







Linux服务器常见运维性能测试(2)内存测试mbw、stream
最近需要测试一批服务器的相关硬件性能,以及在常规环境下的硬件运行稳定情况,需要持续拷机测试稳定性。所以找了一些测试用例。本次测试包括在服务器的高低温下性能记录及压力测试,高低电压下性能记录及压力测试,常规环境下CPU满载稳定运行的功率记录。
这个系列是根据这次测试项目的相关测试总结,关于各种常见性能测试及拷机软件的整理。
本章为系列2,主要介绍
系列往期:Linux服务器常见运维性能测试(1)综合跑分unixbench、superbench
常见性能测试软件
综合测试:UnixBench(综合跑分),superbench(快速脚本)
内存测试:mbw(内存带宽测试),stream(读写响应测试)
CPU测试:super_pi
网络测试:netperf
IO测试:FIO、iometer
辅助监测:sensors、top、
内存测试:1.mbw(内存带宽测试)
内存带宽的计算公式是:带宽=内存核心频率×内存总线位数×倍增系数。简化公式为:标称频率位数。比如一条DDR3 1333MHz 64bit的内存,理论带宽为:133364/8=10664MiB/s = 10.6GiB/s。基于计算公式,我们可以得出内存的理论带宽,配合测试工具测试出实际带宽,方便我们查找问题,确认测试结果。
mbw作为一个内存宽带测试工具,可以测试在内存拷贝memcpy、字符串拷贝dumb、内存块拷贝mcblock三种不同方式下的内存拷贝速度。
下载地址:https://github.com/raas/mbw/archive/refs/heads/master.zip
解压得mbw-master文件夹,进入文件夹执行编译安装,注意赋权限(同上文)
help获取相关参数说明:
./mbw -h
mbw memory benchmark v1.4, https://github.com/raas/mbw
Usage: mbw [options] array_size_in_MiB #使用方式 单位MiB
Options:
-n: number of runs per test (0 to run forever) #运行次数
-a: Don't display average #不显示平均值
-t0: memcpy test #内存拷贝
-t1: dumb (b[i]=a[i] style) test #字符串拷贝
-t2: memcpy test with fixed block size #内存块拷贝
-b : block size in bytes for -t2 (default: 262144)
-q: quiet (print statistics only)
(will then use two arrays, watch out for swapping)
'Bandwidth' is amount of data copied over the time this operation took.
The default is to run all tests available.
mpstat -P ALL 2 #2秒监视
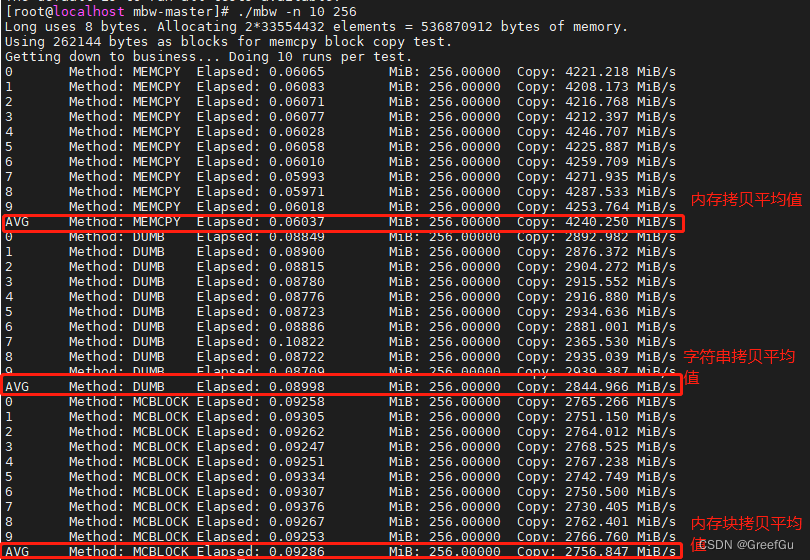
一般会三种测试后查看平均值,平均值越高测试内存带宽越高。
e.g. ./mbw -n 10 256
分配2*33554432=536870912字节的内存。
使用262144字节作为块进行memcpy块复制测试。
内存测试:2.stream(读写响应测试)
