







 本文详细介绍了如何在Windows 10系统上,针对Intel集成显卡Intel®UHDGraphics620,配置OpenCL开发环境。首先检查显卡是否支持OpenCL,然后下载并安装Intel SDK,接着在Visual Studio 2015中配置OpenCL环境,包括设置附加包含目录、预处理器定义、附加库目录和附加依赖项。最后,提供了主机程序和内核程序的示例代码进行测试。在配置过程中需要注意环境变量与平台的一致性,并解决clCreateCommandQueue函数的警告。
本文详细介绍了如何在Windows 10系统上,针对Intel集成显卡Intel®UHDGraphics620,配置OpenCL开发环境。首先检查显卡是否支持OpenCL,然后下载并安装Intel SDK,接着在Visual Studio 2015中配置OpenCL环境,包括设置附加包含目录、预处理器定义、附加库目录和附加依赖项。最后,提供了主机程序和内核程序的示例代码进行测试。在配置过程中需要注意环境变量与平台的一致性,并解决clCreateCommandQueue函数的警告。
【OpenCL学习】环境配置(Intel)
【OpenCL学习】环境配置(Intel)
最近在做OpenCL的相关调研,花费了一点时间参考博文(环境配置)学习如何配置环境。电脑没有加独立的显卡 ,用的是笔记本自带的Intel® UHD Graphics 620,本文是在windows 10 64位系统上搭建OpenCL的开发环境。
检查显卡是否支持OpenCL
关于电脑的显卡型号以及是否支持OpenCL可以通过下载GPU-Z软件来查看

下载OpenCL
下载Intel SDK,安装步骤很简单,中间只需要自定义安装路径即可。
下载网址:https://software.intel.com/en-us/intel-opencl/download
在Visual Studio 2015配置OpenCL环境
在其他博客中有看到通过配置Microsoft.Cpp.Win32.user的属性达到永久配置的效果,但是尝试了一下没有成功,下面列出来的环境配置方法是针对每个项目来的:
1.打开vs2015新建一个空项目
