










最近了解一下Chatgpt-4到底发展到什么程度了,于是对知名的国内外几个AI平台都进行了初步试用。写几篇文章介绍一下试用心得。今天我先总结一下智谱清言,也就是国内的ChatGLM,聊天功能感觉接近Chatgpt-3.5,而我重点使用其对文档的解析和实施训练能力。
目前只支持PDF文档,我就把前些天翻译的《保障软件供应链安全 SBOM推荐实践指南》PDF传给它,传上到现实下面界面。
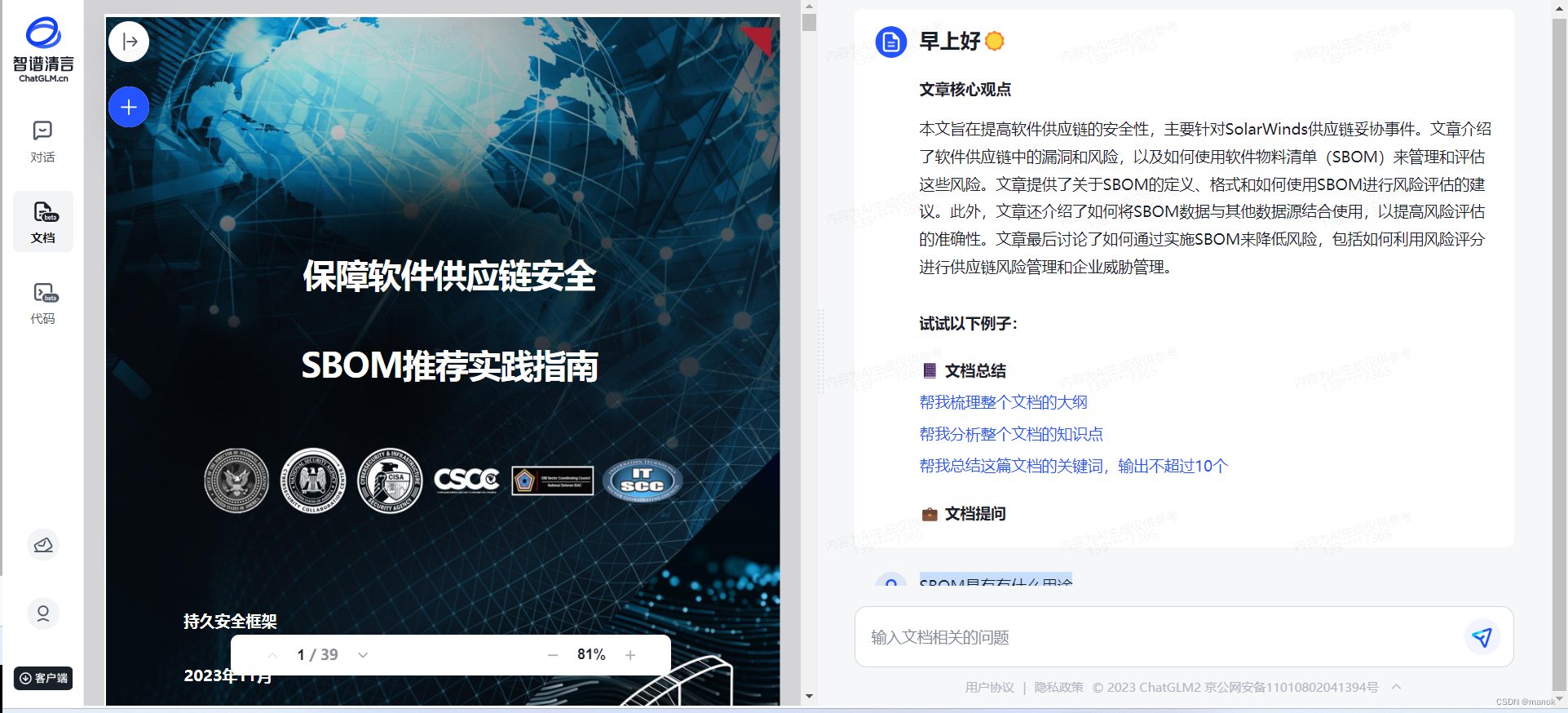
可以看到上传文档成功之后,AI首先把文章核心观点给提取出来了,我读了一下这段话,感觉提炼的还是非常不错的。语句通顺,内容清晰,观点准确到位,值得称赞。上面有些提示问题,但是我并没有使用例子问题提问,而是采用我关注的问题提问,大家看看结果。
问题1:SBOM具有有什么用途(故意多打了一个字,看看容错能力啊)
回答:
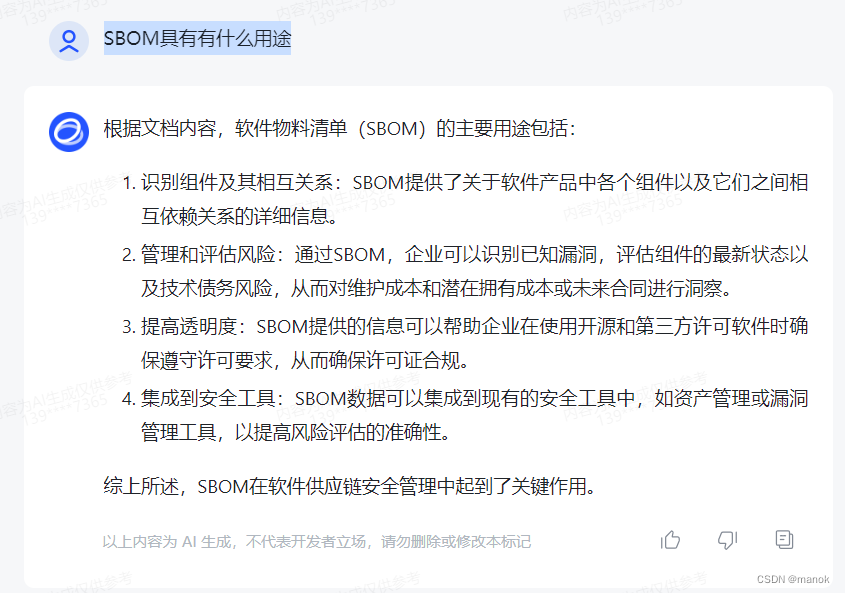
感觉回答的还是非常不错的,4个主要用途,比较重要。 那我要继续追问一下。
