







1. 摘要
本文研究了深度卷积神经网络的结构,通过以单个 RGB 图像作为输入来预测前景 alpha 遮罩。我们的网络是具有两个解码器分支的全卷积网络,分别用于前景和背景分类。然后,使用融合分支对两个分类结果进行融合,这将产生 alpha 值作为软分割结果。与网络中的单个解码器分支相比,此设计提供了更大的自由度,以便在训练过程中获得更好的 alpha 值。该网络无需用户交互即可隐式生成 trimap,这对于没有数字遮罩专业知识的新手来说很容易使用。实验结果表明,我们的网络可以为各种类型的对象实现高质量的 alpha 遮罩,并且在人类图像遮罩任务上优于基于 CNN 的最新图像遮罩方法。
论文地址:A Late Fusion CNN for Digital Matting
训练与部署代码:https://download.csdn.net/download/matt45m/89009389

2. 相关工作
在这个部分,我们简要回顾了三种主要的数字抠图方法:基于采样的方法、基于类的方法以及基于深度学习的方法。基于采样的方法使用颜色信息来推断图片中过渡区域每个像素的 alpha 值。这类方法的关键是要(1)收集采样的像素,(2)建立前景与背景的颜色模型。这类方法利用自然图像的统计信息来解决一些抠图问题,并且当 trimap 标记的很好时,该方法能够取得较好的结果。基于类的方法已被证明效果比基于采样的方法更好。而要取得更好的 alpha 值结果,就要定义一个恰当的亲和力分数。全局优化策略,如频谱技术,是二进制优化技术的连续松弛,不能保证获取的最优解。基于深度学习的抠图方法直接从大量标注的数据中学习了一种输入图像到 alpha 的映射。随后作者介绍了一些其他作者的贡献,并指出他们的优缺点。
3. 本文方法
在这个部分,将介绍我们提出的方法细节。3.1 是方法总览,3.2 和 3.3 详细描述了模型结构和分割网络与融合网络的训练损失,3.4 给出了网络的训练细节。
3.1 方法概述
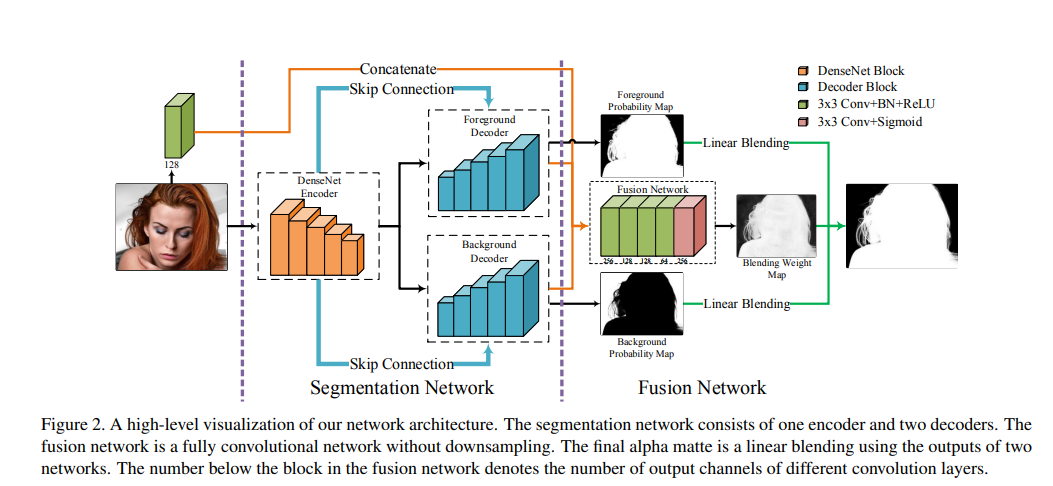
我们提出了一个新颖的端到端神经网络,其输入为包含前景的图像,输出为前景的 alpha 遮罩。如图2所示,我们的方法核心是利用神经网络来预测三个图像:前景概率图、背景概率图和混合权重图。输出的 alpha 遮罩是根据混合权重图将前景概率图与背景概率图进行融合得到的。网络包括三个需要连续训练的部分:分割网络的预训练步骤、融合网络的预训练步骤以及最终的端到端联合训练步骤,其训练损失被加在输出的 alpha 遮罩上。
我们将尝试通过下面的统合方程来预测alpha:
α
p
=
β
p
F
‾
p
+
(
1
−
β
p
)
(
1
−
B
‾
p
)
,
(
2
)
\alpha_{p}=\beta_{p} \overline{\mathbf{F}}_{p}+(1-\beta_{p})(1-\overline{\mathbf{B}}_{p}),\qquad(2)
αp=βpFp+(1−βp)(1−Bp),(2)
在我们的实现中,( F_p ) 和 ( B_p ) 分别代表某像素预测的前景与背景概率,( \beta_p ) 为融合网络预测的混合权重。融合网络将输入图像和特征作为预测前景和背景分类分支的逻辑回归之前的输入。
从优化的角度来看,当满足以下等式时,( \alpha_p ) 关于 ( \beta_p ) 的导数将消失:
B
‾
p
+
F
‾
p
=
1.
