







介绍
论文地址:https://arxiv.org/abs/2403.18551
源码地址:https://github.com/monalissaa/disendiff
近年来,使用大型语料库的文本到图像(T2I)建模技术取得了巨大进步,大大提高了图像生成和合成的质量。现在,只需输入少量图像,就能轻松生成参考图像中不存在的新概念。但另一方面,当数据集为单一图像时,注意力图谱变得模糊不清,扩散模型难以学习和生成该图像特有的概念和外观,这仍然是一个挑战。
因此,本文提出了一种注意力校准机制,以提高 T2I 模型的概念理解能力。该机制引入了与类相关联的可学习修饰符,从单幅图像中提取多个概念,这些概念之间互不干扰,抑制了不同概念之间的相互影响,增强了逐类理解能力。
本文提出的方法被命名为 “分离扩散法”(DisenDiff),在各种数据集的定性和定量评估中均证明其性能优于 SOTA。此外,据报告,该方法在扩展任务方面具有很高的灵活性,包括与 LoRA 和 Inpainting 技术的互操作性。
DisenDiff
如图 1 所示,本文提出的 DisenDiff 注意力校准机制通过三个阶段来解决单一图像中的多个概念。
稳定扩散技术输出的注意力图首先会通过抑制技术在相应的类别区域内变得更加清晰。然后,引入损失Lbind,使修饰符与类别相对应。最后,添加损耗Ls&s将每个类别独立分离出来。下一节将介绍每个阶段。
本文使用稳定扩散作为骨干模型,使用 CLIP 作为预训练文本编码器。
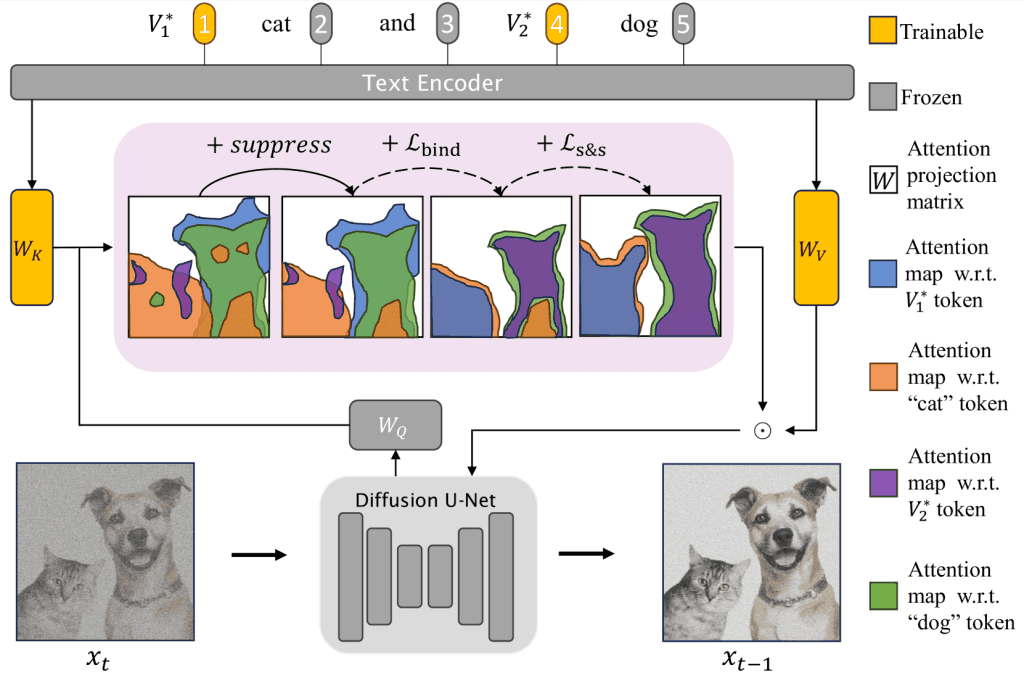
图 1:DisenDiff 的全貌。
引入可学习的修改器
T2I 模型的训练需要在输入图像的同时输入适当的文本提示。在本文中,修饰符标记 "Vi*"被插入类标记 "猫 "之前,如 “V1*猫和 V2*狗”。
修改器和类绑定
当训练数据为单一图像时,传统方法往往会过度拟合,导致每个标记的注意力图模糊不清。利用前面介绍的修饰符标记注意力,可以根据图 2 生成精确的交叉注意力图。
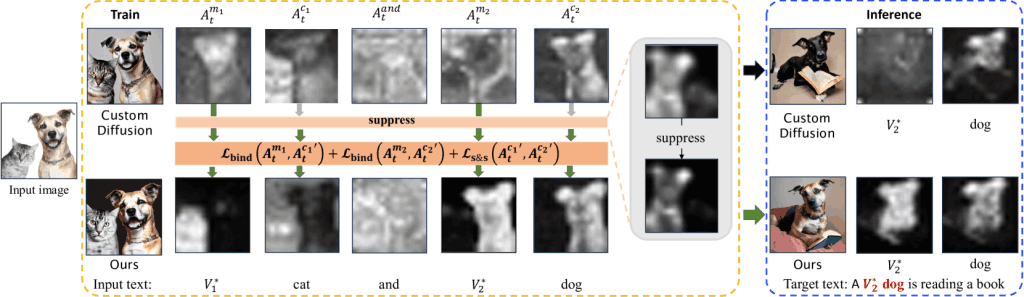
图 2 每个标记的注意力图。
