







目录
1、MLP的BP过程
MLP(multilayer perceptron)多层神经网络
1、单层神经网络的BP算法
反向误差传播

delta就是误差的反向传播,用来更新网络参数(w,b)
使得损失函数向最小值靠近
2、深层前向、后向

3、MLP(multilayer perceptron)的BP
- 无监督预训练 RBM
- 有监督微调 BP
RBM受限玻尔兹曼机
利用1步CD算法

2、maxpool层BP怎么做的
创建 “mask” 矩阵
通过维度形状的矩阵来平均分配值d
- Max Pooling比较有意思,forward的时候需要记录 每个窗口内部最大元素的位置
- 然后bp的时候,对于窗口内最大元素的gradient是1,否则是0。原理和ReLu是一样的。
3、opencv遍历像素的方式,讲两种?
(1). C操作符[] (指针方式访问)
(2). 迭代器iterator
(3). 动态地址计算
像素遍历方式在速度上不同,用C操作符[]是最快的访问方式
at()函数和行首指针
4、传统图像处理有了解过吗,比如去噪 特征提取
1、图像去噪
图像去噪是指减少数字图像中噪声的过程称为图像去噪。现实中的数字图像在数字化和传输过程中常受到成像设备与外部环境噪声干扰等影响,称为含噪图像或噪声图像。
噪声是图象干扰的重要原因。一幅图象在实际应用中可能存在各种各样的噪声,这些噪声可能在传输中产生,也可能在量化等处理中产生。
去除图像噪声的方法简介
- 均值滤波器:采用邻域平均法
- 自适应维纳滤波器
- 中值滤波器
- 小波去噪:(1)对图象信号进行小波分解 (2)对经过层次分解后的高频系数进行阈值量化 (3)利用二维小波重构图象信号
2、图像特征提取
参考:http://blog.csdn.net/jscese/article/details/52954208
- HOG特征(方向梯度直方图)
- LBP特征(局部二值模式)(编码:中心像素做阈值)
- Haar-like特征
5、问在linux下写过代码吗? 问用了什么软件工具
表示写过,写的代码是跨平台的,在win和linux下都能编译运行
没用工具,主要是代码结构设计,用宏开关来定义是在WIN还是在LINUX,编译的时候加上宏定义就行了。
6、LDA(狄利克雷分布)
Dirichlet Distribution(狄利克雷分布)的定义和性质
- 狄利克雷分布是一组连续多变量的概率分布,是多变量普遍化的Β分布
- 狄利克雷分布常作为贝叶斯统计的先验概率
- 狄利克雷分布有个重要的性质就是聚合性,这个性质使得该分布在计算中非常方便
multinomial distribution(多项式分布)
LDA中,多项式分布, 和狄利克雷分布的 形式一致,所以称为共轭
共轭分布:共轭先验分布,在贝叶斯统计中,如果后验分布与先验分布属于同类,则先验分布与后验分布被称为共轭分布,而先验分布被称为似然函数的共轭先验。
7、PR曲线、ROC曲线
PR曲线、ROC曲线、AUC、Accuracy
参考博客:http://blog.csdn.net/mingtian715/article/details/53488094
1、查准率、查全率、F1
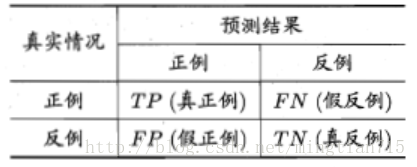
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(TP),假反例(FN),假正例(FP),真反例(TN),具体分类结果如下
查准率P和查全率R分别定义为:
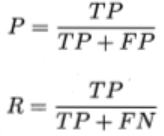
查准率关心的是”预测出正例的正确率”即从正反例子中挑选出正例的问题。
查全率关心的是”预测出正例的保证性”即从正例中挑选出正例的问题。
这两者是一对矛盾的度量,查准率可以认为是”宁缺毋滥”,适合对准确率要求高的应用,例如商品推荐,网页检索等。
查全率可以认为是”宁错杀一百,不放过1个”,适合类似于检查走私、逃犯信息等。
下图为查准率-查全率曲线(P-R图)
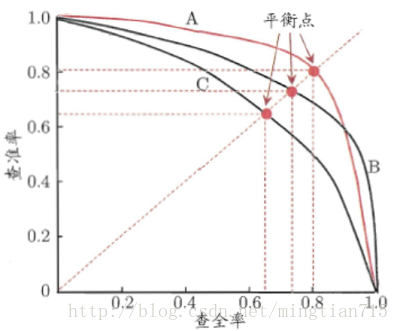
若一个学习器的P-R曲线被另一个学习器完全”包住”,则后者的性能优于前者。当存在交叉时,可以计算曲线围住面积,但比较麻烦,平衡点(查准率=查全率,BEP)是一种度量方式。
但BEP还是过于简化了些,更常用的是F1和Fp度量,它们分别是查准率和查全率的调和平均和加权调和平均。定义如下
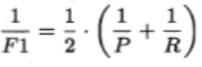
2、ROC和AUC
很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与一个分类阈值进行比较,若大于阈值分为正类,否则为反类,因此分类过程可以看作选取一个截断点。
不同任务中,可以选择不同截断点,若更注重”查准率”,应选择排序中靠前位置进行截断,反之若注重”查全率”,则选择靠后位置截断。因此排序本身质量的好坏,可以直接导致学习器不同泛化性能好坏,ROC曲线则是从这个角度出发来研究学习器的工具。
曲线的坐标分别为真正例率(TPR)和假正例率(FPR),定义如下
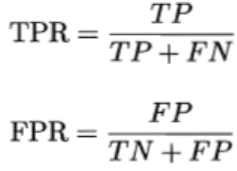
下图为ROC曲线示意图,因现实任务中通常利用有限个测试样例来绘制ROC图,因此应为无法产生光滑曲线,如右图所示。
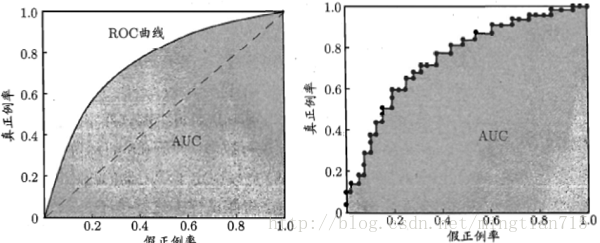
计算曲线围住的面积(AUC)来评价性能优劣
3、偏差和方差
泛化误差可以分解为偏差、方差与噪声之和
偏差度量了学习算法的期望预测和真实结果偏离程度。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声可以认为数据自身的波动性,表达了目前任何学习算法所能达到泛化误差的下限。
偏差大说明欠拟合,方差大说明过拟合。
8、特征工程
参考:http://www.cnblogs.com/jasonfreak/p/5448385.html

