









实验环境
- 系统:AlmaLinux 8
- CPU:N5105
- 核显:Intel® UHD Graphics
- 运行内存:32G
- OpenCL版本:3.0
我们的目标不是用CPU来推理,而是用CPU的核心显卡来推理DeepSeek大模型!!!
过程
现在 llama.cpp 已经支持 OpenCL 后端,因此我这里采用 Llama.cpp + OpenCL 来运行DeepSeek大模型。
安装OpenCL
OpenCL(开放计算语言)是一个开放的、免版税的标准,用于跨平台、并行编程超级计算机、云服务器、个人计算机、移动设备和嵌入式平台中的各种加速器。OpenCL用于对这些设备和应用程序编程接口(API)进行编程,以控制平台并在计算设备上执行程序。与CUDA类似,OpenCL已被广泛用于GPU编程,并得到大多数GPU供应商的支持。
对于Intel的CPU,OpenCL的安装教程我总结到这里了:Linux下为Intel核显安装OpenCL
其他CPU我没有试过,请参考其他教程!
编译llama.cpp
llama.cpp 是用来运行各种大模型的,当然也可以运行 DeepSeek 模型。
先通过git来将这个项目克隆到本地:
git clone https://github.com/ggerganov/llama.cpp
# 没有git请先输入以下命令安装
yum install git -y
进入刚刚克隆好的文件夹中cd llama.cpp,准备编译。
通过以下两行命令来编译这个项目:
cmake -Bbuild -DGGML_OPENCL=ON -DGGML_OPENCL_USE_ADRENO_KERNELS=OFF
cmake --build build
其中-DGGML_OPENCL=ON代表启用OpenCL,这个是必加的参数,因为我们本来就是用OpenCL来跑模型嘛。然后-DGGML_OPENCL_USE_ADRENO_KERNELS=OFF是用来关闭 Adreno GPU (骁龙处理器的GPU,用于手机)选项的,因为我们用的是Intel的GPU。
我执行编译 cmake --build build 的时候出现了个问题:
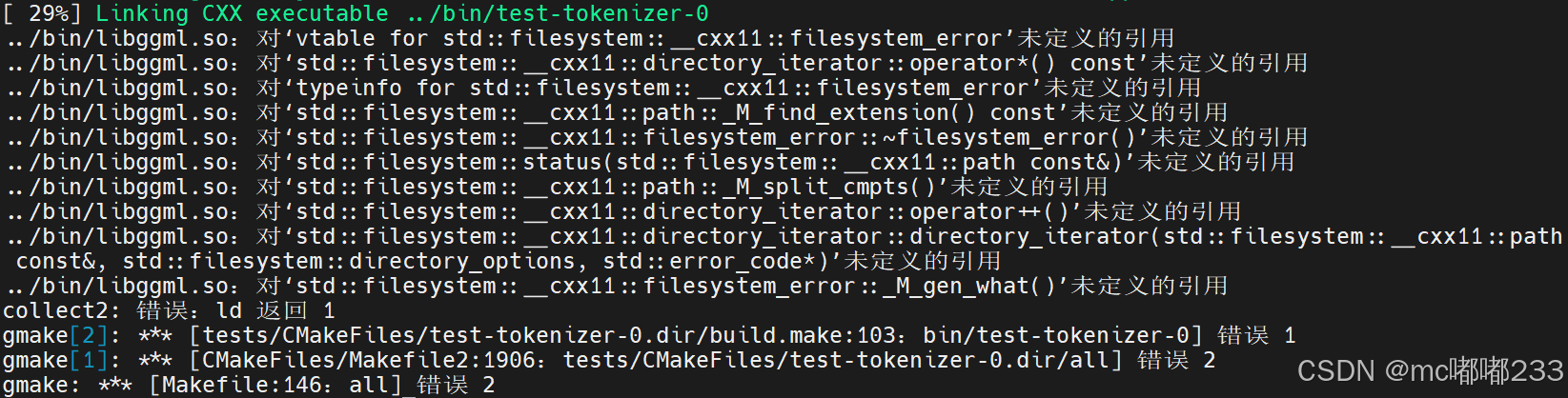
这是因为gcc编译器的版本太低导致的,我是参考这个文章解决的。就是要安装并启用新版本的gcc环境,对于RHEL的系统来说,执行:
yum install gcc-toolset-14
scl enable gcc-toolset-14 bash
