







原创公众号(谢谢支持):AIAS编程有道
背景
很多同学想学习深度学习,但是无奈自己的机器老旧,要么显卡老旧,要么不是Nvidia的显卡,有的甚至没有显卡。没有GPU加速,深度学习还怎么玩?乖乖,怎么能够抵挡我成为一名学霸呢。

办法总比困难多,来薅一下资本主义羊毛吧,那就是google的Colab notebooks。jupyter notebook想必大家不陌生,如果你不知道的话,还搞啥深度学习!!!而这个Colab notebooks就原生支持它。这个很久就知道了,一直也没时间去整理,现在整理一下。话说,Colab notebooks的效果比以往好很多。
前提:这时需要能够打开google哦,否则就不用看了。
1 了解Colab notebooks
1.1 创建notebooks
首先,进入Google云端网盘,如下图:
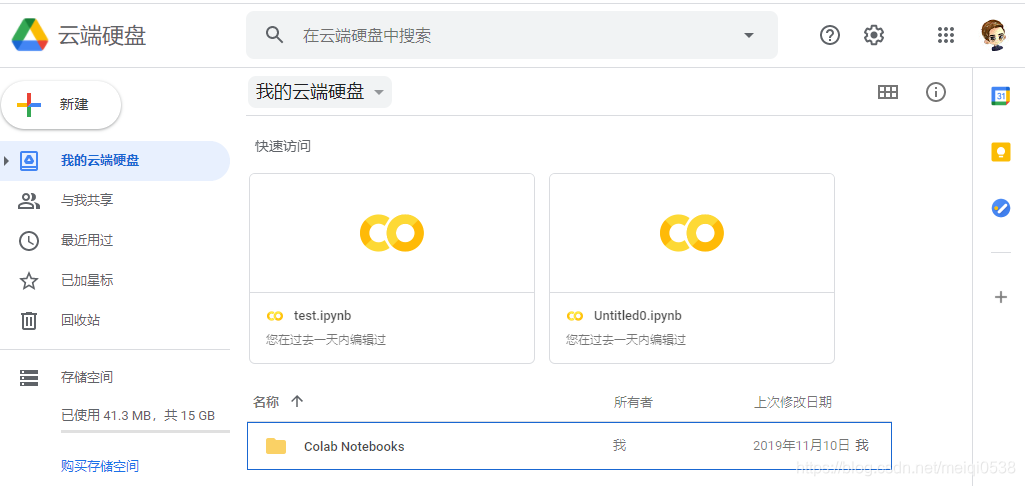
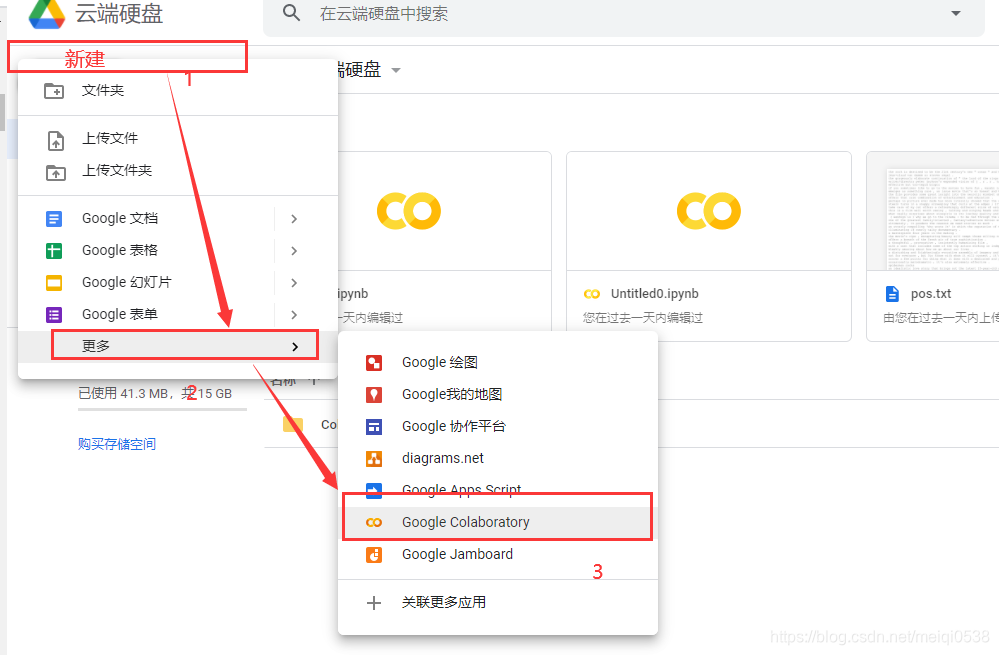
然后我们就开始创建notebook,点击**【新建】**,接着如下图:
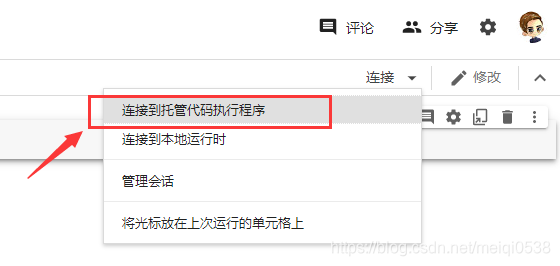
设置远端执行程序,如下图:
可直接点击ipynb文件改名,本事例改名为demo。
设置程序运行环境,默认是使用cpu运行的,
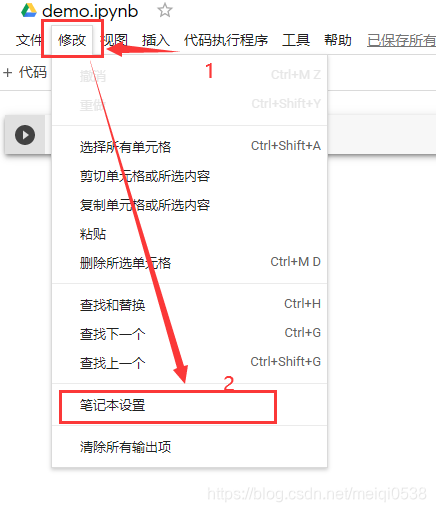
可选设备如下:
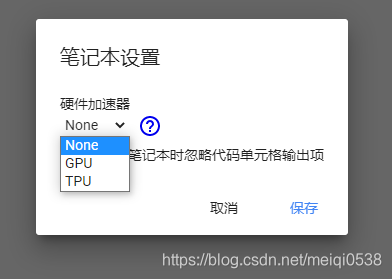
看,除了GPU外,还有TPU。贫穷的我,还不知道TPU是如何使用的。
1.2 基本指令了解
如果你懂一些linux指令那就更好了。首先,我们看看python的版本。

在notebooks中使用英文的感叹号加上linux命令,就可以执行linux命令了。从上面可以看出python版本是3.6。
查看一下是否有numpy包,如下:
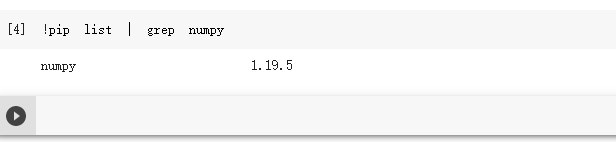
同理看看环境中是否安装了其他包,例如:pytorch_lightning这个包就没有安装。

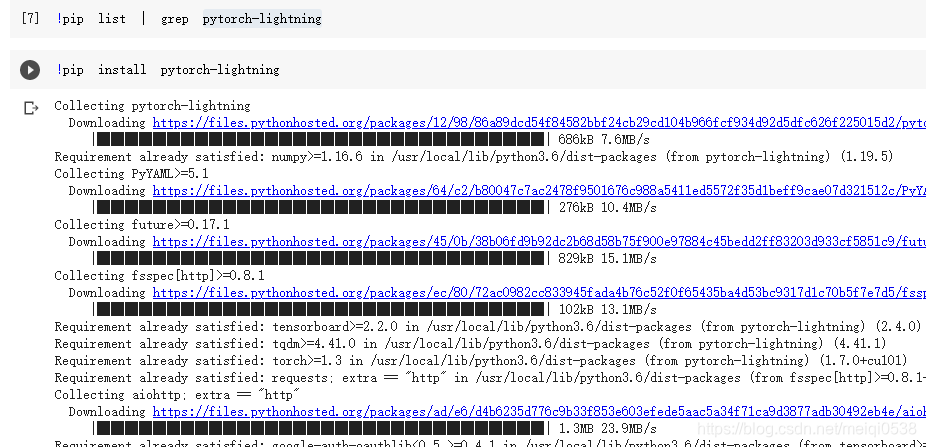
那么,我们就来按照这个包,如下:
看看当前程序运行的路径吧,因为可能要加载数据,那么就需要用到路径,如下:

当然,你还是不知道这个路径在哪。其实你可以理解这就是和linux中与\opt,\home等目录统计的目录。带你看看,按下面操作:
那么就会有:
再继续点击那个"…",这个你应该知道的,是返回上一目录,就有:
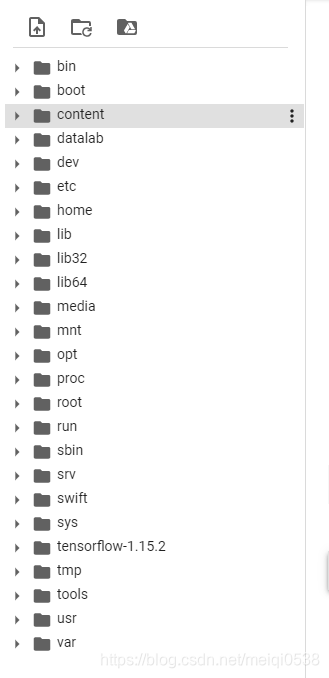
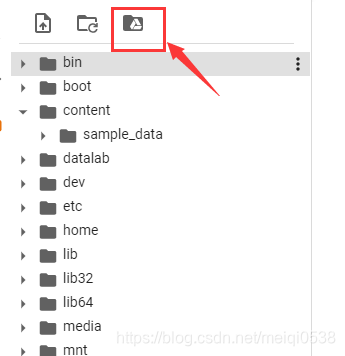
