







pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,\
keys=None, levels=None, names=None, verify_integrity=False,sort=None,copy=True)
#objs: series,dataframe或者是panel构成的序列lsit
#axis: 需要合并链接的轴,0是行,1是列
#join: 连接的方式 inner,或者outer
#keys: 加上一个层次化索引,识别数据源自于哪张表
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
#纵合并两张表的列名需要完全一致
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None,\
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'),\
copy=True, indicator=False, validate=None)
#主键合并数据,根据某几个字段将表拼接起来
#left: 接收DataFrame或Series。表示要添加的新数据1。
#right: 接收DataFrame或Series。表示要添加的新数据2。
#how: 数据融合的方法inner、outer、left、right.
#on: 列名,对齐的那一列的名字.
#left_on: 左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
#right_on: 右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
#left_index/ right_index: 如果是True的haunted以index作为对齐的key.
#sort:根据dataframe合并的keys按字典顺序排序,默认是false。
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
#部分主键合并,主键名需要完全一致
DataFrame.combine_first(other)
#重叠合并,用于处理两份数据几乎一致,但是某些特征在其中一张表上是完整的,
#而在另一张表上的数据则是缺失的情况
[/code]
清洗数据的过程主要包括检查与处理重复值、缺失值、异常值等
```code
#去除重复记录, first保留第一个,last保留最后一个,false只要重复都不保留
DataFrame.duplicated(subset=None, keep='first')
#去除重复记录,将特征间相似度为1的特征去除,或利用DataFrame.equals方法进行特征去重
corrDet = detail[['counts','amounts']].corr(method='kendall')
def FeatureEquals(df):
dfEquals=pd.DataFrame([],columns=df.columns,index=df.columns)
for i in df.columns:
for j in df.columns:
dfEquals.loc[i,j]=df.loc[:,i].equals(df.loc[:,j])
return dfEquals
#删除缺失值记录,0代表行,1代表列,how可以取any或all
detail.dropna(axis = 1,how ='any',subset=['dish_name','counts'])
#替换缺失值记录
detail.fillna(-99)
[/code]
常用的插值法有线性插值、多项式差值、和样条插值等。pandas提供了对应名称为interpolate的模块,但是SciPy的interpolate模块更加全面。
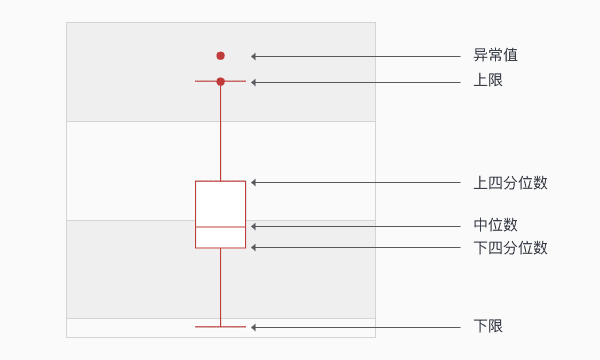
异常值是指数据中个别值的数据明显偏离其余的数值,有时也称为离群点,检测异常值就是检测数据中是否有输入错误以及是否有不合理的数据。常用的异常值检测主要有3σ原则和箱线图分析两种方法。
3σ原则:仅适用于正态或近似正态分布的样本,超出(u-3σ,u+3σ)范围的数据可认为为异常数据。
箱线图:箱线图依据实际数据绘制,真是、直观地表现出了数据分布的本来面貌,且没有对数据做任何限制性要求,异常值被定义为超出(QL-1.5IQR,QH+.5IQR)的值,QL/QH为下/上四分位数,IQR=QH-
QL。如果箱形图很扁,异常值很多可以尝试进行对数变换。
## 使用scikit-learn构建模型
sklearn库整合了多种机器学习算法,拥有优秀的官方文档。
datasets模块继承了部分数据分析的经典数据集,加载后的数据可以视为一个字典,可以使用data、target、feature_names、DESCR获取数据集的数据、标签、特征名称和描述信息。
```code
