







介绍
论文地址:https://arxiv.org/abs/2312.04557
扩散模型在图像生成、视频制作、音频合成和代码生成等各种内容创建领域取得了显著进展。然而,这些领域通常使用卷积 U-Net 架构。因此,通过在自然语言处理和计算机视觉识别领域应用占主导地位的变换器,有望生成更高质量的图像和视频。
在这篇评论文章中,我们提出了一种利用Transformers的扩散模型–GenTron。其主要方针是改进扩散变换器(DiTs)。首先,功能从类扩展到文本条件图像生成。此外,GenTron 将大幅扩展,以利用变换器架构的可扩展性,并提高视觉质量。此外,GenTron 还从图像生成模型发展到视频生成模型,为每个变换器块添加了时间自注意层,从而提出了视频扩散模型变换器。它还提出了新的无运动引导,以提高视频质量。
在实验中,除了常用指标外,GenTron 在人类评分方面的表现也优于扩散模型 SOTA、SDXL,在视觉质量方面取得了 51.1% 的胜率(抽签率为 19.8%),在文本对齐方面取得了 42.3% 的胜率(抽签率为 42.9%)。
算法框架
从文本生成图像
从文本生成图像(T2I)涉及两个关键要素。首先是选择文本编码器将原始文本转换为文本嵌入,其次是如何将这些嵌入整合到扩散过程中。
在文本编码器方面,典型的模型包括多模态模型中的 Text Tower 和 CLIP,以及大规模语言模型 Flan-T5。为了测试这些语言模型的有效性,本文将每个模型独立集成到 GenTron 中,并对每个模型的性能进行评估。
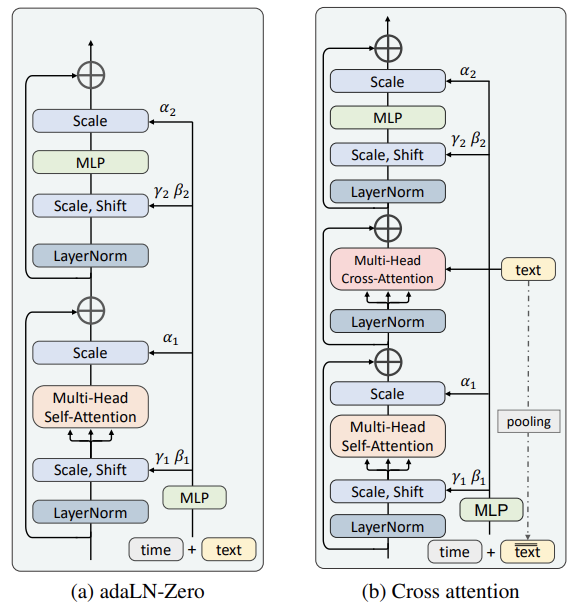
图 1. 文本嵌入的集成架构
关于将嵌入文本整合到扩散过程中,图 1 中考虑了两种方法:第一种是 Adaptive layernorm(adaLN)。如图 1.a 所示,它将条件嵌入作为特征通道的归一化参数进行整合,与广泛应用于条件生成模型(如 StyleGAN)的 adaLN 类似。
第二种技术是交叉关注。如图 2b 所示,图像特征充当查询,文本嵌入充当键和值。这种设置允许图像特征和文本嵌入通过关注机制进行直接交互。
扩大模型
关于模型的扩展,重点在于扩展三个关键方面:Transformers块的数量(深度)、补丁嵌入的维度(宽度)和 MLP 的隐藏维度(MLP 宽度)。其中,GenTron-G/2 模型有超过 30 亿个参数。它是迄今为止开发的最大的基于Transformers的扩散模型。

表 1. GenTron 型号的配置详情
根据文本生成视频
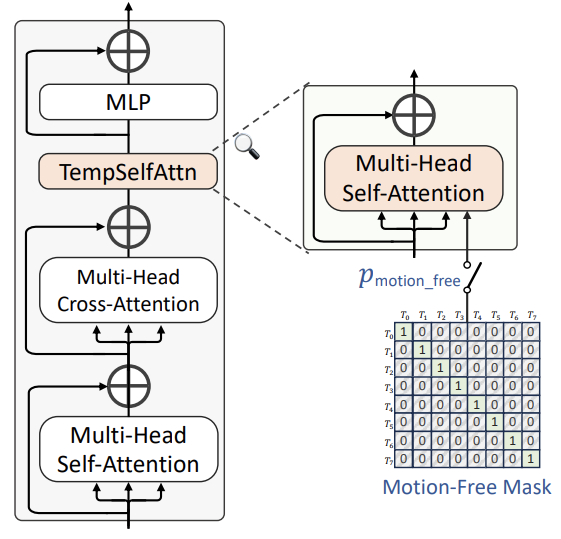
图 2. 视频生成模型的结构
TempSelfAttn
在视频生成任务中,模型由图 2 所示的变换块组成。与传统方法不同的是,这种方法没有在 U-Net 中同时添加时空卷积层和时空变换块,而只是在每个变换块中集成了一个轻量级时空自注意层(TempSelfAttn)。如图 2 所示,TempSelfAttn 层紧接在交叉注意层之后、MLP 层之前。在进入 TempSelfAttn 层之前,它对交叉注意层的输出进行重构,并在通过后将其恢复为原来的形式,从而进一步修改交叉注意层的输出。
无运动引导
面临的挑战是,在学习视频生成过程中,如果只关注时间方面的优化,就会无意中损害空间视觉质量,进而降低生成视频的整体质量。为解决这一问题,我们提出了无运动引导方法。与无分类器引导类似,这种方法用空字符串取代了条件文本。不同之处在于,它使用了一个单元矩阵,以概率 p 来禁用时间注意力。
单位矩阵如图 2(无运动遮罩)所示,对角线上填充 1,所有其他位置设为 0。这种配置限制了时空自取只能在单帧内工作。此外,时态自取是时态建模的唯一运算符。因此,在视频扩散过程中,只需使用无运动注意力掩码,就能禁用时间建模。
试验结果
验证每种成分的功效
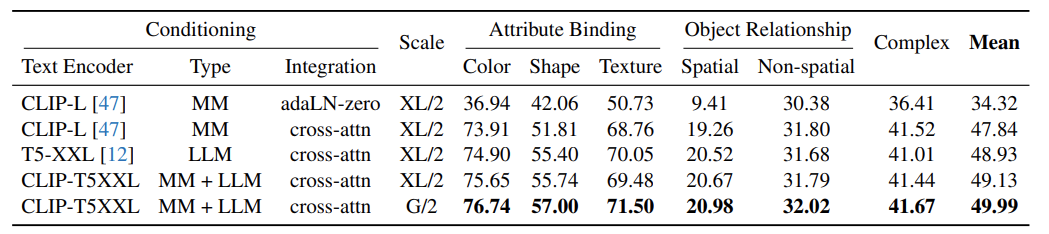
表 2. 各组成部分效果的验证结果
交叉关注与 adaLN
实验揭示了 adaLN 在处理自由形式文本条件时的局限性。在图 3 中,adaLN 生成熊猫图像的尝试并不充分,而 Cross attention 则显示出明显的优势。表 2 的前两行也从数量上验证了这一点,Cross attention 在所有评估指标上都始终优于 adaLN。