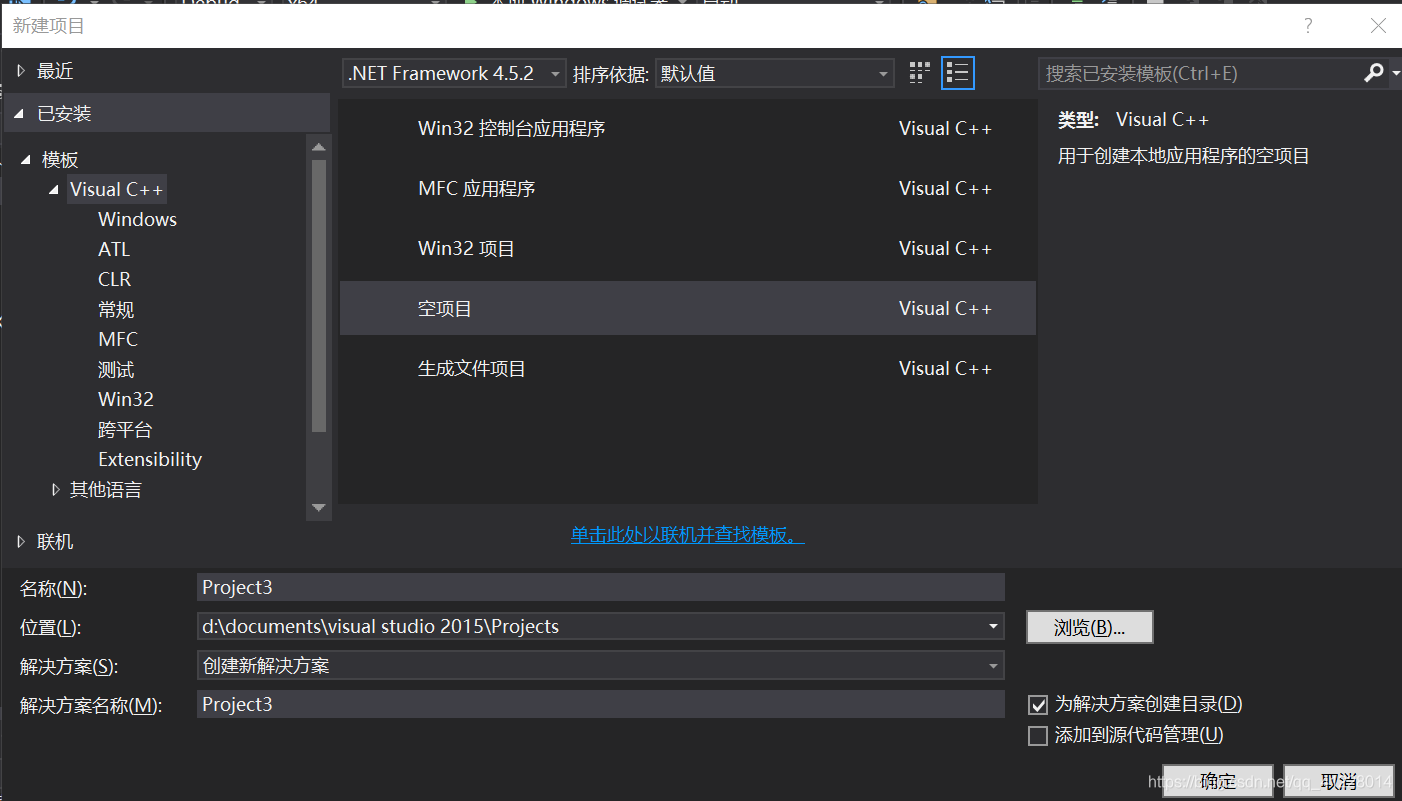
2.配置文件(所需的文件均在上一步下载的SDK中)
(1)将OpenCL的SDK头文件包含到项目中:C/C+±>常规->附加包含目录->添加CL文件夹的目录
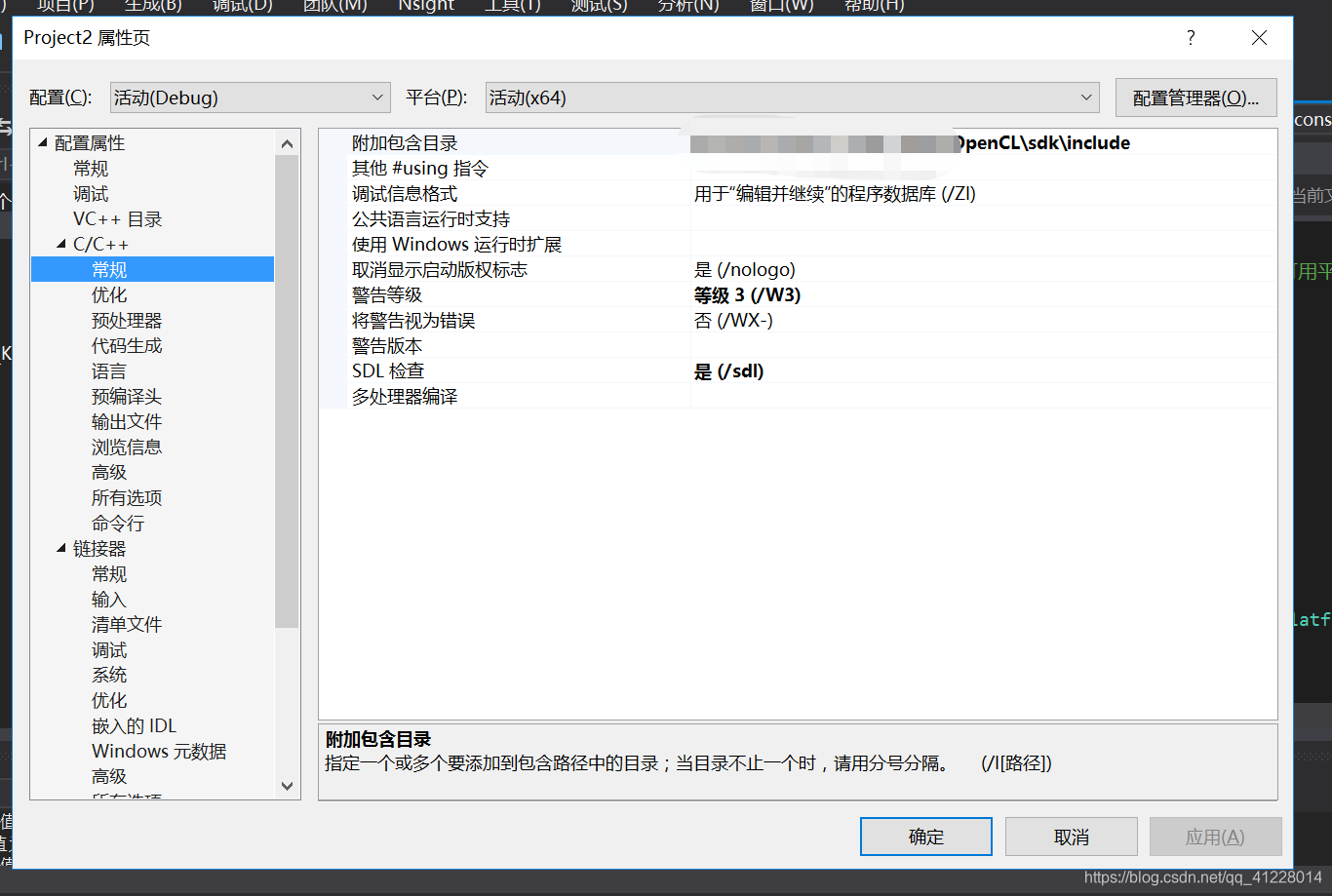
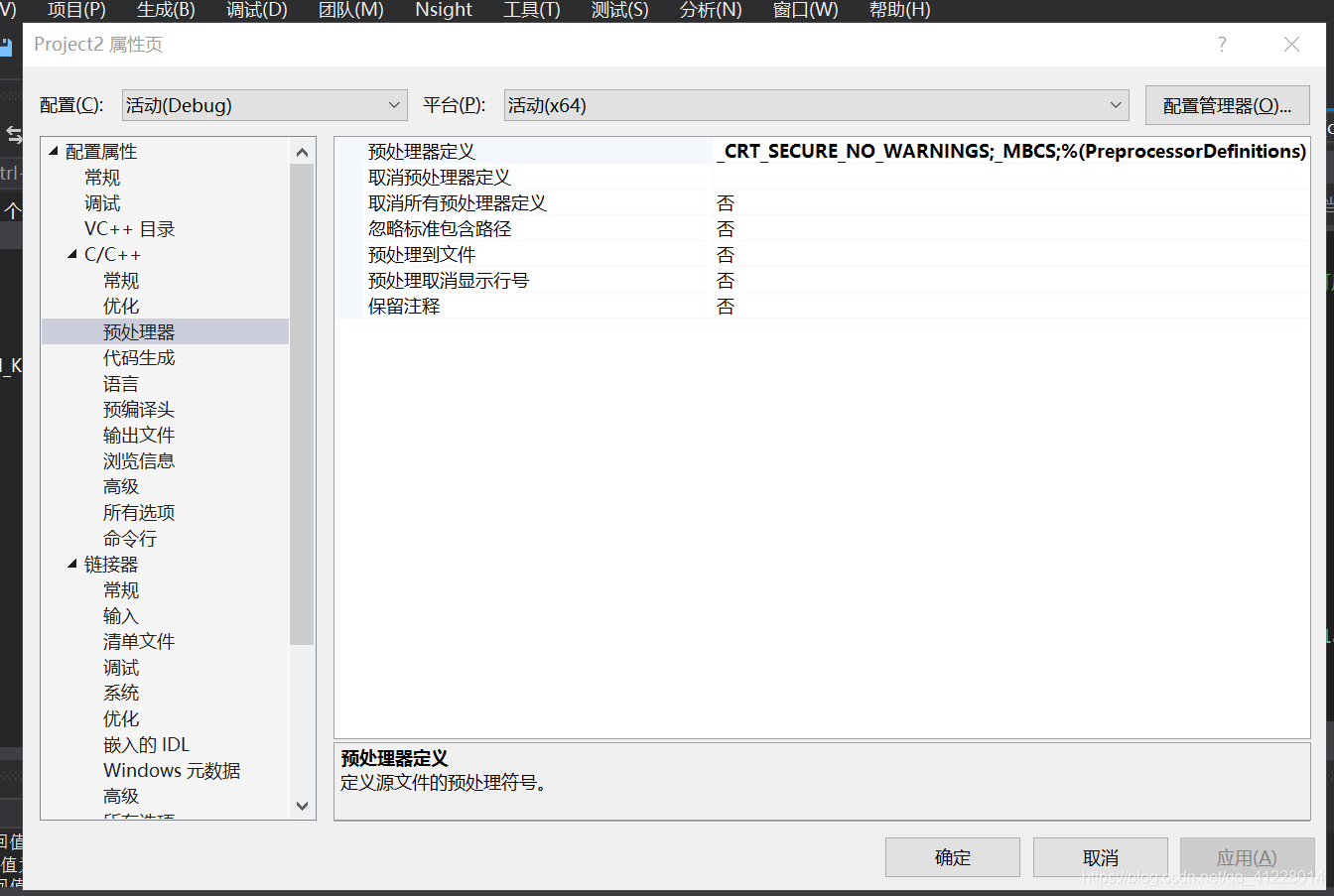
(2)配置预处理器
C/C+±>预处理器->预处理器定义->添加“_CRT_SECURE_NO_WARNINGS",避免编译时的函数报错
(3)配置外部依赖OpenCL.lib目录
链接器 → 常规 → 附加库目录→ 添加OpenCL.lib所在的目录
链接器 → 常规 → 启用增量链接 → 编辑 → 否
32位平台是X86,64位平台是X64
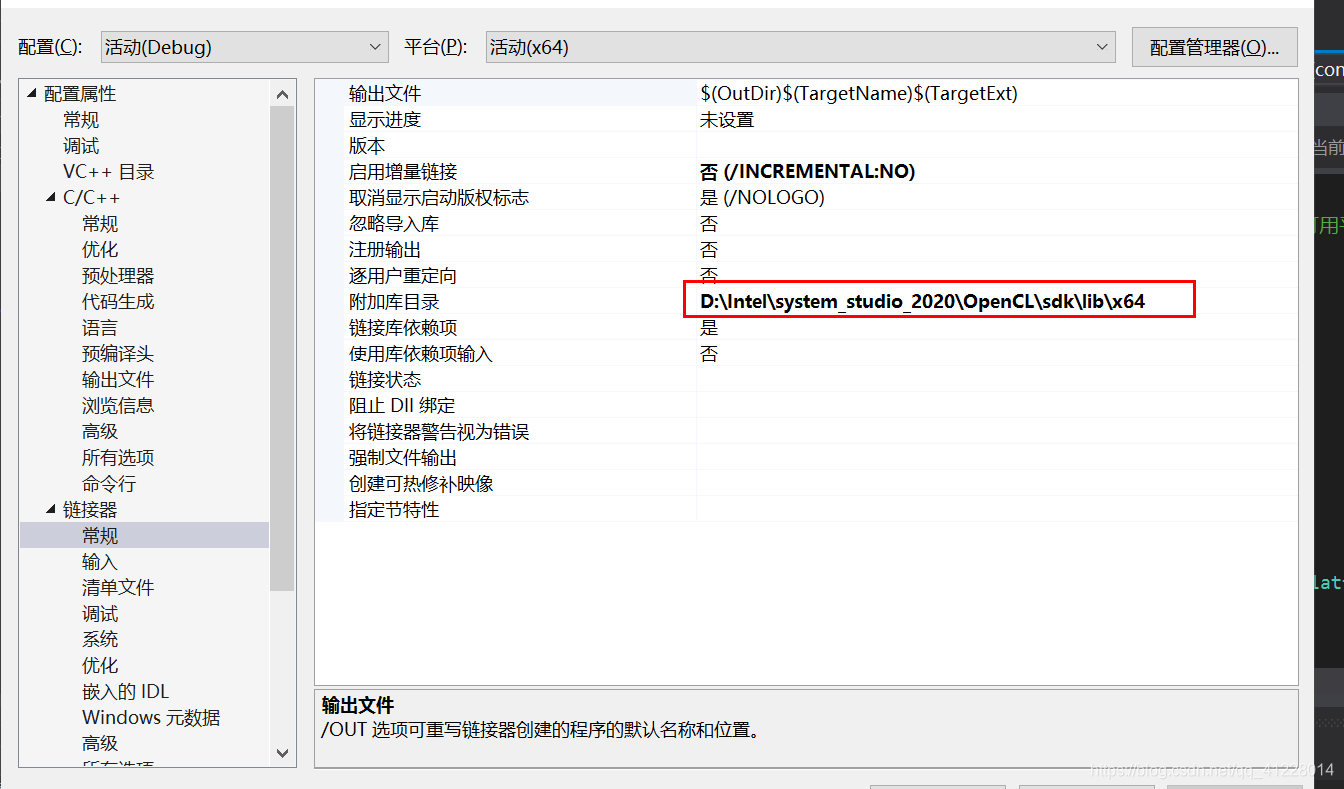
需要注意的是,配置需要与下图所示达成一致

(4)配置OpenCL.lib文件
链接器 → 输入 → 附加依赖项 → 添加“OpenCL.lib”
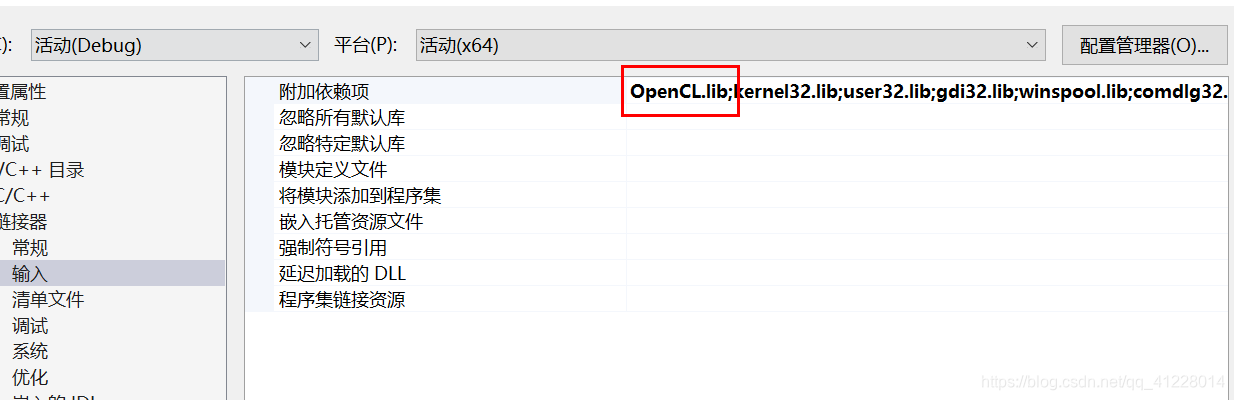
配置完成后保存即可在该项目中进行OpenCL代码的编写和运行
测试
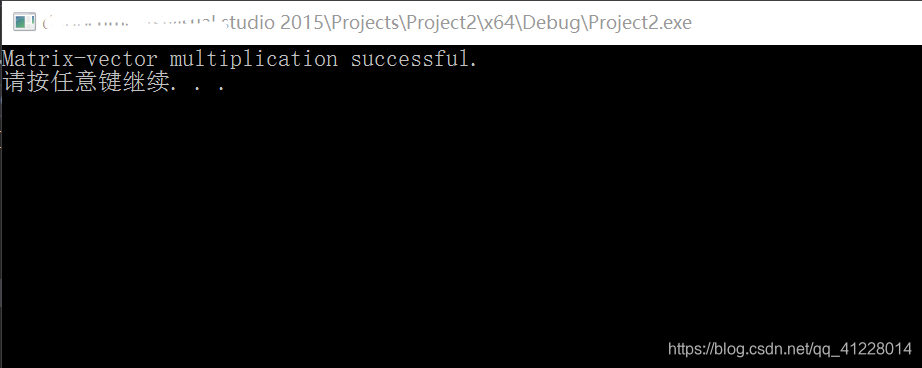
在源文件中添加主机程序(.cpp)和内核程序(.cl),并点击运行,结果如下所示:
主机程序代码
//源.cpp
#define _CRT_SECURE_NO_WARNINGS
#define PROGRAM_FILE "matvec.cl"
#define KERNEL_FUNC "matvec_mult"
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#pragma warning( disable : 4996 )
#ifdef MAC
#include <OpenCL/cl.h>
#else
#include <CL/cl.h>
#endif
int main() {
/* Host/device data structures */
cl_platform_id platform;
