







纸上获得终觉浅,要知学问需code。每次看那么多公式,是时候亲自实现一下,沉淀一下知识。在自己实现的过程,才发现自己忽略了还多细节,也debug了好久。
定义符号
线性回归,定义实验函数 y = 0.5x1+x0 。
参考教材,x0 = 1,所以先定义一些变量,这会影响到后面的计算。
- x = [
[x00,x01]T
, … ,
[xn0,xn1]T
] 样本向量
- y =
[y0,y1,...,yn]T
目标向量
- w =
[w1,w0]T
权值向量
上面的向量shape到计算的时候很重要,趟过几次坑了。
测试数据
初始化测试数据,添加高斯噪声。
def load_dataset(n):
noise = np.random.rand(n)
X = [[x, 1.] for x in range(n)]
y = [(0.5 * X[i][0] + 1. + noise[i]) for i in range(n)]
return np.array(X).T, np.array(y).T # 注意X,W,y的维数批梯度下降
批梯度下降就是计算整个样本的损失总值才更新一遍权值,具体推导看Andrew Ng的课程。
需要注意的就是公式中的负号放进括号里面了,之前没看清楚,导致一直没收敛。没有使用终止条件,因为发现会提前结束,没达到好的效果。
def bgd(self, X, y):
start_time = timeit.default_timer()
loop_max = 10000 #最大迭代数
epsilon = 0.000001 # 精度
alpha = 0.0005 # 步长
later_L = self.loss(y, self.predict(X.T))
for loop in range(loop_max):
# former_L = later_L
for j in range(len(X)):
tmp = 0
for i in range(len(X[0])):
predict = self.predict(X.T)
tmp += (predict[i] - y[i]) * X[j][i] # predict和y的顺序问题
self.w[j] = self.w[j] - alpha * tmp
# later_L = self.loss(y, self.predict(X.T))
# if former_L - later_L < epsilon:
# break结果:

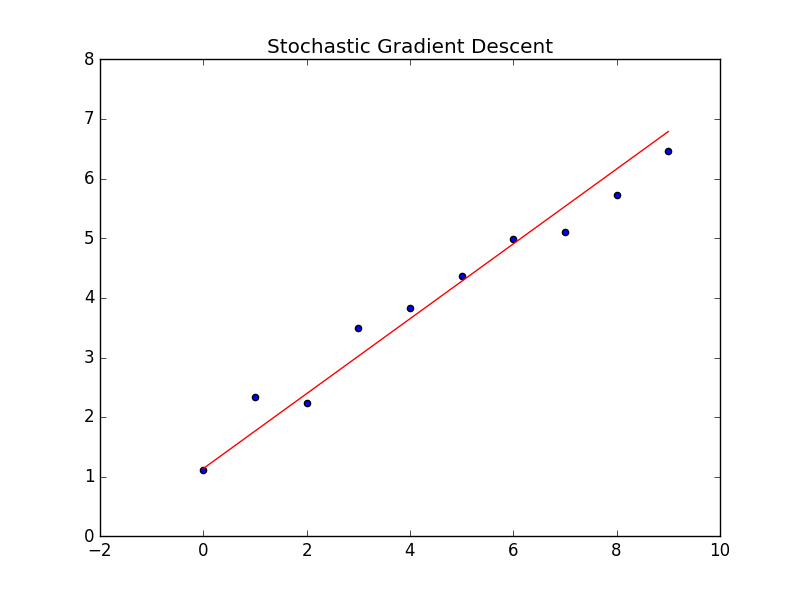
随机梯度下降
随机梯度下降就是每一个样本更新一次权值,超过样本范围就循环回去。
def sgd(self, X, y):
start_time = timeit.default_timer()
loop_max = 10000 #最大迭代数
epsilon = 0.000001 # 精度
alpha = 0.0005 # 步长
later_L = self.loss(y, self.predict(X.T))
for loop in range(loop_max):
# former_L = later_L
tmp = self.w[0] * X[0][loop % len(X[0])] + self.w[1] * X[1][loop % len(X[0])] - y[loop % len(X[0])]
for j in range(len(X)):
self.w[j] = self.w[j] - alpha * tmp
# later_L = self.loss(y, self.predict(X.T))
# if former_L - later_L < epsilon:
# break结果:
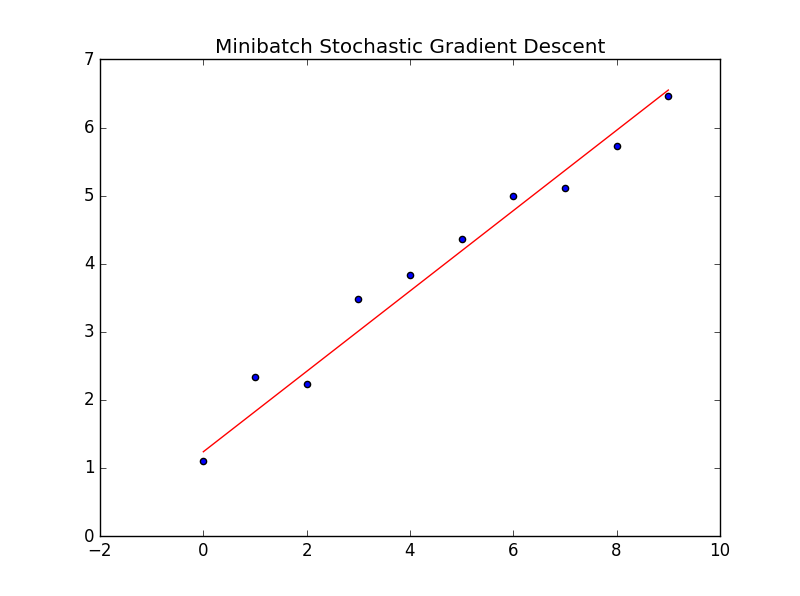
小批量随机梯度下降
小批量(minibatch)的方法就是结合上面的两种方法,把样本总体切成小块,每小块更新一次权值。这个代码实现并不美观,纠结。
def msgd(self, X, y):
batch_size = 2
