







1 简介
随着人类社会的进步,科学技术的发展日新月异.模拟人脑神经网络的人工神经网络已取得了长足的发展.经过半个多世纪的发展,人工神经网络在计算机科学,人工智能,智能控制等方面得到了广泛的应用. 当代社会是一个讲究效率的社会,科技更新领域也是如此.在人工神经网络研究领域,算法的优化显得尤为重要,对提高网络整体性能举足轻重.BP神经网络模型是目前应用最为广泛的一种神经网络模型,对于解决非线性复杂问题具有重要的意义.但是BP神经网络有其自身的一些不足(收敛速度慢和容易陷入局部极小值问题),在解决某些现实问题的时候显得力不从心.针对这个问题,本文利用遗传算法的并行全局搜索的优势,能够弥补BP网络的不足,为解决大规模复杂问题提供了广阔的前景.本文将鲸鱼算法与BP网络有机地结合起来,提出了一种新的网络结构,在稳定性,学习性和效率方面都有了很大的提高. 基于以上的研究目的,本文首先设计了BP神经网络结构,在此基础上,应用鲸鱼算法进行优化,达到了加快收敛速度和全局寻优的效果.本文借助MATLAB平台,对算法的优化内容进行了仿真实验,得出的效果也符合期望值,实现了对BP算法优化的目的.
2 部分代码
%_________________________________________________________________________%% Whale Optimization Algorithm (WOA) source codes demo 1.0 %% %% %%_________________________________________________________________________%% You can simply define your cost in a seperate file and load its handle to fobj% The initial parameters that you need are:%__________________________________________% fobj = @YourCostFunction% dim = number of your variables% Max_iteration = maximum number of generations% SearchAgents_no = number of search agents% lb=[lb1,lb2,...,lbn] where lbn is the lower bound of variable n% ub=[ub1,ub2,...,ubn] where ubn is the upper bound of variable n% If all the variables have equal lower bound you can just% define lb and ub as two single number numbers% To run ALO: [Best_score,Best_pos,cg_curve]=ALO(SearchAgents_no,Max_iteration,lb,ub,dim,fobj)% The Whale Optimization Algorithmfunction [Leader_score,Leader_pos,Convergence_curve]=WOA(SearchAgents_no,Max_iter,lb,ub,dim,fobj,handles,value)% initialize position vector and score for the leaderLeader_pos=zeros(1,dim);Leader_score=inf; %change this to -inf for maximization problems%Initialize the positions of search agentsPositions=initialization(SearchAgents_no,dim,ub,lb);Convergence_curve=zeros(1,Max_iter);t=0;% Loop counter% Main loopwhile t<Max_iterfor i=1:size(Positions,1)% Return back the search agents that go beyond the boundaries of the search spaceFlag4ub=Positions(i,:)>ub;Flag4lb=Positions(i,:)<lb;Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;% Calculate objective function for each search agentfitness=fobj(Positions(i,:));All_fitness(1,i)=fitness;% Update the leaderif fitness<Leader_score % Change this to > for maximization problemLeader_score=fitness; % Update alphaLeader_pos=Positions(i,:);endenda=2-t*((2)/Max_iter); % a decreases linearly fron 2 to 0 in Eq. (2.3)% a2 linearly dicreases from -1 to -2 to calculate t in Eq. (3.12)a2=-1+t*((-1)/Max_iter);% Update the Position of search agentsfor i=1:size(Positions,1)r1=rand(); % r1 is a random number in [0,1]r2=rand(); % r2 is a random number in [0,1]A=2*a*r1-a; % Eq. (2.3) in the paperC=2*r2; % Eq. (2.4) in the paperb=1; % parameters in Eq. (2.5)l=(a2-1)*rand+1; % parameters in Eq. (2.5)p = rand(); % p in Eq. (2.6)for j=1:size(Positions,2)if p<0.5if abs(A)>=1rand_leader_index = floor(SearchAgents_no*rand()+1);X_rand = Positions(rand_leader_index, :);D_X_rand=abs(C*X_rand(j)-Positions(i,j)); % Eq. (2.7)Positions(i,j)=X_rand(j)-A*D_X_rand; % Eq. (2.8)elseif abs(A)<1D_Leader=abs(C*Leader_pos(j)-Positions(i,j)); % Eq. (2.1)Positions(i,j)=Leader_pos(j)-A*D_Leader; % Eq. (2.2)endelseif p>=0.5distance2Leader=abs(Leader_pos(j)-Positions(i,j));% Eq. (2.5)Positions(i,j)=distance2Leader*exp(b.*l).*cos(l.*2*pi)+Leader_pos(j);endendendt=t+1;Convergence_curve(t)=Leader_score;if t>2line([t-1 t], [Convergence_curve(t-1) Convergence_curve(t)],'Color','b')xlabel('Iteration');ylabel('Best score obtained so far');drawnowendset(handles.itertext,'String', ['The current iteration is ', num2str(t)])set(handles.optimumtext,'String', ['The current optimal value is ', num2str(Leader_score)])if value==1hold onscatter(t*ones(1,SearchAgents_no),All_fitness,'.','k')endend
3 仿真结果
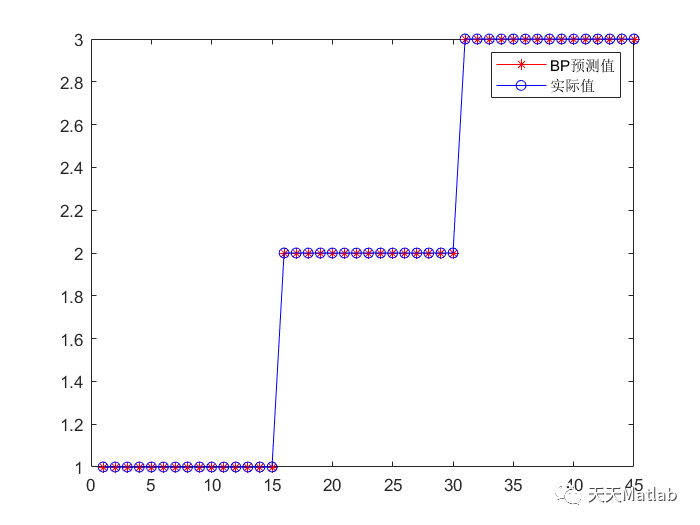
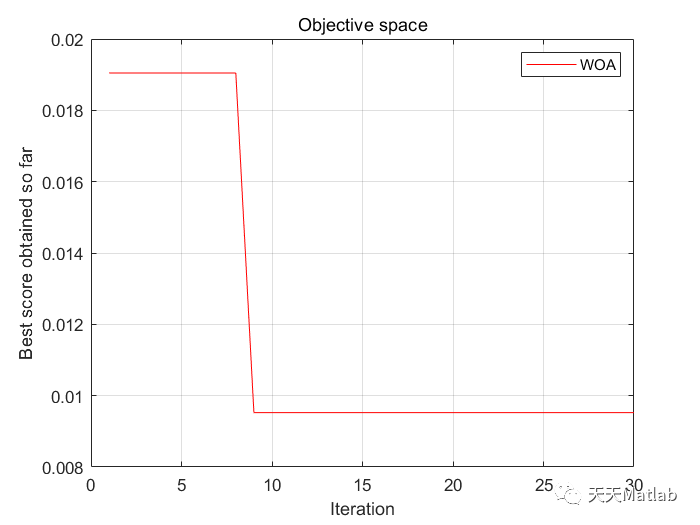
4 参考文献
[1]任谢楠. 基于遗传算法的BP神经网络的优化研究及MATLAB仿真[D]. 天津师范大学, 2014.
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