图 2 中最上方的地图显示,与修饰符标记的地图相比,类标记的注意力地图能够大致捕捉到类的语义边界。因此,我们的目标是通过提供以下损失来增加修饰符标记与类标记注意力图谱之间的 IoU,激活修饰符标记并使其与相应的类标记对齐。
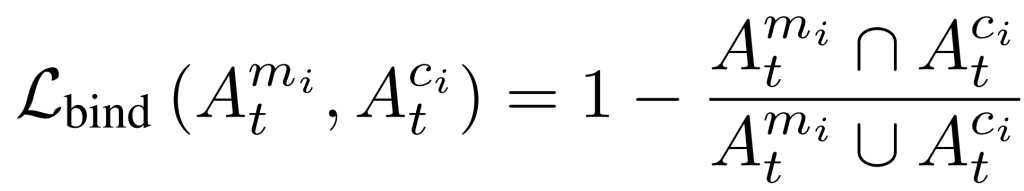
然而,按原样调整这一损失可能会导致一些问题,例如同一像素上的注意力水平相互竞争,或者修改器不能全面捕捉概念。因此,本文在计算损失之前,会对注意力图谱应用高斯滤波器_G(At_) 使其平滑。
阶级分化和提高
如上一节所述,当训练数据为单张图像时,存在过度拟合的趋势,但同时也存在类别标记可能会侵占其他类别区域的问题。图 2 中最上方的地图显示,"猫 "标记的注意力地图也在一定程度上侵入了 "狗 "领域。
因此,通过给出下一个损失,可以在避免与其他对象重叠和确保全面覆盖对象之间取得平衡,从而提高注意力的准确性。
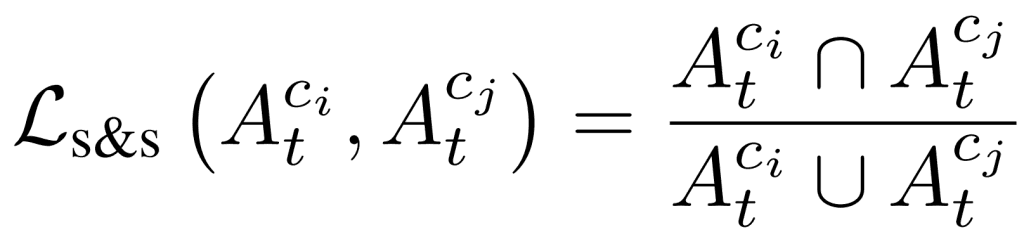
但是,由于不同类别之间的激活分布不平衡,按原样调整这一损失可能会导致对某些类别的强调不自然。因此,本文在计算损失之前,对注意力图进行了逐元素乘法,即__fm(Atci)__=Atci⨀Atci,以排除对某一类别不太重要的激活分布。
总体培训损失
根据上文所述,训练过程中使用的损失可表示如下。其中,_S 是_输入图像中的类别数。
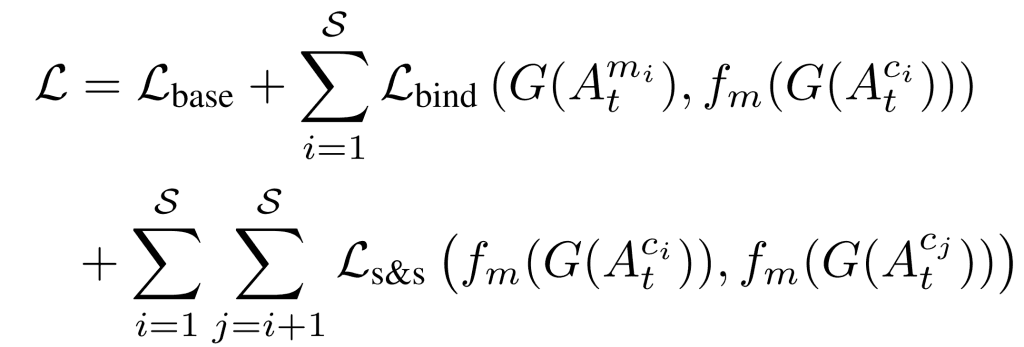
试验
数据集
本文在 10 个数据集上进行了实验,这些数据集涉及人物、动物、家具和有宠物/玩具的人等多个类别。数据集中的每张图片都包含两个不同的概念。推理测试在每张图片中使用了 30 个提示,其中 10 个提示同时关注两个概念,10 个提示关注第一个概念,10 个提示关注第二个概念。
估值指数
图像对齐度测量生成图像与相应真实图像之间的 CLIP 空间余弦相似度,而文本对齐度则计算提示文本与图像之间的相似度。这些评估指标在图像重建能力和可编辑性之间取得了平衡。
实验结果
将所提出的方法模型 DisenDiff 与三种最先进的 T2I 模型–文字反演(TI)、DreamBooth(DB)和自定义扩散(CD)–进行了比较,定量比较结果如图 3(a)所示。
