







生成的代码
除了,从数据库中的内容写到HDFS,Sqoop还提供了写向当前本地目录的生成的Java源文件(widgest.java)。(运行完Sqoop导入命令以后,你可以通过 ls widgest.java 查看)
代码生成是Sqoop导入过程的一个必要部分;你会在483页,数据导入:深入学习,在导入HDFS前,Sqoop用生成的代码来反序列化数据库中的特定的表数据。
生成的类,有能力处理一个单独的记录,这个记录索引着导入的表。生成的类可以在Mapreduce中操作这样的一个记录,或者把记录以序列化文件存储在HDFS中。(在导入数据期间,Sqoop所写的序列化文件会存储导入的每一行,行是key—value格式的)。
可能,你不想命名你的生成的代码,因为类的每一个实例只指向一个单独的记录。我们可以使用Sqoop的另一个工具来生成源代码,而不使用import命令,这个生成的代码也会检查数据库中的表,以决定每个字段最合适数据类型。
% sqoop codegen --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets --class-name Widget
这个代码生成工具,只是简单的生成代码,它不会执行完全的导入。我们指明想生成一个名为widget的类,生成的代码
就会被写进一个Widget.java。我们同样可以,在导入过程之前,指定类的名字和其它的生成代码的参数。
这个工具可以被用来重新生成代码,如果你不小心删除了源代码的时候。
如果你处理导入序列化文件中的记录,那么,不可避免的,你要使用生成的代码(从序列化存储的文件中反序列化数据)。
你可以不用生成的代码,就处理文本格式的记录,但是在486页的“处理导入的数据”中,Sqoop的生成代码可以处理一些数据处理过程中的冗长的方面。
其它的序列化系统
由于Sqoop处在发展阶段,Sqoop序列化的方法和处理数据的方法在不断增加。目前Sqoop的实现需要生成的代码来实现Writable接口。未来的Sqoop版本应该能够支持Avro格式的序列化(Avro 相关在103页),并且允许你在项目中使用Sqoop的时候,不必再整合生成的代码了。
数据导入的深入学习
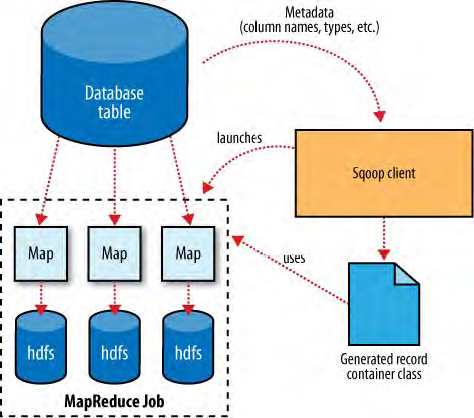
之前提过,Sqoop运行Mapreduce job从数据库中导入数据,Mapreduce job从表中抽取行,并把这些记录写到HDFS中。那么,Mapreduce是怎么读取表中的行的呢?这部分就介绍下。
表15-1展示了Sqoop与数据库和Hadoop怎样交流的。像Hadoop一样,Sqoop也是用Java写的。Java提供了一个叫做java 数据库连接的API,也就是JDBC,这个API允许程序访问RDBMS中的数据。大多数数据供应商会提供一个JDBC驱动来实现JDBC API,驱动中包含连接到他们的数据库服务器的必要的代码。
注:Sqoop尝试预测它要载入的驱动。你可能仍然需要下载JDBC驱动,并安装在Sqoop上面。有些时候,Sqoop不知道那种JDBC合适,用户可以在Sqoop中详细的指明怎样载入JDBC驱动。这种兼容性,允许Sqoop与很多种数据库平台使用。
在导入开始之前,Sqoop使用JDBC来检查它将要导入的表。它索引所有列和他们的SQL数据类型。这些SQL数据类型(VARCHAR,INTEGER, 等等)可以被映射成Java的数据类型(String, Integer, 等等),这些类型组成Mapreduce程序中的value字段。Sqoop的代码生成器会使用这个信息来创建一个特定的表,来存储从表中抽取出来的记录。
举例,Widget 类包括如下的方法来索引记录中的每一列:
public Integer get_id();
public String get_widget_name();
public java.math.BigDecimal get_price();
public java.sql.Date get_design_date();
public Integer get_version();
public String get_design_comment();
导入数据,更关键的一点是,DBWritable接口的序列化方法,序列化方法允许Widget类与JDBC交流:
public void readFields(ResultSet __dbResults) throws SQLException;
public void write(PreparedStatement __dbStmt) throws SQLException;
