






最近我发现有不少朋友在学习了“Stable diffusion”之后,还只是在“玩”这个层次上徘徊。但是,我认为,最重要的,还是要让所有人都能“用”到它。
于是我思考了很久,找出了SD在“应用”层面,最重要的两个功能:Lora 和 ControlNet
Lora负责把自己生活中有关联的人或物炼制成模型,ControlNet负责更好地“控制”这个“模型”
当这两样东西结合在一起,你才能真正的使用 SD,不管是为自己量身定做一个真人,还是为一个商业产品做一个模型,都能做到。
所以,今天这篇是Lora的炼丹教程篇
文章包含了Lora的功能介绍,炼丹方法,实操案例,大家只要跟着一步一步操作,一定能学会。另外需要用到的整合包和模型也都给大家打包好了,请看文末扫描获取哦
一、炼Lora能做到什么
1.AI模特
为自己制作一个模特,然后把模特带到自己的产品上。

2.炼衣服Lora
添加一个衣服的Lora,就可以让人物穿上特定的衣服

3.改变画风
增加 Lora来改变图片的风格,这种风格是可以自己调整的。

那Lora究竟是什么?
Lora可以复刻人物和物品的特征,固定人物动作,改变照片画风
Lora所需的数据非常少,比起大型的模型,要容易得多。因此,每个人都可以根据自己的 Lora来制作自己喜欢的照片。
给大家看看我自己训练的Lora复刻真实的程度
真人Lora👇

衣服Lora👇

二、4个步骤炼制Lora
炼制Lora有许多不同的方法,但它们的训练逻辑都是一样的
所以我们选择整合包就可以了,整合包就是把炼丹所需要的所有工具都整合到一个软件里。需要Lora训练器的小伙伴可以扫描获取哦