cl_device_id device;
cl_context context;
cl_command_queue queue;
cl_int i, err;
/* Program/kernel data structures */
cl_program program;
FILE *program_handle;
char *program_buffer, *program_log;
size_t program_size, log_size;
cl_kernel kernel;
/* Data and buffers */
float mat[16], vec[4], result[4];
float correct[4] = { 0.0f, 0.0f, 0.0f, 0.0f };
cl_mem mat_buff, vec_buff, res_buff;
size_t work_units_per_kernel;
/* Initialize data to be processed by the kernel */
for (i = 0; i<16; i++) {
mat[i] = i * 2.0f;
}
for (i = 0; i<4; i++) {
vec[i] = i * 3.0f;
correct[0] += mat[i] * vec[i];
correct[1] += mat[i + 4] * vec[i];
correct[2] += mat[i + 8] * vec[i];
correct[3] += mat[i + 12] * vec[i];
}
/* Identify a platform */
err = clGetPlatformIDs(1, &platform, NULL);
if (err < 0) {
perror("Couldn't find any platforms");
exit(1);
}
/* Access a device */
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
if (err < 0) {
perror("Couldn't find any devices");
exit(1);
}
/* Create the context */
context = clCreateContext(NULL, 1, &device, NULL, NULL, &err);
if (err < 0) {
perror("Couldn't create a context");
exit(1);
}
/* Read program file and place content into buffer */
program_handle = fopen(PROGRAM_FILE, "r");
if (program_handle == NULL) {
perror("Couldn't find the program file");
exit(1);
}
fseek(program_handle, 0, SEEK_END);
program_size = ftell(program_handle);
rewind(program_handle);
program_buffer = (char*)malloc(program_size + 1);
program_buffer[program_size] = '\0';
fread(program_buffer, sizeof(char), program_size, program_handle);
fclose(program_handle);
/* Create program from file */
program = clCreateProgramWithSource(context, 1,
(const char**)&program_buffer, &program_size, &err);
if (err < 0) {
perror("Couldn't create the program");
exit(1);
}
free(program_buffer);
/* Build program */
err = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
if (err < 0) {
/* Find size of log and print to std output */
