






Current statistical machine translation systems
源语言:法语
目标语言:英语
概率公式(利用贝叶斯定理):
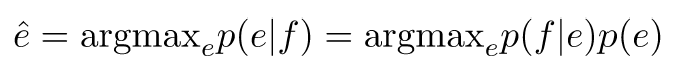
在平行语料库(parallel corpora)上训练翻译模型p(f|e)
在英语语料库上训练语言模型p(e)
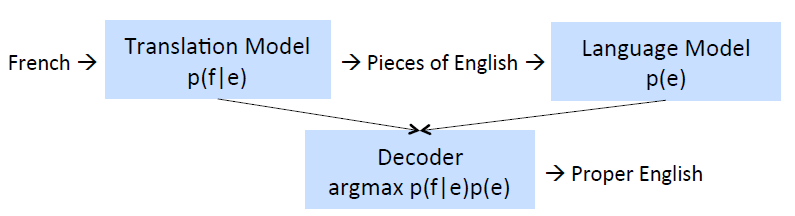
Step1: Alignment
目标:将源语言中的单词或者短语匹配到正确的目标语言中的单词或者短语
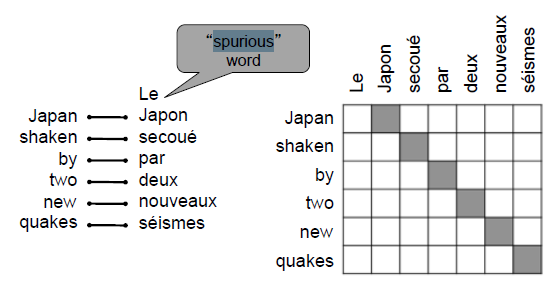
假如匹配好了单词和短语,那么又如何给这些单词和短语重新排序呢?
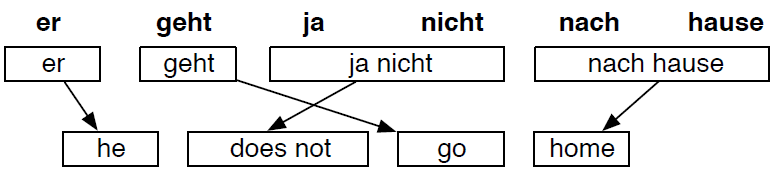
After many steps
每个源语言中的单词或者短语,在目标语言中都有不止一个相匹配的单词或者短语:
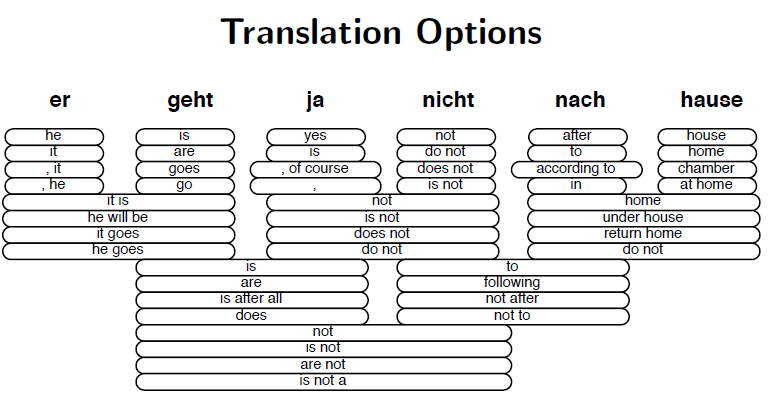
Decode: Search for best of many hypotheses
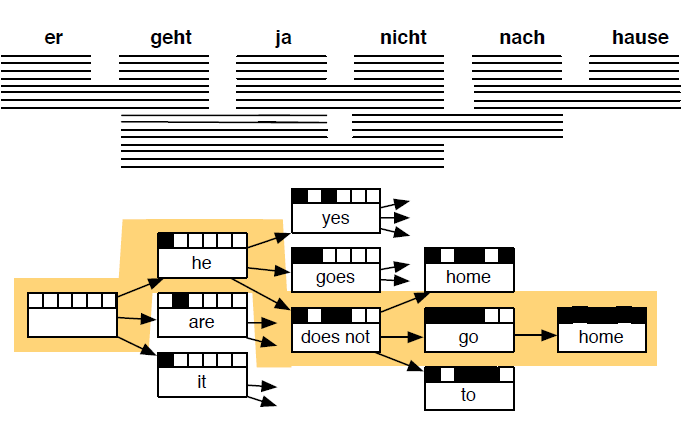
TradiBonal MT(Machine Translation)
直接跳过非常多的细节部分
需要非常多的人工处理特征信息
非常复杂的系统
Deep learning to the rescue! … ?