(
3
)
\overline{\mathrm{B}}_{p}+\overline{\mathrm{F}}_{p}=1.\qquad(3)
Bp+Fp=1.(3)
首先,如果前景/背景概率图的预测准确(即满足等式3),则融合网络将专注于学习从前景到背景的过渡区域,这是解决消光问题的瓶颈。其次,我们可以仔细设计损失函数,以鼓励过渡区域内的 ( F_p + B_p \neq 1 )(请参见第3.2节),这可以提供有用的梯度来训练融合网络。
3.2 分割网络
我们继续描述分割网络的结构以及其训练损失。特别地,训练损失有利于实心前景和背景区域的概率为0或1。它还尝试预测过渡区域中真实 Alpha 值的上限和下限。
网络结构:分割网络由一个编码器和两个解码器组成。编码器从输入图像中提取语义特征。这两个解码器共享相同的编码结果,并分别预测前景和背景概率图。具体来说,我们使用了没有全连接层头的 DenseNet-201 作为编码器。每个分支由与五个编码器块相对应的五个解码器块组成,并且解码器块遵循特征金字塔网络结构的设计。为了增强像素级分割的结果,我们采用了跳跃连接,将编码器块中的多尺度特征(在平均下采样之前)与通过反卷积层上采样的特征连接起来。
训练损失:训练损失包括 L1 损失、L2 损失和交叉熵损失。特别地,我们通过根据 alpha 遮罩为不同的像素设置不同的权重来控制网络训练过程的行为。
我们首先测量预测概率值和真实值之间的差异:
L
d
(
F
‾
p
)
=
{
∣
F
‾
p
−
α
p
∣
,
0
<
α
p
<
1.
(
F
‾
p
−
α
p
)
2
,
α
p
=
0
,
1.
(
4
)
L_{d}(\overline{F}_{p})=\left\{\begin{array}{l l}{{|\overline{\mathrm{F}}_{p}-\alpha_{p}|,}}&{{0\lt \alpha_{p}\lt 1.}}\\ {{(\overline{\mathrm{F}}_{p}-\alpha_{p})^{2},}}&{{\alpha_{p}=0,1.}}\end{array}\right.\qquad(4)
Ld(Fp)={∣Fp−αp∣,(Fp−αp)2,0<αp<1.αp=0,1.(4)
差异选择为过渡区域内的 L1 损失,以便在那里恢复 alpha 遮罩的细节,而其余区域使用 L2 损失来惩罚可能的分割误差。我们发现此设置可以很好地在软细分和硬细分之间取得平衡。
我们还将 L1 损失引入预测的 alpha 遮罩的梯度上,因为在分类后去除过度模糊的 alpha 遮罩是有益的:
L
g
(
F
‾
p
)
=
∣
∇
x
(
F
‾
p
)
−
∇
x
(
α
p
)
∣
+
∣
∇
y
(
F
‾
p
)
−
∇
y
(
α
p
)
∣
.
(
5
)
{\cal L}_{g}(\overline{\mathbf{F}}_{p})=|\nabla_{x}(\overline{\mathbf{F}}_{p})-\nabla_{x}(\alpha_{p})|+|\nabla_{y}(\overline{\mathbf{F}}_{p})-\nabla_{y}(\alpha_{p})|.\qquad(5)
Lg(Fp)=∣∇x(Fp)−∇x(αp)∣+∣∇y(Fp)−∇y(αp)∣.(5)
前景分类分支在像素p处的交叉熵(CE)损失由下式给出:
C
E
(
F
‾
p
)
=
w
p
⋅
(
−
α
^
p
log
(
F
‾
p
)
−
(
1
−
α
^
p
)
log
(
1
−
F
‾
p
)
)
,
(
6
)
CE(\overline{\bf F}_{p})=w_{p}\cdot(-\hat{\alpha}_{p}\log(\overline{\bf F}_{p})-(1-\hat{\alpha}_{p})\log(1-\overline{\bf F}_{p})),\qquad(6)
CE(Fp)=wp⋅(−α^plog(Fp)−(1−α^p)log(1−Fp)),(6)
损失函数如下所示:
L
F
=
∑
p
C
E
(
F
ˉ
p
)
+
L
d
(
F
ˉ
p
)
+
L
g
(
F
ˉ
p
)
.
