







author: 张俊林
谷歌DeepMind开发的人工智能围棋程序AlphaGo以5:0的压倒性优势击败了欧洲围棋冠军、专业二段棋手Fan Hui,这是最近一周来最火爆的新闻了。16年3月份AlphaGo会和最近10年平均成绩表现最优秀的韩国九段、世界冠军李世石进行对弈,这无疑也是最吸引眼球的一场人机世纪大战,如果此役AlphaGo获胜,这意味着人工智能真正里程碑式的胜利,从此起码在智力博弈类游戏范围内,碳基体人类将无法抵挡硅基类机器的狂风骤雨,不知这是该令人惊恐还是令人兴奋呢?
反正我是属于看了这个新闻像被注射了兴奋剂似得那类具备反人类人格犯罪分子的兴奋类型@^^@。
当然,本文的标题有点哗众取宠,但是并非毫无根据的。现在的问题是:三月份的人机大战中,李世石的胜率能有多高?是AlphaGo击败人类还是李世石力挽狂澜,维护人类尊严?此前众说纷纭,各种说法都有。但是看上去都是没什么依据的猜测。我在深入了解了AlphaGo的AI运作机制后,斗胆做出如下预测,到时可看是被打脸还是能够成为新世纪的保罗,首先强调一点,我这个预测是有科学根据的,至于依据是什么,后文会谈。
如果是5番棋,预测如下:
如果李世石首局输掉,那么AlphaGo很可能获得压倒性胜利,我预估AlphaGo会以4:1甚至5:0获胜;
如果李世石首局赢,但是第二局输掉,那么AlphaGo可能会以3:2甚至4:1胜出;
如果李世石首局和第二局都赢,那么AlphaGo可能会碾压性失败,局面可能是0:5或者1:4;
也就是说,局面很可能是一方压倒性胜利,要么是AlphaGo要么是李世石,而且首局胜败可能起到关键作用,为什么这么说呢?我们要了解AlphaGo是怎么下棋的。
|下围棋的本质是什么?
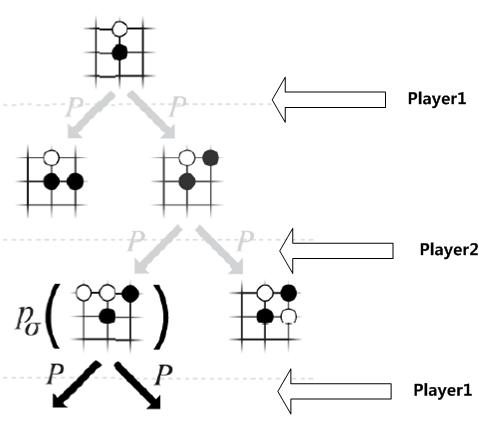
图1 下围棋是在干什么
下围棋的本质是在干什么?图1其实基本就说明了问题了。两个棋手(这两个棋手可能其中一个人类一个AI,也许两个都是人类或者两个都是AI,这不重要)刚开始都是面对一个19*19的空棋盘,执黑先下子,下子是什么意思?就是在当前棋局S下(刚开始S就是空棋盘),判断下个子应该放在哪里更好,所有合法的落子位置都在考虑范围,比如开局第一子,任何一个棋盘位置落子都是可以的,但是这里面有些是好的落子位置,有些是不好的落子范围,至于到底好不好,因为棋还没下完,暂时不知道,只有最后决出输赢才能说这个子落得好不好。
如果黑方选定了一个落子位置,则棋局局面从S进入到S1,此时该白方下,一样的,白方面对很多可能的落子选择,然后选择一个他认为最好的…..就这么依次下下去,直到决出输赢为止。
从这里可以看出,从落第一个子到下完,整个下子的决策空间形成了一个非常巨大的树形结构。之所以我们说围棋难,就是因为这颗树的宽度(就是应该落哪个子)和深度(就是一步一步轮着下子)都太大了,组合出的可能空间巨大无比,基本靠搜索遍整个空间是不可能做到的。
所以你看到下围棋本质是什么,就是在这颗超大的树搜索空间里面,从树的根节点,也就是空棋盘,顺着树一路下行,走出一条路径,路径的末尾就是已经决出胜负的棋局状态。
