







决策树算法和 kNN 算法一样,也是有监督学习,即是有分好类的训练集的。此算法通过分好类的训练集来决定出决策树长得什么样子。然后根据这个决策树来对测试集中的数据进行分类。决策树长得样子,即是说这个决策先用哪个特征划分数据集,再用哪个特征划分数据集。
1,在决策树算法中,通过计算什么标准来划分数据集,方式有多种。比如可以通过 计算信息增益,还可以通过计算基尼不纯度(即度量被错误分配到其他分组里的概率)。这里我们通过计算信息增益的方式,来创建决策树。
2,所谓信息增益(熵增益),就是一次划分数据集前后熵的差。即信息增益 = 划分前熵 -- 划分后熵。
3,一个决策树有多个特征属性,那么先用哪个特征划分数据集,再用哪个特征划分数据集,我们就要看哪个特征划分数据集得到的信息增益最大;也就是说,哪个特征划分数据集之后,熵变得最小,就先用哪个特征值来划分数据。这样同理地一步步走下去(递归),直至完成整个决策树的创建。本文中决策树算法为简单的决策树算法(ID3算法),每次数据划分都会消耗一个特征。
4,下面说明熵的概念,熵就是一个数据集合的信息量的大小。集合内的数据类别越多,越鱼龙混杂,那么这个集合的信息量就越大,熵就越大。反之,如果一个集合内的数据都是同一种类型,那么这个集合就没有信息量,熵就为零,因为这个集合对其他人来说毫无神秘感,集合内都是同样的东西,也就无所谓信息不信息了。简言之,信息就是熵,熵就是信息,熵的大小就是信息的大小。熵的定义如下图
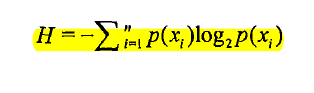
解释一下这个公式的含义:n 表示这个集合内一共有n条数据,Xi表示集合中的第 i 条数据,P(Xi) 表示Xi这种类别的数据在集合中出现的概率,H代表这个集合的熵。
5,在决策树算法中,有两个列表的概念很重要,也不能混淆它们。懂了它们,就能看懂决策树算法的代码,决策树算法的本质和过程就是处理这两个列表。它们是特征标签列表和类别标签别列表。特征标签列表是指这个集合中的数据有几个特征,类别标签列表是指这个数据集合有几个类别。假设一条数据是一个m维向量,那么这个向量的前m-1维代表各自特征的值,第m维代表这个向量所对应数据的类别。可以看出,从一条数据向量的维数,就能知道这个集合的特征数,即m-1。
6,ch03的主要内容:
(1),构造决策树
(2),绘制决策树形图
(3),用决策树对测试数据进行分类
(4),由于决策树生成,需要很长时间,所以要考虑,如果存储决策树
(5),实例应用
7,ID3算法的优缺点,如下图:
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