交叉注意和 adaLN 的比较
文本编码器比较
表 2 评估了 T2I-CompBench 中的不同文本编码器。结果显示,GenTron-T5XXL 在三个指标上的表现优于 GenTronCLIP-L,而在另外两个指标上的表现类似。这表明 T5 嵌入具有更好的可配置性。另一方面,将 CLIP-L 和 T5XXL 嵌入结合起来可以提高 GenTron 的性能,这表明该模型能够利用每种文本嵌入类型的不同优势。
与以往研究的比较
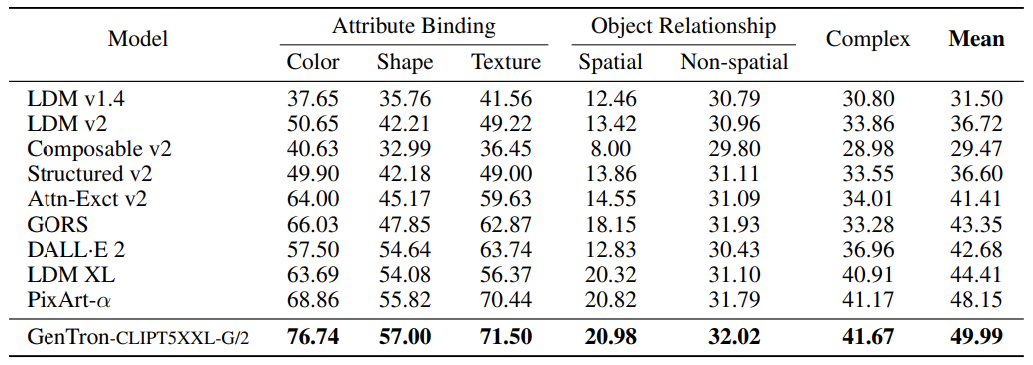
表 3.与以往研究的比较结果
在这一理论中,根据上述测试的交叉注意、CLIP-L 和 T5XXL 的组合效果,并与以往的研究进行比较,建立了最终模型。
表 3 显示了 T2I-CompBench 的配准评估结果。在属性绑定、对象关系和复杂配置等所有方面,拟议的方法都表现出色。这表明生成配置的能力有所提高,特别是在颜色绑定方面。特别是,拟议方法比以前研究的 SOTA 高出 7% 以上。
人类评估

图 4:人类评估结果。
在图 4 中,使用 PartiPrompt2 的标准提示,同时使用建议的方法和 LDXL 生成了 100 张图片,并在洗牌后盲式询问人们的偏好。共收到 3000 份关于视觉质量与文本可靠性的回复。结果显示,建议的方法明显更胜一筹。
文本到视频的生成结果

图 5.视频生成结果示例。
使用的提示:“泰迪熊走在第五大道上,前方是美丽的日落”、“一只狗在游泳”、"一只巨龟正穿过海滩 "和 “一只海豚跳出水面”。"一只巨龟正穿过海滩 "和 “一只海豚跃出水面”。
图 5 是 GenTron-T2V 生成的视频。它不仅在视觉上令人印象深刻,而且在时间上也表现出了高质量的一致性。特别是在生成视频的一致性方面,建议的无运动引导非常有效。如图 6 所示,当 GenTron-T2V 与 MFG 集成时,有一个明显的迹象表明,人们明显倾向于将注意力集中在提示中提到的中心物体上。具体来说,在生成的视频中,该对象通常更加详细、更加突出、占据中心位置,并且是整个视频帧的视觉焦点。

图 6:测试无动作引导有效性的实验 提示:“夕阳西下,一只狮子站在大海中的冲浪板上”。
总结
本文介绍了基于变换器的图像和视频生成扩散模型 GenTron。通过研究文本编码器、如何将嵌入文本整合到扩散过程中,以及提出用于视频生成的 TempSelfAttn 和无运动引导,GenTron 在人类评估和一般评估指标上都优于扩散模型 SOTA。从这些结果来看,GenTron可望帮助缩小将转换器应用于扩散模型的差距,并促进其在不同领域的广泛应用。
















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