因为搜索空间太大,所以围棋AI不可能遍历所有可能的下棋路径,那么只能学习一些策略或者评估函数,根据这些策略能够大量减少搜索空间,包括树的宽度和深度。
有了这个基础,我们可以讲AlphaGo了。
AlphaGo的技术总体架构如果一句话总结的话就是:采用深层CNN神经网络架构结合蒙特卡洛搜索树。深度学习神经网络训练出两个落子策略和一个局面评估策略,这三个策略的神经网络架构基本相同,只是学习完后网络参数不同而已。而且这三个策略是环环相扣的:落子策略SL是通过学习人类对弈棋局,来模拟给定当前棋局局面,人如何落子的思路,这是纯粹的学习人类下棋经验,它的学习目标是:给定某个棋局形式,人会怎么落子?那么AlphaGo通过人类对弈棋局来学习这些落子策略,也就是说SL策略学习到的是像人一样来下下一步棋;
落子策略RL是通过AlphaGo自己和自己下棋来学习的,是在SL落子策略基础上的改进模型,RL策略的初始参数就是SL落子策略学习到的参数,就是它是以SL落子策略作为学习起点的,然后通过自己和自己下棋,要进化出更好的自己,它的学习目标是:不像SL落子策略那样只是学习下一步怎么走,而是要两个AlphaGo不断落子,直到决出某盘棋局的胜负,然后根据胜负情况调整RL策略的参数,使得RL学习到如何能够找到赢棋的一系列前后联系的当前棋局及对应落子,就是它的学习目标是赢得整盘棋,而不是像SL策略那样仅仅预测下一个落子。
局面评估网络Value Network采用类似的深度学习网络结构,只不过它不是学习怎么落子,而是给定某个棋局盘面,学习从这个盘面出发,最后能够赢棋的胜率有多高,所以它的输入是某个棋局盘面,通过学习输出一个分值,这个分值越高代表从这个棋盘出发,那么赢棋的可能性有多大;
有了上面的三个深度学习策略,AlphaGo把这三个策略引入到蒙特卡洛搜索树中,所以它的总体架构还是蒙特卡洛搜索树,只是在应用蒙特卡洛搜索树的时候在几个步骤集成了深度学习学到的落子策略及盘面评估。
AlphaGo的整体技术思路就是上面说的,那么我们从这些技术原理可以得出什么结论呢?我对各个部分的分析和结论如下,这也是为何本文开头作出那个人机大战预测的科学依据所在。
|SL落子策略
首先,我们看落子策略SL,就是那个根据人类对弈过程来学习像人一样落子的策略。这个策略重要吗?重要,但是只靠这个策略能够战胜人类世界冠军吗?我的结论是不可能,靠这个策略一万年也赢不了人类。为什么呢?你要考虑到很关键的一点:AlphaGo这个策略是通过看了16万局人类对弈棋局来学习的,但是问题的关键是,这些下棋的人素质总体有多高?如果以职业棋手水平来衡量,平均下来总体素质其实是不高的,里面大量棋局是业余选手下的,即使有不少专业选手下,高段位选手肯定不会太多。那么AlphaGo从这些二流选手下棋落子能够学到每步棋都达到九段水平吗?这不太可能。
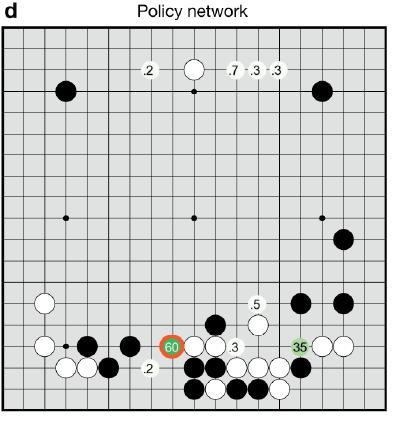
图2 AlphaGo和fan hui对弈过程中的SL落子策略得分,图中某些位置的得分代表AlphaGo认为落子位置有多像人会选择的落子位置
