






随着人工智能技术的不断进步和深化,大模型已经成为深度学习领域的核心驱动力,是近年来备受关注和研究的热门领域之一。
今年8月31日,百度、字节、商汤、中科院旗下紫东太初、百川智能、智谱华章等8家企业和机构的大模型产品通过首批《生成式人工智能服务管理暂行办法》备案,可正式上线面向公众提供服务。
大模型的出现不仅改变了我们对人工智能的认识,更在深度学习的应用领域引领了新的革命。本文介绍什么是大模型,系统的分析其应用及发展。
01
什么是大模型
大模型,顾名思义,指的是具有庞大参数数量、计算需求高的机器学习模型。与传统的小规模模型相比,大模型在预训练阶段通过大量数据自我学习,然后通过微调在特定任务上发挥作用。
大模型的关键特点在于其庞大的参数数量,例如,GPT-3模型拥有1,750亿个参数,GPT-4模型推测拥有1.8万亿参数,中科院自动化所的紫东太初也是千亿级参数的大模型,阿里的通义千文包含1000亿个参数。
大模型庞大的参数代表了模型的权重和连接关系,这使得大模型能够学习更多的细节和抽象特征,从而提高模型的泛化能力和应用范围。例如,自然语言处理领域的大模型能够理解更复杂的语义关系,生成更自然流畅的文本;计算机视觉领域的大模型能够更精准地识别图像中的物体和特征。
近年国内外主要发布的大模型
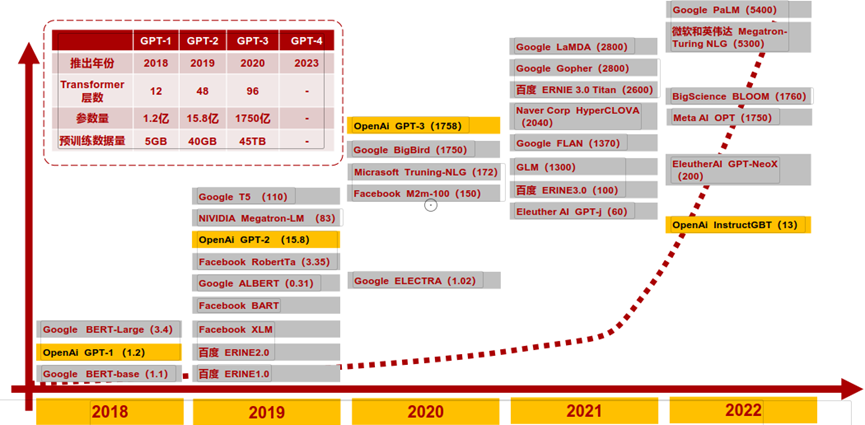
资料来源:浙商证券
02
大模型的分类

大模型是人工智能领域中的一项重要技术,根据应用领域和任务类型的不同,可以分为几种不同的分类。
1.自然语言处理模型
自然语言处理模型是大模型在处理文本和语言任务方面的应用。这类模型被广泛用于机器翻译、文本生成、情感分析、问答系统等任务。其中,百度的文心大模型、字节跳动的Byte BERT(基于Bidirectional Encoder Representations from Transformer 深度双向语言表征模型) 、OpenAI的GPT(Generative Pre-training Transformer 生成式预训练模型)系列就是一种典型的自然语言处理大模型,它能够根据输入的文本生成连贯、富有创意的文章。
2.计算机视觉模型
计算机视觉模型是大模型在处理图像和视觉任务方面的应用。这类模型在图像分类、目标检测、图像生成等领域具有出色表现。如OpenAI推出的DALL-E大模型,能够根据文本描述生成符合要求的图像。
3.跨模态模型
跨模态模型是指能够同时处理不同类型数据(如文本、图像等)的大模型。这类模型在理解和关联不同模态的信息方面表现出色。例如,紫东太初,是中科院自动化所开发的全球首个多模态全开源大模型。它以图文音三模态为统一表示,具有全模态理解、多任务处理、多样化生成和大模型部署等核心能力。
4.强化学习模型
强化学习模型是一类通过与环境交互来学习最优行动策略的大模型。这类模型在机器人控制、游戏策略等领域有广泛应用。AlphaGo就是一个著名的强化学习大模型,它在围棋比赛中击败了人类世界冠军。
5.领域特定模型
除了通用领域的应用外,大模型还可以根据特定领域的需求进行定制。如在金融领域,可以开发用于市场预测的大模型,比如度小满推出了用于风控和反欺诈的特定大模型AlphaRisk。
03
大模型的优势