start_time = timeit.default_timer()
loop_max = 10000 #最大迭代数
epsilon = 0.000001 # 精度
alpha = 0.0005 # 步长
later_L = self.loss(y, self.predict(X.T))
tmp = [0 for i in range(len(X))]
for loop in range(int(loop_max / batch_size)):
# former_L = later_L
tmp[0] += (self.w[0] * X[0][loop % len(X[0])] + self.w[1] * X[1][loop % len(X[0])] - y[loop % len(X[0])]) * X[0][loop % len(X[0])]
tmp[1] += (self.w[0] * X[0][loop % len(X[0])] + self.w[1] * X[1][loop % len(X[0])] - y[loop % len(X[0])]) * X[1][loop % len(X[0])]
if loop % batch_size == 0:
for j in range(len(X)):
self.w[j] -= alpha * tmp[j]
tmp[j] = 0
# later_L = self.loss(y, self.predict(X.T))
# if former_L - later_L < epsilon:
# break结果:
Normal Equation
这种方法引入了矩阵的表示。这里也要注意X的shape。
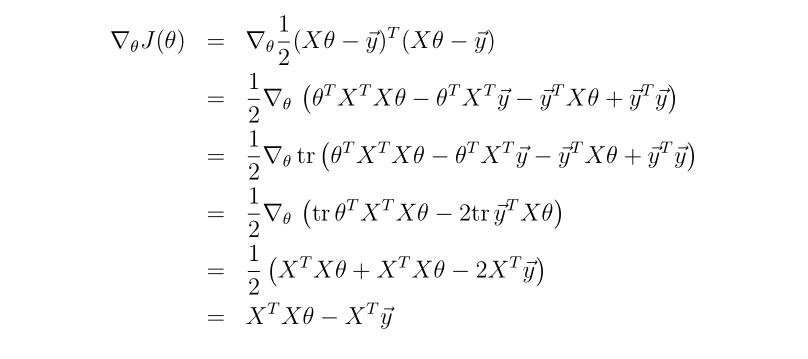
- 第二步: 先使用转置的性质把装置符号放进括号,然后就是乘法分配。
- 第三步: 实数的迹等于本身。
- 第四步: y^T^y不包含参数,求导忽略。第一项用对参数转置求导的公式化简。第二第三项用迹的性质,trA^T^=trA合并。
- 最后: 导数为0,就是最优解。
def normal_equation(self, X, y):
start_time = timeit.default_timer()
X = X.T
X_T_X = np.linalg.pinv(X.T.dot(X)) # 奇异矩阵的伪逆矩阵
self.w = np.dot(X_T_X, X.T).dot(y)
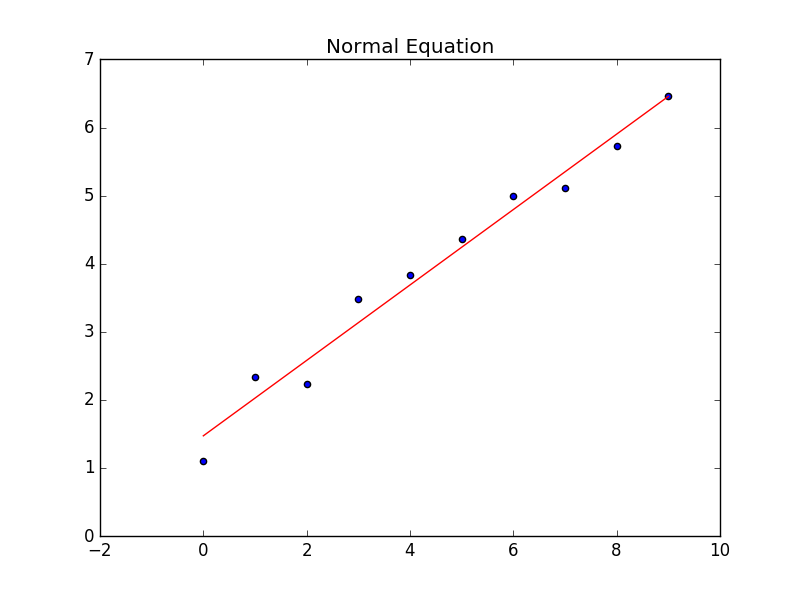
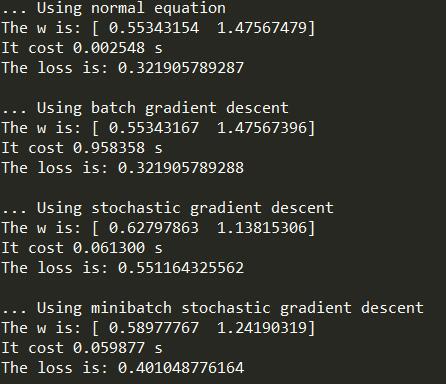
结果对比
完整代码
import numpy as np
import matplotlib.pyplot as plt
import timeit
# y = 0.5 * x0 + 1 * x1
def load_dataset(n):
noise = np.random.rand(n)
X = [[x, 1.] for x in range(n)]
y = [(0.5 * X[i][0] + 1. + noise[i]) for i in range(n)]
return np.array(X).T, np.array(y).T # 注意X,W,y的维数
class LinearRegression(object):
def __init__(self, m):
self.w = np.random.rand(m)
# 计算预测值,点乘的顺序决定X是否为转置
def predict(self, X):
predict = np.dot(X, self.w)
return predict
# 计算损失函数
def loss(self, y, predict):
l = 0
for i in range(len(y)):
l += (y[i] - predict[i]) ** 2
return 1/2 * l
# 正规方程
def normal_equation(self, X, y):
start_time = timeit.default_timer()