1、特征工程是什么??
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程包括以下方面:
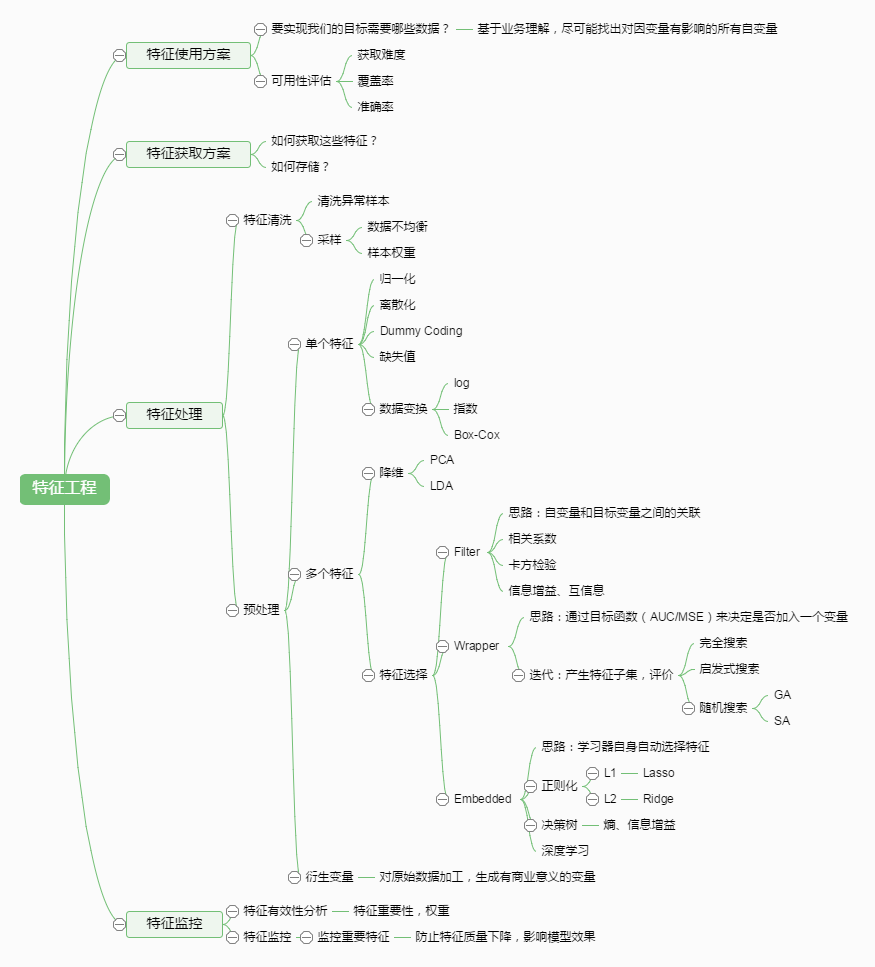
特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。首次接触到sklearn,通常会被其丰富且方便的算法模型库吸引,但是这里介绍的特征处理库也十分强大!
9、数据预处理的方法
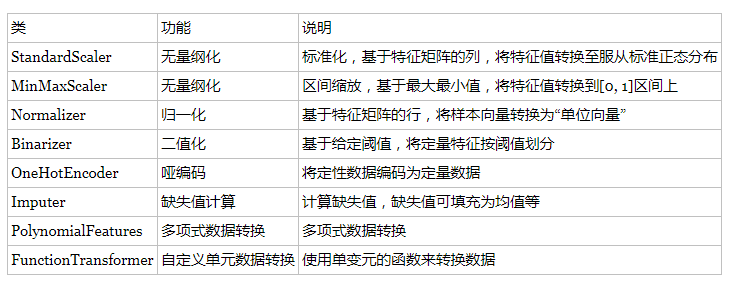
我们使用sklearn中的preproccessing库来进行数据预处理
通过特征提取,我们能得到未经处理的特征,这时的特征可能有以下问题:
- 不属于同一量纲
- 信息冗余
- 定性特征不能直接使用
- 存在缺失值
- 信息利用率低
10、特征选择的方法有哪些
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
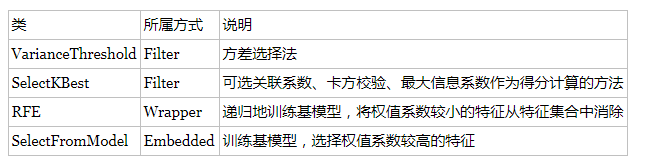
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
我们使用sklearn中的feature_selection库来进行特征选择。
降维:PCA、LDA
11、写K-means、GMM的公式