然后再运行上面的cmake命令就能解决这个问题了。
以下是我的编译过程:
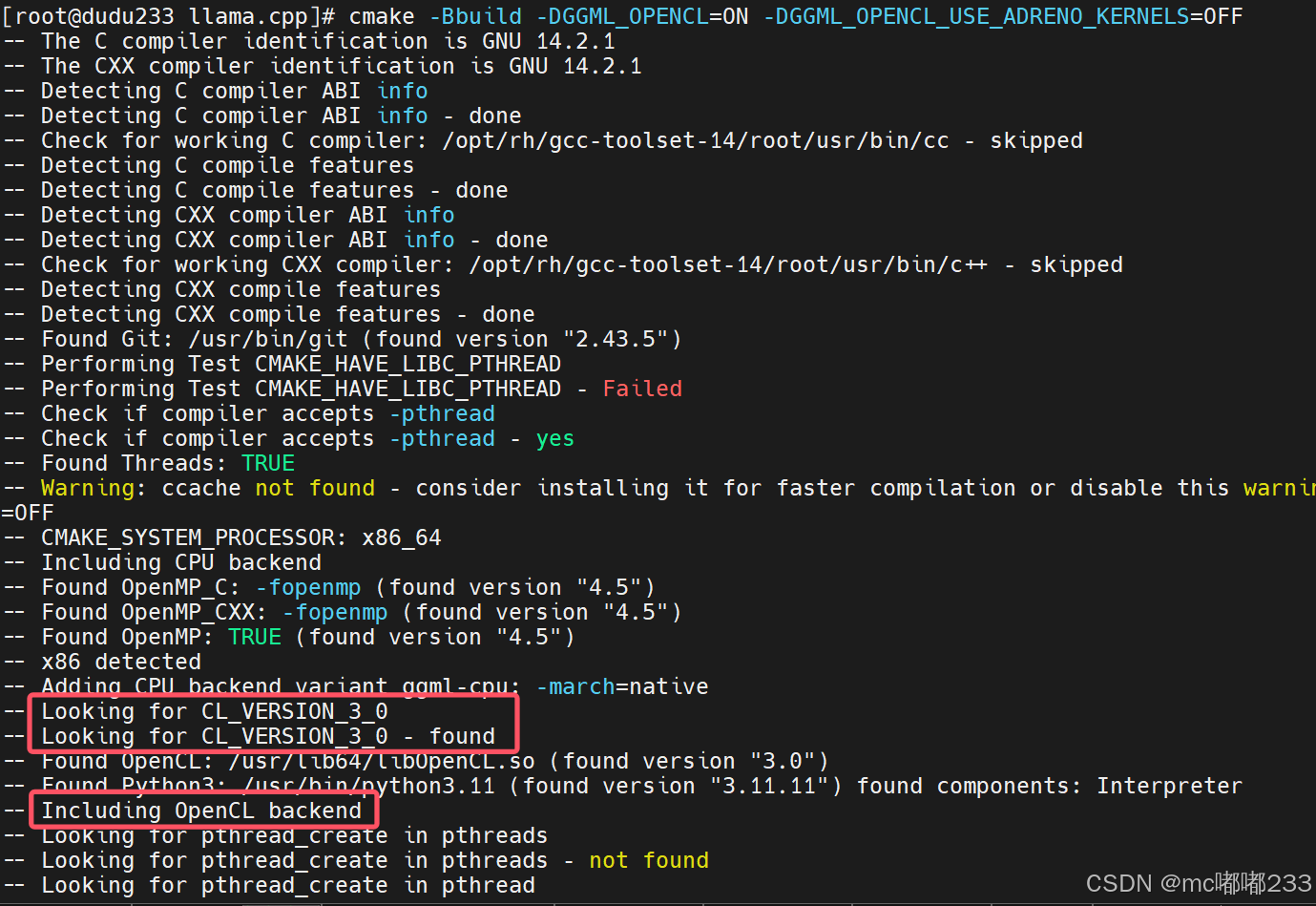
这里必须没有任何报错,llama.cpp是支持OpenCL 3.0和2.2的。我这里采用的是OpenCL3.0,红色的框里面所示。
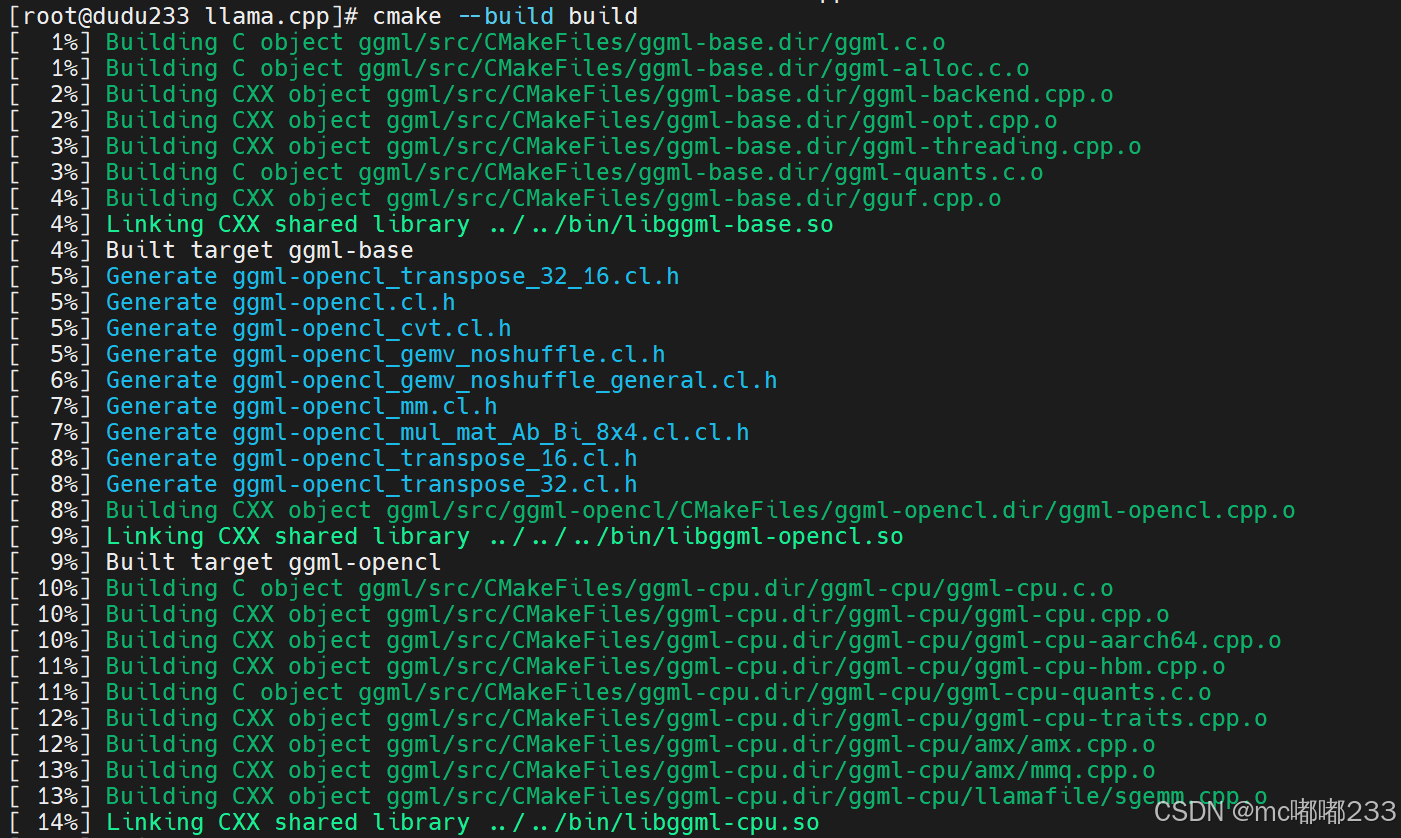
编译也是没问题的,全绿通过。
编译完成后,会出现 build 文件夹,里面的 bin 文件夹下(即 build/bin )就是我们编译好的可运行的 llama.cpp 程序。
运行模型
下载模型
我们到这里下载 DeepSeek-R1-1.5B 的模型。
必须要下载的文件有 model.safetensors 、 config.json 和 tokenizer.json ,或者直接克隆整个项目也行。这三个文件保存到同一个文件夹下,如我保存在了/mnt/disk/models/DeepSeek-R1-1.5B/。
将模型转换成GGUF格式
到上一节的 llama.cpp 的目录下,安装依赖:
pip install -r requirements.txt
然后用以下命令将 safetensors 的文件格式转换成 gguf 的格式。