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer() #将数据集赋值给变量
print("输出前4个特征名称:",cancer['feature_names'][:4])
#输出前4个特征名称: ['mean radius' 'mean texture' 'mean perimeter' 'mean area']
[/code]
sklearn提供了model_selection模块、preprocessing数据预处理模块与decompisition特征分解模块。通过这三个模块能够实现数据预处理与模型构建前的数据标准化、二值化、归一化、数据集的分割、交叉验证和PCA降维等工作。
```code
from sklearn.model_selection import train_test_split #划分数据集
dtrain, dtest,ttrain, ttest = train_test_split(cancer['data'],\
cancer['target'],test_size=0.2)
from sklearn.preprocessing import MinMaxScaler
Scaler = MinMaxScaler().fit(dtrain) #生成标准化规则
cancer_trainScaler = Scaler.transform(dtrain) #将规则应用于训练集
cancer_testScaler = Scaler.transform(dtest) #将规则应用于测试集
from sklearn.decomposition import PCA
pca_model = PCA(n_components=10).fit(cancer_trainScaler) #生成PCA降维规则规则
cancer_trainPca = pca_model.transform(cancer_trainScaler) #将规则应用于训练集
cancer_testPca = pca_model.transform(cancer_testScaler) #将规则应用于测试集
#降维前后测试集:(455, 30),(455, 10)
StandardScaler #对特征进行标准差标准化
Normalizer #对特征进行归一化
Binarizer #对定量特征进行二值化处理、
OneHotEncoder #对定性特征进行独热编码处理
FunctionTransformer #对特征进行自定义的函数变换