所以我的结论是:如果人工智能程序只能从人类棋手下的盘面学习,按照目前的学习方式,机器永远也无法战胜最好的人类,因为它学习的对象平庸者居多,三流师父永远教不出一流的徒弟,这个道理很简单。如果只用这个方法,就算AlphaGo看到再多人类的比赛也无法战胜人类,除非它看到的都是超一流选手的盘面,那么它可以成为超一流选手,但是面对人类最强手,并没有必胜的把握。
那么岂不是说三月的对决中,AlphaGo必败无疑了?其实不然,上面这点说的是SL策略的弱点,但是AlphaGo的论文给出了数据,SL策略比传统单纯使用蒙特卡洛搜索树的策略下子准确率从44%提升到了55%左右,这个55%是什么意思?意思是SL策略做了100次落子,其中55个落子是和人落子位置相同的。看上去55%好像也不太高么,没什么可怕的,你肯定这么想,是吧?你错了!你要看44%到55%的提升幅度,因为SL策略只是决定了单步落子,而单步落子小幅度的准确率提升,会极大提升最终赢棋的胜率,因为你想啊,一个棋局是由几百个落子构成的,每一步的小幅度准确率提升,经过几百次不断累积,那最终结果差异是非常大的,这就是所谓的“积小胜为大胜”的道理。这是机器对人很大的一个优势,因为它稳定,如果准确率达到一定程度,就不容易出昏招,只要依靠每一步的小优势不断积累就能获得巨大的累积优势。
人类其实相对机器还有一个很大的劣势:人的理性决策太容易受到情绪影响,一旦自己局面处于不利地位,或者自己下了一步臭棋,估计后面连续若干落子都会受到影响,而且下到后面人估计比较疲劳了,算棋能力下降难免,但是机器完全没有这两个问题,可以很冷血很冷静的跟你下,下了好棋也没见AlphaGo笑,下了臭棋也没见AlphaGo哭,体力无敌,只要你不拔它的电源插头,它就面无表情地跟你死磕到底,是不是这个道理?
所以说,即使AlphaGo只有SL落子策略,如果它的落子水平是5段,那么其实考虑到这些优势,它基本上是能稳赢人类5段这种相同段位棋手的。这也是为何本文开头预测三月人机大战可能是如此结果的一个重要参考因素。李世石肩上担着这么个重担,而且这是世界瞩目的一场比赛,他完全没有心理负担是不可能的,也许他看了AlphaGo和Fan Hui的棋局,现在心理上同时蔑视AlphaGo和Fan Hui棋力渣,但是如果初赛不利,很可能会被冷血的机器打崩溃。
|RL落子策略
然后,我们再来看落子策略RL。前面提到,它学习的目的和落子策略SL不一样,落子策略SL就是学习单步如何像人一样落子,至于后面这局棋是输掉还是赢了它其实没学到什么东西,它只要保证说面对目前的棋盘布局,像人一样落下下一个子就行了。而落子策略RL学习目标则是以赢棋为目的,是说经过若干轮博弈,最终赢棋那么它就认为在这个对弈过程中的相应的棋局和落子就是值得鼓励的,并把这些鼓励体现到深度学习模型参数里面,意思是以后看到类似的局面,更倾向于这么去落子,因为这么落子很可能最终会赢棋。它自己和自己下完一局棋,如果胜利了,那么在这条通向胜利结果过程中的所有棋局对应的落子都会得到鼓励。
