







什么是交叉熵
交叉熵(Cross-entropy)是信息论中一个常用的度量方式,常用于衡量两个概率分布之间的差异。在机器学习中,交叉熵常用于衡量真实概率分布与预测概率分布之间的差异,用于评估分类模型的性能。
假设有两个概率分布 P 和Q,则它们的交叉熵为:
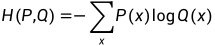
其中,P(x) 表示事件 x 在真实分布中的概率,Q(x) 表示事件x 在预测分布中的概率,log 表示自然对数。交叉熵越小,表示预测分布越接近真实分布,模型的性能越好。
机器学习中的交叉熵
在机器学习中,交叉熵常常被用作损失函数,用于训练分类模型。以二分类问题为例,假设 y 是真实标签$p 是模型对 y=1 的预测概率,则交叉熵损失函数为:
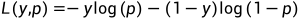
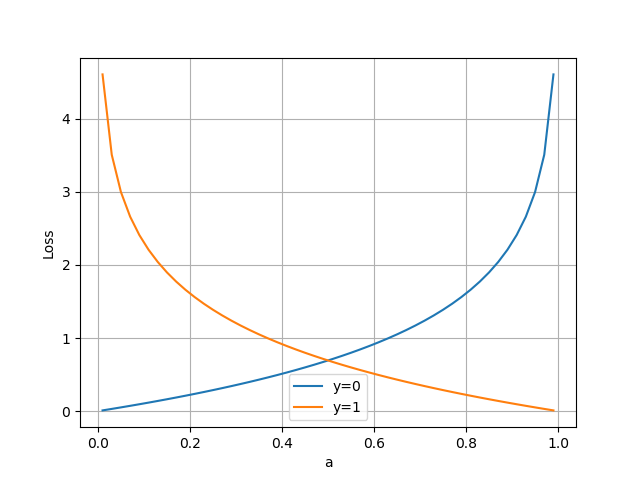
当 $y=1$ 时,损失函数变为 $-\log(p)$,当 $y=0$ 时,损失函数变为 $-\log(1-p)$。这个损失函数可以解释为:如果模型预测 $y=1$ 的概率越接近真实值 $y=1$,则损失函数越小,否则损失函数越大。同理,如果模型预测 $y=0$ 的概率越接近真实值 $y=0$,则损失函数也越小,否则损失函数也越大。
对于多分类问题,交叉熵损失函数可以表示为:
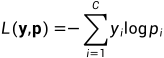
其中,C 是类别数,y 是真实标签的 one-hot 编码,p 是模型对每个类别的预测概率。同样的,如果模型对真实标签的预测越接近,损失函数越小,否则损失函数越大。
交叉熵损失函数的优点在于,它不仅可以用于训练分类模型,还可以用于训练神经网络模型。在神经网络中,交叉熵损失函数可以用来衡量网络输出和真实标签之间的差异,通过反向传播算法更新网络参数,从而优化模型。交叉熵损失函数还具有平滑性和凸性质,能够保证优化过程的稳定性和收敛性。
损失值与预测值的函数图















 4601
4601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