(
7
)
{\cal L}_{F}=\sum_{p}C E(\bar{\bf F}_{p})+L_{d}(\bar{\bf F}_{p})+L_{g}(\bar{\bf F}_{p}).\qquad(7)
LF=p∑CE(Fˉp)+Ld(Fˉp)+Lg(Fˉp).(7)
注意,交叉熵和过渡区域内部的 L1 损失的组合试图提供比真实值更大的概率,因为交叉熵损失会将概率拖至 1。因此,可以将真实的 alpha 值放在方括号中。由于等式中的 (1 - B_p),由两个分支预测的两个概率形成的区间。 (2) 应该小于我们设置中的 (p)。 这种设计使我们能够在应用融合网络后对精确的 alpha 值进行回归。
此外,以不同的损失来训练前景和背景分割分支有助于学习输入图像的不同特征。这些特征有益于整体学习的结果。如图3和图4所示,分段损失的这种设计确实导致了有意义的隐式三映射的生成。此外,介于 0 和 1 之间的 alpha 值大多由两个预测的概率括起来。
代码实现:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import tensorflow as tf
import keras
from keras import backend as K
from keras.models import Model
from keras.layers import Activation
from keras.layers import AveragePooling2D
from keras.layers import Add
from keras.layers import UpSampling2D
from keras.layers import Lambda
#from keras.layers import BatchNormalization
from util import BatchNorm, BilinearUpsampling
from keras.layers import Concatenate
from keras.layers import Conv2D
from keras.layers import Dense
from keras.layers import GlobalAveragePooling2D
from keras.layers import Input
from keras.layers import MaxPooling2D
from keras.layers import ZeroPadding2D
def dense_block(x, blocks, name, train_bn):
"""A dense block.
# Arguments
x: input tensor.
blocks: integer, the number of building blocks.
name: string, block label.
# Returns
output tensor for the block.
"""
for i in range(blocks):
x = conv_block(x, 32, name=name + '_block' + str(i + 1), train_bn=train_bn)
return x
def transition_block(x, reduction, name, train_bn):
"""A transition block.
# Arguments
x: input tensor.
reduction: float, compression rate at transition layers.
name: string, block label.
# Returns
output tensor for the block.
"""
bn_axis = 3 if K.image_data_format() == 'channels_last' else 1
x = BatchNorm(axis=bn_axis, epsilon=1.001e-5,
name=name + '_bn')(x, training=train_bn)
x = Activation('relu', name=name + '_relu')(x)
skip = x = Conv2D(int(K.int_shape(x)[bn_axis] * reduction), 1, use_bias=False,
name=name + '_conv')(x)
x = AveragePooling2D(2, strides=2, name=name + '_pool')(x)
return skip, x
def conv_block(x, growth_rate, name, train_bn):
"""A building block for a dense block.
# Arguments
x: input tensor.
growth_rate: float, growth rate at dense layers.
name: string, block label.
# Returns
output tensor for the block.
"""
bn_axis = 3 if K.image_data_format() == 'channels_last' else 1
x1 = BatchNorm(axis=bn_axis, epsilon=1.001e-5,
name=name + '_0_bn')(x, training=train_bn)
x1 = Activation('relu', name=name + '_0_relu')(x1)
x1 = Conv2D(4 * growth_rate, 1, use_bias=False,
name=name + '_1_conv')(x1)
x1 = BatchNorm(axis=bn_axis, epsilon=1.001e-5,
name=name + '_1_bn')(x1, training=train_bn)
x1 = Activation('relu', name=name + '_1_relu')(x1)
x1 = Lambda(lambda x: tf.pad(x, [[0,0],[1,1],[1,1],[0,0]], mode='SYMMETRIC'))(x1)
x1 = Conv2D(growth_rate, 3, padding='valid', use_bias=False,
name=name + '_2_conv')(x1)
x = Concatenate(axis=bn_axis, name=name + '_concat')([x, x1])
return x
def DenseNet_encoder(blocks,
input_tensor,
pooling=None,
train_bn=False):
"""Instantiates the DenseNet architecture."""
bn_axis = 3 if K.image_data_format() == 'channels_last' else 1
# x = ZeroPadding2D(padding=((3, 3), (3, 3)))(input_tensor)
x = Lambda(lambda x: tf.pad(x, [[0,0],[3,3],[3,3],[0,0]], mode='SYMMETRIC'))(input_tensor)
x = Conv2D(64, 7, strides=2, use_bias=False, name='conv1/conv')(x)
x = BatchNorm(axis=bn_axis, epsilon=1.001e-5,
name='conv1/bn', )(x, training=train_bn)
R1 = x = Activation('relu', name='conv1/relu')(x)
x = ZeroPadding2D(padding=((1, 1), (1, 1)))(x)
x = MaxPooling2D(3, strides=2, name='pool1')(x)
R2 = x = dense_block(x, blocks[0], name='conv2', train_bn=train_bn)
_, x = transition_block(x, 0.5, name='pool2', train_bn=train_bn)
R3 = x = dense_block(x, blocks[1], name='conv3', train_bn=train_bn)
_, x = transition_block(x, 0.5, name='pool3', train_bn=train_bn)
R4 = x = dense_block(x, blocks[2], name='conv4', train_bn=train_bn)
_, x = transition_block(x, 0.5, name='pool4', train_bn=train_bn)
x = dense_block(x, blocks[3], name='conv5', train_bn=train_bn)
x = BatchNorm(axis=bn_axis, epsilon=1.001e-5,
name='bn')(x, training=train_bn)
if pooling == 'avg':
x = AveragePooling2D(7, name='avg_pool')(x)
elif pooling == 'max':
x = MaxPooling2D(7, name='max_pool')(x)
return [R1, R2, R3, R4], x
def fpn_side_output_block(deconv_input, upsample_input, block_name,