python3 convert_hf_to_gguf.py /mnt/disk/models/DeepSeek-R1-1.5B/ --outtype f16 --verbose --outfile /mnt/disk/models/DeepSeek-R1-1.5B.gguf
其中/mnt/disk/models/DeepSeek-R1-1.5B/就是刚才模型保存的位置,/mnt/disk/models/DeepSeek-R1-1.5B.gguf是模型输出的位置,为gguf格式。f16是模型的精度,至于这里为什么用半精度浮点,是因为显卡对浮点运算的优化较好。其实大家常用的模型都是q4或者q8的吧。

这里比较慢,取决于硬盘速度,大家要耐心等一下。
运行模型
从刚才的文件夹进入cd build/bin,然后运行:
./llama-cli -m /mnt/disk/models/DeepSeek-R1-1.5B.gguf -p "你是我的助手,要竭尽全力帮我解决我的问题!" -ngl 999 -t 1 -cnv
其中/mnt/disk/models/DeepSeek-R1-1.5B.gguf是模型文件;"你是我的助手,要竭尽全力帮我解决我的问题!"是提示词,可以换成其他的;-ngl 999表示将模型的所有层加载到GPU上;-t 1表示只使用一个CPU线程;-cnv表示使用交互模式。
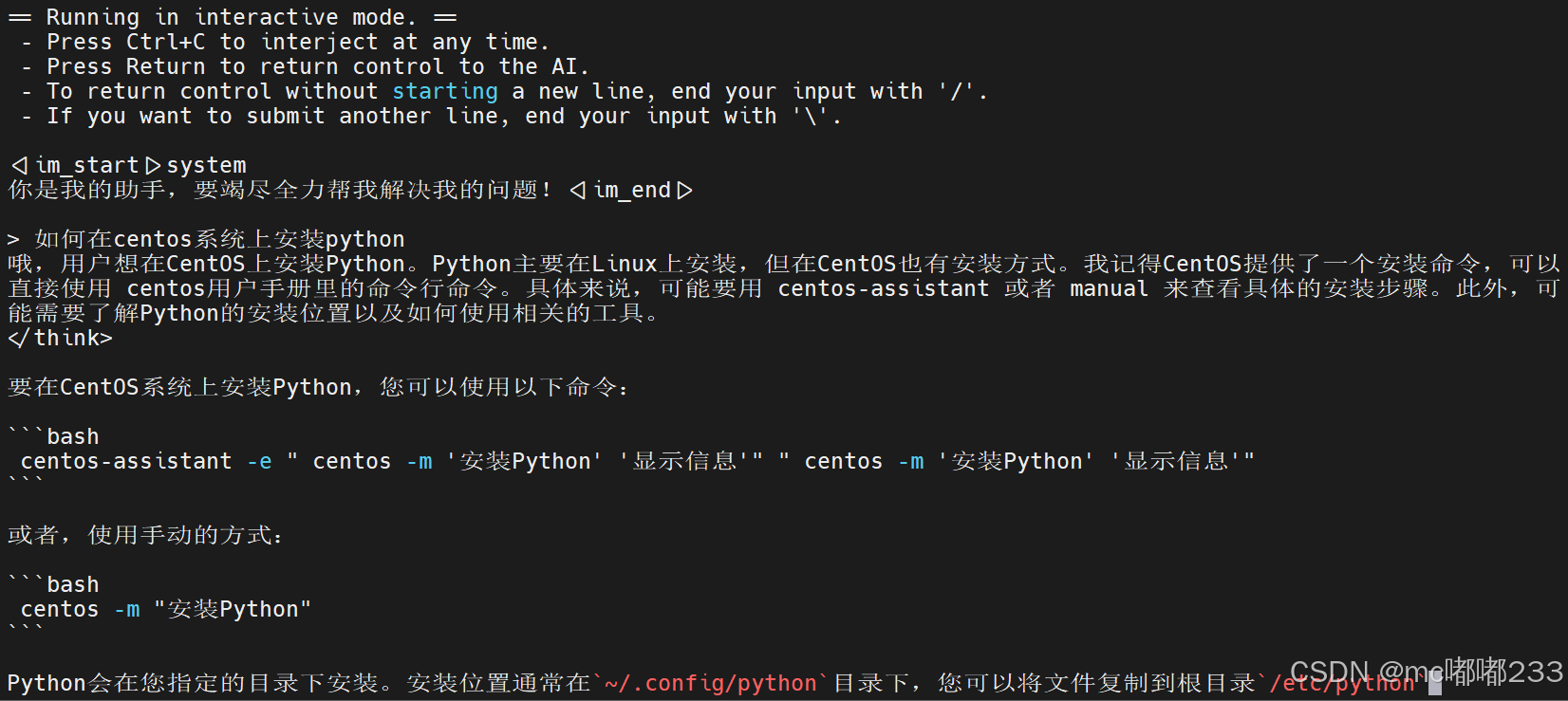
模型加载需要一段时间,等模型加载好后,我们就能问他问题了。比如这里我问了他如何在centos系统上安装python,他会先思考,再回答(推理模型是这样的)、
结果对比
由于采用的模型是F16(半精度浮点)类型的,在CPU上的运算肯定比Q4(4位整数)的模型要慢得多。我这里用了CPU的所有核心(只有4个核心),结果下图所示:

果不其然,只有 0.26 tokens/s (即每秒0.26个token)。
我们再来用核心显卡试试,英特尔的核显是能够跑满的:
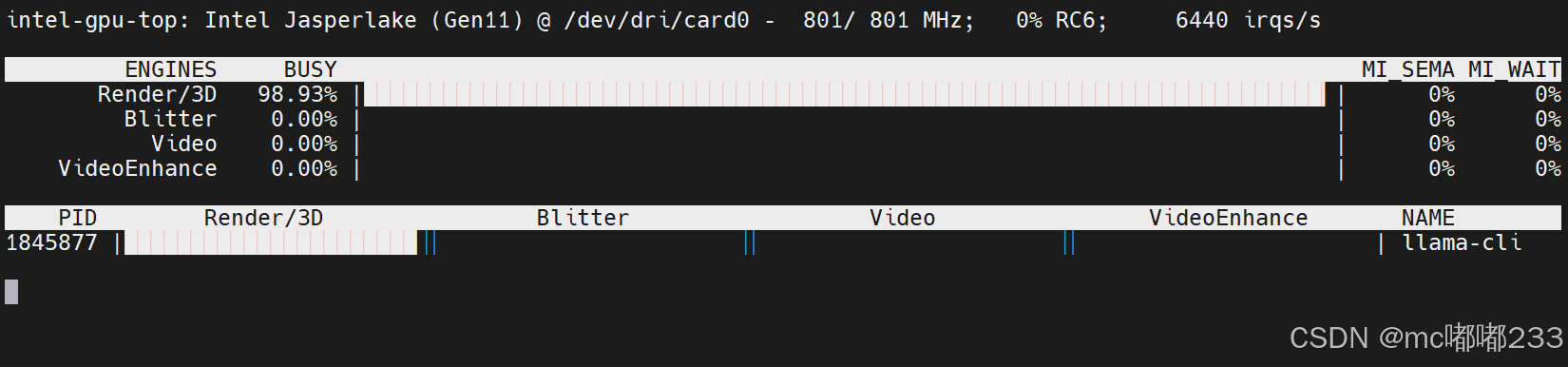
如果你跑不满可能是因为用的模型不是F16类型的,通常显卡运算浮点数据的速度较快。然后我跑模型的速度结果如下图:

这里平均token可以达到每秒4.63,即 4.63 tokens/s 。比CPU的推理速度快了约18倍!
用CPU的核显跑模型何尝不是一种很好的选择呢???


















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









