






1.7HashMap分析
一、基本了解
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。HashMap 是无序的,即不会记录插入的顺序。HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。
1.7中HashMap结构是:数组+散列表。存储的是Entry<K,V>对象:

我们可以看到Entry<K,V>对象是HashMap的内部类,他包含4个属性,其中Entry<K,V> next是链表中指向下个Entry<K,V>节点

二、源码分析
当我们new一个HashMap时,可以传两个参数或者不传(如果不传的话默认初始大小是16,加载因子0.75)
![]()
我们可以看看这个构造方法:

put<K,V>方法分析
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);//计算key值得hash值
int i = indexFor(hash, table.length);//通过hash值和数组长度计算该key值的数组下标
//从table[i]处遍历链表,有重复的key则替换并返回老value值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//没有重复的key则添加新的Entry<K,V>对象
addEntry(hash, key, value, i);
return null;
}我们可以看到,如果key==null,调的是putForNullKey(value),这个方法时在计算key值的hash之前调用的

数组的大小为什么要设计成2的幂次方呢?我们可以看下计算数组下标i的方法
static int indexFor(int h, int length) {
return h & (length-1);
}首先,HashMap设计的初衷就是让存储时时随机的,这一点hash算法已经帮我们保证了。第二点,我们要让算出来数组下标在我们容量范围内。这里就以初始容量16为例。int类型是32bit位,我们这就简单的用8位表示
16:0000 1000 ---2的幂次方
h: 0101 0101(hash值是随机的,可以随便写)经过和15&运算后
&
15:0000 1111 ---2的幂次方减一 低4位永远都是四个一
结果: 0000 0101(&运算后低四位是和hash一模一样的,所以范围就是0000-1111)
我们可以发现,不过hash值是什么,经过&运算得出的结果永远在0-15我们的数组范围内,这就是HashMap保证数组大小是2的幂次方
当然,为了让key计算的hash值更加的散列,让高位也参加进来计算,前面这个方法有进行一系列的右移操作和^运算
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}该方法可以看出,key==null的值存在table[0]的位置
我们再看下addEntry()添加新的Entry<K,V>对象这个方法
void addEntry(int hash, K key, V value, int bucketIndex) {
//size超过阈值且当前位置不为空
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容处理
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//创建新的Entry对象
createEntry(hash, key, value, bucketIndex);
}再看下createEntry()方法
void createEntry(int hash, K key, V value, int bucketIndex) {
//这里可以看出采取的头插法
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}这里会产生线程不安全,假设有两个线程T1,T2一起执行put()操作,key算出的数组下标都是一样的。都跑到了createEntry()方法,此时T2线程被挂起(为分到CPU时间片),这是T1线程把新的Entry对象已经赋值给数组,这是T2获取到执行时间,就会重新对该位置赋值,把T1线程的值覆盖,造成数据丢失。
接下来我们看看扩容方法的源码resize(int newCapacity)
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果老表数组已经是最大值,则不扩容直接返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
//useAltHashing默认是false
boolean oldAltHashing = useAltHashing;
//当我们新数组大小大于 Holder.ALTERNATIVE_HASHING_THRESHOLD,这个结果为true,则rehash为true,重新计算hash
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
//老表数据迁移到新表
transfer(newTable, rehash);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}所以我们来看看Holder这个静态内部类
private static class Holder {
/**
* Table capacity above which to switch to use alternative hashing.
*/
static final int ALTERNATIVE_HASHING_THRESHOLD;
static {
//获取本地变量jdk.map.althashing.threshold值
String altThreshold = java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction(
"jdk.map.althashing.threshold"));
int threshold;
try {
threshold = (null != altThreshold)
? Integer.parseInt(altThreshold)
: ALTERNATIVE_HASHING_THRESHOLD_DEFAULT;//为null取Integer最大值
// disable alternative hashing if -1
ALTERNATIVE_HASHING_THRESHOLD = threshold;
}
}也就是说Hashmap给我们提供了这样一个功能,我们可以去配置这个变量的值,当我们扩容的新数组大于jdk.map.althashing.threshold,则重新计算hash,不配这个值则默认是Integer的最大值即2^31-1,所以一般我们不配扩容时都不需要rehash。1.8中已经去掉这个判断,扩容时不需要rehash。

