







1.索引:本质是一种数据结构(hash,二叉树,b-tree,b+tree),可以用来帮助mysql高效获取数据;
2.索引文件存储在磁盘中,和数据库文件共一个文件(xxx.ibd),文件中既有索引内容,也有表的数据内容;
3.索引种类:聚簇索引,非聚簇索引,复合索引,覆盖索引,前缀索引,次要索引,唯一索引
4.索引优缺点:
优点:能极大提高查询效率,降低数据库的io成本;通过索引列队数据排序,降低了数据库的排序成本,降低了cpu的消耗;
缺点:会降低表的更新速度,每次更新表数据时,同时索引文件也要进行更新
索引只是提高数据库效率的一种方式,需要寻求建立更优秀的索引;


innodb下的索引(b+树结构)
单值索引:一个索引只包含单个列
explain分析中的type列:system>const>eq_ref>ref>range>index>all
正常来说保证查询到range级别,最好能达到ref级别。
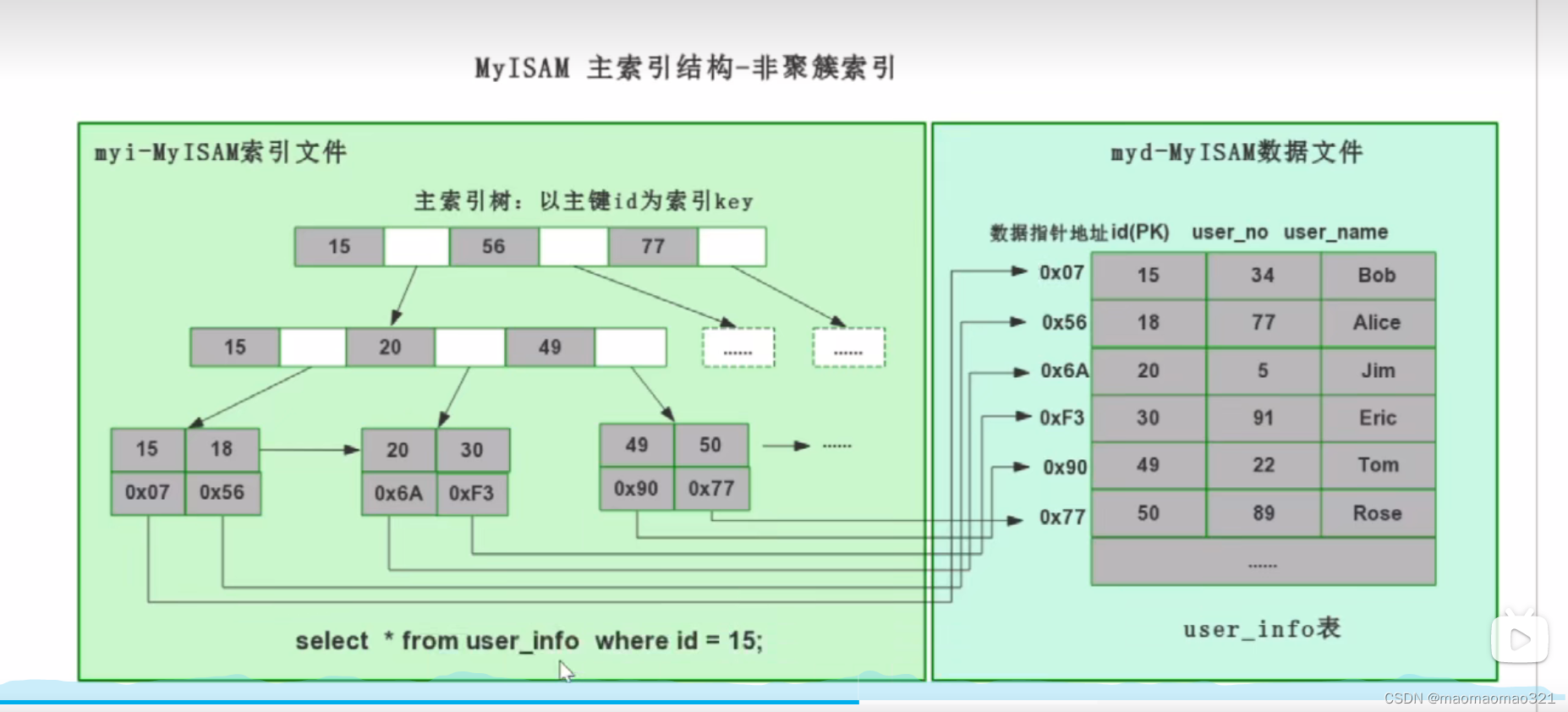
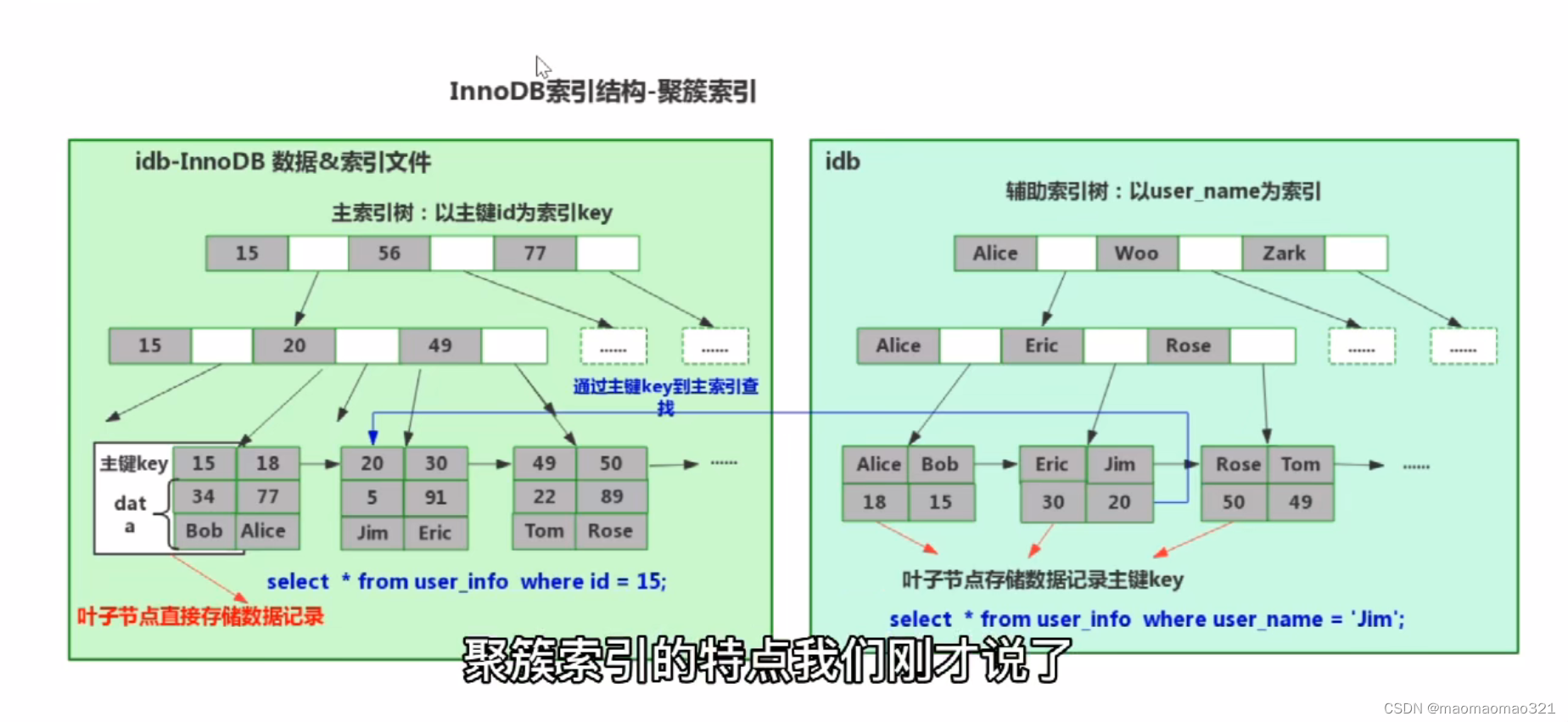
B+树+二分查找法:索引的底层结构和算法
MYsql的主要面试点:mysql的索引优化,mysql的acid(事务特性)
redo log比数据缓区buffer的同步要快的多,主要两个原因:
1.buffer是随机io,更新的数据在表中的位置是不确定的,而redo log是追加模式,在redo log日志文件后面追加,是顺序io
2.buffer写入数据是以page(页)为单位的,即时只更新了一条数据,也要写入一页数据16k.而redo log只需要写入真正需要的数据,减少了无效的io;


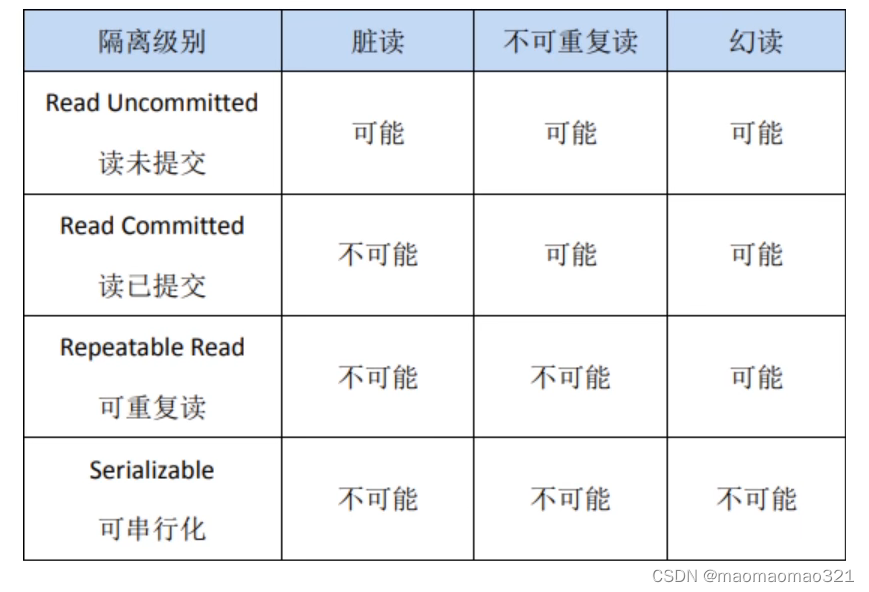
