









Intro
from: https://en.wikipedia.org/wiki/Systolic_array
Overview
In parallel computer architectures, a systolic array is a homogeneous network of tightly coupled data processing units (DPUs) called cells or nodes. Each node or DPU independently computes a partial result as a function of the data received from its upstream neighbors, stores the result within itself and passes it downstream. They are sometimes classified as multiple-instruction single-data (MISD) architectures under Flynn's taxonomy, but this classification is questionable because a strong argument can be made to distinguish systolic arrays from any of Flynn's four categories: SISD, SIMD, MISD, MIMD, as discussed later in this article.
The parallel input data flows through a network of hard-wired processor nodes, which combine, process, merge or sort the input data into a derived result. Because the wave-like propagation of data through a systolic array resembles the pulse of the human circulatory system, the name systolic was coined from medical terminology. The name is derived from systole as an analogy to the regular pumping of blood by the heart.
A major benefit of systolic arrays is that all operand data and partial results are stored within (passing through) the processor array. There is no need to access external buses, main memory or internal caches during each operation as is the case with Von Neumann or Harvard sequential machines. The sequential limits on parallel performance dictated by Amdahl's Law also do not apply in the same way, because data dependencies are implicitly handled by the programmable node interconnect and there are no sequential steps in managing the highly parallel data flow.
Systolic arrays are therefore extremely good at artificial intelligence, image processing, pattern recognition, computer vision and other tasks which animal brains do so particularly well. Wavefront processors in general can also be very good at machine learning by implementing self configuring neural nets in hardware.
Architecture
A systolic array typically consists of a large monolithic network of primitive computing nodes which can be hardwired or software configured for a specific application. The nodes are usually fixed and identical, while the interconnect is programmable. The more general wavefront processors, by contrast, employ sophisticated and individually programmable nodes which may or may not be monolithic, depending on the array size and design parameters. The other distinction is that systolic arrays rely on synchronous data transfers, while wavefront tend to work asynchronously.
Unlike the more common Von Neumann architecture, where program execution follows a script of instructions stored in common memory, addressed and sequenced under the control of the CPU's program counter (PC), the individual nodes within a systolic array are triggered by the arrival of new data and always process the data in exactly the same way. The actual processing within each node may be hard wired or block microcoded, in which case the common node personality can be block programmable.
The systolic array paradigm with data-streams driven by data counters, is the counterpart of the Von Neumann architecture with instruction-stream driven by a program counter. Because a systolic array usually sends and receives multiple data streams, and multiple data counters are needed to generate these data streams, it supports data parallelism.
A systolic array is composed of matrix-like rows of data processing units called cells. Data processing units (DPUs) are similar to central processing units (CPUs), (except for the usual lack of a program counter,[3] since operation is transport-triggered, i.e., by the arrival of a data object). Each cell shares the information with its neighbors immediately after processing. The systolic array is often rectangular where data flows across the array between neighbour DPUs, often with different data flowing in different directions. The data streams entering and leaving the ports of the array are generated by auto-sequencing memory units, ASMs. Each ASM includes a data counter. In embedded systems a data stream may also be input from and/or output to an external source.
