









(1)可变形部件模型
可变形部件模型(DeformablePart Model)由三部分组成:
(1) 一个较为粗糙的,覆盖整个目标的全局根模版(或叫做根滤波器)。
(2) 几个高分辨率的部件模版(或叫做部件滤波器)。
(3) 部件模版相对于根模版的空间位置。
首先要计算一个HOG金字塔:通过计算标准图像金字塔中每层图像的HOG特征得到HOG特征金字塔,HOG金字塔中每一层的的最小单位是细胞单元(cell)。
滤波器(模版)就是一个权重向量,一个w * h大小的滤波器F是一个含w * h * 9 * 4个权重的向量(9*4是一个HOG细胞单元的特征向量的维数)。所谓滤波器的得分就是此权重向量与HOG金字塔中w * h大小子窗口的HOG特征向量的点积(DotProduct)。
而检测窗口的得分是根滤波器的分数加上各个部件的分数的总和,每个部件的分数是此部件的各个空间位置得分的最大值,每个部件的空间位置得分是部件在该子窗口上滤波器的得分减去变形花费。
假设H是HOG金字塔,p = (x, y, l) 表示金字塔第l层 (x, y) 位置的一个细胞单元。φ(H, p, w, h)是将金字塔H中以p为左上角点的w * h大小子窗口的HOG特征串接起来得到的向量。所以,滤波器F在此检测窗口上的得分为:F·φ(H, p, w, h)。此后,在不引起歧义的情况下,我们使用φ(H,p)代表φ(H, p, w, h)。
所以,含n个部件的模型可以通过根滤波器F0和一系列部件模型(P1,..., Pn)来定义,其中Pi = (Fi, vi, si, ai, bi)。Fi是第i个部件的滤波器;vi和si都是二维向量,都以细胞单元为单位,vi指明第i个部件位置的矩形中心点相对于根位置的坐标,si是此矩形的大小;ai和bi也都是二维向量,指明一个二次函数的参数,此二次函数用来对第i个部件的每个可能位置进行评分。
模型在HOG金字塔中的位置可以用z = (p0, ..... , pn)来表示,当i=0时,pi = (xi, yi,li )表示根滤波器的位置;i>0时,pi = (xi, yi,li )表示第i个部件滤波器的位置。我们假设每个部件所在层的HOG细胞单元的尺寸是根所在的层的细胞单元尺寸的一半。空间位置的得分等于每个部件滤波器的得分(从数据来看)加上(?加上减去都一样,通过正负号控制就行)每个部件的位置相对于根的得分(从空间来看)。
即:

(1)式中左边表示所有滤波器(i从0开始,包括根滤波器和部件滤波器)的得分(即滤波器的权重向量与对应的HOG特征向量的点积),右边表示所有部件滤波器(i从1开始)的形变花费。
其中:

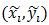
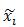
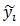
(x0,y0)是根滤波器在其所在层的坐标,为了统一到部件滤波器所在层需乘以2。
vi是部件i相对于根的坐标偏移,所以2(x0, y0)+vi表示未发生形变时部件i的坐标,
所以(xi,yi) – [2(x0,y0) + vi]是部件i的形变位移量,再除以部件的矩形框大小si可保证在-1到1之间。
计算过程如下图:
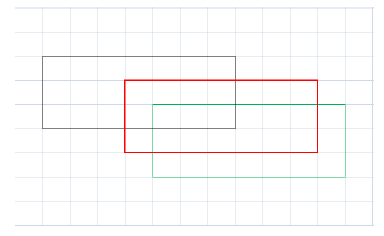
图中每个格子表示部件所在HOG金字塔层的细胞单元,红框表示某部件未发生位移时的位置,w=7,h=3.黑框表示部件的实际位置,因此
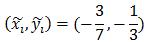
同理,绿框所在位置对应:
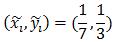
(2)在不完全标注(partially labeled)数据集上的学习
模型训练使用的数据集中只标注了整个目标的位置,没有标注出每个部件的位置,所以叫做部分标注或不完全标注,并不是说图片中有指定类别的目标没有标注出来,这里容易理解错误。
这种训练方法可以看做弱监督训练,正因为不知道目标中部件的位置,所以将部件的位置看做隐藏变量,使用LSVM进行训练,训练时同时估计部件位置和学习模型参数。
(3)半凸
LSVM最终是一个非凸规划(non-convex)问题。然而,在下面所讨论的情况下LSVM是半凸规划(semi-convexity)问题,一旦将隐藏信息指定给正样本则训练问题变为凸规划问题。
几个凸函数的最大值问题是凸规划问题。在线性SVM中,有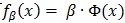
注意到公式(13)中定义的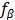
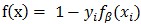

