







介绍:Tesseract是一个Google支持的开源的OCR图文识别开源项目,可以较好的识别常见的字体(字母、数字和汉字)并且可以根据需求训练出指定字体的字库,GitHub上有众多开发者贡献的字库。
最近Boss让破解一中类型的验证码,大概长这个样子
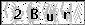
破解的详细过程下面会慢慢描述,在破解的时候遇到了各种坑,然而总结出来就只有这两点
1、图片不能太小
2、图片不能太脏
满足了这些条件破解成功率基本就能保证在85%以上
首先安装tesseract(需要JDK环境),并下载jTessBoxEditor训练字库工具
一、图片的预处理
处理干净的图片可以提高识别率,对于上面这种干扰点和背景色比较乱的验证码来说是必不可少的一步,我就对上面的图片进行了比较繁琐的处理,最后得到的结果完全就是一个白色的背景和剩下的字母数字,如果需要,可以将图片放大几倍提高正确率;
然后就需要一个比较全的样本文件集合,我将上面的一个验证码切割成了四个独立的图片文件(当然了,一个好的验证码要有随机的扭曲和黏合,字符不能只出现在固定的位置,这种才能称为有效的验证码,否则能被这样切割成独立字符的简直就是对验证码的侮辱)拉取了上千个验证码后就能得到相当丰富的样本集。
在样本中选取一些比较有代表性的字符取组装成一个模版:
1、大写字母:
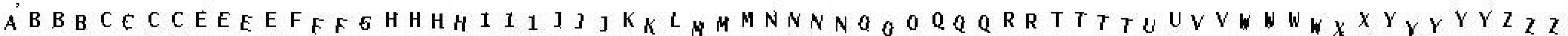
2、小写字母:
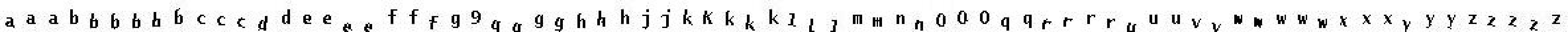
3、数字:
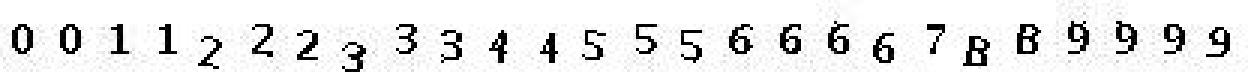
二、训练字库
使用jTessBoxEditor将上面的图片模版合并成一个tif文件:
Tools–>Merger TIFF(使用shift选中多个文件)
然后输入命令行生成box文件
tesseract ybx.font.exp0.tif ybx.font.exp0 batch.nochop makebox
ybx.font.exp0.tif是我tif文件的名称,tif和box名称要保持一致并且要符合以下格式:
tesseract [lang] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6979
6979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









