







caffe的核心模块
以下内容整理自《深度学习轻松学》-冯超
SyncedMemory、Blob、Layer、Net、Solver、多GPU训练和IO
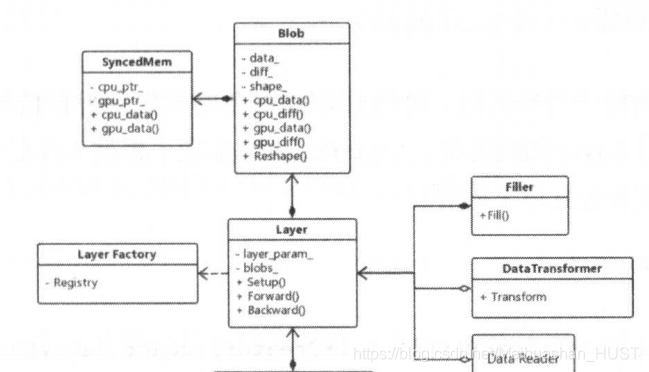
1.SyncedMemory
在深度学习训练的时候需要反复从CPU和GPU之间交互数据,自己写代码的时候也要写CPU和GPU之间数据传输代码,维护GPU和CPU的两个指针。SyncedMemory将这些操作进行了封装,调用相关函数就可以实现CPU和GPU数据的同步。其工作原理简介如下
class SyncedMemory
{
void* cpu_ptr_;
void* gpu_ptr_;
SyncedHead head_;
}
enum SyncedHead{UNINITIALIZED,HEAD_AT_CPU,HEAD_AT_GPU,SYNCED};
inline void SyncedMemory: :to_gpu ()
{
switch (head_)
{
case HEAD AT CPU :
caffe_gpu_memcpy(size_’ cpu_ptr_, gpu_ptr_);
head_ = SYNCED;
break ;
}
}
2.Blob
他在SyncedMemory的基础上进行的封装,维护两个指针,data和diff,data是原始数据,diff是梯度传播的更新量。Blob基本完成了caffe数据的封装,Layer和Net中都是Blob完成的计算
3.Layer
Blob是对数据的抽象,Layer是对模型层次的抽象,首先定义了Layer类,里面包含层创建和运算必须的接口。所有的功能层都要继承他里面定义的抽象方法。对于复杂的功能层也会定义自己的基类,比如base_conv_layer。采用了模板和工厂模式,工厂模式使得子类的具体方法通过多态的方式调用
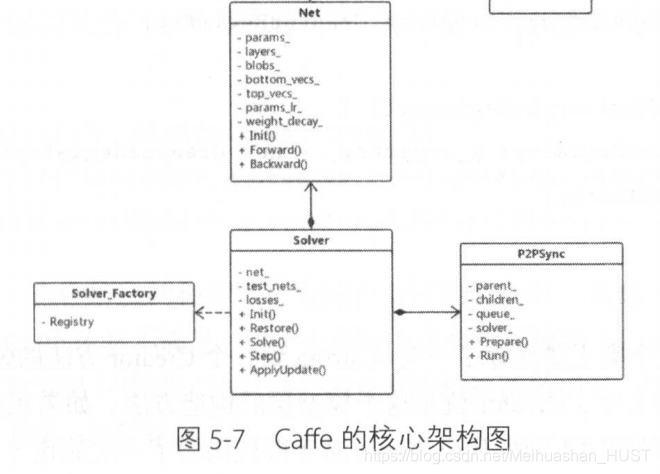
4.Net
Net是表示整个模型的类,对数据和层进行进一步封装,留下了数据的输入输出接口,参数加载接口。
5.Solver
他封装了模型训练和测试的方法。基类为Solver,新的优化方法可以继承Solver;训练过程中可以注入回调函数,在每一轮训练前和反向传播后都会进行调用。
6.多GPU训练
InternalThread和P2PSync两个类,实现基于数据并行的并发优化算法
7.IO
DataReader和DataTransformer类,数据输入和预处理,Filler模型参数的初始化














08-08
 1568
1568
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