network_name, train_bn, use_bias, output_shape,
up_output=True, out_output=True, d=128):
prefix = network_name + '_side_' + block_name
if deconv_input.shape[3] == d:
x = deconv_input
else:
x = Conv2D(d, (1, 1), strides=(1, 1), padding='same',
name=prefix + '_conv1', use_bias=use_bias)(deconv_input)
if upsample_input != None:
x = Add(name=prefix+'_add')([x, upsample_input])
x = Lambda(lambda x: tf.pad(x, [[0,0],[1,1],[1,1],[0,0]], mode='SYMMETRIC'))(x)
add = x = Conv2D(d, (3, 3), padding='valid',
name=prefix+'_conv2', use_bias=use_bias)(x)
else:
add = None
if out_output:
out = Conv2D(1, (1, 1), strides=(1, 1), padding='same',
name=prefix + '_conv3', use_bias=use_bias)(x)
out = Activation('sigmoid', name=prefix+'_sigmoid')(out)
out = BilinearUpsampling(output_size=(output_shape[0], output_shape[1]),
name=prefix+'_out')(out)
else:
out = None
if up_output:
up = UpSampling2D(data_format=K.image_data_format(),
name=prefix+'_up')(x)
else:
up = None
return add, up, out
def deconv_block(x, skip, network_name, fpn_d, train_bn):
bn_axis = 3 if K.image_data_format() == 'channels_last' else 1
x = UpSampling2D(2, data_format=K.image_data_format())(x)
if not skip is None:
channel = K.int_shape(skip)[bn_axis]
channel = fpn_d if channel < fpn_d else channel
#x = Conv2D(channel, (1, 1), name=network_name+'_conv',
#padding='same', use_bias=False)(x)
#x = Add(name=network_name+'_add')([x, skip])
x = Concatenate(axis=bn_axis)([x, skip])
x = Conv2D(channel, (1, 1), name=network_name+'_conv',
padding='same', use_bias=False)(x)
else:
channel = K.int_shape(x)[bn_axis]
channel = fpn_d if channel < fpn_d else channel
x = Conv2D(channel, (1, 1), name=network_name+'_conv', use_bias=False)(x)
x = BatchNorm(axis=bn_axis, epsilon=1.001e-5,
name=network_name+'_bn')(x, training=train_bn)
x = Activation('relu', name=network_name+'_relu')(x)
return x
def DenseNet_decoder(input_tensor,
skip_connection,
network_name,
output_dim,
fpn_d,
train_bn=False):
"""Instantiates the DenseNet architecture. (decoder part) """
bn_axis = 3 if K.image_data_format() == 'channels_last' else 1
R1, R2, R3, R4 = skip_connection
DC4 = x = deconv_block(input_tensor, R4, fpn_d=fpn_d,
network_name=network_name+'_deconv5', train_bn=train_bn)
DC3 = x = deconv_block(x, R3, fpn_d=fpn_d,
network_name=network_name+'_deconv4', train_bn=train_bn)
DC2 = x = deconv_block(x, R2, fpn_d=fpn_d,
network_name=network_name+'_deconv3', train_bn=train_bn)
DC1 = x = deconv_block(x, R1, fpn_d=fpn_d,
network_name=network_name+'_deconv2', train_bn=train_bn)
# We should get 256*256*64 at DC1
x = deconv_block(x, None, network_name=network_name+'_deconv1', fpn_d=fpn_d, train_bn=train_bn)
# FPN
up4 = Conv2D(fpn_d, (1, 1), padding='same', name=network_name+'_up4_conv', use_bias=True)(DC4)
up4 = Activation('relu', name=network_name+'_up4_relu')(up4)
up4 = UpSampling2D(data_format=K.image_data_format(), name=network_name+'_up4_up')(up4)
[_, up3, out_8] = fpn_side_output_block(DC3, up4, block_name='3', output_shape=output_dim,
network_name=network_name, d=fpn_d,
train_bn=train_bn, use_bias=True)
[_, up2, out_4] = fpn_side_output_block(DC2, up3, block_name='2', output_shape=output_dim,
network_name=network_name, d=fpn_d,
train_bn=train_bn, use_bias=True)
[_, up1, out_2] = fpn_side_output_block(DC1, up2, block_name='1', output_shape=output_dim,
network_name=network_name, d=fpn_d,
train_bn=train_bn, use_bias=True)
[add0, _, out] = fpn_side_output_block(x, up1, block_name='0', up_output=False, d=fpn_d,
network_name=network_name, output_shape=output_dim,
train_bn=train_bn, use_bias=True)
return [out, out_2, out_4, out_8, add0]
if __name__ == '__main__':
image_shape = [512, 512, 3]
input_image = keras.layers.Input(shape=image_shape, name="input_image")
skip_connections, bottleneck = DenseNet_encoder([6, 12, 48, 32], input_image)
model = Model(input_image, bottleneck)
model.summary()
print(skip_connections, bottleneck)
3.3 融合网络
融合网络的目标是在像素级别输出 β p \beta_{p} βp以融合前景和背景分类结果。
网络结构:融合网络是一个具有五层卷积层和一层 sigmoid 的全卷积网络,用于计算混合权重 ( \beta_p )(见图2)。网络的输入包括:(1)来自前景和背景解码器最后一块的特征图;(2)来自与输入 RGB 图像卷积的特征。我们根据实验将卷积核的大小设置为 3×3,发现具有这种核大小的融合网络可以更好地生成 alpha 遮罩的细节。
训练损失:假设前景和背景解码器已经为实体像素提供了合理的分割结果,我们将训练损失设计为向过渡区域中的像素倾斜。融合网络的损失函数可以根据公式(2)直接推导出:
L
u
=
∑
p
w
p
⋅
∣
β
p
F
ˉ
p
+
(
1
−
β
p
)
(
1
−
B
ˉ
p
)
−
α
p
∣
.