stream由Virginia University提供,通过生成四种不同模式下的内存读写操作,用于测试高性能计算机的内存带宽。
主要测试内容如下:
| 测试功能 | 操作 | 解释 | 操作次数 |
|---|---|---|---|
| Copy | c[i]+a[i] | 复制操作,即从内存单元中读取一个数,并复制到其他内存单元中,两次访问内存操作 | 1R1W 一读一写 |
| Scale | b[i]=scalar*c[i] | 乘法操作,即从内存单元中读取一个数,与常数相乘,得到的记过存到其他内存单元,两次访问内存操作 | 1R1W 一读一写 |
| Add | c[i]=a[i]+b[i] | 加法操作,从两个内存单元中分别读取两个数,将其进行加法操作后,得到的结果写入另一个内存单元中,3次访问内存操作 | 2R1W 二读一写 |
| Triad | a[i]=b[i]+scalar*c[i] | 是前面三种的结合,先从内存中读取一个数,与一个常数相乘得到一个乘积,然后从另一个内存单元中读取一个数与刚才乘积结果相加,得到的结果写入内存。3次访问内存操作 | 2R1W 二读一写 |
结果会输出各项测试的速率及平均用时,按照测试速率越高,平均用时越短性能越高做参考。
下载及编译
下载地址1:GitHub - cheyang/STREAM: STREAM benchmark
下载地址2:Index of /stream/FTP/Code
下载后解压得到文件夹stream
编译:
编译参数如下:
# 参数介绍
# -mtune=native -march=native 针对CPU指令的优化,此处由于编译机即运行机器。故采用native的优化方法。
# -O3 编译器编译优化级别。
# -mcmodel=medium 当单个Memory Array Size 大于2GB时需要设置此参数(小于2GB时设置无效)。
# -fopenmp 适应多处理器环境,开启后,程序默认线程为CPU线程数。也可以在运行前设置进程数
# 设置方法: export OMP_NUM_THREADS=x x为你想设置的线程数
# -DSTREAM_ARRAY_SIZE=100000000:这个参数是对测试结果影响最大,也是最需要关注的一个参数,指定计算中a[],b[],c[]数组的大小。
# -DNTIMES=40:执行的次数,并且从这些结果中选最优值
单线程编译:
# gcc -mtune=native -march=native -O3 -mcmodel=medium -DSTREAM_ARRAY_SIZE=200000000 -DNTIMES=30 stream.c -o stream.o
多线程编译(一般采用多线程编译):
# gcc -mtune=native -march=native -O3 -mcmodel=medium -fopenmp -DSTREAM_ARRAY_SIZE=200000000 -DNTIMES=30 stream.c -o stream.o
赋权限后可以运行stream.o(赋权同上)
./stream.o
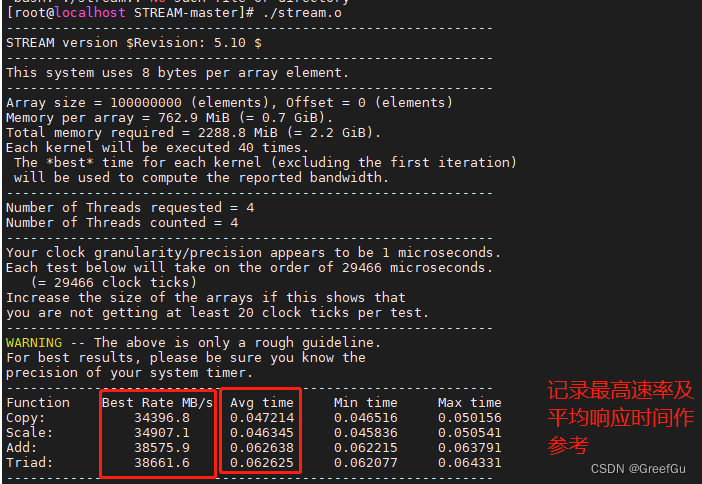
测试结果一般的规律是Add > Triad > Copy > Scale。一次Add操作需要访问三次内存(两个读操作,一个写操作),Triad操作也需要三次访问内存, Copy和Scale操作需要两次访问内存。单位操作内,访问内存次数越多,越能够掩盖访存延迟,带宽越大。















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