其实对于人类来说,这种自己和自己下棋的RL落子策略才是真正可怕的,因为它可以通过这种方式不断自我进化。它自己和自己下了一盘棋等于干了个什么事情?等于说在下棋落子巨大的树组合空间中,搜索找到了其中一条从空棋盘开始到最终胜负已分通向胜利的一条落子路径,而根据这个路径是赢了还是输了调整模型参数,使得模型以后更倾向于选择这条路径;意思是如果以后和人下棋,一旦有一局中某个落子方式在它的这个学习路径中,那么它就倾向于走出那一系列让它赢的策略。因为它的核心目的等于是在所有树空间里搜索,然后学习找到那些容易赢的路径,学习的结果是更倾向找到那些导致最终赢旗的路径,这个只要不断地自己和自己下理论上能力是能够不断提高的,因为围棋组合出的树空间虽然巨大无比,毕竟还是有限的,自己和自己对战等于在不断找出并记住那些能够赢棋的落子路径,对战次数越多,穷举出这些路径的可能性越大,也就意味着它棋力在不断提升。从这个角度看,这也是为何说它可怕在此处的一个原因。
当然,这个左右互搏的自闭症儿童式的自我下棋,它也不是没有弱点,它的弱点是:AlphaGo是根据一个赢旗的路径走的,倾向于学习这个路径上的落子策略,但是在真实下棋过程中,也许对手不会选择这条路径,那么后面学到的看似就没用了,但是这个弱点其实在现实场景中问题也不大:因为AlphaGo的自我下棋的对手(也是它自己)也是有一定水平的,所以对手选择的落子也会很高概率落在真正人类选手选择的落子位置,即是说它选择的这个路径是在再次和其它对手下很可能走的一条路,如果再完全重走这条路径,那么计算机必赢。
综上分析,落子策略RL通过这种自我对战来在巨大的树搜索空间中找到赢棋路径的方法是比较可怕的,因为理论上它只要不断自我对弈,是能够不断提高下棋水平的。这是人机对决中人类不乐观的的一个方面,因为就像上面说的,只要你不拔机器的电门,它就可以不眠不休地去玩自闭症游戏,其实人工智能不可怕,可怕的是能够不断自我学习自我进化的人工智能。
|棋局评估Value Network
Value Network也是通过3000万盘AlphaGo自我对战来进行学习的,它是建立在RL落子策略之上的,因为此刻RL落子策略已经代表了一个棋力比较高的棋手了,不过这个棋手就是AlphaGo自身而已。Value Network它要学习什么东西?它要学的是:给定当前棋局布局,也就是AlphaGo看到的当前棋盘情况,那么这个棋盘布局有多大可能会导致最后赢棋?这就是它学习的目标。Value Netwok的本质思想是:如果当前棋局处于局面S,那么假设这时候有两个目前最强的棋手,就是两个采取RL策略的棋手从局面S开始继续往下下棋,那么从局面S出发,最终赢旗的可能性有多大;因为这两个RL棋手会尽可能走那些局面S出发产生的子树里面,它们各自认为能够导致胜利的路径,所以一般是树搜索子空间里面容易被棋手选择到的路径,评估了这些路径后综合出这种棋局S最终可能胜利的可能性,获胜可能性越大,意味着从棋局S出发的这个搜索个子树空间里面通向胜利局面的路径越多,所以它是个“大面积搜索路径覆盖”的策略;