(
8
)
{\cal L}_{u}=\sum_{p}{\bf w}_{p}\cdot|\beta_{p}\bar{\bf F}_{p}+(1-\beta_{p})(1-\bar{\bf B}_{p})-\alpha_{p}|.\qquad{(8)}
Lu=p∑wp⋅∣βpFˉp+(1−βp)(1−Bˉp)−αp∣.(8)
代码实现:
import os
import random
import math
import multiprocessing
import numpy as np
import skimage.transform
import tensorflow as tf
import keras
import keras.backend as K
import keras.layers as KL
import keras.engine as KE
import keras.models as KM
from util import BatchNorm, BilinearUpsampling
############################################################
# Fusion Net
############################################################
def fusion_graph_with_rgb(fg_features, bg_features, input_rgb, output_shape=None, filters=[256, 128, 128, 64, 256],
train_bn=True, network_name='fusion_', d=256):
'''
:param fg_features: [b, 512, 512, d]
:param bg_features: [b, 512, 512, d]
:param trimap: [b, 512, 512, 1]
:param backbone_r1: [b, 256, 256, 64]
:param filters:
:param train_bn:
:param network_name:
:param broadcast_trimap:
:return:
'''
if len(filters) == 5:
nb_filter0, nb_filter1, nb_filter2, nb_filter3, nb_filter4 = filters
else:
nb_filter0, nb_filter1, nb_filter2, nb_filter3 = filters
# TODO: input_rgb = raw_image - mean_pixel.
# TODO: BatchNorm
conv_rgb = KL.Conv2D(d, (3, 3), strides=1, name=network_name+'convrgb', padding='same')(input_rgb)
conv_rgb = BatchNorm(name=network_name + "bnrgb")(conv_rgb, training=train_bn)
fusion_input = KL.Concatenate(axis=3, name=network_name+'input_concate')([fg_features, bg_features, conv_rgb])
x = KL.Conv2D(nb_filter0, (3, 3), strides=1, name=network_name + "conv0", padding='same')(fusion_input)
x = BatchNorm(name=network_name + "bn0")(x, training=train_bn)
conv0 = KL.Activation('relu', name=network_name + "relu0")(x)
# fusion_conv1
x = KL.Conv2D(nb_filter1, (3, 3), strides=1, name=network_name + "conv1", padding='same')(conv0)
x = BatchNorm(name=network_name + "bn1")(x, training=train_bn)
x = KL.Activation('relu', name=network_name + "relu1")(x)
conv1 = x
# fusion_conv2
x = KL.Conv2D(nb_filter2, (3, 3), strides=1, name=network_name + "conv2", padding='same')(x)
x = BatchNorm(name=network_name + "bn2")(x, training=train_bn)
x = KL.Activation('relu', name=network_name + 'relu2')(x)
conv2 = x
# fusion_conv3
x = KL.Conv2D(nb_filter3, (3, 3), strides=1, name=network_name + "conv3", padding='same')(x)
x = BatchNorm(name=network_name + "bn3")(x, training=train_bn)
x = KL.Activation('relu', name=network_name + 'relu3')(x)
conv3 = x
# fusion_conv4
if len(filters) == 5:
x = KL.Conv2D(nb_filter4, (3, 3), strides=1, name=network_name + "conv4", padding='same')(x)