- 更强大的表示能力
大模型之所以在人工智能领域引起广泛关注,主要在于其卓越的表示能力。表示能力是指模型对数据的理解和表达能力,而大模型由于其庞大的参数规模和复杂的结构,可以捕捉更多的数据细节和抽象特征。这意味着大模型可以更准确地分析和理解数据,从而在各种任务中取得更优异的表现。
以自然语言处理领域为例,大模型如GPT-3可以生成流畅、自然的文本,因为它学习到了丰富的语义和句法规律。对于计算机视觉任务,大模型能够更精准地识别图像中的对象、特征和背景信息,从而提高了图像识别的准确度。大模型的强大表示能力使得它们能够更好地捕捉数据的内在关系,实现更高水平的数据处理和分析。
- 更好的泛化性能
意味着一个模型在学习了一些数据后,能够很好地应用到以前没有见过的新数据上。具有更好泛化性能的模型不仅仅背诵了学习数据,还能理解数据中的规律和模式,从而能够适应不同情况,表现出更高的准确性和可靠性。
假设正在学习识别动物,用一些照片来训练模型,让它能够分辨狗和猫。给模型展示了很多张狗和猫的照片,告诉它什么样的特征是属于狗,什么样的特征是属于猫。
当模型训练好后,用一张新的照片来测试它,这张照片上是一只从未见过的狗。如果模型具有更好的泛化性能,它将能够从之前学习过的狗的特征中找到一些相似之处,识别出这是一只狗。即使这只狗的外观和之前见过的狗有所不同,模型也能够做出正确的判断。
然而,如果模型的泛化性能不够好,它可能会因为之前没有见过这种新的狗,而无法正确识别。这意味着它只是在记忆之前的样本,而不能将学到的知识应用到新情况中。
所以,更好的泛化性能意味着模型不仅仅可以记住已经见过的数据,还能够从中学到一些普遍的规律,从而在面对新数据时能够做出准确的预测或分类。
- 多领域应用的灵活性
大模型的另一个显著优势在于其多领域应用的灵活性。由于大模型具备跨领域的能力,一个训练有素的大模型可以用于多个任务和领域,而无需重新训练。这为开发人员节省了大量的时间和资源,同时也促进了模型的广泛应用。
举例来说,一个在自然语言处理领域预训练的大模型可以用于机器翻译、情感分析、问答等多个任务。同样,一个计算机视觉模型可以在图像分类、目标检测、图像合成等不同领域中发挥作用。这种多领域应用的灵活性使得大模型在满足多样化需求的同时,也促进了人工智能技术的快速迭代和创新。
04
大模型的应用及潜在商业模式