了解linux系统目录的同学是不是豁然开朗了呀。下面要操作的就是把我们google driver挂载过来,也就是把一个磁盘加进来,操作如下:
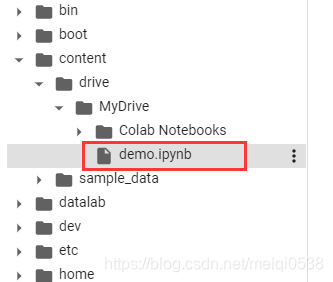
查看当前notebook文件所处路径如下:
下面就可以愉快地使用自己的训练数据咯。上传文件就相当简单了,先看一下网盘目录:
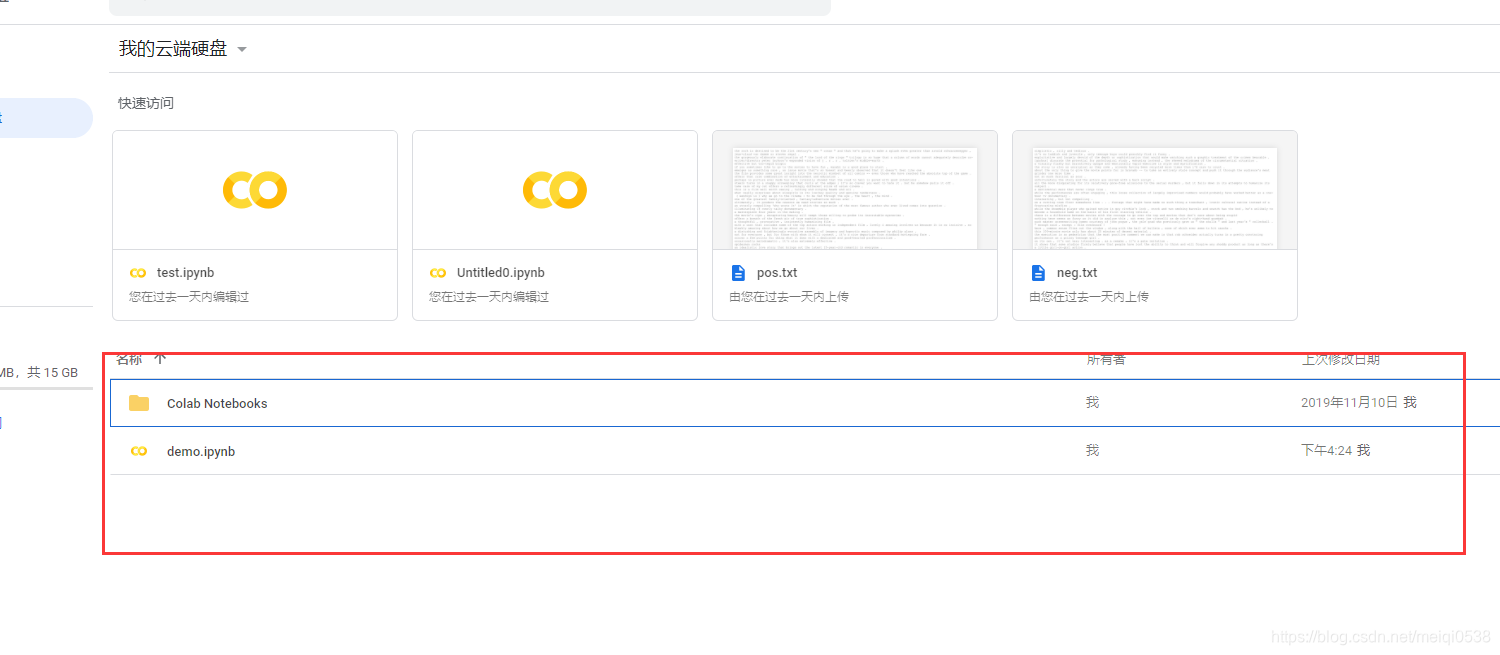
那么就数据拖上去就行了。
既然这个平台支持GPU加速,我们看看到底是什么GPU。如下:
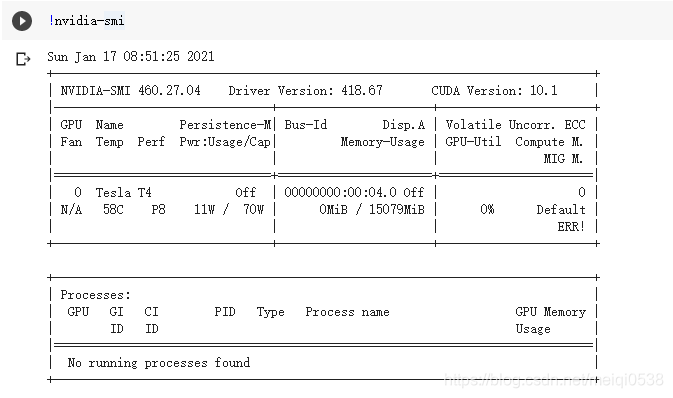
可以看出GPU是Tesla T4。对我们苦逼一族,咋知道Tesla系列的GPU效果如何呀!我查阅了其计算性能和2080Ti是一样的(别高兴太早哦),如图:
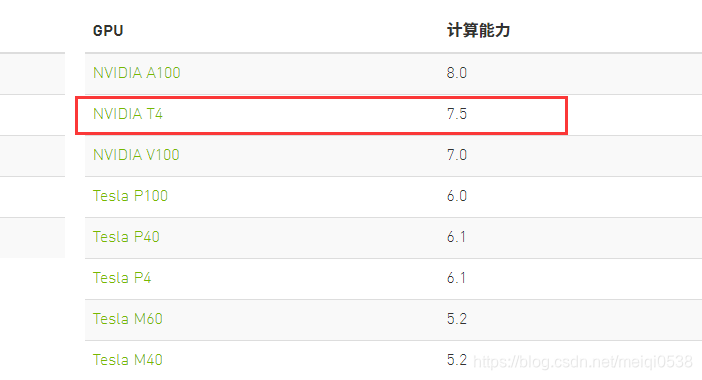
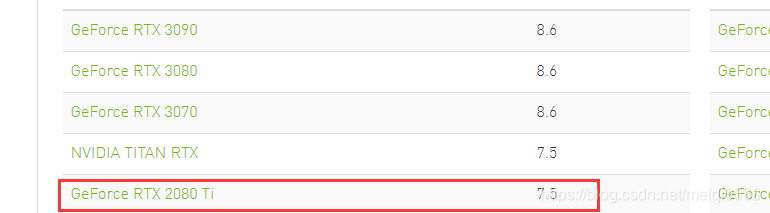
查阅网址:https://developer.nvidia.com/zh-cn/cuda-gpus 。那么到底加速如何,我们跑一个深度学习demo就知道了。
2 运行一个demo
如何构建一个notebooks已经知晓了,现在来运行一个深度学习demo吧。这个demo是之前使用textcnn进行文本分类的案例【深度学习】textCNN论文与原理——短文本分类(基于pytorch和torchtext)。代码和语料已经放在如下路径了:
为了减少你在原来项目的基础上修改代码,修改后代码就粘过来了:
import torch
import matplotlib.pyplot as plt
from torch import nn, optim
from torchtext import data
import random
from torch import nn
import os
import numpy as np
import time
if os.getcwd() != '/content/drive/My Drive/Colab Notebooks':
os.chdir('/content/drive/MyDrive/Colab Notebooks')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = torch.device("cpu")
# 文本内容,使用自定义的分词方法,将内容转换为小写,设置最大长度等
TEXT = data.Field(tokenize=lambda x:x.split(), lower=True, fix_length=50, batch_first=True)
# 文本对应的标签
LABEL = data.LabelField(dtype=torch.float)