x = BatchNorm(name=network_name + "bn4")(x, training=train_bn)
x = KL.Activation('relu', name=network_name + 'relu4')(x)
conv4 = x
# fusion_output
x = KL.Conv2D(1, (1, 1), strides=1, name=network_name + "conv_output", padding='same')(x)
# x = BatchNorm(name=network_name+"bn_output")(x, training=train_bn)
output = KL.Activation('sigmoid', name=network_name + "sigmoid_output")(x)
# output = BilinearUpsampling(output_size=(output_shape[0], output_shape[1]), name=network_name + '_upsampling')(
# output)
return output, [conv0, conv1, conv2, conv3]
def blending_graph(fg_out, bg_out, fg_weights, network_name='fusion_'):
# bg_weights = KL.Subtract()([K.constant(K.ones_like(fg_weights)), fg_weights])
weighted_fg = KL.Multiply(name=network_name + 'fg_mul')([fg_out, fg_weights])
temp_1 = KL.Lambda(lambda x: 1.0-x, name=network_name+'reverse_lambda_bg')(bg_out)
temp_2 = KL.Lambda(lambda x: 1.0-x, name=network_name+'reverse_lambda_blendingweight')(fg_weights)
weighted_bg = KL.Multiply(name=network_name+'bg_mul')([temp_1, temp_2])
final_result = KL.Add(name=network_name + 'blending_output')([weighted_fg, weighted_bg])
return final_result
def generate_trimap(predict_tensors, edge_width=20, threshold=0.5):
# binarize
predict_fg_tensor = K.cast(predict_tensors[0] > threshold, dtype='float32')
predict_bg_tensor = K.cast((1 - predict_tensors[1]) > threshold, dtype='float32')
# heat = K.cast(tf.abs(fg-bg) > threshold, dtype='float32')
# make trimap
with tf.variable_scope('erosion_scope', reuse=tf.AUTO_REUSE):
kernel = tf.get_variable('erosion_kernel', [edge_width, edge_width, 1],
initializer=tf.zeros_initializer(), trainable=False)
dilation_fg = tf.nn.dilation2d(predict_fg_tensor, filter=kernel,
strides=[1, 1, 1, 1], rates=[1, 1, 1, 1],
padding='SAME', name='fg_dilation')
erosion_bg = tf.nn.erosion2d(predict_bg_tensor, kernel=kernel,
strides=[1, 1, 1, 1], rates=[1, 1, 1, 1],
padding='SAME', name='fg_erosion')
edge_map = dilation_fg - erosion_bg
edge_float = K.cast(edge_map > 0, dtype='float32')
trimap = tf.where(edge_map > 0, edge_float * 0.5, predict_fg_tensor)
trimap = tf.stop_gradient(trimap, name="stop_trimap_gradient")
edge_float = tf.stop_gradient(edge_float, name="stop_trimask_gradient")
return [trimap, edge_float]
3.4 训练细节
我们使用预先经过 ImageNet-1K 训练的 DenseNet-201 网络作为我们的编码器主干。首先对分割网络进行 15 次迭代的预训练。在融合网络的预训练步骤中,我们冻结了分割阶段,并单独训练了 4 次迭代的融合阶段。最后,我们对端到端的联合网络进行了 7 次迭代训练,这将融合结果的梯度反向传播至分割和融合网络,从而进一步减少了训练损失。在联合训练步骤中冻结所有批归一化层,以节省内存空间。循环学习率策略用于在整个训练过程中加快收敛速度。所有步骤的基本学习率为 5.0 × 1 0 − 4 5.0 \times 10^{-4} 5.0×10−4。预训练阶段的最大学习速率为 1.5 × 1 0 − 3 1.5 \times 10^{-3} 1.5×10−3。在联合训练步骤中,将最大学习速率设置为较小的 1.0 × 1 0 − 3 1.0 \times 10^{-3} 1.0×10−3。
