







lecture 1:深度学习基础
目录
1、Deep Learning基础
- 1.应用:计算机视觉、自然语言处理(NLP)
- 2.硬件:显卡的处理器,GPU(图形处理器)
- 3.流行:卷积神经网络CNN、循环神经网络RNN
- 4.框架:TensorFlow(Python)、Caffe(C++)
- 5基础:Hopefield网络、玻尔兹曼机BM、限制玻尔兹曼机RBM
- 6.起因:浅层神经网络可以近似任意函数,而高层可以综合应用低层信息
低层关注局部,高层关注全局。- 7.稀疏编码:用几个较少的基将信号表示出来,重复迭代的过程
- 8.训练机制:layer-wise
BP机制对于7层以上,残差传到最前面层很小,出现梯度扩散
训练过程:
- 一是自底向上无监督预训练:每次训练一层网络,逐层构建单层神经元
- 二是自顶向下有监督调优: 当所有层训练完后,使用wake-sleep算法调优
无监督预训练的过程==特征学习的过程
深度学习模型(9种):
- 受限玻尔兹曼机RBM、 自编码器AE、 深层信念网络DBN
深层玻尔兹曼机DBM、 和积网络SPN、 卷积神经网络CNN
深层堆叠网络DSN、 循环神经网络RNN、长短时记忆网络LSTM
两类深层网络模型:生成模型、判别模型
- 判别模型:从输入层到隐含层的归约过程
- 生成模型:从隐含层到输入层的重构过程
数学知识:矩阵论、概率论(贝叶斯公式)、信息论(熵)、概率图模型
- 概率有向图模型(贝叶斯网络、信念网络)
- 概率无向图模型(马尔可夫网络、马尔可夫随机场)
- 部分有向无圈图模型(链图模型)
数据集:MNIST(手写字体)、ATIS(航班信息)、IMDB(电影评论)
2、9种深度学习模型
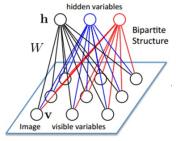
2.1受限玻尔兹曼机RBM

2.2自编码器AE(降维)
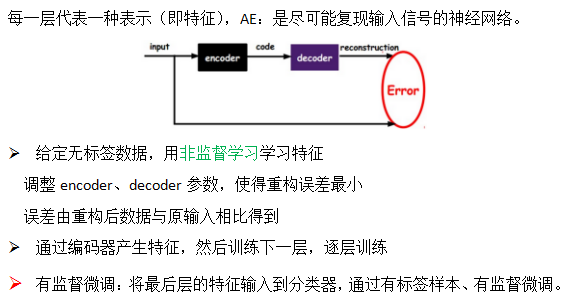
(1)标准AE模型
AE可用来对高维数据降维,深层自编码器本质是一种无监督学习的非线性特征提取模型。无监督预训练、有监督调优两个阶段。
标准AE:关于中间层结构对称的多层前馈网络,期望输出与输入相同。
(2)AE学习算法

- 有监督学习算法有:BP算法、随机梯度下降法、共轭梯度下降法。
- 自编码器的变种模型:稀疏自编码器、降噪自编码器
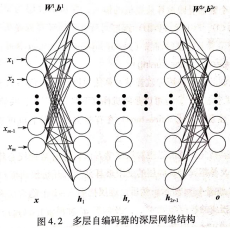
(3)AE实例(mnist)
- AE网络结构: 784-1000-250-30-250-1000-784
- MLP网络结构: 784-500-500-1000-10
可调的参数:最大迭代次数、学习率、网络结构、动量项
主要模块:RBM逐层预训练 、目标函数对参数的偏导、共轭梯度算法更新参数
- 预训练:数据分块
- 调优:数据分更大的块
2.3深层信念网络DBN
(1)标准DBN模型
- DBN是在逻辑斯蒂信念网络的基础上发展起来的。
- 逻辑斯蒂信念网络(sigmoid信念网络)是一种特殊的贝叶斯网络(有向信念网)
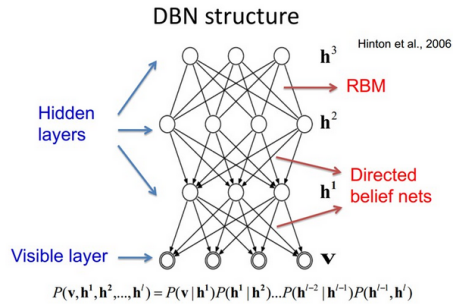
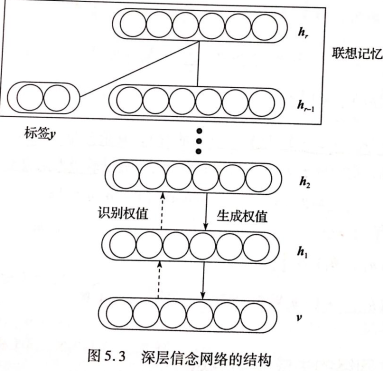
- DBNs是由多个RBM层组成,DBN连接是通过自顶向下的生成权重确定
- 最开始通过非监督预训练获得生成权重
- DBN既包含无向部分,又包含有向部分
- 最上面两层是无向图,构成联想记忆网络,是一个RBM,其余层是有向图
(2)DBN生成学习算法

