






传送门
【STM32】STM32驱动 LCD12864程序代码(串行方式)_stm32操作19264-CSDN博客
学习LCD12864的时候遇到了显示乱码,此乱码很好解决(包括stm32cubeide中文注释乱码) ,
Project -Properties- Resource-Text file enconding改为GBK即可,如下图
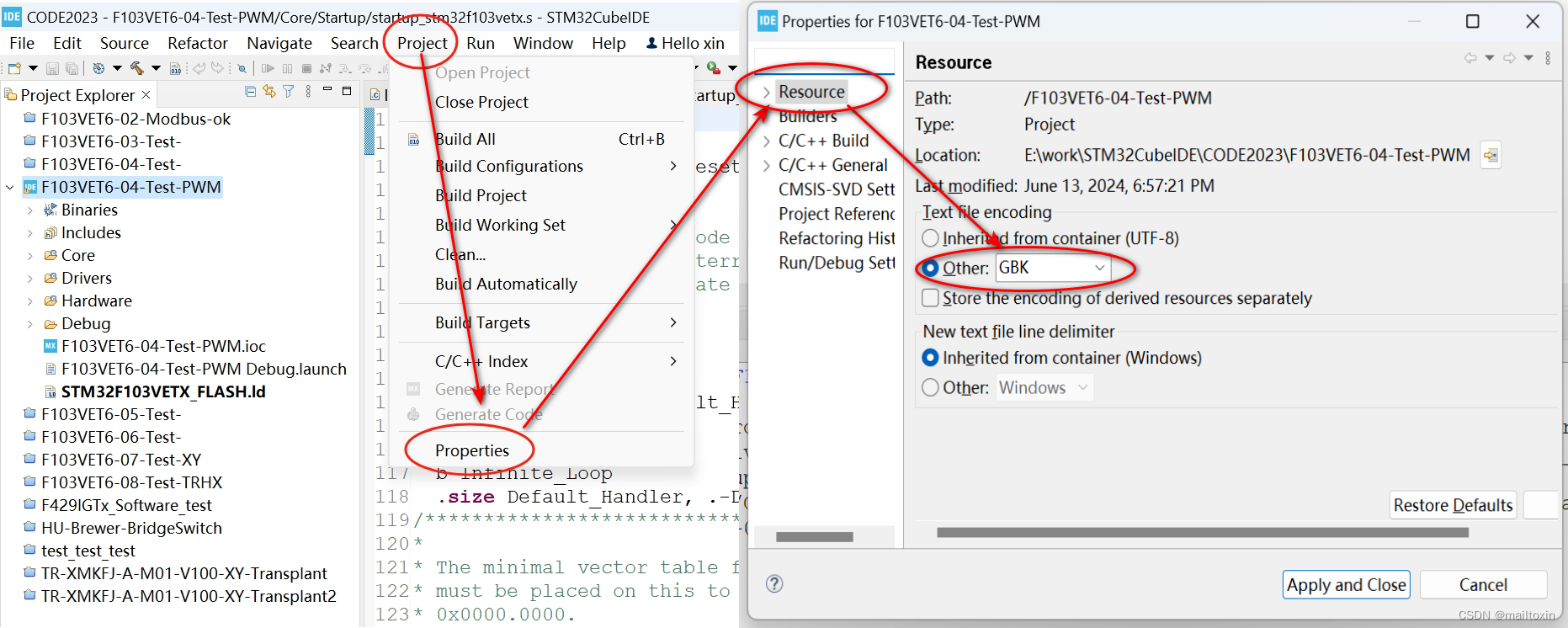
按照以上设置后LCD12864显示乱码的问题是解决了,但是控制台还是会有乱码,如下