从图 3(a)左上角的平均值可以看出,在图像对齐方面,所提方法的模型优于所有比较过的模型;在文本对齐方面,TI 优于所提方法,但 TI 的图像对齐度较低。在文本对齐方面,TI 优于提议的方法,但 TI 的图像对齐度较低,可以看出在生成过程中没有很好地保持原始概念。因此,在保持文本编辑效果的同时,建议方法的模型实现了最高的图像重建能力。
图 3(b) 还显示了为确定对每个组件的需求而进行的消融分析结果。从图中可以看出,采用了所有策略的拟议方法取得了最均衡的性能。
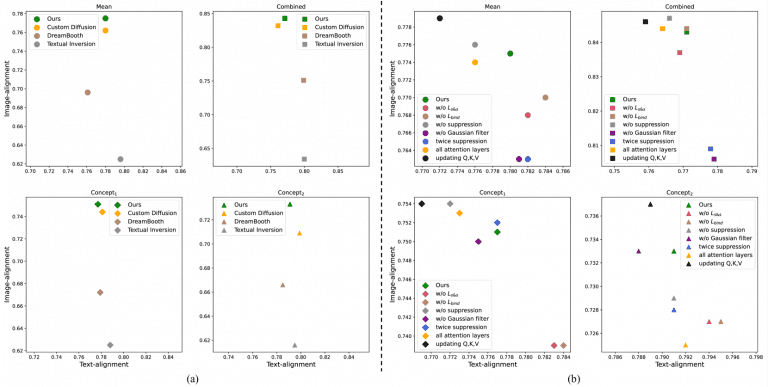
图 3 拟议方法与其他三种 T2I 模型的定量评估比较
图 4 显示了所提议的方法与两种图像高度对齐模型在不同提示下的视觉对比结果。
已输入目标提示,以评估在各种编辑场景中学习到的独立和组合概念,如改变场景、添加对象、改变风格和对概念分离做出反应。例如,对于单个输入图像上的一只猫和一只狗,提示是改变狗的品种以生成图像。
从图 5 中可以看出,DB 合成图像的特点是缺少构成要检索概念的基本元素,而 CD 合成图像的缺点是没有保留概念的外观。由此可以看出,与其他模型相比,拟议方法模型 DisenDiff 与原始图像的保真度更高。
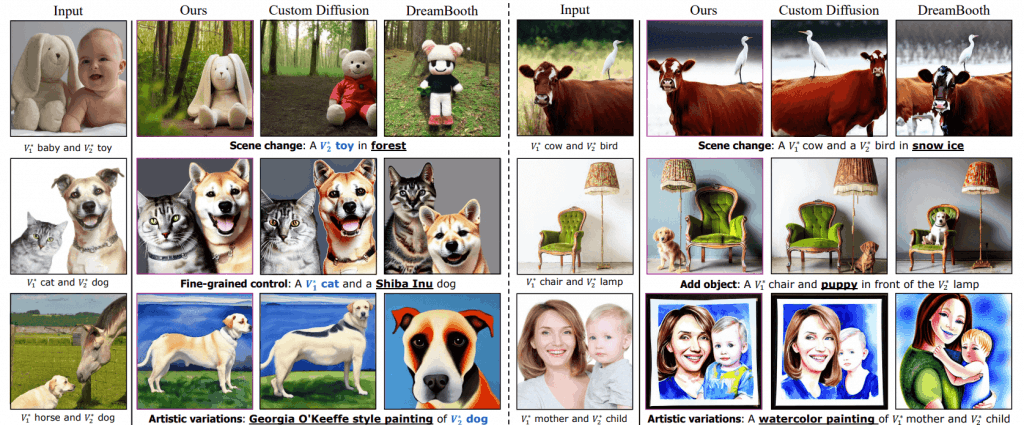

图 4:拟议方法与其他两种 T2I 模型的定性评估比较
论文最后表明,所提出的模型可与 LoRA 和内绘制管道互操作,并可用于用户友好型应用开发。
结论
本文提出的 DisenDiff 可从单张图像中学习多个概念,而不会出现重复。为了为每个标记构建准确的注意力图,交叉注意力单元中引入了独特的损失,以准确捕捉待检索概念的外观,同时减少对单一图像的过度拟合。与其他 T2I 模型的比较表明,所提出的方法模型对输入图像具有很高的保真度和很强的图像重构能力,在定量和定性方面都显示出了最先进的优越性。
所提出的 DisenDiff 方法尤其令人印象深刻的一点是,它通过在交叉注意力图中引入独特的损失,能够比传统方法更好地提取单幅图像的独特概念。这种方法与其他方法(如内画技术)兼容,并有可能提高图像合成技术的质量。我非常期待它的进展。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