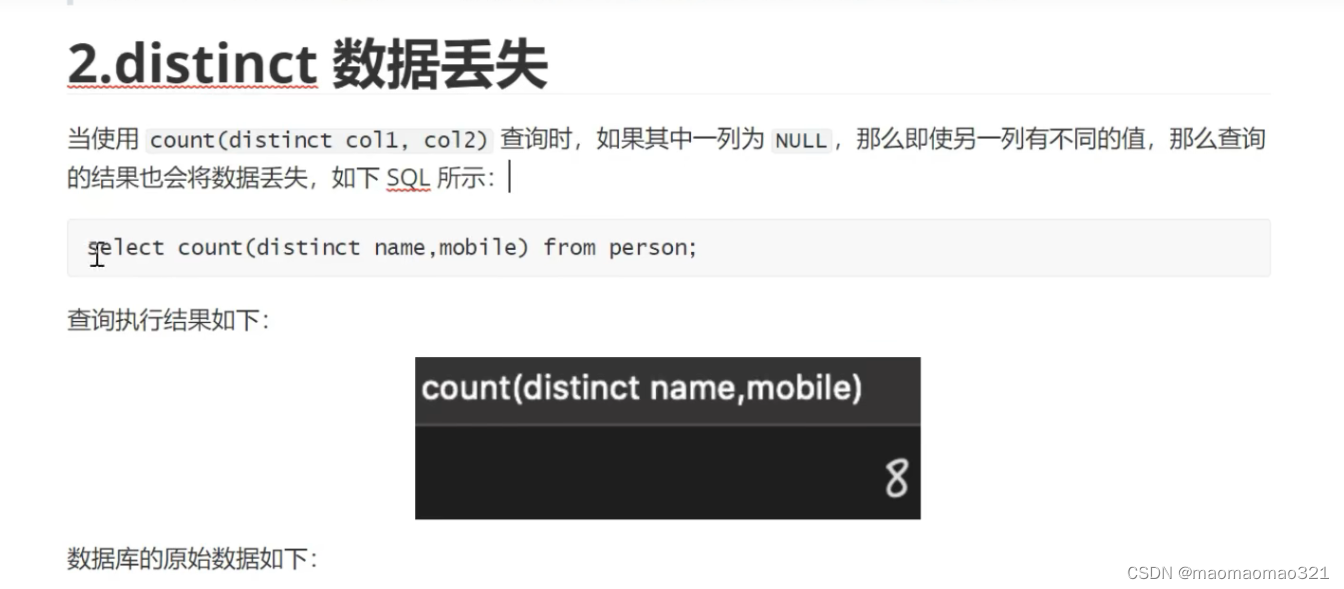
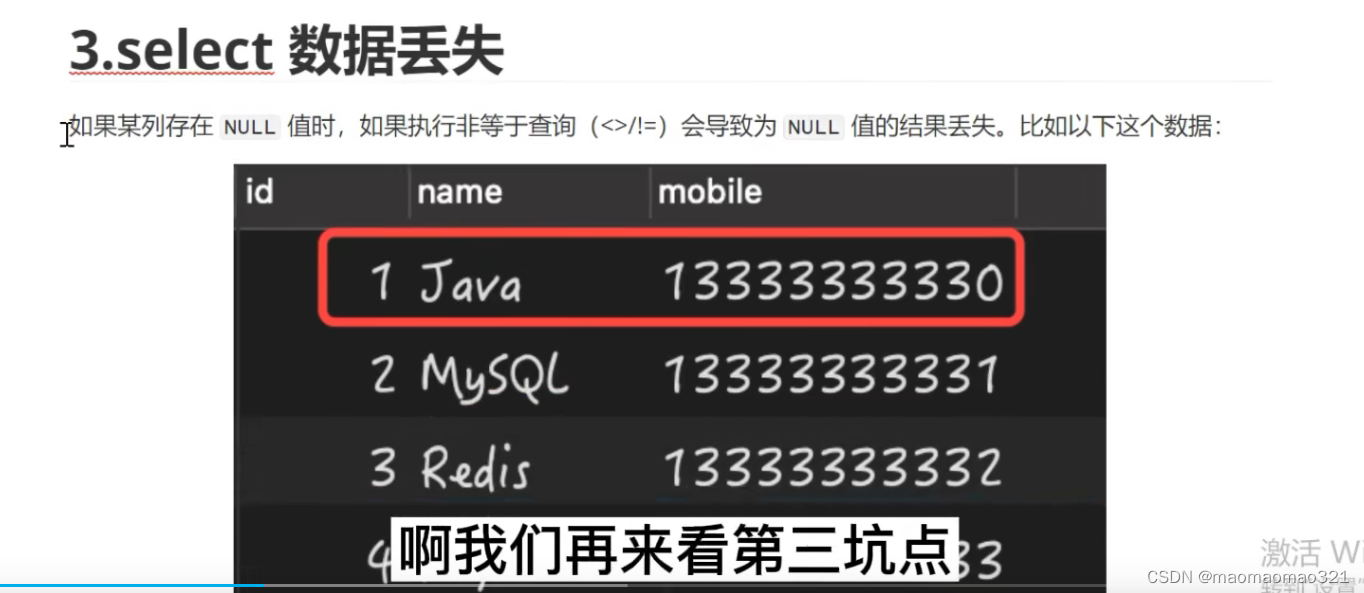
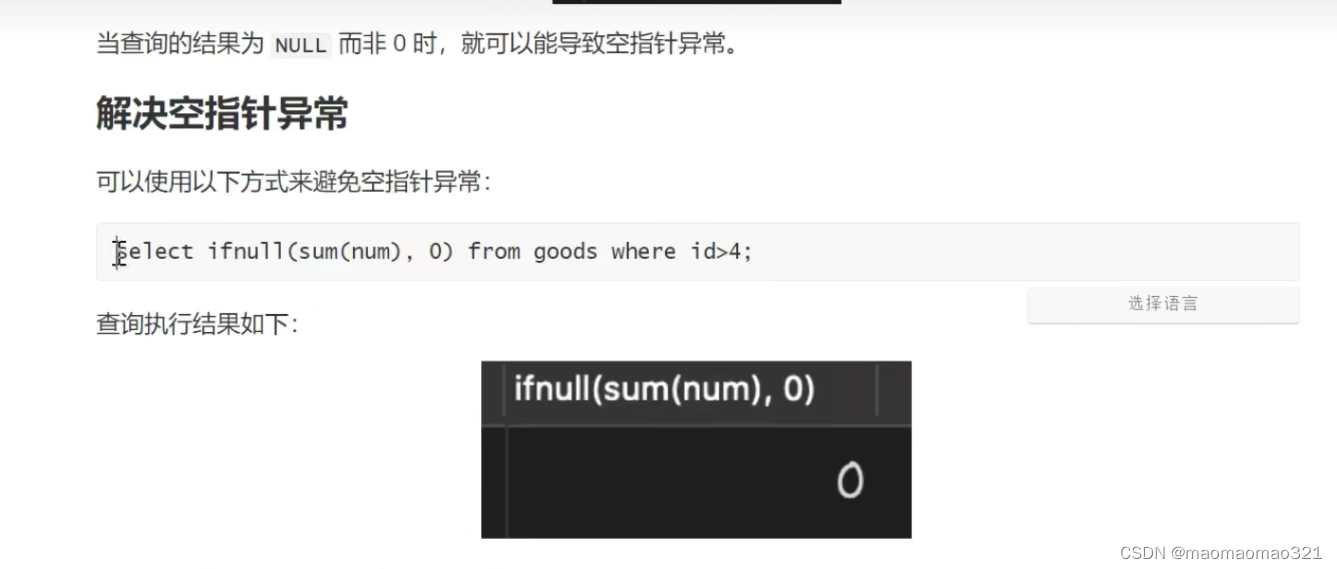
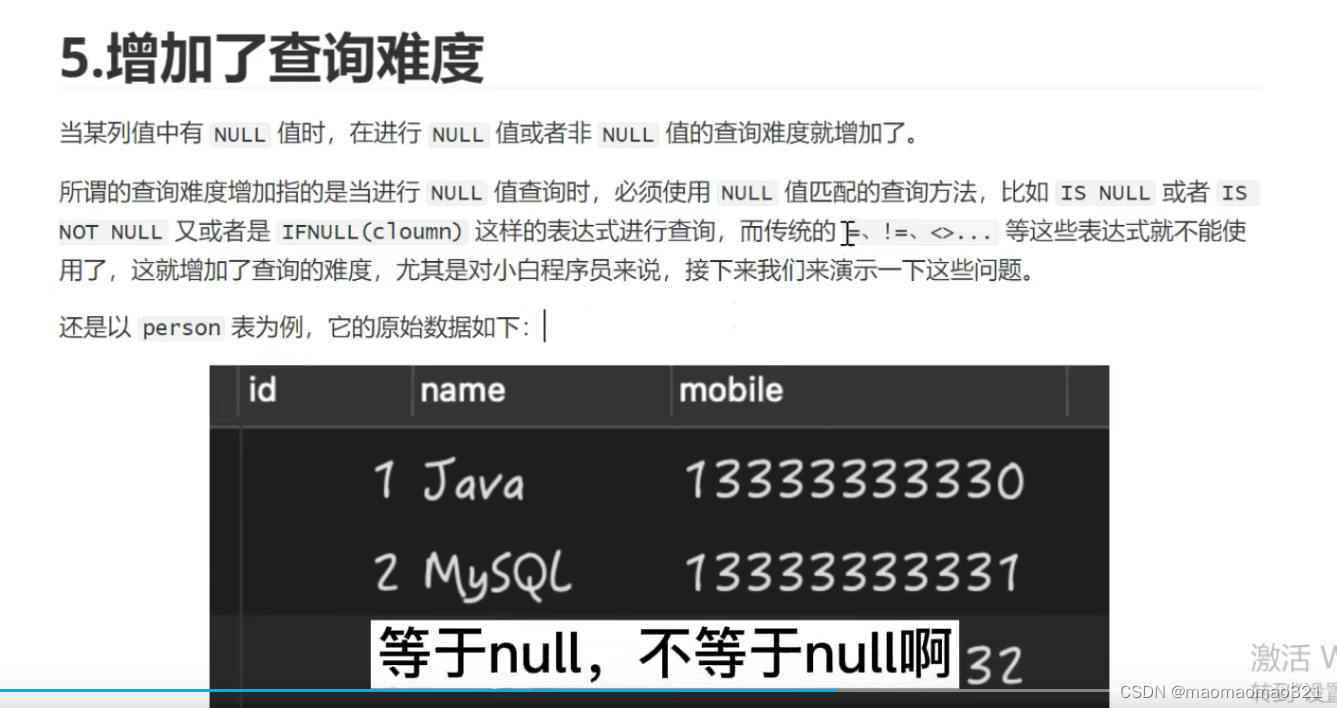
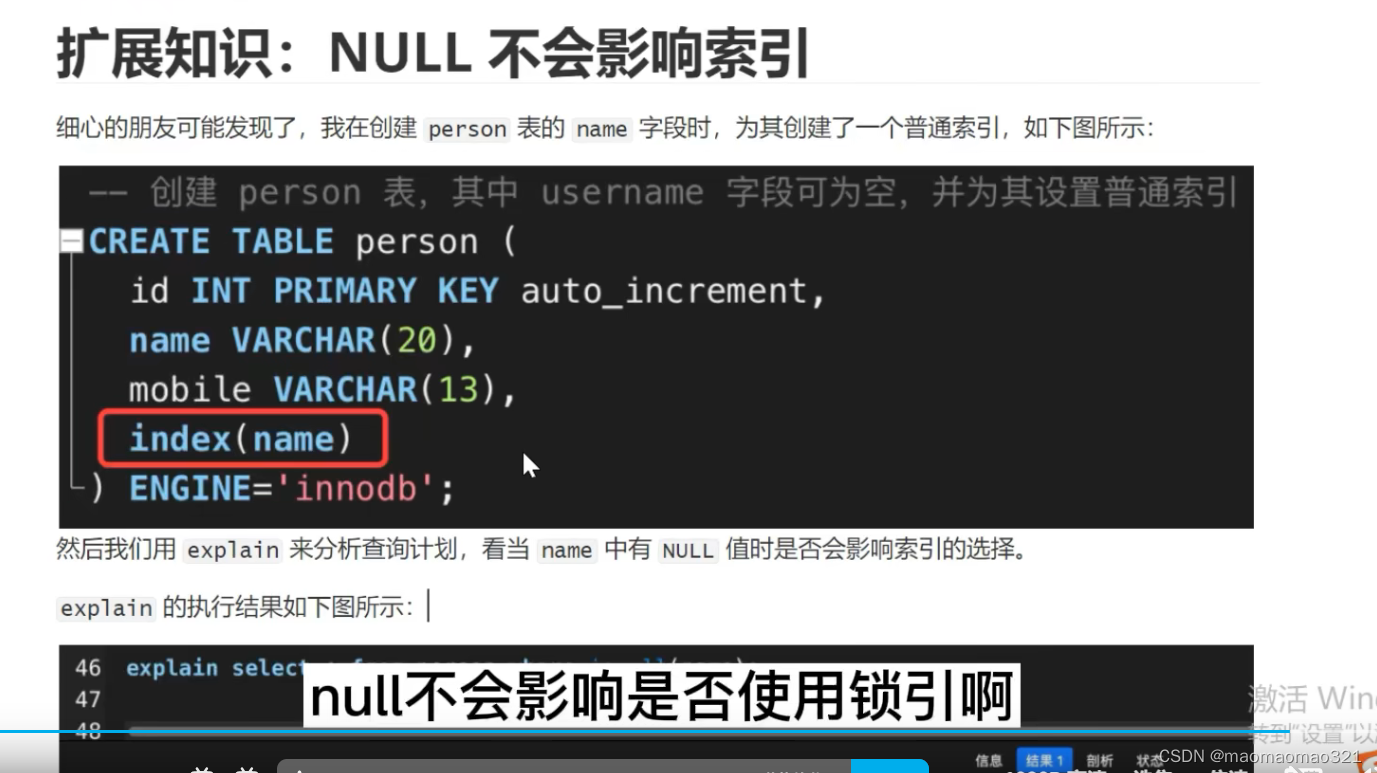