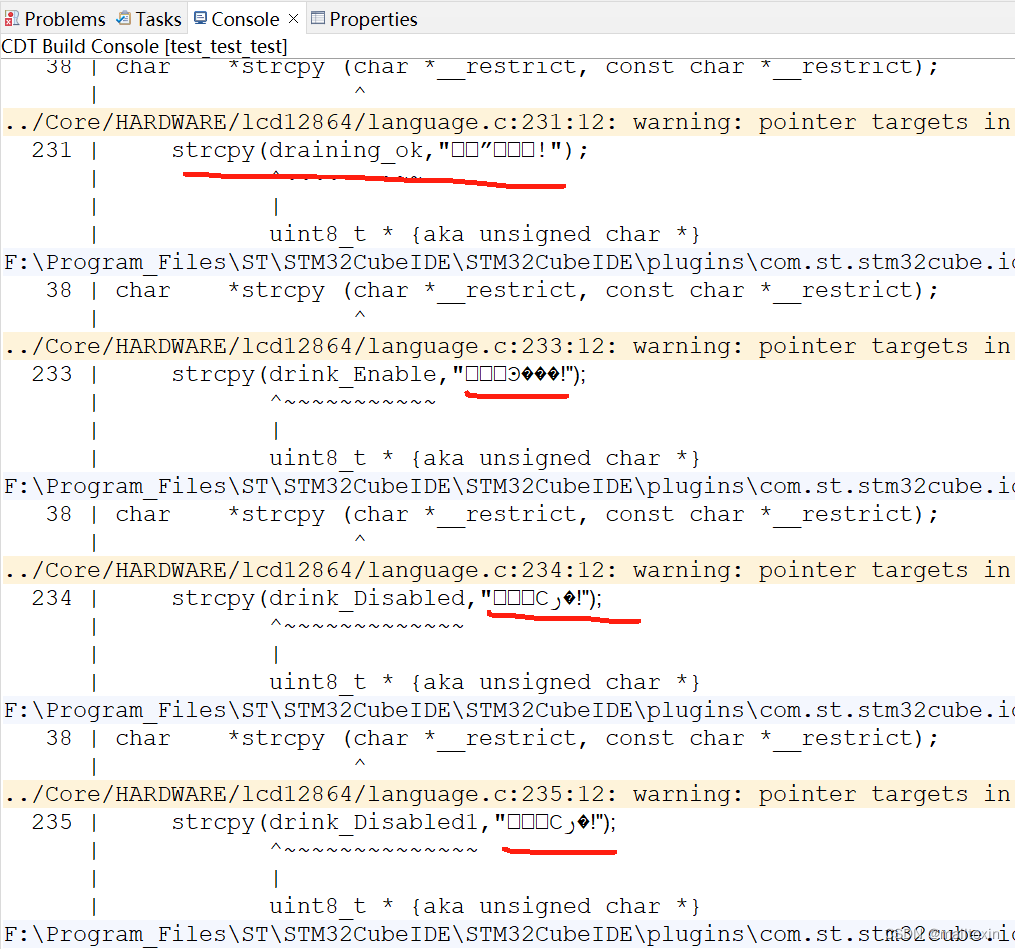
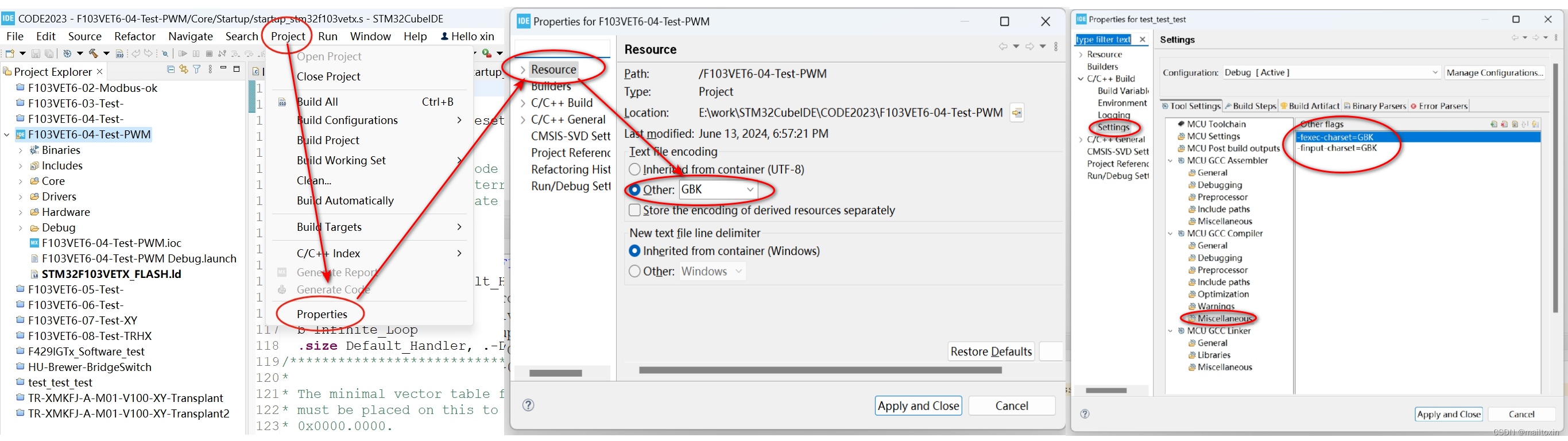
网上一通搜索,按如下设置就解决了
因为Project -Properties- Resource-Text file enconding设置为GBK
所以在C/C++Build - Settings - Tools Settings - MCU GCC Compiler - Miscellaneous下
做如下设置 (注意复制参数时不要有空格,否则会报错.)
