






最近deepseek大语言模型很火,本地部署的概念也随着deepseek被更多普通用户所熟知,在网上跟着抄教程,即使小白也能完成本地部署。这里我理解的本地部署蒸馏模型比较于网上直接使用,好处于私有化和知识库的概念,使用工具是第一步,调教模型才是最终目的。
我在使用ollama开源工具进行本地部署的时遇到了一些问题,发现一些AI一些大博主(也有一些卖课AI的营销号)讲的开盖即食了,导致实际上遇到了一些很蛋疼且问AI无果的小毛病。这些都是我遇到问题,翻找各大平台贴吧知乎b站看到比较多新手问的,还望大佬们绕路。
首先确保电脑满足安装ollama这一款工具的条件,我知道大部分小白都是跟着教程无脑下一步,但是你网上搜到我这一篇肯定是遇到问题了,不妨瞅快速过一眼,说不定后面都不用看了。这个文档里告诉了,安装ollama需要什么系统版本,显卡驱动版本,支持什么显卡,还教了怎么改ollma模型的下载地址。
ollma的使用教程其实是有官方的版本的,github主页里教怎么安装怎么卸载怎么查看使用模型ollama/ollama:启动并运行 Llama 3.3、DeepSeek-R1、Phi-4、Gemma 2 和其他大型语言模型。
第一个问题:怎么下载ollama?
正常人都知道从官网下,Download Ollama on Windows
有人问官网速度很慢,怎么办?镜像模型下载很慢,怎么破?
答:用迅雷下。
这是我直接从官网默认的下载速度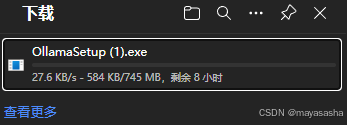
这是复制链接从某讯下载的速度,模型也可以这样下。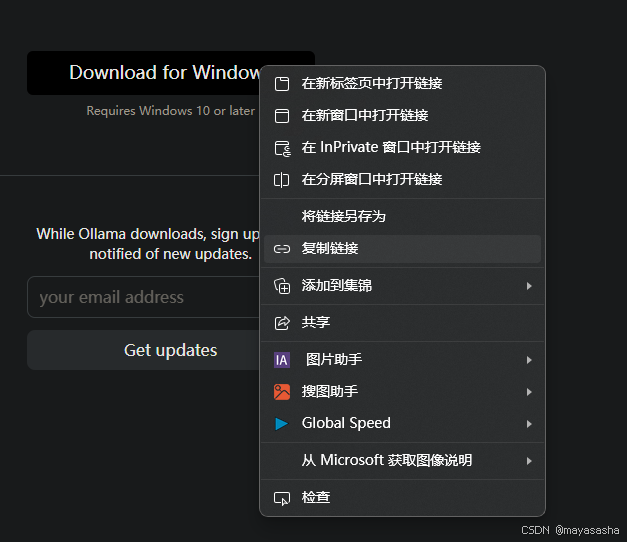
然后就是无脑下一步默认安装ollama。
第二个问题:怎么安装模型?
正常人都知道从官网搜索下载Ollama
这个视频也都会教,这里我了解到的ai的大模型有很多类,有擅长推理的模型,有擅长写代码的模型,甚至有用户重新上传的微调大模型,比如可以绕过审核的大模型,这个我了解的不多,只是知道有那么一个东西存在,大家拓宽思路,多多分享。
另外,我注意到ollma在执行ollma run下载命令,如果中断退出命令模式,是无法继续下载之前没下完的模型,必须重新下。
第三个问题:这GPU它不干活啊?