mysql中列值为空的坑:
count(列名)不会统计为null的记录

B+树彻底解决了范围查询时,二叉树和b-树回旋查找的问题
b-树
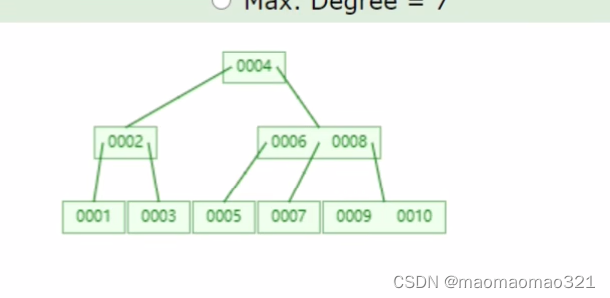
b+树:通过单向链表来解决回旋查找问题;

使用no_cache来不适用缓存查询数据库
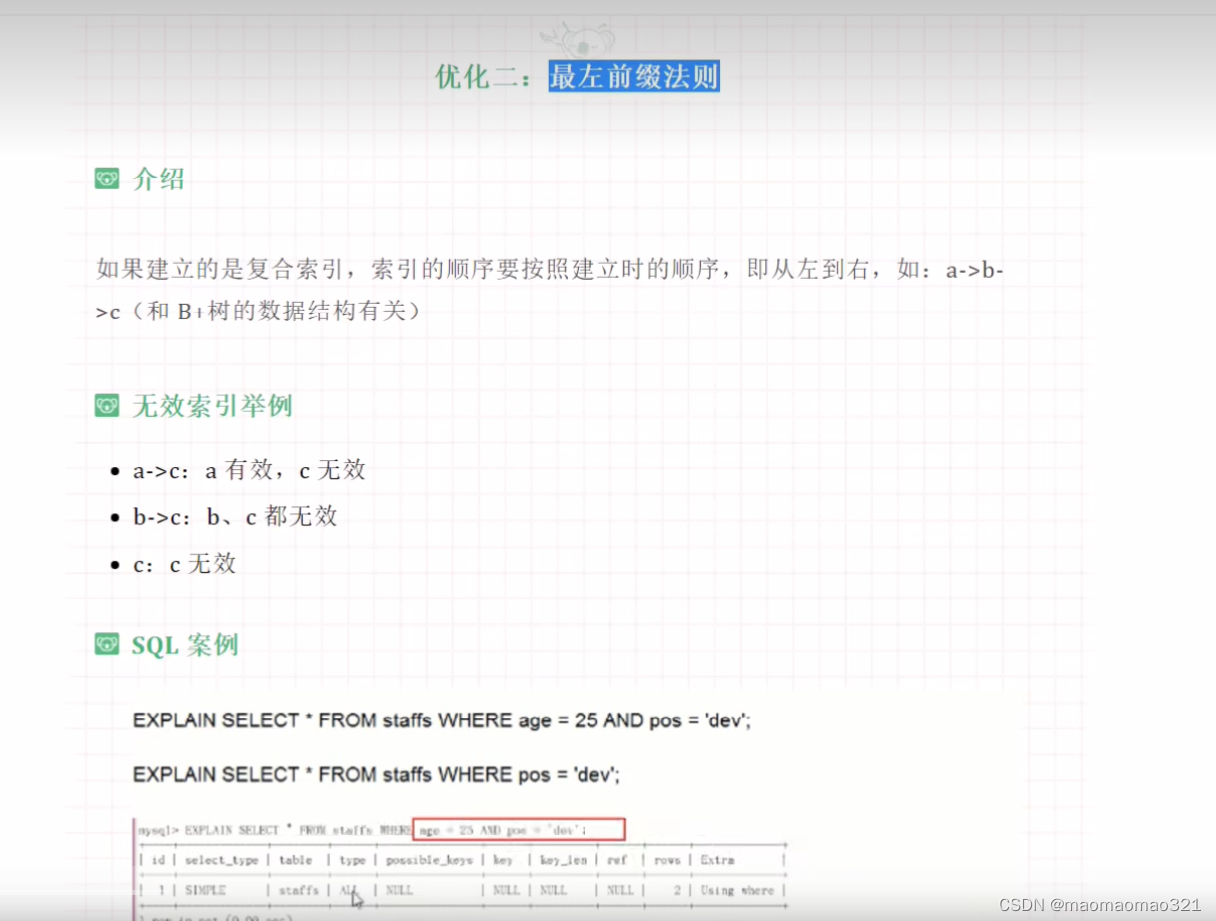



而且使用*会查询很多不必要的字段,增加网络带宽压力; 可以使用覆盖索引优化左前缀like;
可以使用覆盖索引优化左前缀like;

可以用覆盖索引去解决mysql中排序问题;但是满足不了业务需求;所以可以考虑在java代码中做排序,速度要快得多;















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