def get_dataset(corpus_path, text_field, label_field, datatype):
"""
构建torchtext数据集
:param corpus_path: 数据路径
:param text_field: torchtext设置的文本域
:param label_field: torchtext设置的文本标签域
:param datatype: 文本的类别
:return: torchtext格式的数据集以及设置的域
"""
fields = [('text', text_field), ('label', label_field)]
examples = []
with open(corpus_path, encoding='utf8') as reader:
for line in reader:
content = line.rstrip()
if datatype == 'pos':
label = 1
else:
label = 0
# content[:-2]是由于原始文本最后的两个内容是空格和.,这里直接去掉,并将数据与设置的域对应起来
examples.append(data.Example.fromlist([content[:-2], label], fields))
return examples, fields
# 构建data数据
pos_examples, pos_fields = get_dataset('./corpus/pos.txt', TEXT, LABEL, 'pos')
neg_examples, neg_fields = get_dataset('./corpus/neg.txt', TEXT, LABEL, 'neg')
all_examples, all_fields = pos_examples + neg_examples, pos_fields + neg_fields
# 构建torchtext类型的数据集
total_data = data.Dataset(all_examples, all_fields)
# 数据集切分
train_data, test_data = total_data.split(random_state=random.seed(1000), split_ratio=0.8)
# 为该样本数据构建字典,并将子每个单词映射到对应数字
TEXT.build_vocab(train_data)
LABEL.build_vocab(train_data)
.# 构建迭代(iterator)类型的数据
train_iterator, test_iterator = data.BucketIterator.splits((train_data, test_data),batch_size=128,sort=False)
class TextCNN(nn.Module):