这使用模型我遇到的问题。我发现很多介绍ollama时并没有提到这个问题,但是很多人跟着教程安装遇到的情况,要知道cpu和gpu的算力根本不是一个量级的。我亲身体验是,我使用32bLLM,cpu运算十分钟的事情,换到gpu运算我只用10秒钟就得到了答案。
这就是为什么要使用gpu算力的原因。
其次,为什么很多人没有提到如何开启gpu的算力?这个问题我是询问的AI,准确度不一定AI说的可以参考一下,大概是说ollama在封装的时候集成了基于cuda的gpu预编译,安装时ollama检测到了你电脑上的显卡驱动,会默认开启cuda加速。但是在安装ollama时如果没有检测到你的显卡驱动(ollama版本不支持你的显卡驱动/windows系统版本不对/遇上了不知名的bug)等配置因素,ollama就会退回到cpu模式。这个说法我无法验证,但是我在网上检索时看到了有linux佬遇到gpu失效情况,尝试了通过代码解决的。
这也是为什么介绍ollama安装里没有提及需要安装cuda的环境,个人猜想可能是ollama默认集成了这个环境根据检测本地的显卡自动开启,所以很多人安装时并没有遇到gpu不工作的问题。而没有检测到本地显卡驱动,或者是ollama集成的cuda版本与显卡cuda版本冲突时,就需要手动安装cuda环境,并重新安装ollama释放gpu模式。
模型的使用方式,我这里简单陈述一下。
第一种是直接通过windows的cmd通过ollama run命令调出本地模型,
第二种是使用docker+openweb,【看番教程41】DeepSeek五分钟保姆级教程,本地搭建属于自己的大语言模型,我奶奶来了都会_哔哩哔哩_bilibili
第三种是其他像AnythingLLM这类的软件加载ollama,Anything LLM+Ollama 知识本地库_哔哩哔哩_bilibili
具体看各个博主的教程即可。我最先使用的使用第二种docker+openweb,我使用的这里的Nvidia GPU支持运行Open WebUI,来部署docker容器的openweb运行gpu模式
linux - 使用Ollama部署deepseek大模型 - 小陈运维 - SegmentFault 思否
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda我第一次安装到下载都很顺利,使用本地LLM发现一件事,能用,但很慢!风扇已经嘎嘎转了,但是gpu一点动静也没用。一看占用率不足5%。通过ollama ps检查gpu使用情况显示为100%,但是任务管理器是一直没动过。
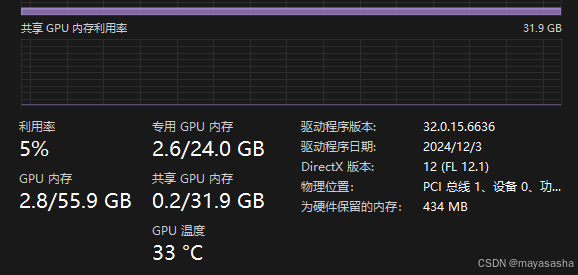
我最后是怎么解决的,答案是——重装ollama。
我是用尽了各种力气各种手段,问遍各大ai翻遍各大搜索引擎贴吧知乎github,对,没错,最后解决,解决问题的方法就是这么简单粗暴——重装。
在这里我本机的情况是系统和显卡是满足ollama要求,且我电脑是配置验证过cuda的环境,我一度怀疑ollama是否不支持我手动安装cuda版本造成的未知错误导致gpu失效,但是也有可能是我装过两次ollama导致,一次是本地安装,一次是docker安装,期间产生了什么不知名的冲突导致。所以当我第三次安装ollama时,这个问题被解决了。
以上提到本地部署的三种方案我都分别尝试过了,cmd调出模型还是到docker启动openWeb或是其他软件,ollama下调用模型始终跑的很慢,虽然cpu也能跑,但是1分钟到4分钟到卡死的速度实在令人头疼。最后经过重装解决后,所有的方案和工具都能正常用gpu算力跑起来了。
如果你重装重启无法解决,你可以尝试换一个部署本地模型的框架,比如lmstudio,它是可以手动调用你的gpu资源,不用担心cuda版本冲突影响(这也是我怀疑是不是我ollama cuda与我本机cuda冲突的原因,因为我在lm上运行,是百分之百能调用我的gpu的!)
如果以上没有解决你的问题,可以尝试我搜索过的步骤(个人感觉可能最终会做很多无用功)。
首先你要排除是否是模型的问题,再继续后续的检查工作。模型问题请看以下的求证方案,里面提提到有一些模型在预训练封装时,用到就是cpu的模式
请问,我想让ollama每次调用模型的时候,默认全部加载到GPU,有什么办法吗? · Issue #7479 · ollama/ollama
之后你需要排除ollama是否与系统存在版本冲突的问题。
①然后看你显卡是否支持,GPU - Ollama 中文文档 在看是否要更新显卡驱动。
②检查cuda环境部署,里面有验证检测cuda是否成功安装的方法
Ai学习之Ollama使用GPU运行模型的环境部署-CSDN博客
③如果你排除了硬件和环境的问题,可以尝试ollama修改默认的系统环境
Ollama:Ollama 配置优化与Open AI接口使用 - 知乎
(65 封私信 / 10 条消息) 如何让ollama只调用GPU工作? - 知乎
④如果还是无法解决,请参考一下ollama文档
使用 CUDA,但 GPU 的使用率接近 0% ·问题 #1663 ·OLLAMA/OLLAMA这篇文章提到了在docker部署的ollama遇到gpu占用率低可以采用删除容器重新构建的解决方案,也提到了重装可以解决gpu占用率低的问题。
⑤删除本机的ollama,完全使用docker部署,手动调用gpu的方案,这个我没尝试,我打算尝试的时候已经解决了。如果以上方案不行,可以尝试以下这个解决方案。一文教你在windows上实现ollama+open webui、外网访问本地模型、ollama使用GPU加速-CSDN博客

















 2774
2774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