其实综合上面三个策略,可以看出:SL落子策略类似于点覆盖,因为它只考虑下步旗子怎么走,只覆盖了一步棋;RL落子策略类似于线覆盖,因为它其实在找一条能够赢棋的走棋路径;而Value Network类似于面覆盖,因为它评估的是当前棋局S出发,所有可能走的搜索路径中综合看通向胜利的下棋路径有多少,越多越好;AlphaGo就是这么利用深度学习来进行搜索空间点线面结合来提升棋力的。
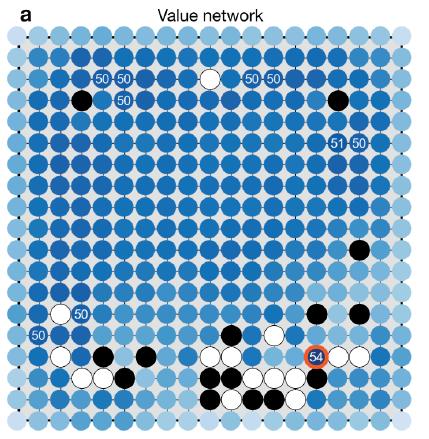
图3 AlphaGo和Fan Hui对弈过程中,对棋局的评估,对应位置的得分意味着如果把旗子落子这个位置,那么这个落子后的棋局最后赢棋的可能性
|蒙特卡洛搜索树
蒙特卡洛搜索树可以说是一项导致围棋人机对战过程中突破性的技术进展,有了蒙特卡洛搜索树,就把机器选手从没资格和人类对战带到了有资格和业余选手进行对战的境地,但是仅仅靠蒙特卡洛树是不够的,因为树搜索空间太大,如果蒙特卡洛采样太多,固然容易找到下棋的最优路径,但是速度会太慢,跟它下人类选手会掀桌子的,所以在实战中采样不可能太多,那么很可能就找不到最优下棋路径,这也是为何在获得能和业余选手对战后,难以再获得大的突破的主要原因。
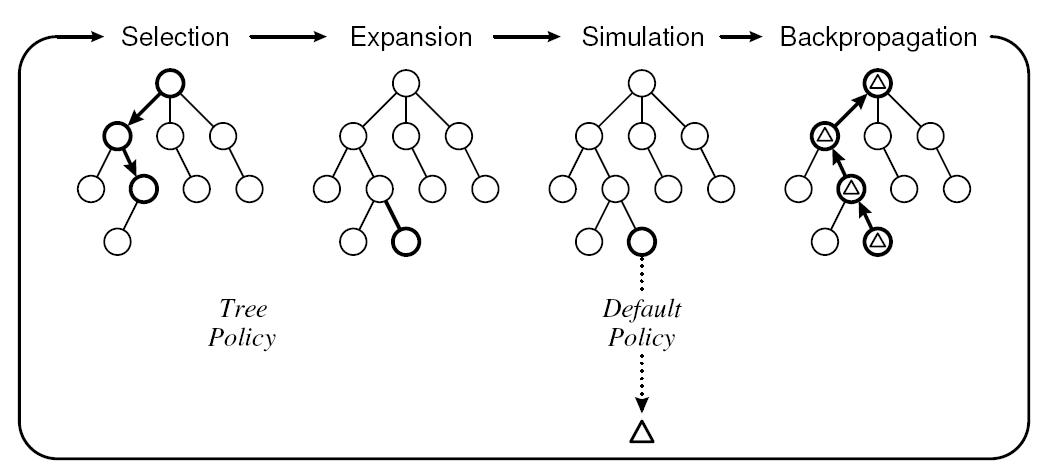
图4. 蒙特卡洛搜索树
AlphaGo本质上大的技术框架还是蒙特卡洛树,但是根本的不同在于把上面讲的两个落子策略和一个局面评估神经网络引到蒙特卡洛树搜索过程中。蒙特卡洛搜索树也需要对棋局盘面进行评估,AlphaGo采用了上面讲的Value Network和传统的采样评估相结合的思路来做;在采样进行过程中,要模拟两个棋手对弈,AlphaGo采用了落子策略SL来模拟两个对战棋手;而落子策略RL则用在了Value Network网络中,我们讲过Value Network是在RL策略基础之上的,其作用也是类似两个采取RL策略的棋手去下棋。
决定蒙特卡洛搜索树效果的其实主要有两个因素,一个就是上面讲的采样数量,数量越大效果越好,但是速度会比较慢,在这点上AlphaGo其实并没太在意;第二点是模拟两个棋手对弈,那么这个棋手棋力越强,那么快速探索出优秀路径的可能性越大,AlphaGo其实把工作重心放在这里了,也就是那两个落子策略和Value Network棋局评估策略。这也是为何说AlphaGo有技术突破的地方,因为它的重心不在暴力搜索上,而是寻找好的下棋策略。
前一阵子网上讨论Facebook围棋AI “暗黑森林”和AlphaGo谁先谁后问题,其实你看过他们各自发的论文就明白这种争论完全没有必要,之前有几项工作都是结合深度学习学习落子策略和蒙特卡洛搜索树方法结合的文献,但是效果应该仍然徘徊在和业余棋手对弈的阶段,包括Facebook的围棋AI,本质上并没有跳出这个思路。导致AlphaGo和其它工作最大的不同其实是那个通过3000万局自我对战产生的RL落子策略和Value Network,而这两者在其中发挥的作用也是最大的,所以AlphaGo对围棋AI产生质的飞越是无可置疑的。而没有疑问的一个坏消息是,即使3月份AlphaGo输掉比赛,从机制上讲,AI胜过人类选手是必然的,这只是时间问题而已。
