









时间限制:
1000ms
单点时限:
1000ms
内存限制:
256MB
-
2 ATCGATAC 2 ATACGTCT 6
样例输出
-
1 3
描述
小Hi和小Ho正在进行一项基因工程实验。他们要修改一段长度为N的DNA序列,使得这段DNA上最前面的K个碱基组成的序列与最后面的K个碱基组成的序列完全一致。
例如对于序列"ATCGATAC"和K=2,可以通过将第二个碱基修改为"C"使得最前面2个碱基与最后面两个碱基都为"AC"。当然还存在其他修改方法,例如将最后一个碱基改为"T",或者直接将最前面两个和最后面两个碱基都修改为"GG"。
小Hi和小Ho希望知道在所有方法中,修改碱基最少的方法需要修改多少个碱基。
输入
第一行包含一个整数T(1 <= T <= 10),代表测试数据的数量。
每组测试数据包含2行,第一行是一个由"ATCG"4个大写字母组成的长度为N(1 <= N <= 1000)的字符串。第二行是一个整数K(1 <= K <= N)。
输出
对于每组数据输出最少需要修改的碱基数量。
这种题目是如果你没有发现到这个敲门你就做不出来。。
思路:
其实问题解法都可以归为一类,不管是前缀和后缀有没有交叉重合。
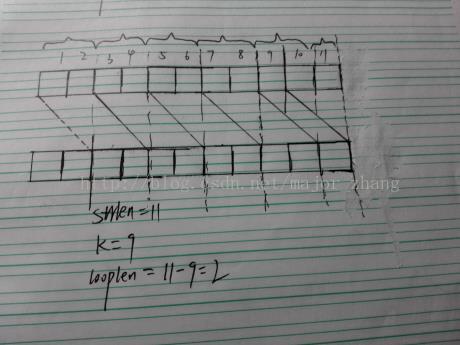
有重合的时候,如图,可以看到其实要想满足题意,出现的必须是循环节,现在只要依次遍历循环的每一位,每一位的总和减去出现次数最多的就是这个位要变换的碱基数,变换成次数最多的这种碱基嘛。累加每个位上统计的即可。
当没有重合时,问题似乎更简单了,这里其实不用再分类,

这时候循环节是4,其实在遍历中间的两位时,超出了范围,在第一种方法的代码里就忽略掉了。所以重合的解决方法也适用这种情况。直接一次AC。
import java.util.Scanner;
class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int T = sc.nextInt();
while(T-->0) {
String str_gene = sc.next();
int K = sc.nextInt();
int loop_len = str_gene.length() - K;
int ans = 0;
for(int i = 0; i < loop_len; i++) {
int[] cnt = new int[4];
for(int j = i; j <str_gene.length(); j+=loop_len) {
if(str_gene.charAt(j) =='A')
cnt[0]++;
else if(str_gene.charAt(j) =='T')
cnt[1]++;
else if(str_gene.charAt(j) == 'C')
cnt[2]++;
else if(str_gene.charAt(j) == 'G')
cnt[3]++;
}
int sum = 0;
int Max = 0;
for(int c = 0; c < 4; c++) {
sum += cnt[c];
Max = Max > cnt[c]?Max:cnt[c];
}
ans += (sum - Max);
}
System.out.println(ans);
}
}
}















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









