







 本文详细介绍了MATLAB中的判别分析,包括距离判别和贝叶斯判别。距离判别主要讨论了马氏距离及其应用,通过classify函数实现。贝叶斯判别利用NaiveBayes类,通过fit和predict方法进行分类。文中给出了多个示例来解释判别过程,并展示了误判率和混淆矩阵的计算。
本文详细介绍了MATLAB中的判别分析,包括距离判别和贝叶斯判别。距离判别主要讨论了马氏距离及其应用,通过classify函数实现。贝叶斯判别利用NaiveBayes类,通过fit和predict方法进行分类。文中给出了多个示例来解释判别过程,并展示了误判率和混淆矩阵的计算。
更多MATLAB数据分析视频请点击,或者在网易云课堂上搜索《MATLAB数据分析与统计》 http://study.163.com/course/courseMain.htm?courseId=1003615016
更多MATLAB数据分析视频请点击,或者在网易云课堂上搜索《MATLAB数据分析与统计》 http://study.163.com/course/courseMain.htm?courseId=1003615016
判别分析是对未知类别的样本进行归类的一种方法。虽然也是对样品进行分类,但它与聚类分析还是不同的。聚类分析的研究对象还没有分类,就是要根据抽样的样本进行分类,而判别分析的研究对象已经有了分类,只是根据抽样的样本建立判别公式和判别准则,然后根据这些判别公式和判别准则,判别未知类别的样品所属的类别。
判别分析有着非常广泛的应用,比如在考古学上,根据出土物品判别墓葬年代,墓主人身份,性别;在医学上,根据患者的临床症状和化验结果判断患者疾病的类型;在经济上,根据各项经济发展指标判断一个国家经济发展水平所属的类型;在模式识别领域,用来进行文字识别,语音识别,指纹识别等。
我们这章的主要内容是距离判别和贝叶斯判别
1.距离判别
1.1 马氏距离(Mahalanobis距离)
马氏距离(Mahalanobis distance)是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。对于一个均值为μ,协方差矩阵为Σ的多变量向量,其马氏距离为sqrt( (x-μ)'Σ^(-1)(x-μ) )。
定义x,y之间的平方马氏距离为
d^2(x,y)=(x-y)'Σ^(-1)(x-y)
定义x到总体G的平方马氏距离为
d^2(x,G)=(x-μ)'Σ^(-1)(x-μ)
1.2 两总体距离判别
设有两个p维总体G1和G2,分布的均值向量分布为u1,u2,协方差矩阵分别为Σ1>0,Σ2>0。现有一未知类别的样本x,试判断x的归属
如果 d^2(x,G1)<d^2(x,G2),则x属于G1类
如果 d^2(x,G1)>d^2(x,G2), 则x属于G2类
d^2(x,G1) = d^2(x,G2),待判
1.3距离判别法的MATLAB实现
MATLAB统计工具箱中提供了classify函数,用来对未知类别的样品进行判别,可以进行距离判别和先验分布为正态分布的贝叶斯判别。调用格式如下:
<1> class=classify(sample,training,group)
将sample中的每一个观测归入training中观测所在的某个组。输入参数sample是待判别的样本数据矩阵,training是用于构成判别函数的训练样本数据矩阵,他们的每一行对应一个观测,每一列对应一个变量,sample和training具有相同的列数。参数group是与training相应的分组变量,group和training具有相同的行数,group中的每一个元素指定了training中相应观测所在的组。group可以是一个分类变量、数值向量、字符串数组或字符串元胞数组。输出参数class是一个列向量,用来指定sample中个观测所在的组,class与group具有相同的数据类型。
classify函数把group中的NaN或空字符串作为数据缺失数据,从而忽略training中相应的观测。
<2>class=classify(sample,training,group,type)
可以通过type参数指定判别函数的类型,type的可能取值如下表:
| type参数的可能取值 |
说明 |
| ‘linear’ |
线性判别函数(默认情况) |
| ‘diaglinear’ |
与‘linear’类似,此时用一个对角矩阵作为协方差矩阵的估计 |
| ‘quadratic’ |
二次判别函数 |
| ‘diagquadratic’ |
与‘quadratic’类似,此时用对角矩阵作为各个协方差矩阵的估计 |
| ‘mahalanobis’ |
各组的协方差矩阵不全相等并未知时的距离,此时分别得出各组的协方差矩阵的估计 |
<3>class=classify(sample,training,group,type,proir)
可以通过prior参数指定各组的先验概率,默认情况下,各组先验概率相等。
<4>[class,err]=classify(........)
返回基于training数据的误判概率的估计值
1.4 距离判别的例子
对21个破产的企业收集他们在破产前两年的年度财务数据,同时对25个财务良好的企业也收集同一时期的数据。数据涉及4个变量
x1=现金流量/总债务
x2=净收入/总资产
x3=流动资产/流动债务
x4=流动资产/净销售额
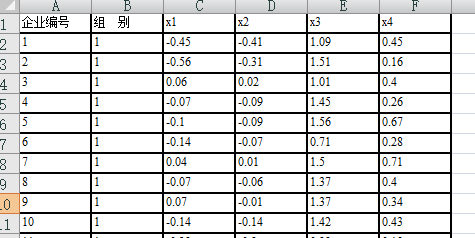
数据中,1组为破产企业,2组为非破产企业。现有4个未判企业,他们的相关数据位于表中的最后4行,根据距离判决法,对这4个未判企业进行判别。
%读取数据
%读取C2:F51范围的数据,即全部样本数据
sample = xlsread('企业.xls','C2:F51');
%读取C2:F47范围的数据,即已知组别的样本数据
training = xlsread('企业.xls','C2:F47');
%读取B2:B47范围的数据,即样本的分组信息
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6884
6884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