X = X.T
X_T_X = np.linalg.pinv(X.T.dot(X)) # 奇异矩阵的伪逆矩阵
self.w = np.dot(X_T_X, X.T).dot(y)
end_time = timeit.default_timer()
predict = self.predict(X)
plt.figure(0)
plt.scatter(range(len(y)), y)
plt.plot(range(len(y)), predict, color='r')
plt.title('Normal Equation')
plt.show()
print('... Using normal equation')
print('The w is:', self.w)
print('It cost %f s' % (end_time - start_time))
print('The loss is:', self.loss(y, predict))
print()
# 批梯度下降
def bgd(self, X, y):
start_time = timeit.default_timer()
loop_max = 10000 #最大迭代数
epsilon = 0.000001 # 精度
alpha = 0.0005 # 步长
later_L = self.loss(y, self.predict(X.T))
for loop in range(loop_max):
# former_L = later_L
for j in range(len(X)):
tmp = 0
for i in range(len(X[0])):
predict = self.predict(X.T)
tmp += (predict[i] - y[i]) * X[j][i] # predict和y的顺序问题
self.w[j] = self.w[j] - alpha * tmp
# later_L = self.loss(y, self.predict(X.T))
# if former_L - later_L < epsilon:
# break
end_time = timeit.default_timer()
predict = self.predict(X.T)
plt.figure(1)
plt.scatter(range(len(y)), y)
plt.plot(range(len(y)), predict, color='r')
plt.title('Batch Gradient Descent')
plt.show()
print('... Using batch gradient descent')
print('The w is:', self.w)
print('It cost %f s' % (end_time - start_time))
print('The loss is:', self.loss(y, predict))
print()
# 随机梯度下降
def sgd(self, X, y):
start_time = timeit.default_timer()
loop_max = 10000 #最大迭代数
epsilon = 0.000001 # 精度
alpha = 0.0005 # 步长
later_L = self.loss(y, self.predict(X.T))
for loop in range(loop_max):
# former_L = later_L
tmp = self.w[0] * X[0][loop % len(X[0])] + self.w[1] * X[1][loop % len(X[0])] - y[loop % len(X[0])]
for j in range(len(X)):
self.w[j] = self.w[j] - alpha * tmp
# later_L = self.loss(y, self.predict(X.T))
# if former_L - later_L < epsilon:
# break
end_time = timeit.default_timer()