对于正样本(yi= 1)来说,LSVM的铰链损失函数不是凸函数,因为它是一个凸函数f(x)= 0 和一个凹函数
但是,当LSVM的正样本的隐藏变量具有唯一可能的取值时, 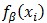
(4)坐标下降算法
对于含有隐藏变量的svm问题,使用坐标下降算法进行求解:
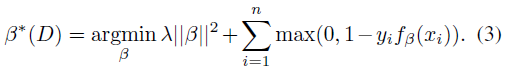
(1) 估计部件位置
保持β值不变,即将β看做常量,找到正样本的隐藏变量zi的最优值:
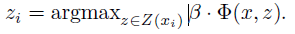
(2) 学习模型参数
保持正样本的zi值不变,即将zi看做常量,通过解上面定义的凸规划问题(即标准SVM问题)最优化β值。
(5)难例挖掘定理
定理1 设C是样本集D的一个子集,如果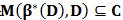
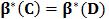
解释:在样本集D上训练一个分类器β( 即β*(D)),用β在样本集D上搜寻难例,得到难例集合即为M(β*(D), D),如果此难例集合包含于样本子集C,则在样本子集C上训练得到的分类器等价于在样本集D上训练得到的分类器。
定理2
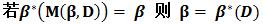
解释:现在有分类器β,β在样本集D上得到的难例集合为M(β,D),用M(β,D)训练一个分类器,即为β*(M(β, D)),如果训练出来的分类器等于β (这说明什么呢?这说明初始分类器β已经足够好了,因为再加入难例进行训练得到的是和初始分类器相同的分类器),则β就是样本集上的最优分类器。
迭代算法:
设C是最初的样本缓冲区(cache)。实际上可以将正样本和随机负样本放在一起。考虑如下迭代算法:
(1)设β:= β*(C)
(2)收缩C,使得C := M(β,C)
(3)通过不断向C中增加M(β, D)中的样本来增大C,直到达到内存限制L。
解释:
(1)C是一个样本缓冲区,在C上训练一个分类器β,即为β*(C)。
(2)用β在C上搜寻得到的难例代替C,使C变小(收缩)。
(3)用β在原样本集D上搜索难例,得到难例集M(β, D),从M(β, D)中拿出样本添加到C中,直到达到内存限制L。
重复步骤(1),在C上训练一个新的分类器β,继续重复步骤(2)(3)。就这样不断重复步骤(1)(2)(3),不断迭代。
定理3如果每次经上述算法步骤2的迭代后,有|C|<L,则算法在有限时间内会收敛到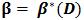
解释:定理3是一个收敛条件,因为在定理2中迭代算法的第(3)步里会将样本缓冲区C增加到L大小,如果进行下一次迭代时,C可以变小,就说明算法在收敛。怎么理解呢?将分类器看做是一个学生,此学生在学习新知识,不断加入的新难例就是新知识,缓冲区C就是学生的书包,新加入的知识放到学生的书包中,如果每次学习过程书包变小,就说明学生将一些新加入的知识消化了,变成了学生的一部分。随着学习过程的进行,新知识一点一点被消化,学生也变得越来越聪明。在这里就是随着迭代过程的进行,难例被一点一点消化,分类器逐渐变得更好。
A Discriminatively Trained, Multiscale,Deformable Part Model[CVPR 2008]的中文翻译
Object Detection with Discriminatively Trained Part Based Models[PAMI 2010]的中文翻译
Deformable Part Model 相关网页:http://www.cs.berkeley.edu/~rbg/latent/index.html
Pedro Felzenszwalb的个人主页:http://cs.brown.edu/~pff/
PASCAL VOC 目标检测挑战:http://pascallin.ecs.soton.ac.uk/challenges/VOC/
有关可变形部件模型(Deformable Part Model)的一些说明














 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