炼丹分为以下几步:
1.下载整合包
2.准备素材
3.测试Lora
4.优化Lora
接下来我就用女朋友的照片炼一个Lora,详细的给大家展示具体的操作
三、炼丹前的准备
在炼Lora之前,需要大家先确认一下自己的电脑配置:
1.需要N卡,并且6G显存以上
2.A卡和Mac系统,或者电脑配置不太行的小伙伴建议用云平台,云端平台的使用教程可以看上方扫描获取哦
3.本地下载整合包,解压即用
在我分享的网盘链接里面可以下载整合包(请看文末扫描获取),下载好了之后把它解压到D盘或者E盘,不要放在C盘!!
打开解压之后的文件夹,在“cfurnace_ui”文件夹里面找到“赛博丹炉”的应用程序
双击打开
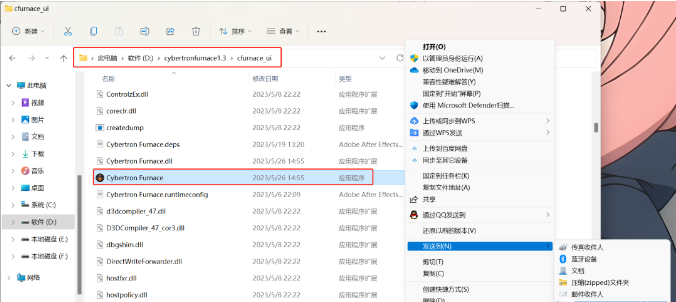
看到这个页面就安装好了,点击“开启炼丹炉”就可以开始炼Lora啦!
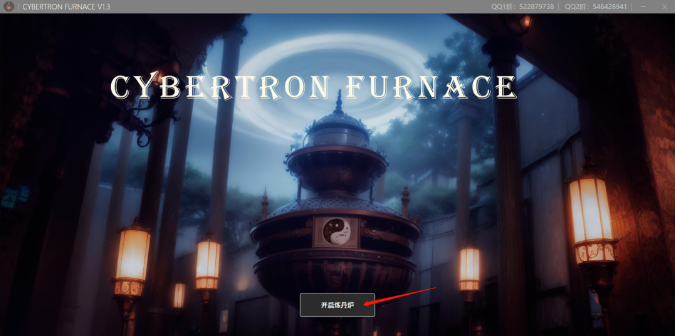
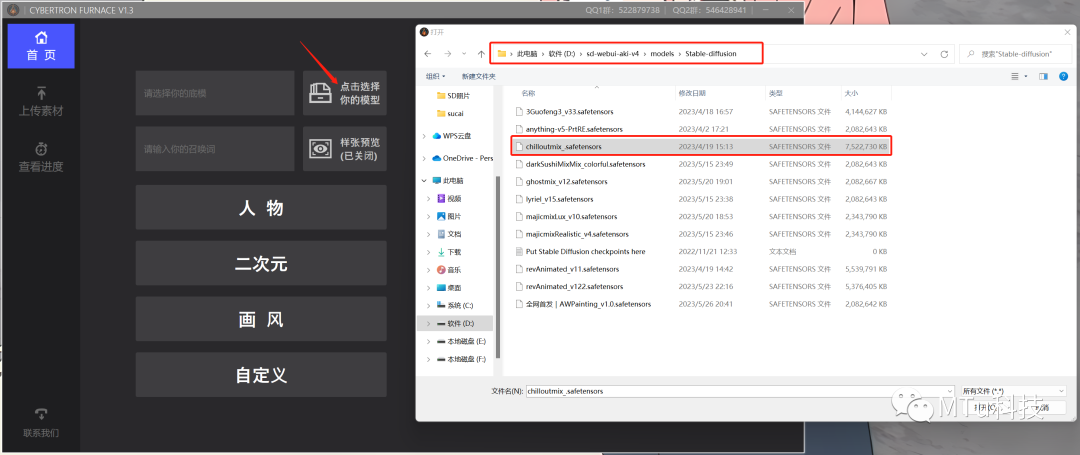
四、选择合适的大模型
跟画图一样,炼Lora之前也要先选一个大模型,确定Lora的画风。点击可以直接打开文件夹,找到SD的文件夹调用里面的模型
我这里打算炼一个真人模型,所以选用“chilloutmix”的大模型
如果你的Stable Diffusion里面没有模型,那就要先去下载模型噢!
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
第二个框框就是输入这个Lora的名字
右边的“样张预览”可以打开,这样我们等一下在训练Lora的过程中就可以实时看到照片
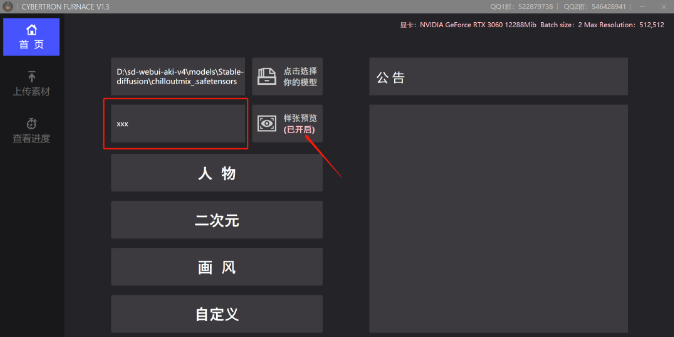
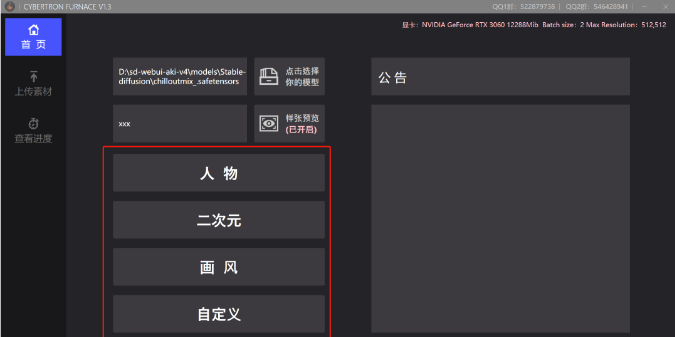
再往下就可以选择一个我们要训练的Lora的类型
选择之后就会帮我们选择默认的参数
训练真人Lora就选“人物”
训练二次元就选“二次元”
如果想炼绘画的风格可以选画风
除此之外还可以自定义去炼平面设计图或者建筑之类的
五、高质量素材的制作
设置好参数之后,我们就可以上传照片素材了,素材的质量非常重要!!
它直接影响最后出来的Lora的质量,我们的素材需要满足几个点:
1.上传20~30张照片
2.素材要高清!!!
3.多角度照片
这里我就以炼真人Lora为例子,上传真人的照片
点击“删除全部”把默认的素材删掉
然后点击“上传素材”,上传自己的照片
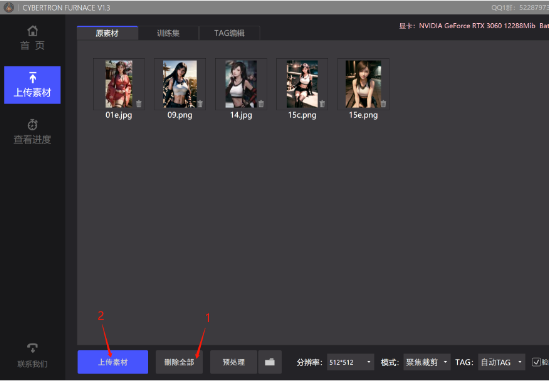
一般情况下,下面的参数默认就可以了
不要选择太高的分辨率,容易爆显存
另外,如果训练真人Lora,可以勾选最右边的“脸部加强训练”
勾选了之后就会再多裁剪出来一组只有脸的照片,这样AI能学到更多的脸部细节
接着点击“预处理”

