







记录一下这周看的论文
这周的论文其实说还挺好。
《图卷积神经网络的可解释方法》
首先的话先说一下这个可解释方法是什么意思吧,其实开始我也是不懂,我是在网上找得相关资料才得知的。
就是说,可解释方法在最开始是针对CNN提出的。我在网上的一篇文章看到的写得很好原文出处请点击:
在当前深度学习的领域,有一个非常不好的风气:一切以经验论,好用就行,不问为什么,很少深究问题背后的深层次原因。从长远来看,这样做就埋下了隐患。举个例子,在1980年左右的时候,美国五角大楼启动了一个项目:用神经网络模型来识别坦克(当时还没有深度学习的概念),他们采集了100张隐藏在树丛中的坦克照片,以及另100张仅有树丛的照片。一组顶尖的研究人员训练了一个神经网络模型来识别这两种不同的场景,这个神经网络模型效果拔群,在测试集上的准确率尽然达到了100%!于是这帮研究人员很高兴的把他们的研究成果带到了某个学术会议上,会议上有个哥们提出了质疑:你们的训练数据是怎么采集的?后来进一步调查发现,原来那100张有坦克的照片都是在阴天拍摄的,而另100张没有坦克的照片是在晴天拍摄的……也就是说,五角大楼花了那么多的经费,最后就得到了一个用来区分阴天和晴天的分类模型。
当然这个故事应该是虚构的,不过它很形象的说明了什么叫“数据泄露”,这在以前的Kaggle比赛中也曾经出现过。大家不妨思考下,假如我们手里现在有一家医院所有医生和护士的照片,我们希望训练出一个图片分类模型,能够准确的区分出医生和护士。当模型训练完成之后,准确率达到了99%,你认为这个模型可靠不可靠呢?大家可以自己考虑下这个问题。
好在学术界的一直有人关注着这个问题,并引申出一个很重要的分支,就是模型的可解释性问题。那么本文从就从近几年来的研究成果出发,谈谈如何让看似黑盒的CNN模型“说话”,对它的分类结果给出一个解释。注意,本文所说的“解释”,与我们日常说的“解释”内涵不一样:例如我们给孩子一张猫的图片,让他解释为什么这是一只猫,孩子会说因为它有尖耳朵、胡须等。而我们让CNN模型解释为什么将这张图片的分类结果为猫,只是让它标出是通过图片的哪些像素作出判断的。(严格来说,这样不能说明模型是否真正学到了我们人类所理解的“特征”,因为模型所学习到的特征本来就和人类的认知有很大区别。何况,即使只标注出是通过哪些像素作出判断就已经有很高价值了,如果标注出的像素集中在地面上,而模型的分类结果是猫,显然这个模型是有问题的)
所以,可解释方法的意思就是告诉人们,这个模型判断出这个图片分类是猫,那么它的依据是什么。这个就是可解释方法的意思。详细的可以看上面的文章,写得很好。受益匪浅。
然后就是目前针对CNN的可解释方法主要就几种,也就是文中类比迁移到GCNN的几种方法
1,基于对比梯度显著图(Contrastive gradient-based saliency maps)
2,类激活映射(Class Activation Mapping)
3,(Grad-CAM)
4,激励反向传播(Excitation Backpropagation)
以上就是几种针对于CNN的几种可解释方法,然后作者就是在以上的基础上,针对GCNN也提出了基于以上方法的可解释方法。
下面就开始看论文。
1.引言
在CNN的几种可解释方法的启发下,作者把几种可解释方法扩展到了GCNN。做出的贡献如下:
(1)将CNN的可解释性方法扩展到为GCNN,
(2)展示了两个图形分类问题的可解释性技术:视觉场景图和分子
(3)使用以下指标表征每种方法的权衡,保真度,对比度和稀疏度。
2.相关工作
2.1 可解释性
其实就是开始上面我说的,看了上面也就知道可解释性是什么了。
2.2.图卷积神经网络
文中只是简单的介绍了一下图卷积神经网络,如果不了解的,可以看一下这篇文章,写得很好如何理解GCNN
3.方法
3.1CNN的可解释性
目前流行的有3种方法
1,梯度对比
2,CAM
3,EB
首先是梯度对比的方法

这是梯度对比方法的公式,公式中:
y是softmax层之前对于c类的得分,x是输入,那么说公式之中小括号里面的就是对于分类得分求输入x的梯度。求出的梯度的话其实就是代表对于分类得分这个输入x这个像素点对其的重要性。由于我们是要想知道该像素点对分类结果的影响,那么我们就是要最大的正变化率。你如果改像素点求出的梯度是负的,那就是可以理解为对分类结果的影响没有关系,所以我们不需要考虑。所以我们就需要取绝对值。然后终上所述,就是对于输入图片的每一个像素点都求出其梯度通过激励函数,求绝对值,然后我们便可以得出a heat-map。类似于,这种:

如上图:下面图中的白色点点,就可以看做事我们这个模型判断图片是狗还是船的依据。
然后是CAM(Class Activation Mapping)类激活映射如何理解CAM
类激活映射原理是利用一种特殊的卷积神经网络结构生成可视化热力图
类激活映射有固定的结构,就是卷积层,全局池化层,softmax层
如下:


上诉公式e就是全局池化层之后得到的F特征的均值。F代表的是第K个特征图的第(i,j)坐标像素点的特征,意思就是把第K个特征图的所有坐标的特征求均值得到e,Z代表像素个数。

y代表分类得分,意思是分类得分是所有K歌特征图上的均值乘以相对应的权重w,w指对应特征的权重参数,这个是可以通过网络进行学习的。然后目的就是学习出权重参数w。有了w我们在直接用w和原特征图相乘。我们就能得到一张像素空间之中的热力图了。就像是这种:

上图就是图中有狗狗和猫咪,然后模型判断猫咪的依据就是以上带颜色的部分,计算方法就是通过公式4进行计算的:
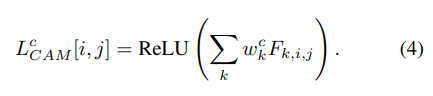
然后是Grad-CAM方法
Grad-CAM里面的权重a是通过梯度反向传播确定的。
权重初始化公式5:

在求出权重a之后和CAM类似的有公式6
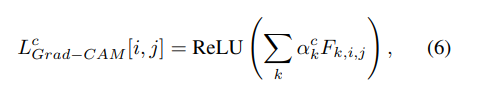
通过公式6的计算就能得到和CAM一样的一个像素空间的热图。
最后就是计算反向传播(EB)
例如,a(l-1)是上一层的神经元,a(l)是当前的神经元,然后定义a(l-1)对于a(l)激活yl的影响。其中有:

W是权重,然后P(aj)是作为上一个神经元的概率分布,这种概率分布可以分解为:
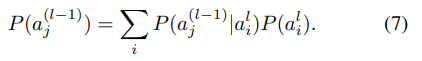
公式中的条件概率分布可以定义为:
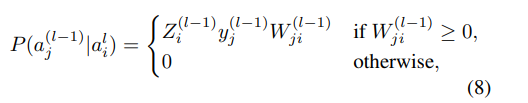
其中

Z是一个标准化因子,y和w在网络训练的时候已经就知道了 ,所以可以直接带进去算概率分布。
例如,对于给定的输入,然后从输出层的P(ali)=1开始计算,运用公式7,公式8 递归运算上一次层的概率分布,直到最开始的神经元,到最开始的神经元之后,可能说例如这个最开始的神经元是通过图像卷积得到的,那么我们就反卷积回去,就可以形成了一个像素空间上的热图了。
接下来就是讨论GCNN中的可解释性方法了。
首先讨论GCNN的描述,然后在讨论GCNN的可解释性方法。
3.2GCNN
节点属性X,和邻接矩阵A,还有度矩阵D,根据之前的文章定义图卷积公式:

F是代表卷积激活函数,W是权重,其中:

A一把是指其邻接矩阵加上自连接,因为In是单位阵嘛就是邻接矩阵的对角线都变成了1.
对于给定的分子数据集有

y是标签,前面是图结构,任务是将每个分子分类到自己的标签。
考虑到我们的任务是对具有潜在不同节点数的单个图(即分子)进行分类,我们使用几个图卷积层,然后在图节点(如原子)上使用全局平均池化(global average pooling,GAP)层。在这种情况下,所有图都将用固定大小的向量表示。最后,将GAP特征输入(feed)分类器。为了使CAM的适用性,我们在GAP层之后使用了一个Softmax分类器。
如图1

3.3GCNN的可解释性方法
将第l层的第K个特征图定义为:

然后在卷积层之后的GAP特征计算为:
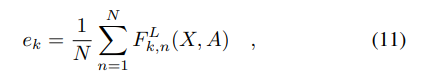
其中的F代表第n各节点的第l层的第k个特征图
然后类得分的计算为
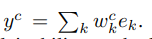
基于以上的公式 我们拓展了GCNN的可解释性方法如下:
Gradient-based:
节点n的热图为:

CAM的热图:
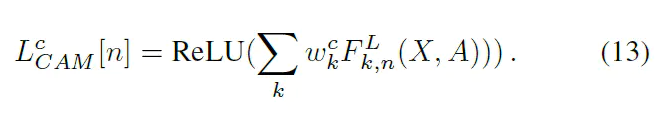
Grad-CAM’的热图,对于节点n在第l层上的第K个特征图上的权重计算为:

然后在第l层上节点N的热图为

上面是对于每一层节点N的热图,然后在本次工作中,我们用所有层的均值作为结果:

因为以上公式里面的参数在训练的时候都已经知道了,所以直接带入计算就可以了。
Excitation Backpropagation’:
通过对Softmax分类器、GAP层和几个图卷积层的反向传递,计算模型的激活反向传播热图。通过Softmax分类器和GAP层的向后传递方程如下:
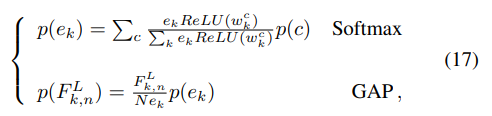
在这里P©=1如果是感兴趣的类,否则为0.意思就是在正向传播里面我们经过softmax层之后是一个0~1之间的数字,那么就有一个最大的数字,这个最大的数字就代表最有可能属于哪一个类。那我反向传播的时候就这个类的P就为1带入公式计算。在反向传播计算完SOFTAMX层和GAP层之后,就要反向计算图卷积层了。因为图卷积层很复杂。为了简化,我们分解一个图卷积算子为:

就是把图卷积公式分为了两部分,标准化的部分,和后面乘以权重的部分。第一个公式是指局部均值,后面一个公式是指每个原子的固定感知器。所以把上面的图卷积算子分解了之后,就有了反向传播公式:

先通过第二个公式计算出局部均值,然后通过第一个公式计算出上一层的特征概率分布。然后一层一层的递归直至最开始的一层,最终得到反向传播的热图:
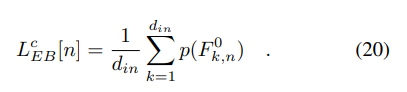
4.Experiments


















 1205
1205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