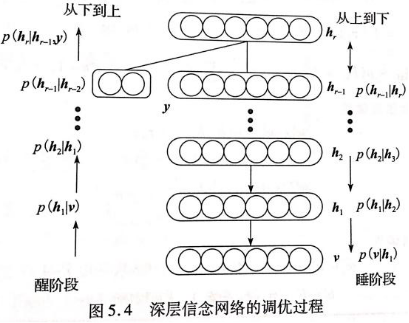
(3)DBN判别学习算法

2.4深层玻尔兹曼机DBM
DBM生成学习算法
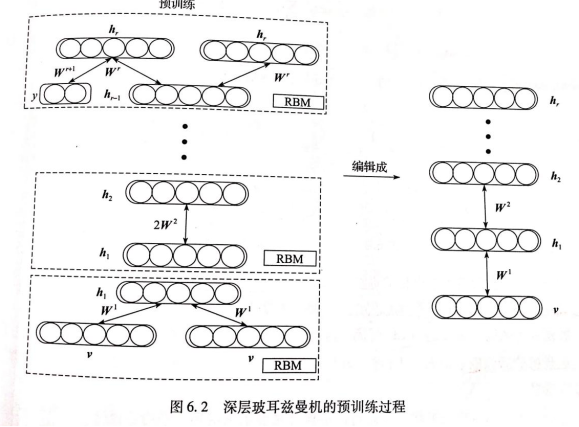
- DBM是概率无向图模型,采用经过编辑的RBM进行逐层预训练。
- 逐层预训练完成后,通过权值减半处理,重新编辑成一个DBM,作为逐层预训练的结果。
- 调优先采用平均场算法估计DBM的后验概率。然后用类CD算法更新参数。
2.5循环神经网络RNN