处理完之后训练集里面就会有两组素材
一组是原素材,还有一组就是裁剪的只有脸的素材

人脸素材里面会有些识别不准确的照片
我们点击照片右下角的图标把照片删掉

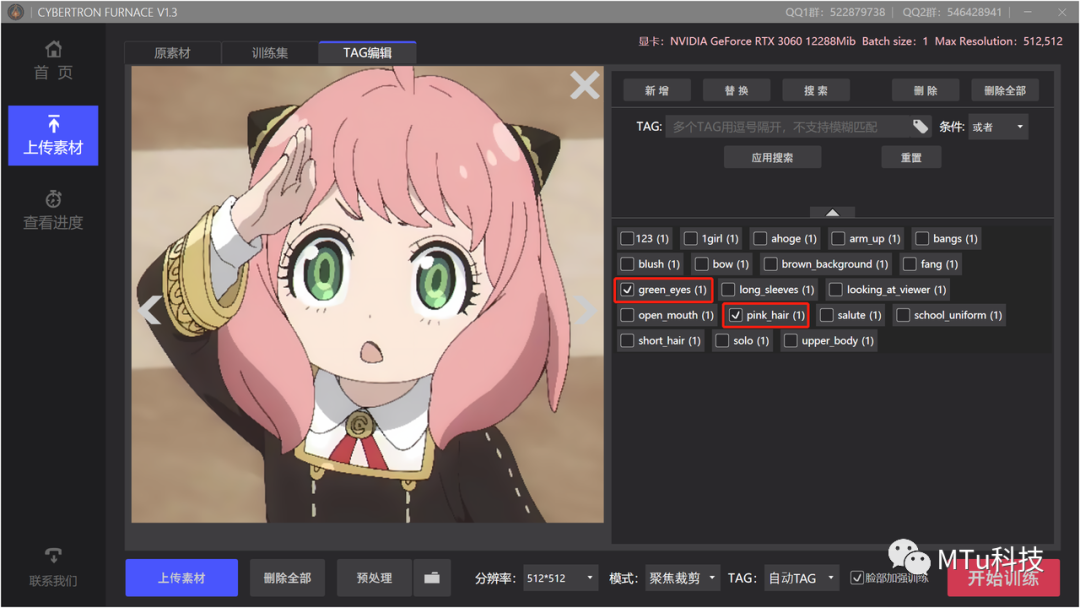
再看到“TAG编辑”
这里面就是形容照片的一些标签
右边是所有照片的标签
单独点击某一张照片就可以看到这张照片的标签

这里我们需要把照片大概检查一下
手动删掉或者增加标签
标签和照片对不上,AI就会学错了
比如这张照片的标签里的“夹克”和“白色衬衫”就是错的
把这两个标签勾选上,点击“删除”
然后新增一个“粉色衬衫”

另外,关于标签,必须了解!
如果你希望保持一个角色的特性,那么就需要删除相应的标签 让AI认为该角色具有该特性。
如果您希望对一个功能具有灵活性,请将其标记为该功能
比如:
如果我现在要教这个角色的话
粉红的头发,碧绿的眼睛是这幅画的特点