大模型是一种强大的机器学习工具,被广泛应用于各个领域,如智能助手、金融风险预测、医疗影像分析等,大模型的应用仍在不断拓展,为大家带来更多便利和创新。
- 自然语言处理和智能助手
大模型在自然语言处理领域的应用非常广泛,其中智能助手是一个突出的案例。公司如苹果的Siri、亚马逊的Alexa、谷歌的Google Assistant等都是基于大模型的智能助手。它们能够理解和回应人类的自然语言输入,提供语音识别、语义理解、对话生成等功能,为用户提供便捷的人机交互体验。
- 金融风险预测
大模型在金融领域的应用包括风险预测和投资决策。基于大规模金融数据,大模型能够分析市场趋势、预测股价波动、识别潜在的金融风险。一些金融机构和投资公司使用大模型来改善投资组合管理,优化风险控制策略,提高投资决策的准确性和效益。
- 医疗影像分析和诊断
医疗领域也广泛应用了大模型,特别是在医疗影像分析和诊断方面。大模型能够分析医学图像,如X射线、MRI和CT扫描,帮助医生检测疾病、识别肿瘤、预测疾病发展趋势等。这些应用有助于提高医疗诊断的准确性和效率,为医疗行业带来积极影响。
- 客户服务和自动化
大模型可以应用于客户服务领域,实现自动化的客户支持和问题解答。通过分析客户的问题,大模型能够生成准确的回复,提供即时帮助,减轻人工客服的负担。这可以提高客户满意度,同时降低企业的运营成本。
- 媒体和内容创作
大模型在媒体和内容创作领域也发挥着重要作用。它们可以自动生成新闻报道、文学作品、音乐、艺术品等创意内容,为媒体和创作者带来新的创作灵感。例如,有些媒体机构已经开始使用大模型来自动化新闻摘要和生成短文。又如Microsoft发布的Microsoft 365 Copilot,这是一款基于GPT-4和Microsoft Graph的AI办公助手,旨在提高工作效率和革新工作方式。它提供了一系列新功能,包括文字和图片内容生成、归纳、数据分析、辅助决策等。Copilot可以嵌入Microsoft 365应用程序中,如Word、Excel、PowerPoint、Outlook、Teams等,也可以通过邮件、联系人、在线会议等软件数据接入大语言模型。借助Power Platform中的Copilot,用户可以自动化重复的工作流程,解锁生产力。
- 零售和推荐系统
大模型在零售领域也被广泛应用,特别是在推荐系统中。基于用户的购买历史和兴趣,大模型可以为用户个性化地推荐产品和服务,提高购物体验,促进销售增长。
ChatGPT 开启了大模型的商业变现。当地时间2023年2月 1日,美国人工智能公司OpenAI推出ChatGPT付费订阅版 ChatGPT Plus,每月收费 20 美元。订阅者可在免费服务基础上获得:1)高峰时段免排队访问;2)更快的相应时间;3)优先使用新功能和优化等权益。2023年3月1日,OpenAI 官方宣布正式开放ChatGPT API。
OpenAI还通过付费开放API接口进行变现。目前OpenAI提供 DALL E、GPT 3、Codex、Content filter 的 API 接口,用于执行图像模型、语言模型,每种模型又细分为多种子模型型号,每种型号有不同的功能和价位。用户可以根据自身业务需求选择对应的模型,API接口根据模型类型、业务量等指标进行收费。图像模型根据图片分辨率的不同按张数收费,语言模型基于子模型型号按字符数收费,微调模型则包括训练和使用两部分的价格。
05
大模型对算力的需求