高斯混合模型GMM:
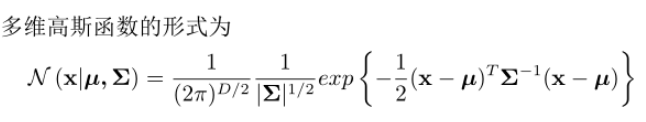

12、CNN与RNN的区别
参考:https://www.leiphone.com/news/201702/ZwcjmiJ45aW27ULB.html?viewType=weixin
如果说DNN特指全连接的神经元结构,并不包含卷积单元或是时间上的关联。因此,如果一定要将DNN、CNN、RNN等进行对比,也未尝不可。
2006年,Hinton利用预训练方法缓解了局部最优解问题,将隐含层推动到了7层,神经网络真正意义上有了“深度”,由此揭开了深度学习的热潮。这里的“深度”并没有固定的定义——在语音识别中4层网络就能够被认为是“较深的”,而在图像识别中20层以上的网络屡见不鲜。
为了克服梯度消失,ReLU、maxout等传输函数代替了sigmoid,形成了如今DNN的基本形式。单从结构上来说,全连接的DNN和多层感知机是没有任何区别的。
对于CNN来说,并不是所有上下层神经元都能直接相连,而是通过“卷积核”作为中介。同一个卷积核在所有图像内是共享的,图像通过卷积操作后仍然保留原先的位置关系。
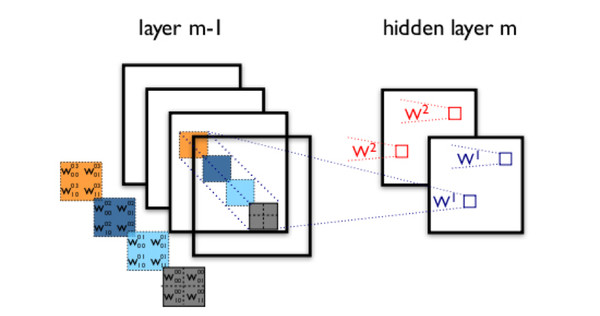
CNN中还有max-pooling等操作进一步提高鲁棒性
全连接的DNN还存在着另一个问题——无法对时间序列上的变化进行建模。然而,样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。对了适应这种需求,就出现了大家所说的另一种神经网络结构——循环神经网络RNN。
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!表示成图就是这样的:
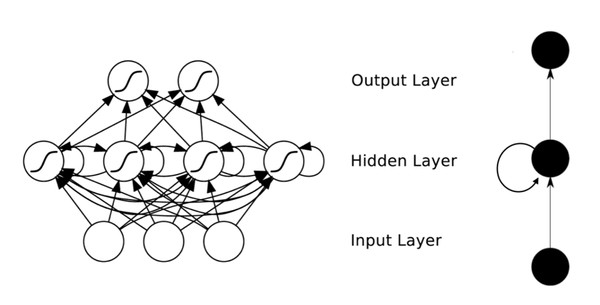
我们可以看到在隐含层节点之间增加了互连。为了分析方便,我们常将RNN在时间上进行展开,得到如图6所示的结构:
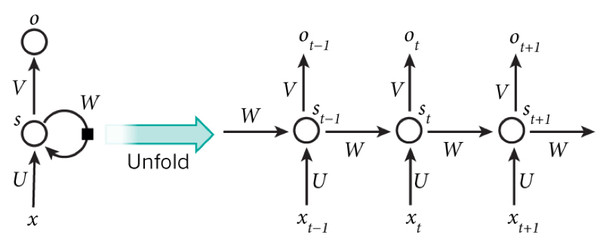
Cool,(t+1)时刻网络的最终结果O(t+1)是该时刻输入和所有历史共同作用的结果!这就达到了对时间序列建模的目的。 不知题主是否发现,RNN可以看成一个在时间上传递的神经网络,它的深度是时间的长度!正如我们上面所说,“梯度消失”现象又要出现了,只不过这次发生在时间轴上。
对于t时刻来说,它产生的梯度在时间轴上向历史传播几层之后就消失了,根本就无法影响太遥远的过去。因此,之前说“所有历史”共同作用只是理想的情况,在实际中,这种影响也就只能维持若干个时间戳。