如果你想要在 SD中继续拍摄这个角色,那么你想要她的容貌吗?
然后我们要去掉粉发碧眼的标签
所以,无论我们输入的是白发还是黑发,出现的都是粉发。
如果您希望在 SD中定制您的发色,请在此处输入“粉色头发”
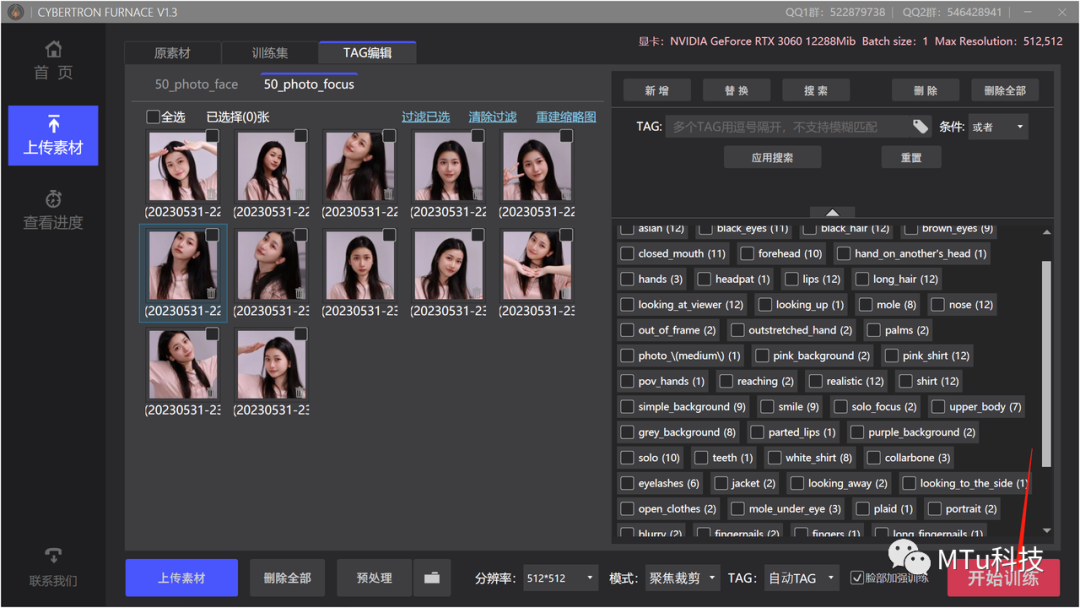
言归正传!
完成所有的选项卡之后,就可以点击右下角的选项进行练习了。
六、耐心等待的训练过程
看到这个页面就是模型正在训练中
到这一步只要耐心等待就可以了,没什么需要操作的
我们来看看以下参数的含义
这里的“Steps”指的是练习的步骤
在每个练习50个步骤的右下角显示一个图像
这样我就能看到洛拉的脸了。
这一头白发,一条红色的裙子,都是被人添加进去的。
可以对 Lora进行推广测试
“普适性”指的是 Lora在照片中可以随意改变自己的发型,发色,衣服等等。

Loss可以用来参考模型的好坏
一个好的模型Loss值在0.07~0.09之间
具体好不好还是要在Stable Diffusion实际测试才知道

等训练完了之后,点击“模型”
就可以看到生成出来模型
按照默认参数训练会出来10个模型,但不是说最后一个模型就是最好的
有可能炼到第六第七个模型就已经够了,再往后的模型就已经训练过度了
所以这些模型还要实际在SD测试一下,才知道哪个是最好的

七、如何测试Lora的好坏
模型生成出来之后就可以到Stable Diffusion(简称SD)里面生成图片
在 SD里面,可以生成这样一张大图,可以直观地看到所有模型在不同权重下的效果。
如果您想要比较哪一种模式,那么您就只需要保留那一种模式即可。