我们再看下老表数据迁移到新表方法transfer(newTable,rehash)
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
//重新对e.hash赋值
e.hash = null == e.key ? 0 : hash(e.key);
}
//这里算数组下标的方法和老表算是一样
int i = indexFor(e.hash, newCapacity);
//头插法,循环遍历完后链表顺序相反
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}我们可以看到,如果rehash为false(1.8中这个判断直接取消了),计算新数组下标的方法和老表是一样的,前面我们有举例子
16:0000 1000 ---2的幂次方 翻倍以后——> 0001 0000
h: 0101 0101(hash值是随机的,可以随便写)经过和15&运算后 0100 0101或0101 0101
&
15:0000 1111 ---2的幂次方减一 低4位永远都是四个一 31:0001 1111 运算结果就是0000 0101(原来的数组下标) 或者 0001 0101(原来的数组下标+oldtable.length)
扩容的目的是为了让链表的长度变短,提高get()方法效率,因为扩容以后数据迁移到新table上的位置是两个(原来数组的下表 或 原来的数组下标+oldtable.length)

resize()扩容这里也会造成线程不安全,会造成一个死循环,主要是迁移这个方法transfer(newTable,rehash)造成的,采取了头插法。具体可以参照这边文章:https://juejin.cn/post/6844903554264596487
三、容错机制:fast-fail(快速失败)
在上面源码的put(K,V)方法中,我们发现,我们每put()一次modCount++,这个属性代表:已对HashMap进行结构修改的次数。
这里有一段代码
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<String, String>();
map.put("1","1");
map.put("2","2");
for (String key: map.keySet()) {
if(key.equals("1")) {
map.remove(key);
System.out.println("remove key1 success");
}
if(key.equals("2")){
map.remove(key);
System.out.println("remove key2 success");
}
}执行结果是:

为什么会出现这种情况呢:为了更好分析,我们拿编译过后的代码分析:
//编译之后的代码 fast-fail(快速失败,容错机制)
HashMap<String, String> map = new HashMap(); //expectedModCount=2 modCount(代表修改)=2 不管在put()或remove操作时:modCount++
map.put("1", "1");
map.put("2", "2");
Iterator i$ = map.keySet().iterator();
while(i$.hasNext()) {
String key = (String)i$.next();
if (key.equals("1")) {
map.remove(key);//modCount++
//i$.remove(); 这里会重新 设置 expectedModCount=modCount
System.out.println("remove key1 success");
}
if (key.equals("2")) {
map.remove(key);//modCount++
//i$.remove();这里会重新 设置 expectedModCount=modCount
System.out.println("remove key2 success");
}
}为什么这样设计的。主要是在多线程情况下,假设两个线程T1,T2。T1在遍历,T2在修改,就会抛出异常。单线程下避免报错可以调用迭代器的remove()方法
1.7ConcurrentHashMap分析
ConcurrentHashMap是线程安全的,它采取的是分段式锁,它的数据结构还是数组+链表。只不过数组放的不是Entry<K,V>对象,而是Segment<K,V>[]数组,(我们可以理解每个Segment就是一个HashMap(线程不安全),只是他是线程安全的,因为Segment继承了ReentrantLock)而Segment里放的是HashEntry<K,V>对象(与HashMap中Entry<K,V>一样)。ConcurrentHashMap中key,value都不能为null。

当我们不传参数创建一个new ConcurrentHashMap(),会默认传三个参数
initialCapacity:初始化容量(默认16),内部会作调整一容纳更多元素。 loadFactor:加载因子(0.75)。 concurrencyLevel:并发级别(默认16)。 一个segment就一个锁。当我们初始化完后,Segment<K,V>[]数组长度不变了,只有HashEntry<K,V>[]数组长度会变(扩容)
假设我们new ConcurrentHashMap(33,0.75f,16),由源码得知,Segment[ssize]大小为16,HashEntry[cap]大小为4,