-finput-charset=GBK (指定C文件中的文字编码格式)
-fexec-charset=GBK (指定编译之后的可执行文件的文字编码格式)
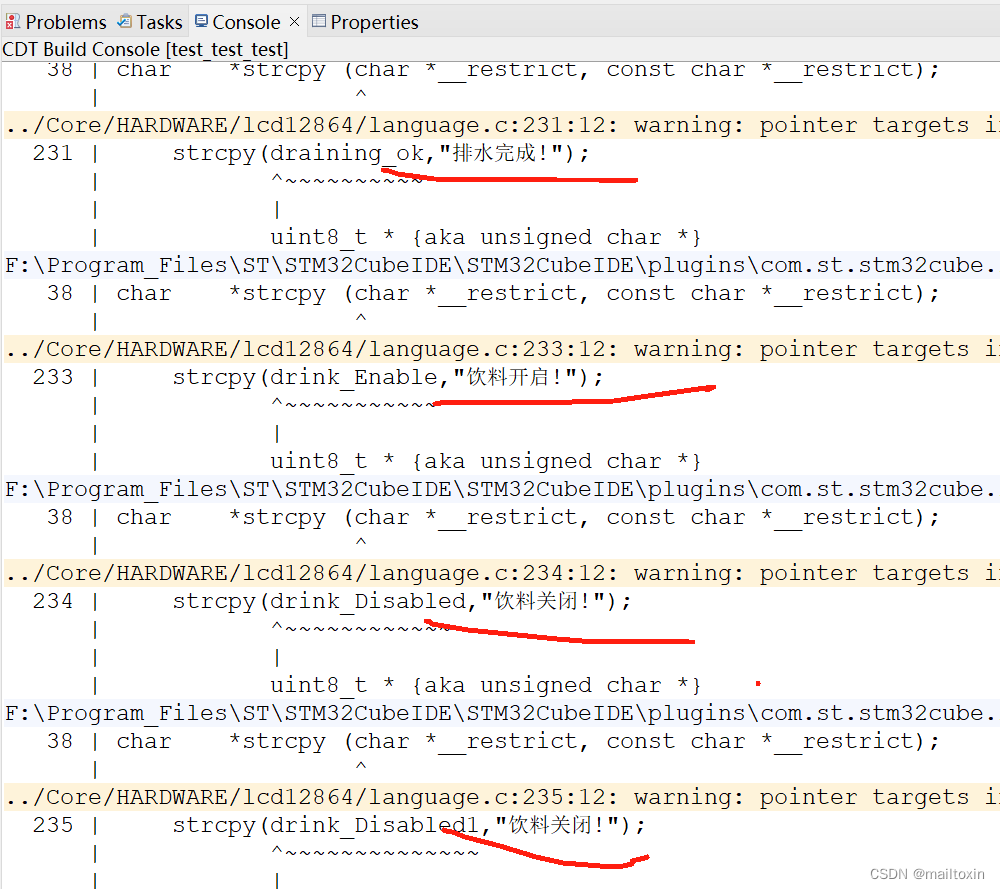
重新编译就可以看到控制台乱码就解决了.
问题解决后就会想到偷懒.
Project -Properties- Resource-Text file enconding 按默认参数 UTF-8,不作改动
C/C++Build - Settings - Tools Settings - MCU GCC Compiler - Miscellaneous下
做如下设置 (注意复制参数时不要有空格,否则会报错.)
-fexec-charset=GBK (指定编译之后的可执行文件的文字编码格式)

这样乱码的问题就解决啦
以下为转载
首先分清两个概念:C文件中(转换为16进制)汉字的编码,编译后bin文件中汉字的编码。
gcc的 -finput-charset 和 -fexec-charset 两个选项的存在就是为了实现这两者的转换。
1. 默认情况下,gcc使用UTF-8 charset。
2. C文件中使用GBK编码的汉字:若要使bin文件为UTF-8编码,必须同时指定 -finput-charset=GBK,-fexec-charset=UTF-8(不指定fexec-charset也是可以的,但是单独指定它无效,编译器会认为输入为UTF-8)。若要使bin文件为GBK编码,可以不指定charset,这样编译器就不会去做转换(它认为前后都是UTF-8),看起来就像是“骗过”了编译器;也可以同时指定 -finput-charset=GBK,-fexec-charset=GBK。
3. C文件中使用UTF-8编码的汉字:若要使bin文件为UTF-8编码,可以不指定charset;若要使bin文件为GBK编码,必须指定 -fexec-charset=GBK。当然,如果你想“欺骗”编译器:“我的C文件使用的是GBK编码”,而去指定-finput-charset=GBK,这时编译器可能不会像上面那种情况一样好骗,你可能收到这样一条答复:“cc1: error: failure to convert GBK to UTF-8”。
举个例子:我在程序中需要去调用HZK16(点阵字库),它是基于GBK编码的,所以,我希望我的bin文件中的汉字是GBK编码。我在UE编辑器中,使用GBK编码写了xxx.c,又使用UTF-8编码写了yyy.c,那么,我将可以用以下几种方式去编译它们:
对于xxx.c:
(1)gcc -o xxx xxx.c
(2)gcc -finput-charset=GBK -fexec-charset=GBK -o xxx xxx.c
对于yyy.c:
(1)gcc -fexec-charset=GBK -o yyy yyy.c
(2)gcc -finput-charset=UTF-8 -fexec-charset=GBK -o yyy yyy.c
总而言之,-finput-charset 用来指定 C文件中的文字编码格式,-fexec-charset 用来指定编译之后的可执行文件的文字编码格式;默认情况下,gcc编译器认为编译前后的文字编码格式都是UTF-8。
至于 “为什么要指定 -finput-charset 或者 -fexec-charset ?” ,那是可能你的程序中的某部分的操作必须依赖于某个特定的charset 。例如上文所说的,使用 HZK16 来获取汉字的位图等。















 3541
3541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









