







训练一个分类器,第一步就是为每个类别准备大量数据。这一个看似简单,在实际中往往却最难达到理想情况。因为:实际中很多分类任务的数据不是平衡的,即类与类之间的数量悬殊,例如对磁盘进行故障预测分类,然而磁盘故障率每年小于1%,于是理想和现实如同如下左、右图那样。


有很多学者对这种非平衡数据的分类问题进行了研究,总的来说,以下是解决这个问题的主要方法:
1. 不做任何事情,在这样自然分布的数据下坐等训练结果;
2. 对少数量的类进行上采样,对大数量的类进行下采样,或给少数量的类加入一些新的合成数据;
3. 不考虑少数量的类型,把问题转化为“异常检测”解法;
4. 做些算法上的优化,如给损失函数加权重控制、调整决策阈值、或是对算法做些修改使得对少量数据的类更敏感。
5. 设计一个新的算法。
在阐述具体方法前,我们来谈谈如何评价分类的性能,要注意以下几点:
1. 通过ROC来评价,不要就在某个阈值下讨论算法的效果,应该根据实际应用上的条件来寻找ROC曲线上最佳的值。
2. 要在“自然”分布的数据集上对算法进行测试验证 (sklearn.cross_validation.StratifiedKFold)。
3. 可以用The Area Under the ROC curve (AUC) 、F1-score、Cohen’s Kappa 进行单指标评价。
下面,具体来看以上谈到的几个方法:
1. 关于上、下采样。上采样可以放大错误,但也有副作用,它会让变量的方差过小;而下采样会让独立变量有更大的方差,如下图,由于样本少,使得分类变得方差较大(10个不同的采样导致10个不同的分类器),如下图左。于是,可以用bagging的方法来避免,如下图右。


2. 用邻域链接的方法来进行下采样: TomekLink。 如下图,该算法通过将少量数据类的样本附近的一个大量数据类的样本进行删除来实现。


6. 将问题看作“异常检测”,效果比较不错的是:Isolation-Based Anomaly Detection, 它通过学习一个随机森林并获得分割每个点的决策面的个数,这个个数可以衡量对应点的异常分数。
7. 最后,通过社会化众包发现数据也是很多公司采用的方法。
8. 模型级联。 EasyEnsemble and BalanceCascade (Exploratory Under Sampling for Class Imbalance Learning). 这是个迭代清洗数据获得多个模型的算法。首先从整体训练集中采样获得大类的子集M1,使得数量和小类S相当,然后用M1+S训练获得分类器H(1)。 获得H(1)分类结果中分类正确的M1的子集M11, 认为M11是M1的冗余,并从整体训练集中删去。接着重复同样的步骤,采样->训练->删冗余,迭代直至无法获得更好的结果。然后把所有模型级联起来进行分类。
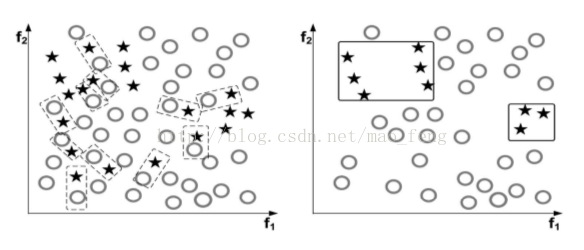
9. one-sided selection (OSS). 这个是清洗数据使得更有利于训练的方法。它也是迭代进行的。每次获得Tomek links,即当不存在实例使得其到大类Xm和小类Xs的距离小于Xm和Xs之间的距离,则认为(Xm,Xs)是一个Tomek link. 属于Tomek link的两个实例,要么是噪声点,要么是类间的边界。如下图,左边虚线矩形框出了Tomek links, 右边是清理后的数据集。
原文连接: http://www.svds.com/learning-imbalanced-classes/#fn6















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









