







文心一言
交叉熵(Cross Entropy)是Shannon信息论中的一个重要概念,主要用于度量两个概率分布间的差异性信息。具体来说,交叉熵是表示两个概率分布p和q之间的差异性,其中p表示真实分布,q表示非真实分布或模型预测的分布。交叉熵的定义为:H(p,q)=−∑i=1npilog(qi),其中p_i表示真实分布中第i个事件发生的概率,q_i表示模型预测分布中第i个事件发生的概率。
在深度学习中,交叉熵是一种常用的损失函数,用于衡量模型的预测与真实值之间的差距。这种差距越小,表示模型预测的结果与真实结果越接近。因此,通过最小化交叉熵损失函数,可以指导模型的优化,提高模型的预测性能。
交叉熵在深度学习中有广泛的应用,尤其适用于分类任务。根据不同的任务类型,交叉熵还可以进一步分为对数损失(Log Loss)、平滑对数损失(Smooth Log Loss)、平均交叉熵损失(Average Cross-Entropy Loss)等。这些不同的形式可以更好地适应不同类型的任务和数据集。
总的来说,交叉熵在深度学习中起到了衡量模型预测性能的作用,通过最小化交叉熵损失函数,可以优化模型参数,提高模型的预测精度。
智谱清言
交叉熵(Cross-Entropy)是一种衡量预测分布与真实分布之间差异的指标,常用于分类问题中评估模型的性能。在深度学习中,交叉熵损失函数用于训练模型,使模型的预测尽可能接近真实的标签分布。
交叉熵的定义
交叉熵源于信息论,是两个概率分布之间的差异的度量。对于一个分类问题,我们有一个真实的标签分布(即正确的答案),以及模型生成的预测分布。交叉熵损失函数计算这两个分布之间的差异。
在深度学习中的使用
在深度学习中,尤其是在神经网络中,交叉熵通常作为损失函数来使用,其目的是通过反向传播算法来优化网络的权重。
交叉熵损失函数
对于一个有C个类别的分类问题,假设我们的模型输出一个概率分布p(即p(y=c|x),其中y是真实的标签,c是类别,x是输入数据),真实的标签分布是一个one-hot编码的向量t(如果y=c,则t[c]为1,否则为0)。交叉熵损失函数L计算如下:
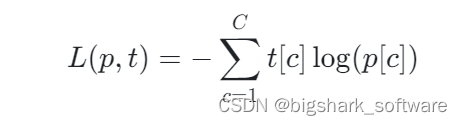
这里\log是自然对数。损失值是负的,因为我们要最大化p和t之间的相似性,而\log函数是递减的,所以我们可以通过最小化损失函数来最大化相似性。
在反向传播中的作用
在训练过程中,通过前向传播计算预测概率p,然后计算交叉熵损失L。接着,使用损失函数的梯度来更新网络的权重,这个过程称为反向传播。交叉熵损失函数的梯度指导了权重的更新,使得模型在接下来的数据上产生更准确的预测。
应用
在实际应用中,交叉熵损失函数广泛用于各种深度学习任务,如图像识别、自然语言处理、语音识别等,特别是在多分类问题中。
总结
交叉熵在深度学习中的使用是为了让模型的预测尽可能地接近真实的标签分布。它通过计算预测概率分布和真实分布之间的差异来评估模型的性能,并通过反向传播算法来优化网络参数,以减少这种差异。
豆包
交叉熵是 Shannon 信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。在深度学习中,交叉熵常用于衡量模型预测的概率分布与真实标签的概率分布之间的差异,特别用于分类问题的损失函数。通过最小化交叉熵,可以帮助模型更好地拟合训练数据,并提高分类性能。
在深度学习中,可以使用 CrossEntropyLoss API 实现交叉熵损失函数。例如,在 PyTorch 中,可以使用以下代码计算交叉熵损失:
收起
python
import torch.nn.functional as F
# 假定预测概率分布和真实概率分布分别为 pred 和 target
loss = F.cross_entropy(pred, target)
其中,pred 是模型的预测概率分布,target 是真实标签的概率分布。
需要注意的是,交叉熵损失函数在类别不平衡的数据集中可能会存在一些问题,例如对多数类别过于关注,导致模型性能下降。此外,交叉熵损失函数对输出概率分布的平滑性要求较高,如果输出概率分布过于离散,可能会导致损失值较大。
讯飞星火
交叉熵在深度学习中通常作为损失函数使用,用于衡量模型预测与真实标签之间的差异。
交叉熵是信息论中的一个概念,它用来衡量两个概率分布之间的差异。在深度学习中,我们通常使用它来表示预测分布和真实分布之间的差异。以下是交叉熵在深度学习中的一些具体应用:
- 二分类问题:在二分类问题中,交叉熵损失函数可以表示为
Loss = -y*log(\hat{p}) - (1-y)*log(1-\hat{p}),其中y是真实标签(0或1),\hat{p}是模型预测为正类的概率。 - 多分类问题:对于多分类问题,交叉熵损失函数会涉及到每个类别的预测概率和实际标签,用于衡量在一个类别上的预测准确度。
- 生成对抗网络:在生成对抗网络(GANs)中,交叉熵用于衡量生成数据分布和真实数据分布之间的差异,以此来训练判别器更好地区分真实和生成的数据。
- 自然语言处理:在自然语言处理领域,交叉熵常用于衡量语言模型的性能,即通过比较模型分布和训练集上的真实分布来衡量模型的正确率。
此外,选择交叉熵作为损失函数还因为它具有一些优点。例如,它的梯度计算相对简单,这在反向传播算法中非常有用。同时,交叉熵损失函数对异常值不太敏感,这使得模型更加稳健。
总的来说,交叉熵在深度学习中主要作为损失函数,用于评估和优化模型的性能,尤其在分类问题和生成模型中发挥着重要作用。通过最小化交叉熵损失,我们可以调整模型参数以更好地拟合数据,从而提高模型的预测准确性。















 1587
1587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