也许我们能直接使用RNN做机器翻译
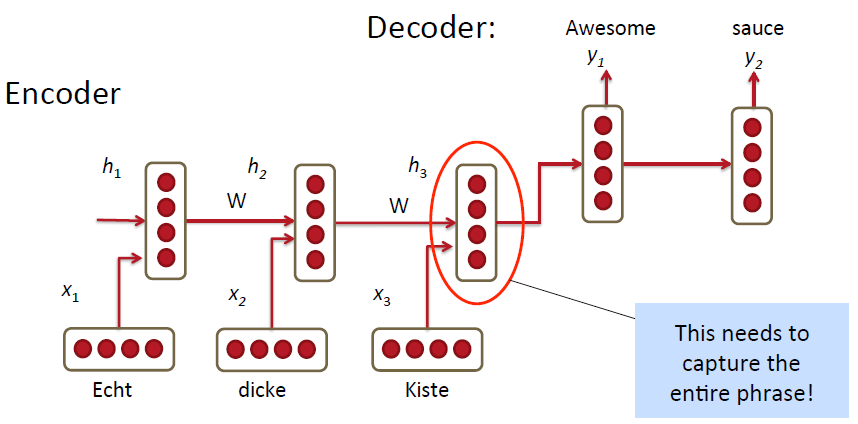
MT with RNNs – Simplest Model
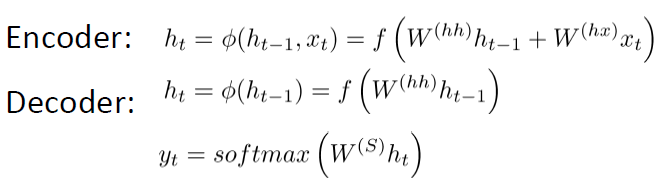
最小化基于源语言,对应的目标语言中的词的交叉熵:
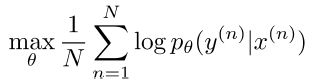
然而并没有这么的简单:)
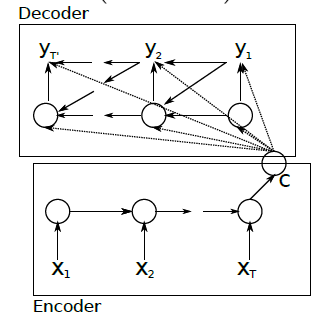
RNN Translation Model Extensions
1)decoding和encoding部分,训练得到的RNN的Weeights是不一样的:
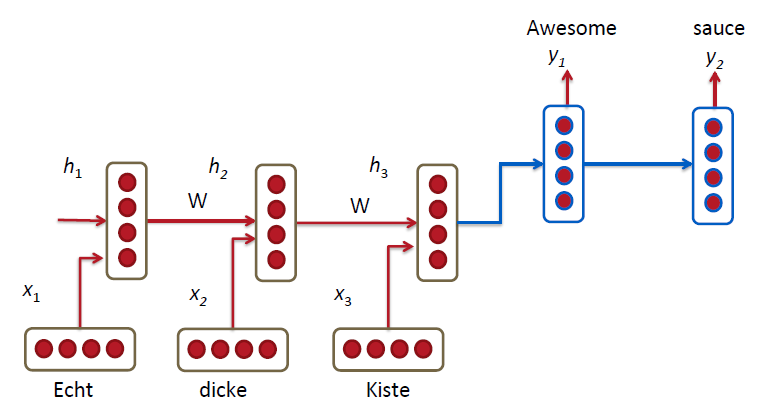
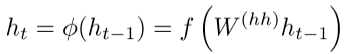
2)在解码时,根据下面的三项计算当前的hidden层:
1.之前的hidden层
2.上一个编码器的hidden层:c=hT
3.之前预测得到的词yt-1