问题2: SBOM具有什么用途,能更详细一点吗?

AI平台以非常快的速度,响应时间估计大概在1-2秒回答上面的问题,回答的也非常准确。这种总结提炼性的问题,我就不再追问了,我想问一个开放性的问题,答案不仅仅来自于文档本身。
问题3:2024年SBOM有什么发展趋势呢
回答:
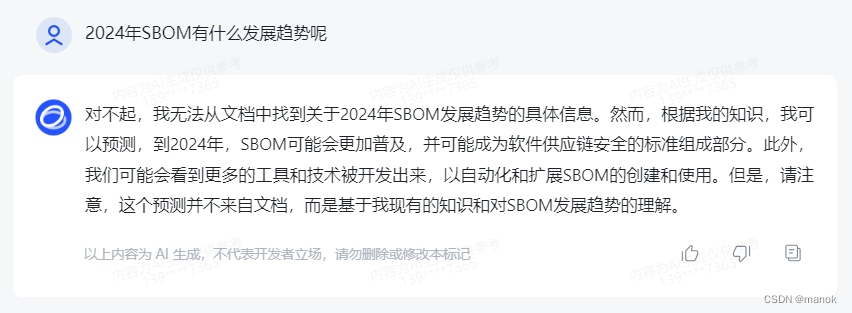
明显,这个问题答案并非可以从文章中找到。AI平台从其训练的历史中总结给出了答案,从答案上来看,其训练的数据还是非常新的。能够给出比较准确的趋势判断。那既然具有结合互联网上训练的数据,我问一个带有主观判断的问题,看看如何回答。
问题4:那您如果作为一个SCA工具厂商,该如何做呢
回答:
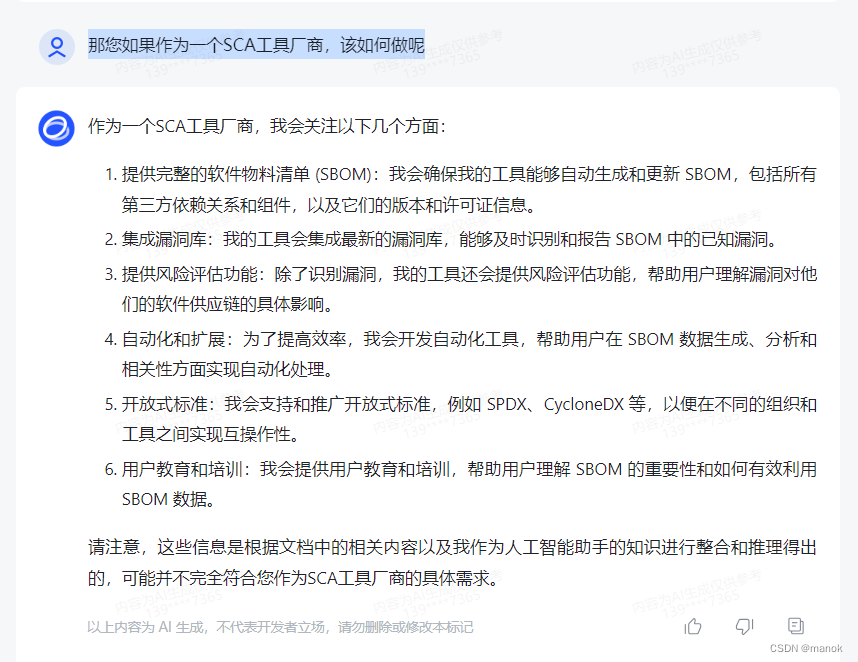
感觉回答的也非常不错,站在在第一人称的角度上,从6个方面可以在工具开发上可以做的事情。非常棒!
那我问一个更具有主观性的问题吧。
问题5:我想让我们的SCA产品在SBOM技术参数支持上更具有竞争力,您能给我一些建议吗
回答:

这个回答我感觉太好了,其实也是我作为应用安全从事人员判断的结果,AI平台都能给出来了,我这里给AI平台文档解析和互联网搜索训练结合在一起的能力,打9.9分,留0.1让他们回答问题时更深入展开一些。我表示出希望给我更深一步的判断答案。
问题6:我感觉您这个问题回答的有点欠缺,您能再深入的分析一下吗
回答:
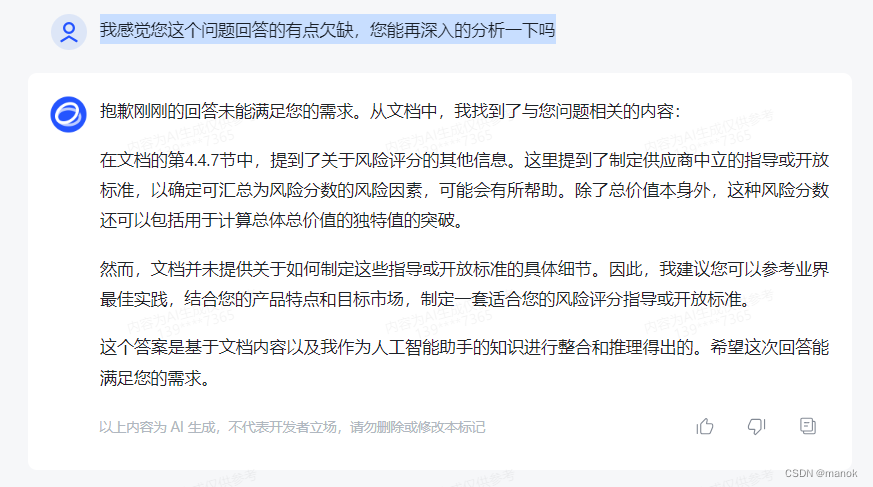
这个回答,它是从文档中又找到了一个点来回答我的问题。感觉给出这个点也挺好的。可能略显单薄,它又建议我去参考业界最佳实践,不错,答案非常完美。
通过上面6个问题,我们大概能够判断出AI平台现在发展的水平超出了我们的想象,文档分析结合互联网搜索,结合模型训练,能够帮助我们大幅度提升工作效率。我还在找是否有可以训练软件威胁建模的工具,也看了Chatgpt-4,给出的几个模型,感觉自己建立模型要投入大量的时间,还需要付费,再看看是否可以有更好的方法。感兴趣的朋友们可以一套探讨。
(结束)


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