在进行端到端联合训练以微调整个网络时,我们还会使用特殊的损失。损失是基于融合网络的损失,同时增加了分割网络的损失以避免过度拟合。总体连接训练损失描述如下:
L
J
=
L
u
+
w
1
(
L
F
+
L
B
)
+
w
2
L
s
,
(
9
)
L_{J}=L_{u}+w_{1}(L_{F}+L_{B})+w_{2}L_{\mathrm{s}},\qquad(9)
LJ=Lu+w1(LF+LB)+w2Ls,(9)
在我们的实现中,我们设置了
w
1
=
0.5
w_1 = 0.5
w1=0.5 和
w
2
=
0.01
w_2 = 0.01
w2=0.01。第三项
L
s
L_s
Ls直接采用自 [20] 中,用于惩罚软分割像素的数量,即:
L s = ∑ p α p γ + ( 1 − α p ) γ , γ ∈ [ 0 , 1 ] . ( 10 ) L_{\mathrm{s}}=\sum_{p}\alpha_{p}^{\gamma}+(1-\alpha_{p})^{\gamma},\;\gamma\in[0,1].\qquad(10) Ls=p∑αpγ+(1−αp)γ,γ∈[0,1].(10)
在我们的实验中,我们将 γ \gamma γ 设置为 0.9。
4、数据处理与模型训练
4.1.准备环境
conda create --name keras python=3.6
source activate keras
pip install tensorflow-gpu==1.14 keras scikit-image tqdm opencv-python scipy imgaug
4.2. 数据处理
数据集可参考:https://github.com/aisegmentcn/matting_human_datasets
数据存放目录结构如下:
- clip_img: 原始图像
- matting: 标注matting图像
- alpha: 根据matting生成的alpha图像,执行以下命令:
4.3.处理数据集
参数说明:
–imgDir:输入图像路径
–outDir:输出训练和验证txt的文件夹,txt中里面每一行分别是原始图像路径,alpha图路径
–trainRatio:训练集所占比例
python gen_alpha.py --imgDir data/clip_img --outDir data --trainRatio 0.9
结果将在data目录下生成train_set.txt和val_set.txt,分别表示训练集和验证集。
4.4.训练
训练第一阶段(分割网络):
python main.py train classifier --logs logs --dataset data --input_size 640,960 --epochs 10
参数说明:
–logs:模型和日志保存的路径,会自动生成该文件夹
–data:train_set.txt和val_set.txt所在的目录
–input_size:网络的输入大小(高,宽)
–epochs:训练的epoch数
训练第二阶段(融合网络):
python main.py train fusion --logs logs --dataset data --input_size 640,960 --weights logs/classifier20200801T2130/classifier_classifier_0010.h5 --epochs 20
参数说明:
–logs:模型和日志保存的路径,会自动生成该文件夹
–data:train_set.txt和val_set.txt所在的目录
–input_size:网络的输入大小(高,宽)
–weights: 第一阶段训练得到的模型
–epochs:训练的epoch数
联合训练:
python main.py train joint --logs logs --dataset data --input_size 640,960 --weights logs/fusion20200801T2130/classifier_fusion_0010.h5 --epochs 50
参数说明:
–logs:模型和日志保存的路径,会自动生成该文件夹
–data:train_set.txt和val_set.txt所在的目录
–input_size:网络的输入大小(高,宽)
–weights: 第二阶段训练得到的模型
–epochs:训练的epoch数
4.5 测试
python main.py infer joint --input_size 640,960 --weights logs/fusion20200801T2130/classifier_fusion_0020.h5 --image images/13.jpg --outdir results
注意:测试过程中会在当前目录生成一个lfm.pb,用来后续的pb转换。
参数说明:
–input_size:网络的输入大小(高,宽)
–weights: 训练得到的模型
–image:测试图像
–outdir:输出结果路径

4.6.转换pb模型
python convert.py --input lfm.pb --output checkpoints
参数说明:
–input:输入在测试阶段生成的pb模型
–output:模型保存文件夹,输出导出的pb模型,可以用于opencv dnn加载
4.7.模型C++推理
模型转成pb后,使用opencv的dnn进行推理,没有GPU的情况下推理时间有点慢,C++ 推理代码如下:
#include <iostream>
#include <string>
#include <vector>
#include <fstream>
#include <sstream>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
void show_img(std::string name, const cv::Mat& img) {
