
是存在最小值的,同时是光滑连续,可微及二次可微的。其曲线类似于下图:
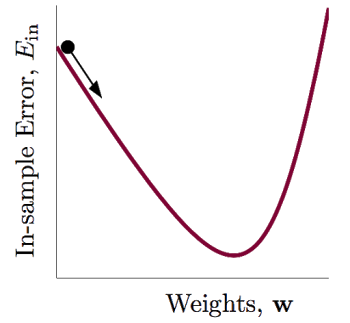
任何一条曲线,如果只看一小段的话,可以把这一小段曲线看成是一个线段。从数学上来讲,一个函数在某一点到附近的另外一点,可以用一个线段来表示。附近点的值为该点的值加上一小段线段的梯度,就得到了上式。
要使
Ein(w⃗ t)+ηv⃗ T∇Ein(w⃗ t)
比
Ein(w⃗ t)
小很多,必须
ηv⃗ T∇Ein(w⃗ t)
取最小值,
η
是不变的,两个向量相乘需要得到最小值,很显然方向相反时,向量乘积取得最小值。因此
v⃗
需要和
∇Ein(w⃗ t)
方向相反,同时
v⃗
是单位向量,因此在
wt
点时有
因此有 w⃗ 的更新方式为
到此,梯度下降总体思想结束了。梯度下降主要有两种方法,一种是随机梯度下降,一种是批量梯度下降。批量梯度下降每次更新权重需要训练完所有的数据,随机梯度下降每次训练完一条记录,就可以计算对应梯度,更新权重。在实际使用中,推荐使用随机梯度,收敛速度快。同时有关步长 η 的设置需要注意,设置太大会引起抖动,太小收敛速度太慢,可以采用动态的步长,比如一开始比较大,慢慢的缩小。迭代更新的停止条件从理论上来说是找不到更小的 Ein(w⃗ ) ,在实际使用可以直接设置一个比较大的迭代次数,或者根据经验设置一个迭代次数,一般都会收敛。当然这些都是工程上的东西了。
总结
到此基本讲完了Logistic Regression大部分内容了。当时在学校学完之后怎么也没懂,损失函数为什么是这样,为什么要使用随机梯度下降等等这些问题一直没有解决,虽然看看博客也能够做实验把代码写完(南京大学数据挖掘课程很赞啊)。最近在看林轩田老师的视频,慢慢弄,基本搞懂了。Logistic Regression作为常见的一类回归,其中的思想在很多算法中都用到。欢迎大家一起讨论。
Ref: http://blog.csdn.net/joshly/article/details/50494548















 3811
3811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