接下来我们就看看怎么生成这张大图
首先把新生成的10个模型复制到SD的models文件夹,放到Lora文件夹里面
可以在Lora文件夹里新建一个文件夹来存放

然后把没有序号编码的那个Lora重命名
没有序号编码的Lora就是最后生成出来的一个模型
为了方便进行测试,统一一下所有模型的名称

保存好模型之后就可以打开SD进行测试了
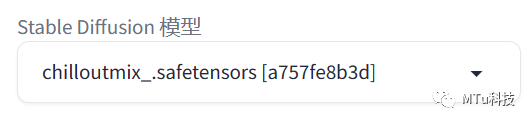
首先先选一个大模型
你用哪一个大模型来训练lora就选哪个大模型
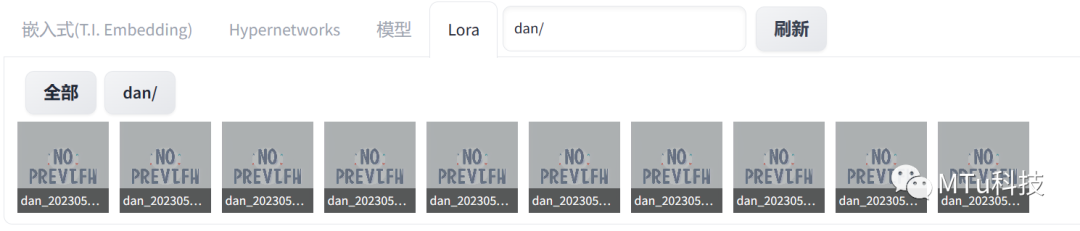
下一步,就是我们新制作出来的Lora了。
随便挑一个就行
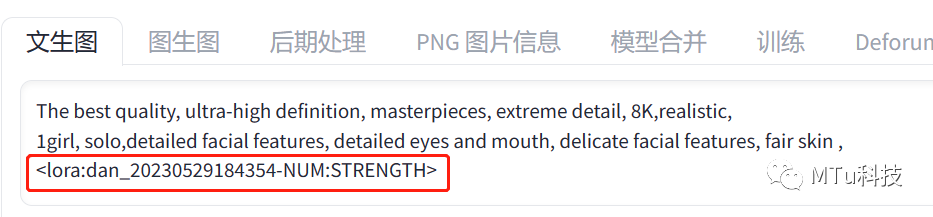
选了Lora之后,我们就会在关键词的文本框里看到这串Lora的编号

然后把“000006”那段数值改成“NUM”
把最后的数字“1”改成“STRENGTH”,也就是权重的意思
迭代步数,采样方法这些参数大家可以按照自己的习惯去修改
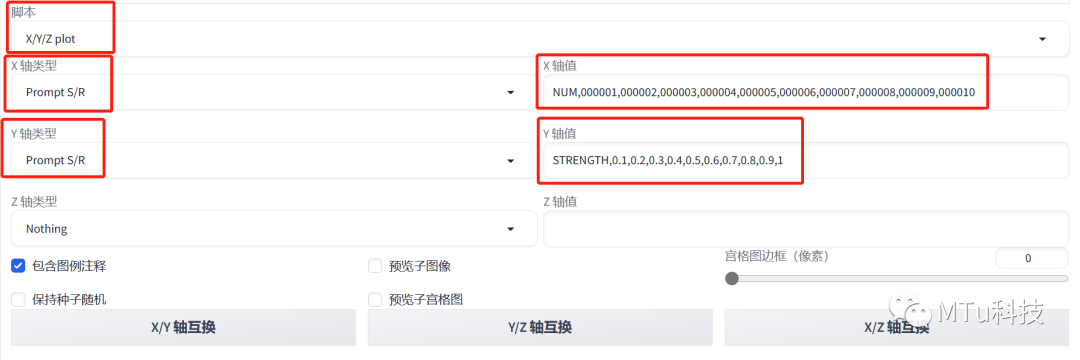
然后滑到最下面找到“脚本”
在脚本里面选择 “X/Y/Z图表”
X轴、Y轴类型都选择 “提示词搜索/替换”
X轴的值输入:NUM,000001,000002,000003,000004,000005,000006,000007,000008,000009,000010
这里的序号对应的就是我们10个Lora的编号
Y轴值输入:STRENGTH,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1
这里的序号代表的是Lora的权重
当所有的参数都被设置好后,接下来是“生成”的时候了。
生成了这样一幅大图,上面显示了10个 Lora在不同强度下的表现。
从下面的图片中,找出一幅与自己最相似,最有效果的图片。
就能看出哪种 Lora在什么强度下才能发挥出最大的作用。
像我可能就会选第七个Lora,在权重0.7的时候的照片

然后,我们可以对 Lora的推广能力进行测试。
在关键字中键入图片中找不到的内容
比如原来图片是黑色头发,那就在关键词里面输入一个白色头发
原来图片是粉色衣服,那就可以让它变成黑色衣服

要查看图片,请单击“生成”
半白半黑的头发和半黑的衣服
所以我认为洛拉已经够好了

来看看真人和AI的对比

这份完整版的资料我已经打包好,需要的点击下方添加,即可免费领取!
对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。


这份完整版的资料我已经打包好,需要的点击下方添加,即可免费领取!















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









