







1 内容介绍
灰狼优化(GWO)算法是一种新兴的算法,它基于灰狼的社会等级以及它们的狩猎和合作策略。 该算法于 2014 年推出,已被大量研究人员和设计人员使用,原始论文的引用次数超过了许多其他算法。 在 Niu 等人最近的一项研究中,介绍了该算法优化现实问题的主要缺点之一。 总之,他们表明,随着问题的最优解偏离 0,GWO 的性能会下降。在本文中,通过对原始 GWO 算法进行直接修改,即忽略其社会等级,作者能够在很大程度上消除 这一缺陷为今后使用该算法开辟了新的视角。 通过将其应用于基准和实际工程问题,验证了所提出方法的有效性。

2 仿真代码
clc
clear
global NFE
NFE=0;
nPop=30; % Number of search agents (Population Number)
MaxIt=1000; % Maximum number of iterations
nVar=30; % Number of Optimization Variables
nFun=1; % Function No, select any integer number from 1 to 14
CostFunction=@(x,nFun) Cost(x,nFun); % Cost Function
%% Problem Definition
VarMin=-100; % Decision Variables Lower Bound
if nFun==7
VarMin=-600; % Decision Variables Lower Bound
end
if nFun==8
VarMin=-32; % Decision Variables Lower Bound
end
if nFun==9
VarMin=-5; % Decision Variables Lower Bound
end
if nFun==10
VarMin=-5; % Decision Variables Lower Bound
end
if nFun==11
VarMin=-0.5; % Decision Variables Lower Bound
end
if nFun==12
VarMin=-pi; % Decision Variables Lower Bound
end
if nFun==14
VarMin=-100; % Decision Variables Lower Bound
end
VarMax= -VarMin; % Decision Variables Upper Bound
if nFun==13
VarMin=-3; % Decision Variables Lower Bound
VarMax= 1; % Decision Variables Upper Bound
end
%% Grey Wold Optimizer (GWO)
% Initialize Alpha, Beta, and Delta
Alpha_pos=zeros(1,nVar);
Alpha_score=inf;
Beta_pos=zeros(1,nVar);
Beta_score=inf;
Delta_pos=zeros(1,nVar);
Delta_score=inf;
%Initialize the positions of search agents
Positions=rand(nPop,nVar).*(VarMax-VarMin)+VarMin;
BestCosts=zeros(1,MaxIt);
fitness=nan(1,nPop);
iter=0; % Loop counter
%% Main loop
while iter<MaxIt
for i=1:nPop
% Return back the search agents that go beyond the boundaries of the search space
Flag4ub=Positions(i,:)>VarMax;
Flag4lb=Positions(i,:)<VarMin;
Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+VarMax.*Flag4ub+VarMin.*Flag4lb;
% Calculate objective function for each search agent
fitness(i)= CostFunction(Positions(i,:), nFun);
% Update Alpha, Beta, and Delta
if fitness(i)<Alpha_score
Alpha_score=fitness(i); % Update Alpha
Alpha_pos=Positions(i,:);
end
if fitness(i)>Alpha_score && fitness(i)<Beta_score
Beta_score=fitness(i); % Update Beta
Beta_pos=Positions(i,:);
end
if fitness(i)>Alpha_score && fitness(i)>Beta_score && fitness(i)<Delta_score
Delta_score=fitness(i); % Update Delta
Delta_pos=Positions(i,:);
end
end
a=2-(iter*((2)/MaxIt)); % a decreases linearly fron 2 to 0
% Update the Position of all search agents
for i=1:nPop
for j=1:nVar
r1=rand;
r2=rand;
A1=2*a*r1-a;
C1=2*r2;
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j));
X1=Alpha_pos(j)-A1*D_alpha;
r1=rand;
r2=rand;
A2=2*a*r1-a;
C2=2*r2;
D_beta=abs(C2*Beta_pos(j)-Positions(i,j));
X2=Beta_pos(j)-A2*D_beta;
r1=rand;
r2=rand;
A3=2*a*r1-a;
C3=2*r2;
D_delta=abs(C3*Delta_pos(j)-Positions(i,j));
X3=Delta_pos(j)-A3*D_delta;
Positions(i,j)=(X1+X2+X3)/3;
end
end
iter=iter+1;
BestCosts(iter)=Alpha_score;
fprintf('Iter= %g, NFE= %g, Best Cost = %g\n',iter,NFE,Alpha_score);
end
1 内容介绍
灰狼优化(GWO)算法是一种新兴的算法,它基于灰狼的社会等级以及它们的狩猎和合作策略。 该算法于 2014 年推出,已被大量研究人员和设计人员使用,原始论文的引用次数超过了许多其他算法。 在 Niu 等人最近的一项研究中,介绍了该算法优化现实问题的主要缺点之一。 总之,他们表明,随着问题的最优解偏离 0,GWO 的性能会下降。在本文中,通过对原始 GWO 算法进行直接修改,即忽略其社会等级,作者能够在很大程度上消除 这一缺陷为今后使用该算法开辟了新的视角。 通过将其应用于基准和实际工程问题,验证了所提出方法的有效性。
2 仿真代码
clc
clear
global NFE
NFE=0;
nPop=30; % Number of search agents (Population Number)
MaxIt=1000; % Maximum number of iterations