这里是因为put()方法中算key的hash和HashMap中一样,第一步算出Segment[]数组下标:hash&Segment[].length-1(拿的是高四位进行&计算)。第二部算出HashEntry[]数组下标:hash&HashEntry[].length-1(和HashMap一样,用的是低四位)。前面我们分析过,只有数组大小为2的幂次方算出来的下标才会刚好在数组大小范围内。所以这里和HashMap一样,两个数组大小初始化是都会处理成2的幂次方。
上面还有这段代码很重要:
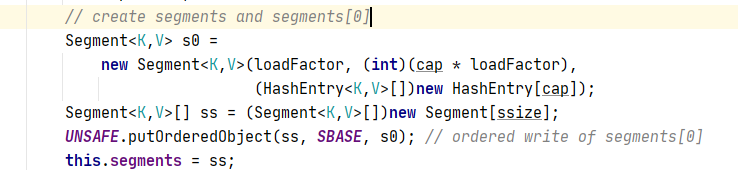
这里创建了一个Segment<K,V> S0 = new Segment<K,V>(a,b,c);这三个参数分别为加载因子、阈值(超过了扩容,segment内部扩容)、HashEntry对象。并调用UNSAFE(CAS算法保证线程安全只会PUT一个s0)方法把s0放到ss[0]的位置,然后其他Segment<K,V>[]位置都为null。为什么这样设计呢?
因为当我们调用ConcurrentHashMap的put()方法时,假如通过key算出下标为1,此处Segment<K,V>[]为null,我们只需要把S0位置上的Segment<K,V>拷贝过来就行,S0那三个参数已经在构造器中初始化好了,然后再调用Segment<K,V>中的put()方法。接下来我们就来看看ConcurrentHashMap中put()方法源码

我们看下是如何生成Segment<K,V>对象的:

Segment<K,V>[i]中的Segment<K,V>对象创建好以后,调用Segment<K,V>中的put()方法开始进行真正的put()操作

如果获取到则返回null,如果没获取到则走scanAndLockForPut(),我们点进该方法
tryLock():非阻塞 T1线程尝试去获取锁,获取到则返回true,没获取到则false(比如被其他线程占有),T1线程不会阻塞可以去干其他事。
lock():阻塞 T1线程调用lock()方法,获取不到锁(比如被其他线程占有),则阻塞,一直等待获取锁
我们再来看看scanAndLockForPut(key,hash,value)这个方法:这个方法只是为了加锁。但在加锁过程中遍历链表提前new HashEntry(),但有点多余,因为后面也有去遍历链表。1.8中就去掉了这段逻辑
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
//通过hash算出当前位置链表头结点HashEntry对象
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
//尝试去获取锁,当前线程获取失败则不会阻塞,继续执行下面代码。即根据判断是否要
//提前new HashEntry()对象
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
//需要new 一个新节点
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
//key有重复,不需要new一个新节点
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
//尝试获取锁失败超过一定次数,直接lock()阻塞获取锁
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
//在循环尝试获取锁过程中,多线程下,如果这时其他线程有去改变当前链表上的值(头插
法,所以不管改变那个值头结点会变),则
retries置为-1,重新遍历
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}我们再看看扩容方法rehash():这个方法是在Segment<K,V>中的。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
//把最后几个连续节点(通过hash算出在新数组同一个位置)转移,只要转移一个
就全部转移了,因为有指针链接
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
从头节点到lastRun节点遍历,转移到新数组
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
//转移完后,头插法把put的元素插进来
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}ConcurrentHashMap扩容值针对SegMent内部扩容。而且在转移元素时与HashMap也有不一样:HashMap是一个一个元素转移,采用头插法方式,多线程下会造成死循环。而ConcurrentHashMap里分了两次,第一次循环把最后几个连续节点(通过hash算出在新数组同一个位置)转移,只要转移一个就全部转移了,因为有指针链接 。第二个循环从头节点到lastRun节点遍历,转移到新数组。
get(Object key)方法分析
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//通过UNSAFE方法拿第u个位置segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
//通过UNSAFE方法拿HashEntry[]数组里的HashEntry对象
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