# output_size为输出类别(2个类别,0和1),三种kernel,size分别是3,4,5,每种kernel有100个
def __init__(self, vocab_size, embedding_dim, output_size, filter_num=100, kernel_list=(3, 4, 5), dropout=0.5):
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# 1表示channel_num,filter_num即输出数据通道数,卷积核大小为(kernel, embedding_dim)
self.convs = nn.ModuleList([
nn.Sequential(nn.Conv2d(1, filter_num, (kernel, embedding_dim)),
nn.LeakyReLU(),
nn.MaxPool2d((50 - kernel + 1, 1)))
for kernel in kernel_list
])
self.fc = nn.Linear(filter_num * len(kernel_list), output_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.embedding(x) # [128, 50, 200] (batch, seq_len, embedding_dim)
x = x.unsqueeze(1) # [128, 1, 50, 200] 即(batch, channel_num, seq_len, embedding_dim)
out = [conv(x) for conv in self.convs]
out = torch.cat(out, dim=1) # [128, 300, 1, 1],各通道的数据拼接在一起
out = out.view(x.size(0), -1) # 展平
out = self.dropout(out) # 构建dropout层
logits = self.fc(out) # 结果输出[128, 2]
return logits
# 创建模型
text_cnn =TextCNN(len(TEXT.vocab), 128, len(LABEL.vocab)).to(device)
print('device:', device)
# 选取优化器
optimizer = optim.Adam(text_cnn.parameters(), lr=1e-3)
# 选取损失函数
criterion = nn.CrossEntropyLoss()
# 绘制结果
model_train_acc, model_test_acc = [], []
def binary_acc(pred, y):
"""
计算模型的准确率