JDBC的结果集接口提供了一个游标,它索引查询出来的记录;这里的readFields()方法,用结果集的数据中一行的所有列填充Widget对象的字段。write()方法,允许Sqoop向表中插入新的行,这一过程叫做导出。导入过程将在491页的“执行导出”讲述。(此处应为导出,之前笔误 写成了导入)
Sqoop启动的Mapreduce job使用InputFormat,InputFormat可以通过JDBC,读取数据库中的一个表。DataDrivenDBInputFormat通过几个Map tasks给Hadoop提供了一个查询结果。
读取一个表的典型操作是下面的一行简单查询语句
SELECT col1,col2,col3,... FROM tableName
但是,通常情况下,更好的策略是,导入的性能可以提高,通过把查询过程分布在多个节点上面。使用splitting column 方法来实现这种策略。根据表的元数据,Sqoop会猜测一个合适的列来分割表(典型的方法是,表的主键,如果主键存在的话)。主键列的最小和最大值被索引出来,用来与固定数量的task连接,来决定每一个map task应该解决的查询。
例如,假设widgets表有100,000个实体,id列包含0到99,999。当导入这个表的时候,Sqoop应该决定id列为表的主键列。当执行Mapreduce job 的时候,DataDrivenDBInputFormat被用来执行导入工作,它发出一个这样的语句:SELECT MIN(id), MAX(id) FROM widgets。这些值用来插入整个范围的数据。假设,我们指定了5个map tasks 分布运行(使用 -m 5),那么就是每一个map都执行这样的查询语句SELECT id, widget_name, ... FROM widgets WHERE id >= 0 AND id < 20000, SELECT id, widget_name, ... FROM widgets WHERE id >= 20000 AND id < 40000,等等。
分割列,对于分布式工作效率的提高,是很有必要的。如果列并不是平局分布的(可能,在50,000到75,000之间没有IDs),那么有些map可能有很少的或者没有工作可做。尽管其它的map有很多工作要做。在导入的时候,用户可以根据数据的真实分布情况,指定一个特定的分割列的方法。如果导入过程只用一个map task,那么分割是用不到的。
在生成了反序列化代码并且配置好InputFormat之后,Sqoop发送job给Mapreduce集群。Map tasks 执行查询,并且反序列化ResultSet的行到生成类的实例。这些数据直接存储在序列化文件中,或者在写到HDFS之前,转化成分割开来的文档。
控制导入
Sqoop不需要一次性导入一个完整的表。例如,表的一部分可以被特定的导入。用户也可以在查询中指定一个WHERE语句,它指定了要导入的表的行数范围。例如,上个月,导入了widget的0到99,999行数据,但是这个月我们的log新增了1,000个数据,现在,导入工作就是要配置导入过程WHERE id >= 100000。用户支持的WHERE语句是在task分割执行之前,并且每个task都会执行这些查询。
导入和一致性
当向HDFS中导入数据时,保证你访问的原数据的快照是一致的,这是很重要的。Map tasks从一个数据库中分布的读取数据,是运行在分开的进程中的。因此,他们不能分享一个单独的数据库事务。最好的方法是,保证,任何更新表中存在的行数据的进程,在导入过程中是不运行的。
直接模式导入
Sqoop的架构允许它在多种导入数据的策略中选择。大多数数据库,会使用基于DataDrivenDBInputFormat的上面提到的方法。有些数据库提供了,快速抽取数据的特定设计的工具。例如,MySql的mysqldump程序可以比JDBC管道更大产量的读取一个表。这些工具的使用,在Sqoop文档中定义为直接模式。直接模式,必须被用户明确指定启用(通过--direct 参数),但是,这种方式不像通常的JDBC方法一样通用(例如,MySql的直接模式不能处理大数据-CLOB或者BLOB列,Sqoop应该使用JDBC特定的API来加载这些列到HDFS中)。
提供了这样工具的数据库,Sqoop可以使用它们来提高效率、一个从MySql直接模式的导入
通常情况下效率更高。Sqoop会分布式的启动多个map tasks。这些tasks会生成mysqldump的实例,并且读取它的输出。
尽管直接模式用来访问数据库的内容,但是原数据的查询仍是通过JDBC进行的。















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