predict = self.predict(X.T)
plt.figure(2)
plt.scatter(range(len(y)), y)
plt.plot(range(len(y)), predict, color='r')
plt.title('Stochastic Gradient Descent')
plt.show()
print('... Using stochastic gradient descent')
print('The w is:', self.w)
print('It cost %f s' % (end_time - start_time))
print('The loss is:', self.loss(y, predict))
print()
# 小批量随机梯度下降
def msgd(self, X, y):
batch_size = 2
start_time = timeit.default_timer()
loop_max = 10000 #最大迭代数
epsilon = 0.000001 # 精度
alpha = 0.0005 # 步长
later_L = self.loss(y, self.predict(X.T))
tmp = [0 for i in range(len(X))]
for loop in range(int(loop_max / batch_size)):
# former_L = later_L
tmp[0] += (self.w[0] * X[0][loop % len(X[0])] + self.w[1] * X[1][loop % len(X[0])] - y[loop % len(X[0])]) * X[0][loop % len(X[0])]
tmp[1] += (self.w[0] * X[0][loop % len(X[0])] + self.w[1] * X[1][loop % len(X[0])] - y[loop % len(X[0])]) * X[1][loop % len(X[0])]
if loop % batch_size == 0:
for j in range(len(X)):
self.w[j] -= alpha * tmp[j]
tmp[j] = 0
# later_L = self.loss(y, self.predict(X.T))
# if former_L - later_L < epsilon:
# break
end_time = timeit.default_timer()
predict = self.predict(X.T)
plt.figure(2)
plt.scatter(range(len(y)), y)
plt.plot(range(len(y)), predict, color='r')
plt.title('Minibatch Stochastic Gradient Descent')
plt.show()
print('... Using minibatch stochastic gradient descent')
print('The w is:', self.w)
print('It cost %f s' % (end_time - start_time))
print('The loss is:', self.loss(y, predict))
print()
X, y = load_dataset(10)
EN = LinearRegression(2)
EN.normal_equation(X, y)
BGD = LinearRegression(2)
BGD.bgd(X, y)
SGD = LinearRegression(2)
SGD.sgd(X, y)
MSGD = LinearRegression(2)
MSGD.msgd(X, y)














 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