AlphaGo的意义不仅仅在于围棋领域,由于DeepMind采用通用的AI技术来研发AlphaGo,其关键算法能够平滑迁移到很多其它领域,并有望在很多其它领域获得突破性进展。另外,我的个人意见,DeepMind是个令人尊敬的技术团队,他们关注的都是深度学习中重大的问题并不断有突破性成果出来,搞研究其实就应该以这种团队作为榜样。
上面这段看上去好像是要结尾的意思,其实并不是,我们最后再附上一小段技术流。
|深度学习网络架构
上面讲过两个落子策略以及棋局评估神经网络,其架构都是类似的,其中两个落子策略的架构如图5所示,棋局评估神经网络的架构如图6所示。
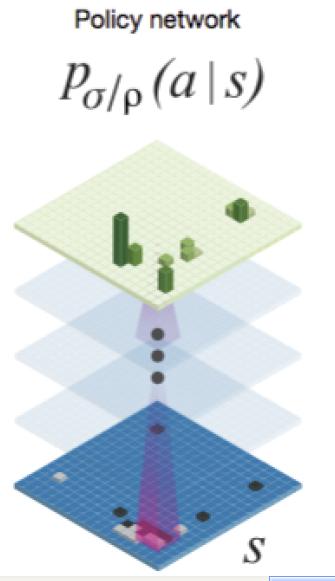
图5 Policy Network网络结构
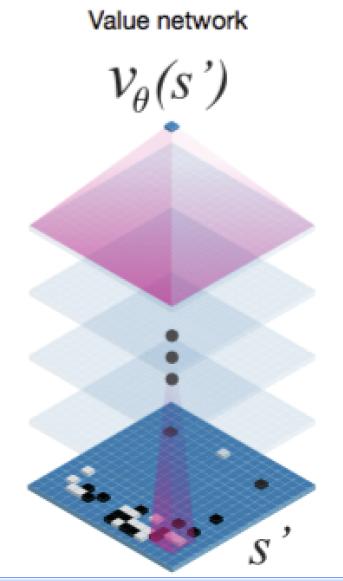
图6 Value Network网络结构
对于两个落子策略来说,其神经网络的输入是19*19*48的三维数据,19*19是一个棋盘的画面,48是因为选择了48类特征来从不同角度描述这个棋盘,所以输入是三维结构。经过12层CNN的卷积层,然后最后套上一个SoftMax分类层。输入是棋盘局面S,输出是针对这个棋盘局面,下面应该如何落子,所以SoftMax分类层给出的是各种合法落子位置的分类概率。AlphaGo就选择概率最高的那个位置去落子。
对于SL落子策略来说,训练数据就是3000万<S,a>集合,就是人下棋的过程,S是面对的某种棋局,a是人接下来把旗子放到哪里,这样通过CNN网络,根据输入棋局,就能学会人大概率会把旗子落在哪个位置,所以说它学的是人如何单步落子。3000万看上去多,其实并不多,这是落子数量,真正的对弈棋局数量也就16万局对弈过程,因为每个对弈过程包含很多落子步骤,所以总数看上去多而已。
对于RL落子策略来说,它学的是如何赢得一局,这里用到了增强学习的Q函数。但是学习过程跟SL是类似的,无非是两个AlphaGo先下一盘,然后看看是输了赢了,并把输赢的分数赋给整个过程中的每个棋局及其对应的落子步骤,这样每个棋局及其落子步骤都会有个输赢得分,根据这个得分调整之前学到的SL落子策略学习到的参数,这样就通过自我对弈来学会如何赢得一局棋。
对于局面评估Value Network来说,其网络架构如图6所示,这里和图5的结构稍微有不同,就是输出层不是SoftMax分类,而是一个回归函数,学习到一个数值,而不是分类。这个正常,因为它的目的是给当前棋局一个估分,而不是学习落子策略。它的输入是从自我对战的3000万局比赛中随机抽取某个时间的棋局状态,并赋予这个棋局状态一个赢棋得分,然后把这些数据当成训练数据,交给这个神经网络去学习给定一个局面,如何给出一个赢棋可能的打分。
好了,整个过程感觉已经说清楚了,就到这吧,觉得写得还算不错的话....你看着办吧,要知道,写东西其实是个挺消耗时间和体力的事情,尤其是类似本文这种精品@^^@。
















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