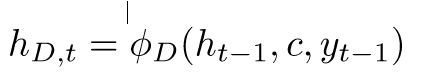
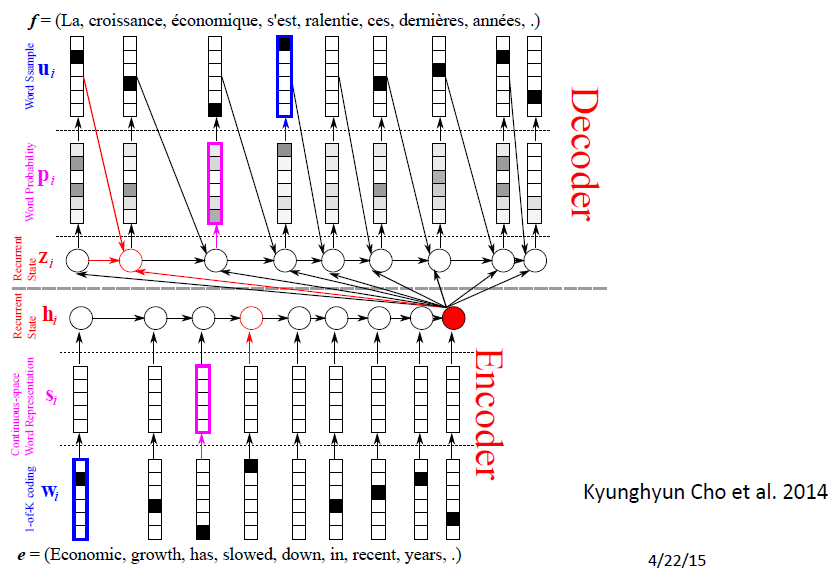
对上一幅图更详细的描述
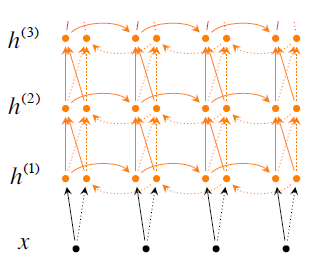
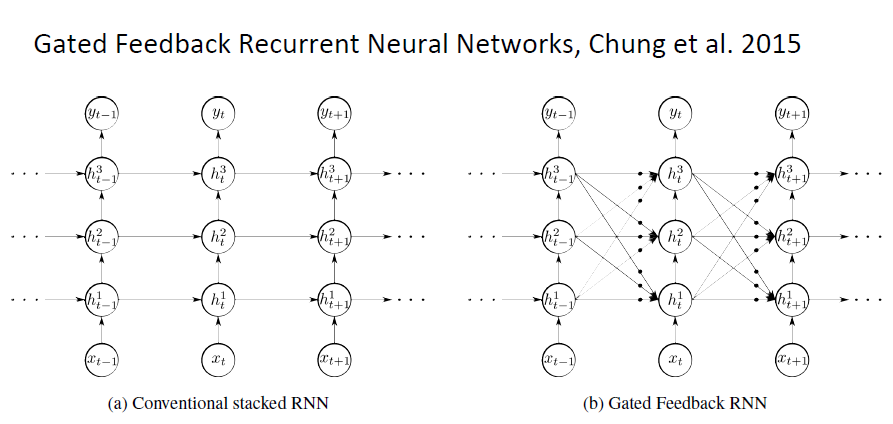
3)训练多层 stacked/deep RNNs
4)也可训练双向RNN
5)将输入序列反向后训练,以使得优化更加简单,如:A B C-》X Y换成C B A-》X Y
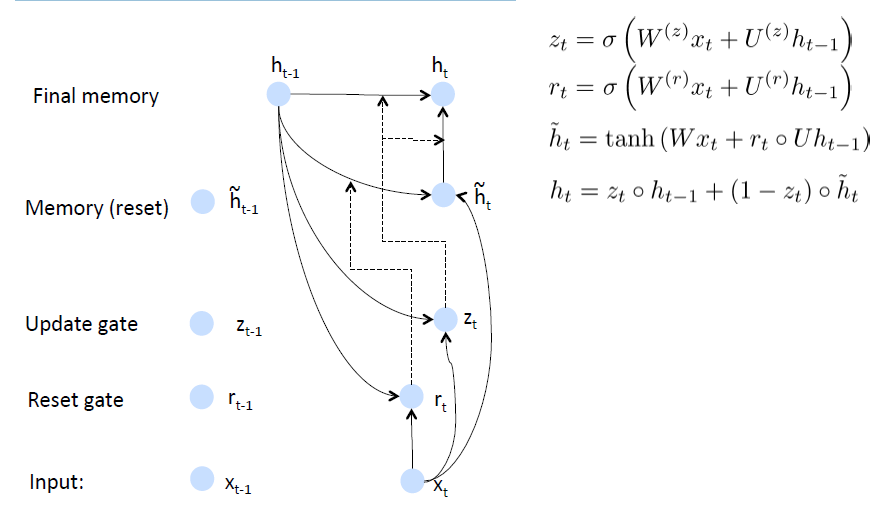
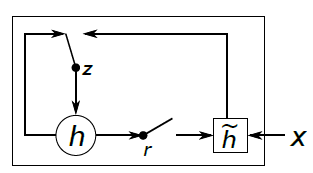
6)Main Improvement: Better Units。在循环的时候使用更加复杂的hidden units,如Gated Recurrent Units(GRU)
GRUs
标准的RNN直接计算下一个time step的hidden layer:
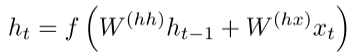
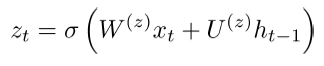
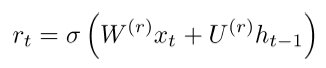
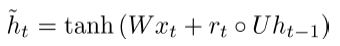
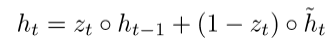
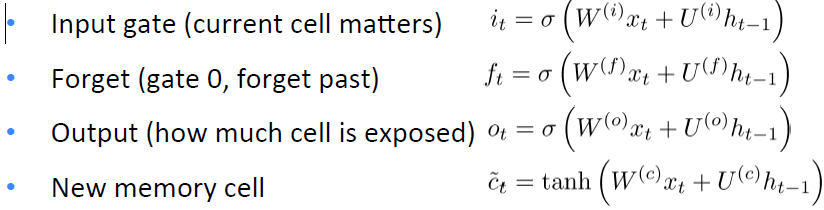
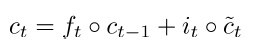
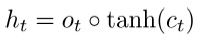
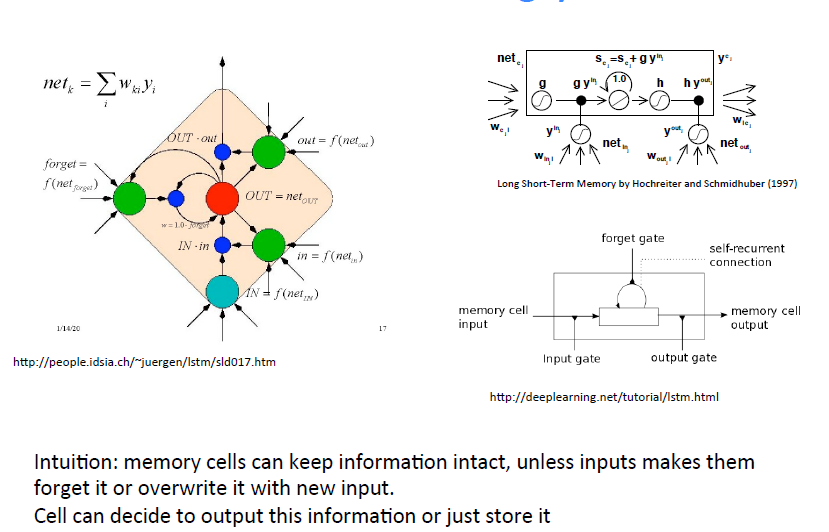
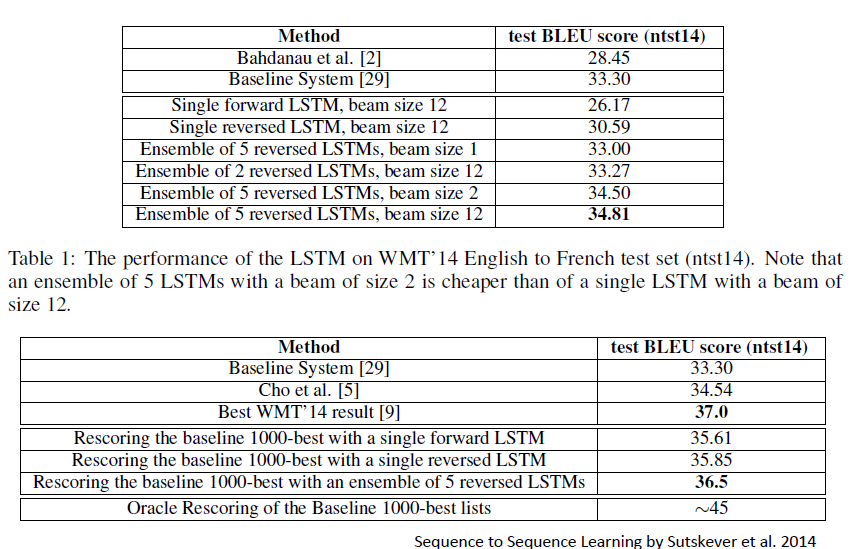















 9586
9586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