An example of a systolic algorithm might be designed for matrix multiplication. One matrix is fed in a row at a time from the top of the array and is passed down the array, the other matrix is fed in a column at a time from the left hand side of the array and passes from left to right. Dummy values are then passed in until each processor has seen one whole row and one whole column. At this point, the result of the multiplication is stored in the array and can now be output a row or a column at a time, flowing down or across the array.[4]
Matrix Multiplication Example
from http://web.cecs.pdx.edu/~mperkows/temp/May22/0020.Matrix-multiplication-systolic.pdf
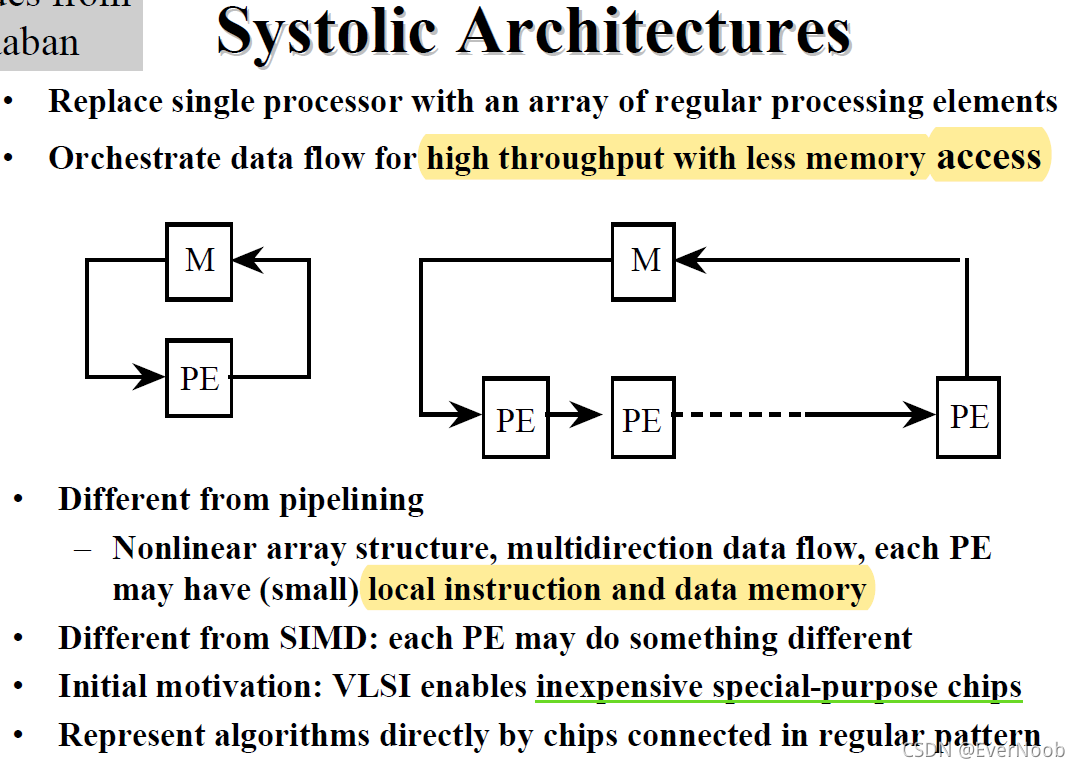
"PE may do something different" as in:
CPU, DPU and FPU for SIMDs are just PUs with different functional capacities.
for FPU, it has a singular ALU execution phase, while for the DPU or PE here, they will, as shown in the example below, pass data to neighbors, execute ALU and hold the data for final result. Each PE might be at a different phase per time step.
CPUs are generally functionlly independent for most multi-threaded tasks, but a multicore processor is essentially just a strongly out-of-phase PU array, with very sophisticated PUs.
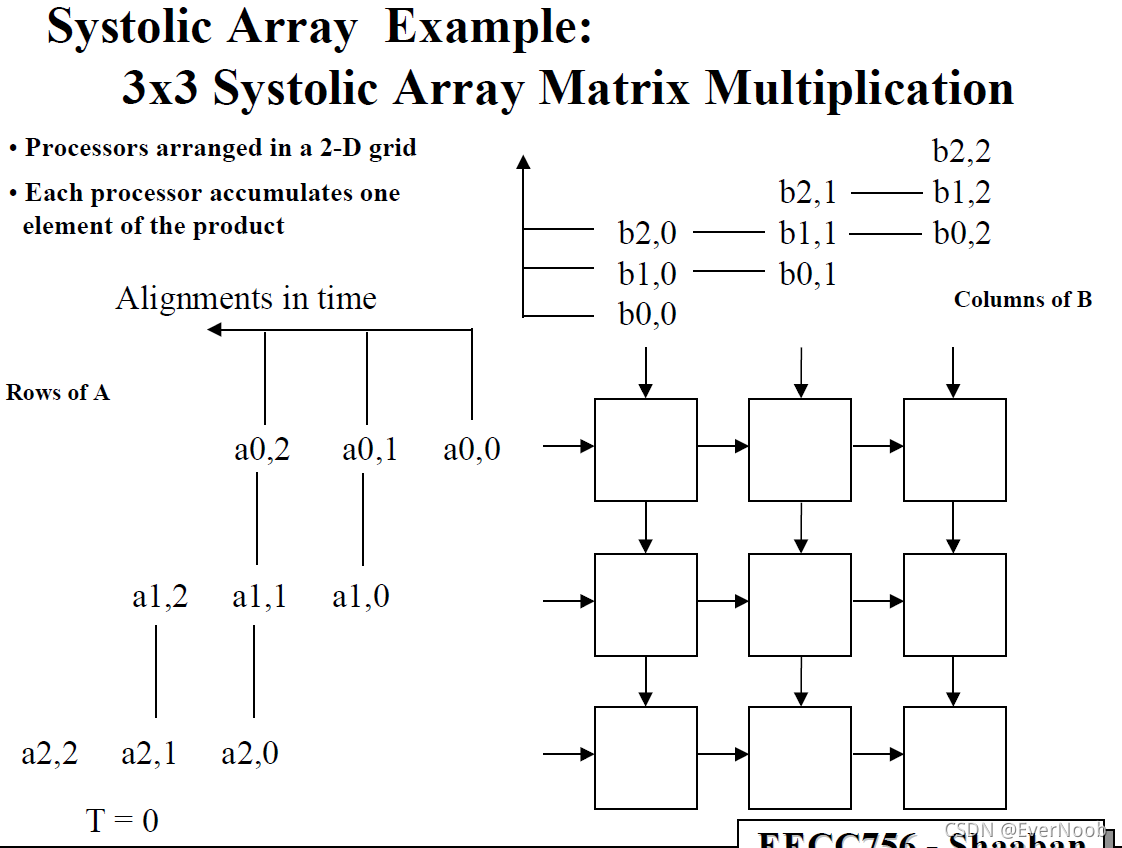
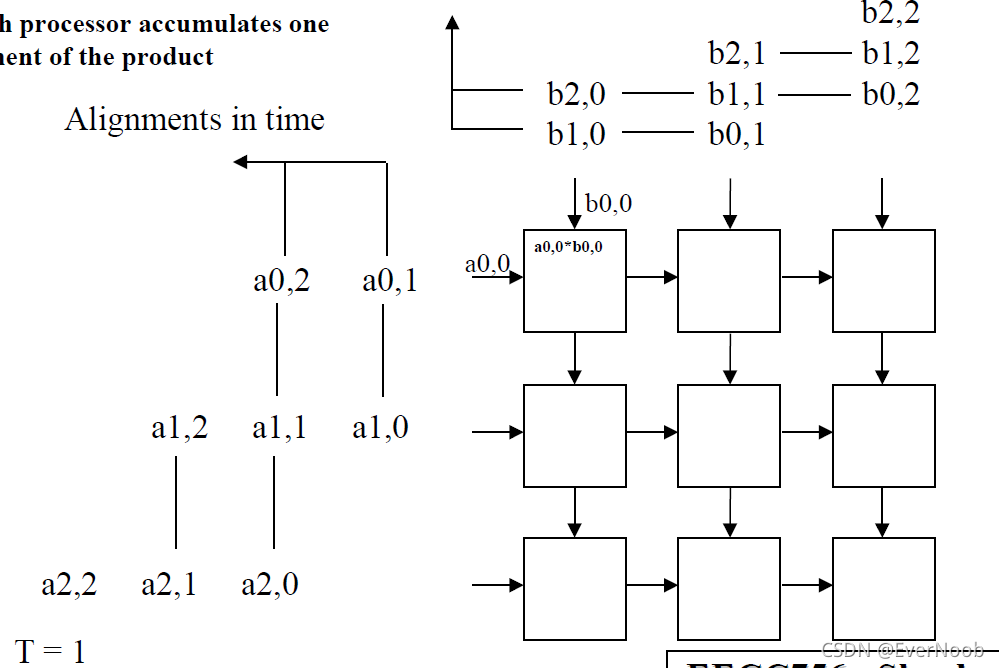