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
0, NULL, &log_size);
program_log = (char*)malloc(log_size + 1);
program_log[log_size] = '\0';
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
log_size + 1, program_log, NULL);
printf("%s\n", program_log);
free(program_log);
exit(1);
}
/* Create kernel for the mat_vec_mult function */
kernel = clCreateKernel(program, KERNEL_FUNC, &err);
if (err < 0) {
perror("Couldn't create the kernel");
exit(1);
}
/* Create CL buffers to hold input and output data */
mat_buff = clCreateBuffer(context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR, sizeof(float) * 16, mat, &err);
if (err < 0) {
perror("Couldn't create a buffer object");
exit(1);
}
vec_buff = clCreateBuffer(context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR, sizeof(float) * 4, vec, NULL);
res_buff = clCreateBuffer(context, CL_MEM_WRITE_ONLY,
sizeof(float) * 4, NULL, NULL);
/* Create kernel arguments from the CL buffers */
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &mat_buff);
if (err < 0) {
perror("Couldn't set the kernel argument");
exit(1);
}
clSetKernelArg(kernel, 1, sizeof(cl_mem), &vec_buff);
clSetKernelArg(kernel, 2, sizeof(cl_mem), &res_buff);
/* Create a CL command queue for the device*/
queue = clCreateCommandQueue(context, device, 0, &err);
if (err < 0) {
perror("Couldn't create the command queue");
exit(1);
}
/* Enqueue the command queue to the device */
work_units_per_kernel = 4; /* 4 work-units per kernel */
err = clEnqueueNDRangeKernel(queue, kernel, 1, NULL, &work_units_per_kernel,
NULL, 0, NULL, NULL);
if (err < 0) {
perror("Couldn't enqueue the kernel execution command");
exit(1);
}
/* Read the result */
err = clEnqueueReadBuffer(queue, res_buff, CL_TRUE, 0, sizeof(float) * 4,
result, 0, NULL, NULL);
if (err < 0) {
perror("Couldn't enqueue the read buffer command");
exit(1);
}
/* Test the result */
if ((result[0] == correct[0]) && (result[1] == correct[1])