为了解决时间上的梯度消失,机器学习领域发展出了长短时记忆单元LSTM,通过门的开关实现时间上记忆功能,并防止梯度消失,一个LSTM单元长这个样子:
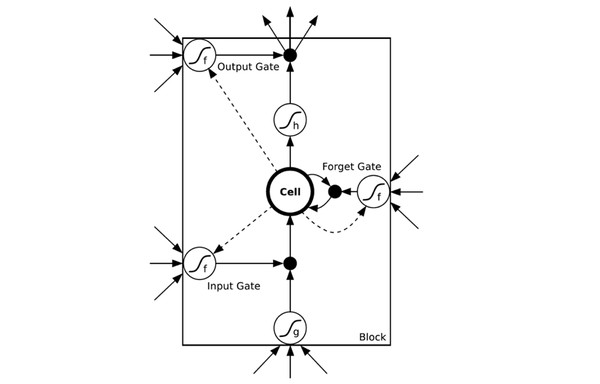
13、你所知道的距离度量方式、损失函数
参考:
http://blog.sina.com.cn/s/blog_6f611c300101c5u2.html
http://blog.csdn.net/google19890102/article/details/50522945
https://www.cnblogs.com/shixiangwan/p/7953591.html
1、距离度量
- 距离函数种类:欧式距离、曼哈顿距离、明式距离(闵可夫斯基距离)、马氏距离、切比雪夫距离、标准化欧式距离、汉明距离、夹角余弦等
- 常用距离函数:欧式距离、马氏距离、曼哈顿距离、明式距离
马氏距离的优点:与量纲无关,排除变量之间的相关性干扰
2、损失函数
- log对数 损失函数(逻辑回归)
- 平方损失函数(最小二乘法)
- 指数损失函数(AdaBoost)
- Hinge损失函数(SVM)
- 0-1损失函数
- 绝对值损失函数
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。模型的结构风险函数包括了经验风险项和正则项。
(1)log对数损失函数(逻辑回归)
在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数。
log函数是单调递增的,(凸函数避免局部最优)
在使用梯度下降来求最优解的时候,它的迭代式子与平方损失求导后的式子非常相似
(2)平方损失函数(最小二乘法, Ordinary Least Squares)
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。
在线性回归中,它假设样本和噪声都服从高斯分布(为什么假设成高斯分布呢?其实这里隐藏了一个小知识点,就是中心极限定理),最后通过极大似然估计(MLE)可以推导出最小二乘式子。
为什么它会选择使用欧式距离作为误差度量呢(即Mean squared error, MSE),主要有以下几个原因:
- 简单,计算方便;
- 欧氏距离是一种很好的相似性度量标准;
- 在不同的表示域变换后特征性质不变。
(3)指数损失函数(AdaBoost)
学过Adaboost算法的人都知道,它是前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。在Adaboost中,经过m此迭代之后,可以得到fm(x)