大模型对算力需求主要分为训练和推理两个主要方面。训练指利用大数据训练神经网络,通过大量数据确定网络中的权重和偏置的值,使其能够适应特定功能。推理指利用训练好的模型,使用新的数据推理和判断出各种结论。
在训练阶段(前期训练模型),假设训练30天,大约需要1,600颗英伟达的A100(单价1.5万美元/颗),硬件投入大约需要2,300万美元)。若后续使用达到接近谷歌的搜索频次(每天约35亿次搜索),在推理阶段,大约需要70万颗英伟达的A100,后续硬件投入约105亿美元。一颗英伟达的A100大约可以同时支持12.5万用户使用。
根据公开资料显示, GPT-3参数量达1750亿个,训练样本token数达3000亿个,其他计算假设参数如下:
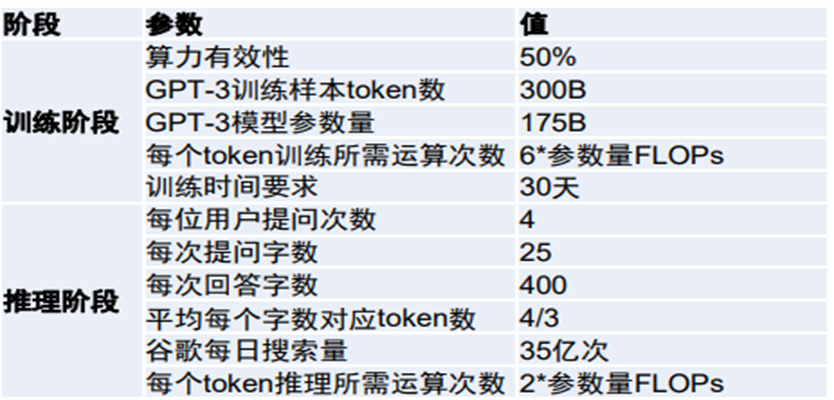
资料来源:国信证券
训练阶段算力需求如下:
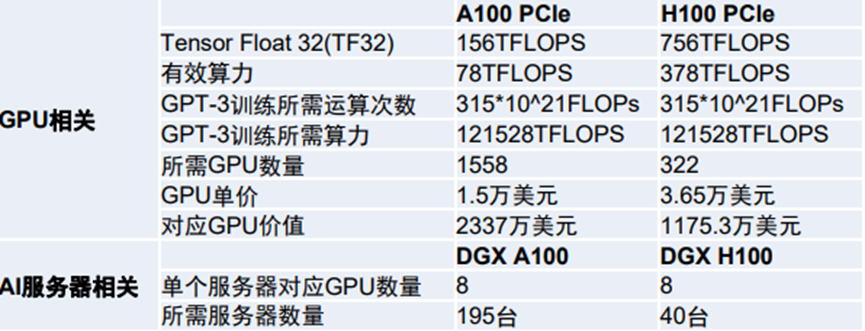
资料来源:国信证券
推理阶段算力需求如下:
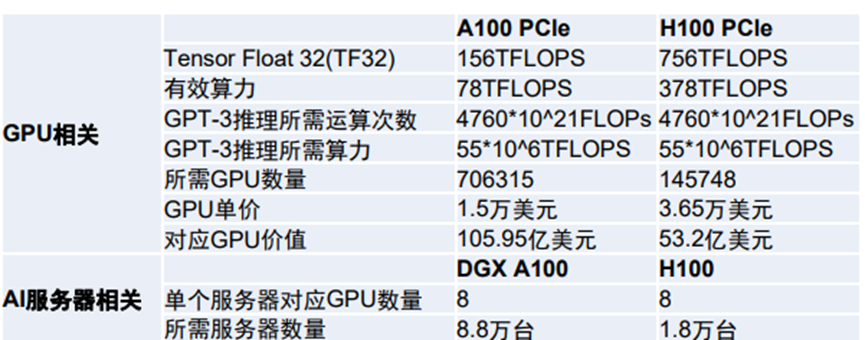
资料来源:国信证券
相关释义:
1.token:语言模型的最基本单位,将长文本分解为基本数据结构,再根据映射规则进行计算。
2.浮点数:一种计算机系统数字表示标准,指一个数的小数点的位置不是固定的,可以浮动,利用科学计数法来表示实数。常见浮点数根据精度不同分为双精度浮点数FP64、单精度浮点数FP32、半精度浮点数FP16等。
3.FLOPS(loating-point operations per second):每秒浮点运算次数,用于大量浮点运算的科学计算领域中。
4.TFLOPS(teraFLOPS):每秒1万亿(=10^12)次浮点运算
06
大模型的发展展望

自2020年起,中国已经进入大模型的快速发展阶段,并与美国保持了同步的增长趋势。在自然语言处理、机器视觉和多模态等众多技术领域,已经涌现出了具有重大行业影响的文心一言等大模型。从领域分布上,自然语言处理领域目前是大模型研发最活跃的部分,其次是多模态领域。相对来说,在计算机视觉和智能语音等领域的大模型数量较少。
随着数据集的扩大和计算能力的提升,未来大模型的规模将更加庞大,参数数量和计算复杂度都将达到新的高度。这将会带来更高的预测精度和更强大的推理能力。
未来的大模型也将更加个性化,能够根据用户的个人特征、行为和偏好进行定制化训练。这将使得大模型能够更好地满足用户的个性化需求,提高用户体验和工作效率。期待大模型被应用于更多的领域,与其他技术相结合,产生更多的创新应用。















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