2.6卷积神经网络CNN

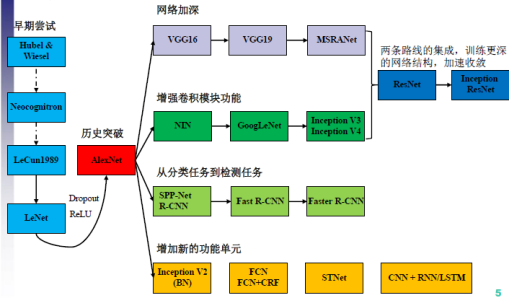

2.7其他模型
和积网络SPN
深层堆叠网络DSN
长短时记忆网络LSTM
3、深度学习的混合模型、广泛应用和开发工具

4、受限玻尔兹曼机RBM
rbm.m
% 训练RBM,利用1步CD算法 Contrastive Divergence(对比差异)
% 可视层二值随机像素 对称加权连接到 隐含层二值随机特征检测器
% maxepoch -- maximum number of epochs 最大迭代次数
% numhid -- number of hidden units 隐含层节点数
% batchdata -- the data that is divided into batches (600*784*100) 分批后的训练集
% restart -- set to 1 if learning starts from beginning 如果从第一层开始学习,就设置restart=1
epsilonw = 0.1; %权值学习速率 % Learning rate for weights
epsilonvb = 0.1; %可视节点偏置项学习速率 % Learning rate for biases of visible units
epsilonhb = 0.1; %隐含节点偏置项学习速率 % Learning rate for biases of hidden units
weightcost = 0.0002; %权值衰减系数,用于防止过拟合
initialmomentum = 0.5; %初始动量项,动量项学习率,用于克服收敛速度和算法不稳定性之间的矛盾
finalmomentum = 0.9; %确定动量项
[numcases numdims numbatches]=size(batchdata); %100*784*600
%主程序定义的变量,这里重新定义,否则无法运行
% restart=1;
% numhid=1000; %第一个隐含层 1000个节点
% maxepoch=10;
if restart ==1,
restart=0;
epoch=1;
%p(h|v)p(v)=p(v|h)p(h) p(v)用v表示,乘以权重得到p(h|v),二值化得到p(h),反向得到p(v|h)
%初始化对称权值和偏置
vishid = 0.1*randn(numdims, numhid); %随机初始化权值矩阵 Wij 784*1000
hidbiases = zeros(1,numhid); %初始化隐含层节点偏置为0 1*1000
visbiases = zeros(1,numdims); %初始化可视层节点偏置为0 1*784
poshidprobs = zeros(numcases,numhid); %初始化单个迷你块正向传播(第一次)时,隐含层的输出概率p(h|v0) 100*1000
neghidprobs = zeros(numcases,numhid); %第二次正向传播时,隐含层的输出概率p(h|v1) 100*1000
posprods = zeros(numdims,numhid); %表示 p(hi=1|v0)*v0,以后更新deta Wij时会用到这一项 784*1000
negprods = zeros(numdims,numhid); %表示 p(hi=1|v1)*v1,以后更新deta Wij时会用到这一项 784*1000
vishidinc = zeros(numdims,numhid); %权值更新的增量 deta Wij 784*1000
hidbiasinc = zeros(1,numhid); %隐含层偏置项更新的增量 deta bj 1*1000
visbiasinc = zeros(1,numdims); %可视层偏置项更新的增量 deta ci 1*784
batchposhidprobs=zeros(numcases,numhid,numbatches); %整个数据第一次正向传播时隐含层的输出概率 100*1000*600
end
for epoch = epoch:maxepoch %迭代10次
fprintf(1,'epoch %d\r',epoch);
errsum=0;
for batch = 1:numbatches, %每次迭代都遍历所有的迷你块 600块
% fprintf(1,'epoch %d batch %d\r',epoch,batch);
%%%%%%%%% 开始正向阶段的计算 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
data = batchdata(:,:,batch); %每次迭代选择一个迷你块数据,每一行代表一个样本值(这里数据并非二值的,严格的说,应该进行二值化)
poshidprobs = 1./(1 + exp(-data*vishid - repmat(hidbiases,numcases,1)));
%样本第一次正向传播时隐含层节点的输出概率,即:p(hi=1|v0) 用的是sigmoid函数
%从可视层*权值=隐含层,然后再减去隐含的偏置,最后用sigmoid函数
batchposhidprobs(:,:,batch)=poshidprobs; %存放第一个迷你块的隐含层输出概率
posprods = data' * poshidprobs; %可视层节点*隐含层节点 计算正向散度统计量,p(hi=1|v0)*v0,以后更新detaWij时会用到这一项
poshidact = sum(poshidprobs); %针对样本值p(hi=1|v0)进行求和,用于计算隐含节点的偏置,更新deta bj时用 1*1000
posvisact = sum(data); %对数据v0进行求和,用于计算可视节点的偏置,更新 deta ci 1*784
%%%%%%%%% 正向阶段计算结束 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%poshidstates表示隐含层的状态h0,将隐含层数据01化(此步骤在posprods之后进行),按照概率值大小来判定.
%大于:激活值等于1,否则激6活值等于0
poshidstates = poshidprobs > rand(numcases,numhid);
%%%%%%%%% 开始反向计算 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
negdata = 1./(1 + exp(-poshidstates*vishid' - repmat(visbiases,numcases,1))); %反向阶段计算可视节点的值v1=p(v1|h0),没有二值化
neghidprobs = 1./(1 + exp(-negdata*vishid - repmat(hidbiases,numcases,1))); %计算隐含层节点的概率值
%第一次反向传播后,又马上正向传播计算隐含层节点 p(hi=1|v1)
negprods = negdata'*neghidprobs; %计算反向散度统计量 p(hi=1|v1)*v1,用于更新权重Wij
neghidact = sum(neghidprobs); %所有p(hi=1|v1)累加,用于更新deta bj 1*1000
negvisact = sum(negdata); %所有v1累加,更新 deta ci 1*784
%%%%%%%%% 反向计算结束 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
err= sum(sum( (data-negdata).^2 )); %计算训练集中原始数据和重构数据之间的误差
errsum = err + errsum;
if epoch>5, %迭代更新参数过程中,前4次使用初始动量项,之后使用确定动量项
momentum=finalmomentum; %表示保持上一次更新增量的比例,如果迭代次数越少,这个比例值可以稍大一点
else
momentum=initialmomentum;
end;
%%%%%%%%% 更新权重和偏置 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%增量
vishidinc = momentum*vishidinc + epsilonw*( (posprods-negprods)/numcases - weightcost*vishid);
% posprods-negprods 表示 deta W;weightcost*vishid 表示权重衰减项,防止过拟合
visbiasinc = momentum*visbiasinc + (epsilonvb/numcases)*(posvisact-negvisact); % deta ci
hidbiasinc = momentum*hidbiasinc + (epsilonhb/numcases)*(poshidact-neghidact); % deta bj
%更新
vishid = vishid + vishidinc;
visbiases = visbiases + visbiasinc;
hidbiases = hidbiases + hidbiasinc;
%%%%%%%%%%%%%%%% 更新结束 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
end
fprintf(1, 'epoch %4i error %6.1f \n', epoch, errsum);
end;















 5589
5589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