[/code]
构建评价聚类模型
```code
fit #主要用于训练算法
predict #主要用于监督学习
[/code]
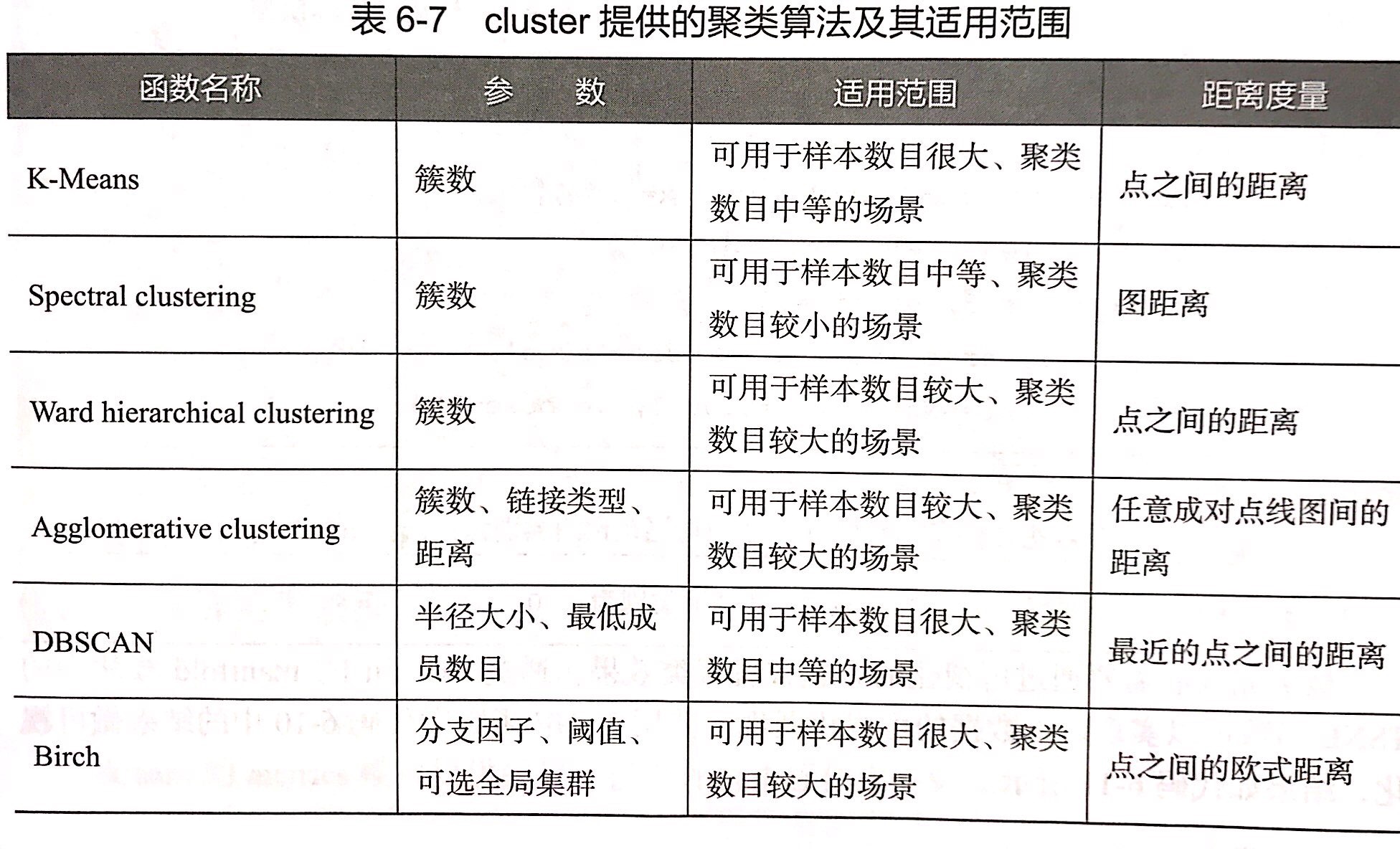
构建评价分类模型

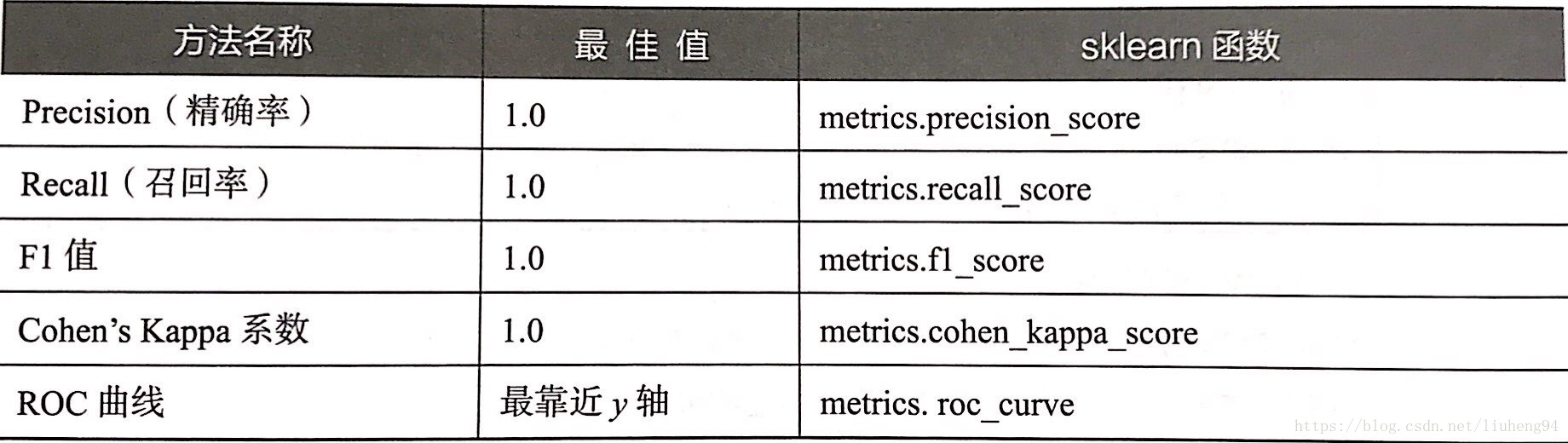
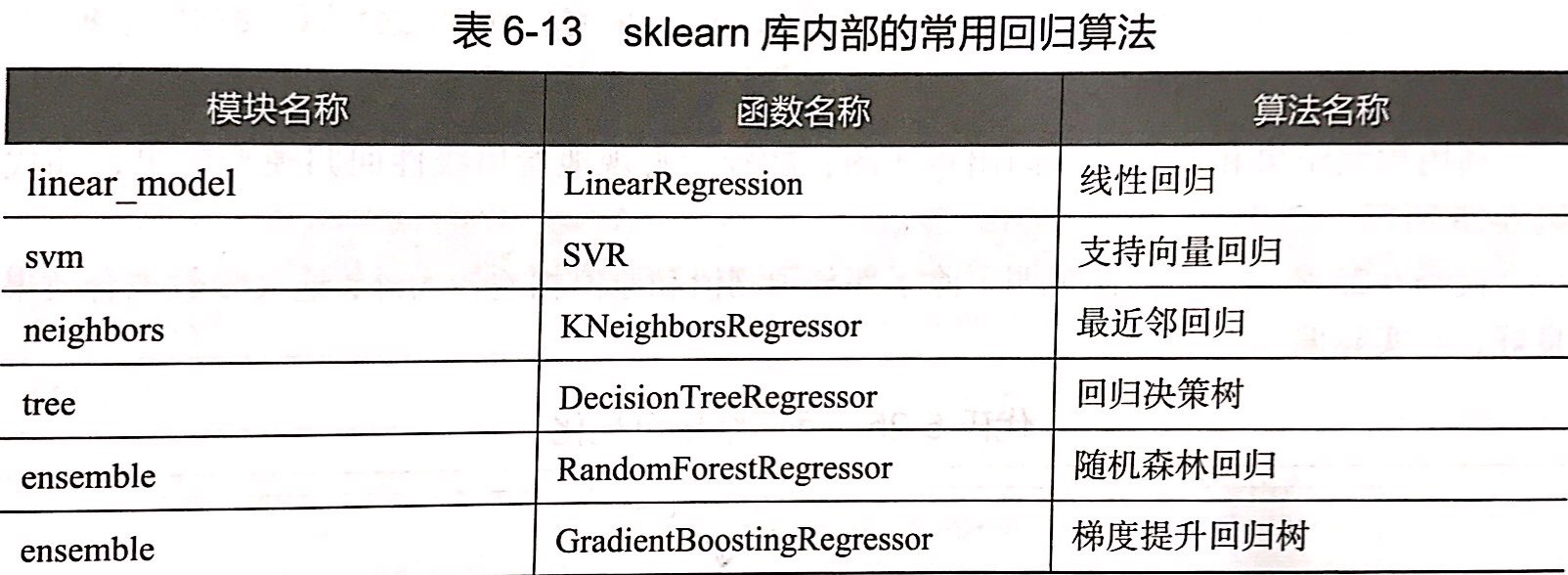
构建评价回归模型
```code
##加载所需函数
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
## 加载boston数据
boston = load_boston()
X = boston['data']
y = boston['target']
names = boston['feature_names']
## 将数据划分为训练集测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,\
random_state=125)
## 建立线性回归模型
clf = LinearRegression().fit(X_train,y_train)
print('建立的LinearRegression模型为:','\n',clf)
## 预测训练集结果
y_pred = clf.predict(X_test)
print('预测前20个结果为:','\n',y_pred[:20])
##评价模型性能
from sklearn.metrics import explained_variance_score,mean_absolute_error,\
mean_squared_error,median_absolute_error,r2_score
mean_absolute_error(y_test,y_pred) #平均绝对误差
mean_squared_error(y_test,y_pred) #均方误差为
median_absolute_error(y_test,y_pred) #值绝对误差
explained_variance_score(y_test,y_pred) #可解释方差值
r2_score(y_test,y_pred) #R方值
[/code]
















 8414
8414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