cv::namedWindow(name, 0);
int max_rows = 500;
int max_cols = 600;
if (img.rows >= img.cols && img.rows > max_rows) {
cv::resizeWindow(name, cv::Size(img.cols * max_rows / img.rows, max_rows));
}
else if (img.cols >= img.rows && img.cols > max_cols) {
cv::resizeWindow(name, cv::Size(max_cols, img.rows * max_cols / img.cols));
}
cv::imshow(name, img);
}
cv::Mat replaceBG(const cv::Mat cv_src, cv::Mat& alpha, std::vector<int>& bg_color)
{
int width = cv_src.cols;
int height = cv_src.rows;
cv::Mat cv_matting = cv::Mat::zeros(cv::Size(width, height), CV_8UC3);
float* alpha_data = (float*)alpha.data;
for (int i = 0; i < height; i++)
{
for (int j = 0; j < width; j++)
{
float alpha_ = alpha_data[i * width + j];
cv_matting.at < cv::Vec3b>(i, j)[0] = cv_src.at < cv::Vec3b>(i, j)[0] * alpha_ + (1 - alpha_) * bg_color[0];
cv_matting.at < cv::Vec3b>(i, j)[1] = cv_src.at < cv::Vec3b>(i, j)[1] * alpha_ + (1 - alpha_) * bg_color[1];
cv_matting.at < cv::Vec3b>(i, j)[2] = cv_src.at < cv::Vec3b>(i, j)[2] * alpha_ + (1 - alpha_) * bg_color[2];
}
}
return cv_matting;
}
int main(int argc, char* argv[])
{
cv::Mat img = cv::imread("images/5.jpg");
cv::Size reso(960, 640);
cv::Mat blob = cv::dnn::blobFromImage(img, 1.0, reso,
cv::Scalar(127.156207, 115.917443, 106.031127), true, false);
cv::dnn::Net net = cv::dnn::readNet("model/graph_final_960_640.pb", "model/graph_final_960_640.pbtxt");
net.setInput(blob);
std::vector<cv::Mat> outputs;
std::vector<std::string> names = {
"deFG_side_0_out/ResizeNearestNeighbor",
"deBG_side_0_out/ResizeNearestNeighbor",
"fusion_sigmoid_output/Sigmoid"
};
auto t0 = cv::getTickCount();
net.forward(outputs, names);
auto t1 = cv::getTickCount();
std::cout << "forward time: " << (t1 - t0) * 1000.0 / cv::getTickFrequency() << "ms" << std::endl;
for (size_t i = 0; i < outputs.size(); ++i) {
outputs[i] = outputs[i].reshape(0, { outputs[i].size[2], outputs[i].size[3] });
cv::resize(outputs[i], outputs[i], img.size(), 0.0, 0.0, cv::INTER_LINEAR);
}
cv::Mat fg = outputs[0];
cv::Mat bg = outputs[1];
cv::Mat alpha = outputs[2];
cv::Mat matting = fg.mul(alpha) + (1.0 - bg).mul(1.0 - alpha);
std::vector<int> color{ 255, 255, 255 };
cv::Mat cv_dst = replaceBG(img, matting, color);
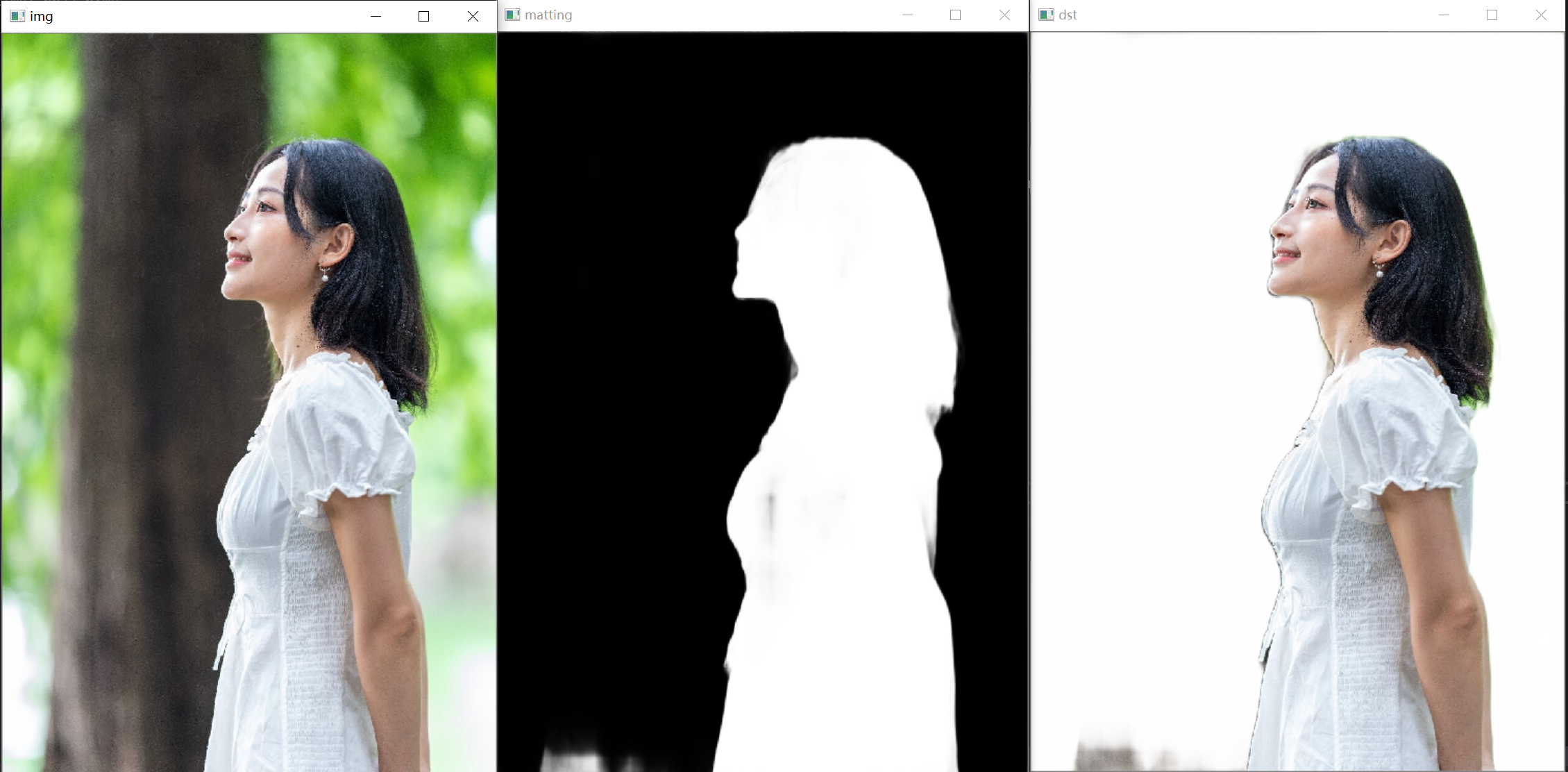
show_img("img", img);
show_img("fg", fg);
show_img("dst", cv_dst);
show_img("alpha", alpha);
show_img("matting", matting);
cv::waitKey();
return 0;
}

后记
这篇论文是全自动抠图的鼻祖,复现与训练的效果没有官方给结果精度那么高,关于这方面,网上有人提出了质疑官方将test set也放进train set,但我测试之后效果并没有那么差。



















 9722
9722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