&& (result[2] == correct[2]) && (result[3] == correct[3])) {
printf("Matrix-vector multiplication successful.\n");
}
else {
printf("Matrix-vector multiplication unsuccessful.\n");
}
/* Deallocate resources */
clReleaseMemObject(mat_buff);
clReleaseMemObject(vec_buff);
clReleaseMemObject(res_buff);
clReleaseKernel(kernel);
clReleaseCommandQueue(queue);
clReleaseProgram(program);
clReleaseContext(context);
system("pause");
return 0;
}
内核程序代码:
//matecv.cl
__kernel void matvec_mult(__global float4* matrix,
__global float4* vector,
__global float* result) {
int i = get_global_id(0);
result[i] = dot(matrix[i], vector[0]);
}
##遇到的问题
1.需要保持配置的OpenCL.lib目录与解决方案配置和平台保持一致,否则会出现系统找不到指定exe文件的报错:
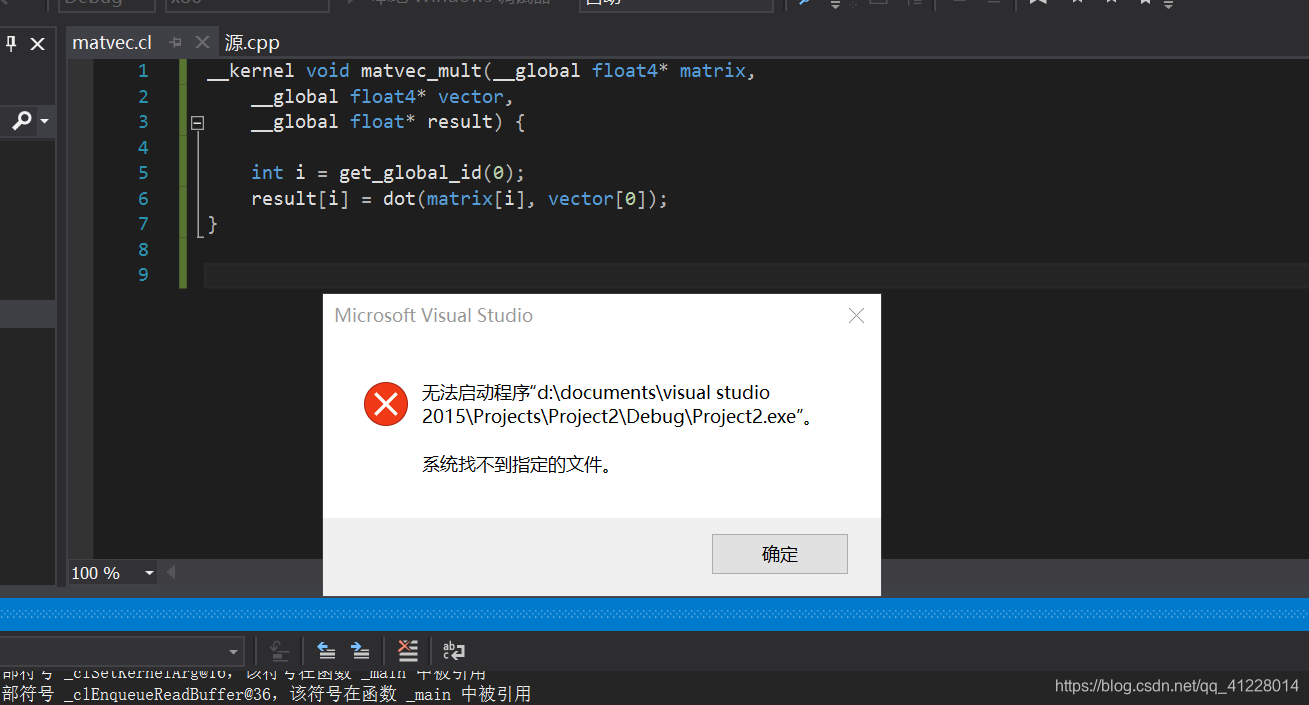
2.在OpenCL2.0中clCreateCommandQueue函数已经被弃用了,需要在使用前#pragma warning( disable : 4996 )来避免报错

以上就是整个环境的搭建过程,如有问题,请提出~
禁止转载
作者:Isla

















 8316
8316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