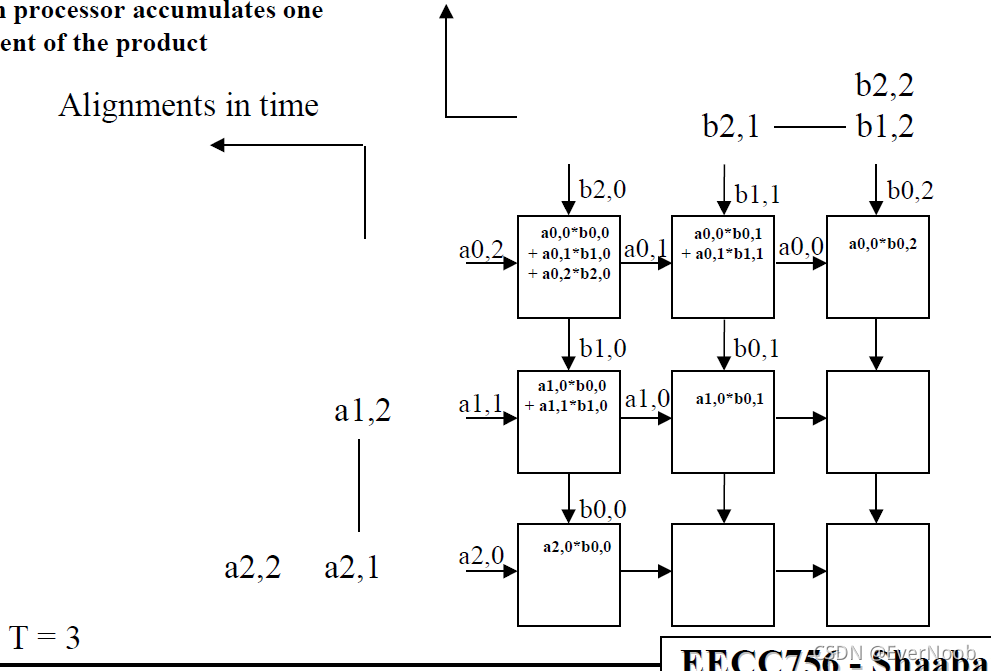
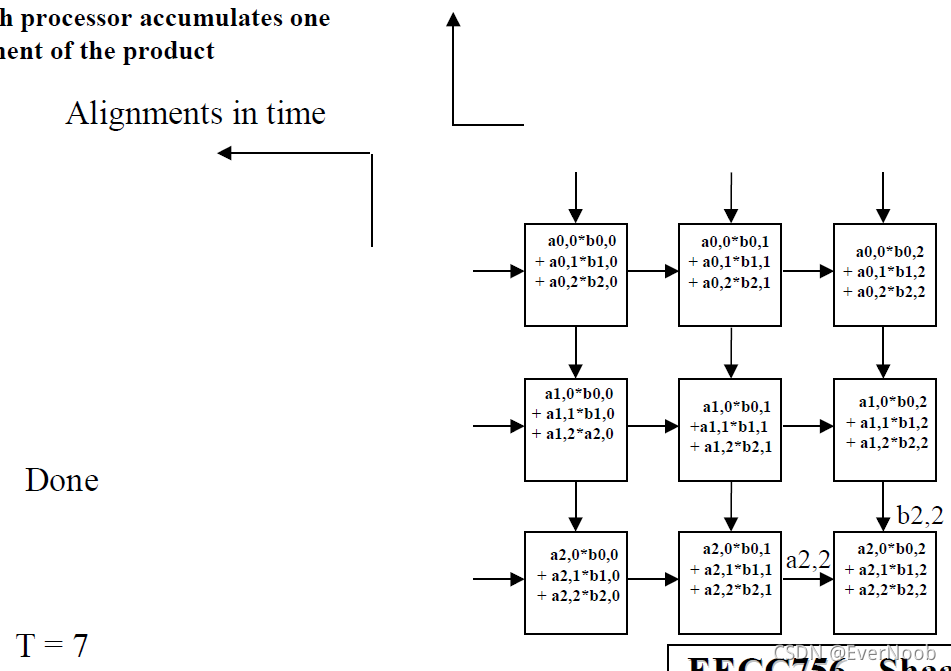
Note that:
1. Since we paid dearly for the hardware costs and the specialization (reduction of functionality) we should make sure the applicable domain has problems with much lower %overhead than this toy example.
2. The processing wavefront is diagonal, as this lock-step 2d unidirectional systolic array should have.
Important Further Readings
Textbook:
full:(PDF) Introduction to VLSI systems
Paper:
(PDF) Data-flow algorithms for parallel matrix computation
Dataflow Machine and Systolic Array:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