(4)Hinge损失函数(SVM)
在机器学习算法中,hinge损失函数和SVM是息息相关的。在线性支持向量机中,最优化问题可以等价于下列式子:

下面来看看几种损失函数的可视化图像,对着图看看横坐标,看看纵坐标,再看看每条线都表示什么损失函数,多看几次好好消化消化。
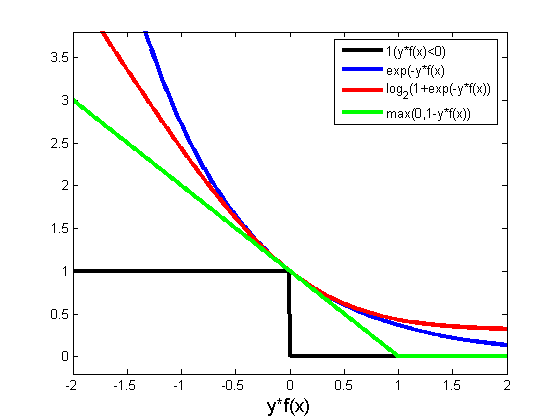
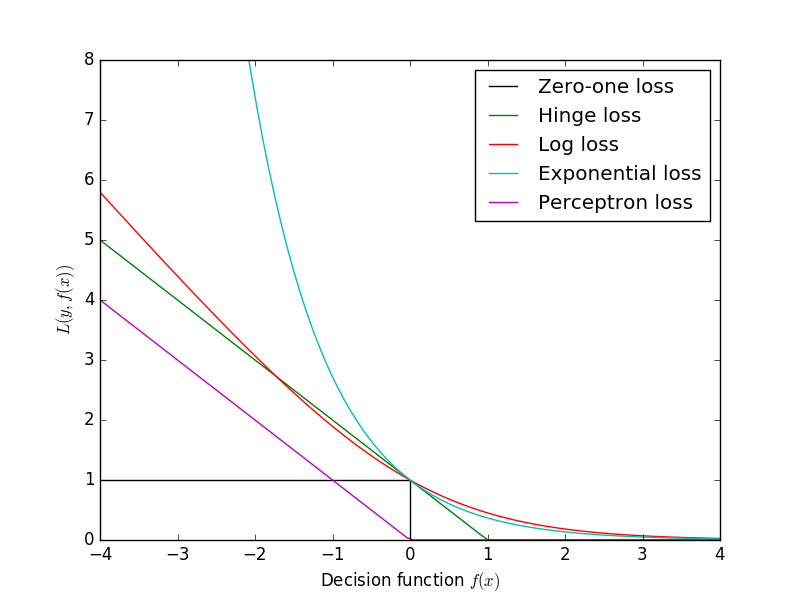
参数越多,模型越复杂,而越复杂的模型越容易过拟合

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