nVar=30; % Number of Optimization Variables
nFun=1; % Function No, select any integer number from 1 to 14
CostFunction=@(x,nFun) Cost(x,nFun); % Cost Function
%% Problem Definition
VarMin=-100; % Decision Variables Lower Bound
if nFun==7
VarMin=-600; % Decision Variables Lower Bound
end
if nFun==8
VarMin=-32; % Decision Variables Lower Bound
end
if nFun==9
VarMin=-5; % Decision Variables Lower Bound
end
if nFun==10
VarMin=-5; % Decision Variables Lower Bound
end
if nFun==11
VarMin=-0.5; % Decision Variables Lower Bound
end
if nFun==12
VarMin=-pi; % Decision Variables Lower Bound
end
if nFun==14
VarMin=-100; % Decision Variables Lower Bound
end
VarMax= -VarMin; % Decision Variables Upper Bound
if nFun==13
VarMin=-3; % Decision Variables Lower Bound
VarMax= 1; % Decision Variables Upper Bound
end
%% Grey Wold Optimizer (GWO)
% Initialize Alpha, Beta, and Delta
Alpha_pos=zeros(1,nVar);
Alpha_score=inf;
Beta_pos=zeros(1,nVar);
Beta_score=inf;
Delta_pos=zeros(1,nVar);
Delta_score=inf;
%Initialize the positions of search agents
Positions=rand(nPop,nVar).*(VarMax-VarMin)+VarMin;
BestCosts=zeros(1,MaxIt);
fitness=nan(1,nPop);
iter=0; % Loop counter
%% Main loop
while iter<MaxIt
for i=1:nPop
% Return back the search agents that go beyond the boundaries of the search space
Flag4ub=Positions(i,:)>VarMax;
Flag4lb=Positions(i,:)<VarMin;
Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+VarMax.*Flag4ub+VarMin.*Flag4lb;
% Calculate objective function for each search agent
fitness(i)= CostFunction(Positions(i,:), nFun);
% Update Alpha, Beta, and Delta
if fitness(i)<Alpha_score
Alpha_score=fitness(i); % Update Alpha
Alpha_pos=Positions(i,:);
end
if fitness(i)>Alpha_score && fitness(i)<Beta_score
Beta_score=fitness(i); % Update Beta
Beta_pos=Positions(i,:);
end
if fitness(i)>Alpha_score && fitness(i)>Beta_score && fitness(i)<Delta_score
Delta_score=fitness(i); % Update Delta
Delta_pos=Positions(i,:);
end
end
a=2-(iter*((2)/MaxIt)); % a decreases linearly fron 2 to 0
% Update the Position of all search agents
for i=1:nPop
for j=1:nVar
r1=rand;
r2=rand;
A1=2*a*r1-a;
C1=2*r2;
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j));
X1=Alpha_pos(j)-A1*D_alpha;
r1=rand;
r2=rand;
A2=2*a*r1-a;
C2=2*r2;
D_beta=abs(C2*Beta_pos(j)-Positions(i,j));
X2=Beta_pos(j)-A2*D_beta;
r1=rand;
r2=rand;
A3=2*a*r1-a;
C3=2*r2;
D_delta=abs(C3*Delta_pos(j)-Positions(i,j));
X3=Delta_pos(j)-A3*D_delta;
Positions(i,j)=(X1+X2+X3)/3;
end
end
iter=iter+1;
BestCosts(iter)=Alpha_score;
fprintf('Iter= %g, NFE= %g, Best Cost = %g\n',iter,NFE,Alpha_score);
end
3 运行结果
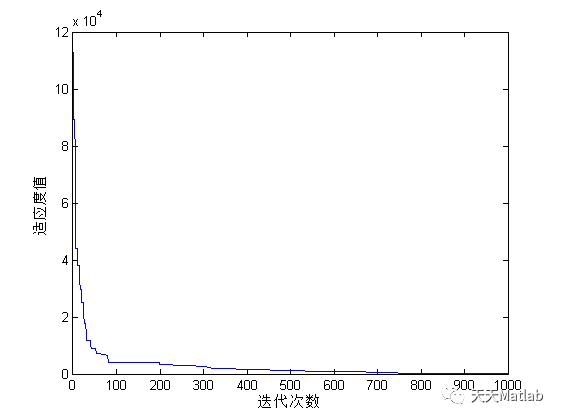
4 参考文献
[1]高珊. 基于贪婪随机自适应灰狼优化算法求解TSP的研究与应用[D]. 太原理工大学.
[2]龙文, 赵东泉, 徐松金. 求解约束优化问题的改进灰狼优化算法[J]. 计算机应用, 2015, 35(009):2590-2595.
[3]姜天华. 混合灰狼优化算法求解柔性作业车间调度问题[J]. 控制与决策, 2018, 33(3):6.
[4] Akbari E , Rahimnejad A , Gadsden S A . A greedy non﹉ierarchical grey wolf optimizer for real﹚orld optimization[J]. Electronics Letters, 2021(1).
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。
3 运行结果
4 参考文献
[1]高珊. 基于贪婪随机自适应灰狼优化算法求解TSP的研究与应用[D]. 太原理工大学.
[2]龙文, 赵东泉, 徐松金. 求解约束优化问题的改进灰狼优化算法[J]. 计算机应用, 2015, 35(009):2590-2595.
[3]姜天华. 混合灰狼优化算法求解柔性作业车间调度问题[J]. 控制与决策, 2018, 33(3):6.
[4] Akbari E , Rahimnejad A , Gadsden S A . A greedy non﹉ierarchical grey wolf optimizer for real﹚orld optimization[J]. Electronics Letters, 2021(1).
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