:param pred: 预测值
:param y: 实际真实值
:return: 返回准确率
"""
correct = torch.eq(pred, y).float()
acc = correct.sum() / len(correct)
return acc
def train(model, train_data, optimizer, criterion):
"""
模型训练
:param model: 训练的模型
:param train_data: 训练数据
:param optimizer: 优化器
:param criterion: 损失函数
:return: 该论训练各批次正确率平均值
"""
avg_acc = []
model.train() # 进入训练模式
for i, batch in enumerate(train_data):
pred = model(batch.text.to(device)).cpu()
loss = criterion(pred, batch.label.long())
acc = binary_acc(torch.max(pred, dim=1)[1], batch.label)
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 计算所有批次数据的结果
avg_acc = np.array(avg_acc).mean()
return avg_acc
def evaluate(model, test_data):
"""
使用测试数据评估模型
:param model: 模型
:param test_data: 测试数据
:return: 该论训练好的模型预测测试数据,查看预测情况
"""
avg_acc = []
model.eval() # 进入测试模式
with torch.no_grad():
for i, batch in enumerate(test_data):
pred = model(batch.text.to(device)).cpu()
acc = binary_acc(torch.max(pred, dim=1)[1], batch.label)
avg_acc.append(acc)
return np.array(avg_acc).mean()
# 模型训练
start = time.time()
for epoch in range(10):
train_acc = train(text_cnn, train_iterator, optimizer, criterion)
print("epoch = {}, 训练准确率={}".format(epoch + 1, train_acc))
test_acc = evaluate(text_cnn, test_iterator)
print("epoch = {}, 测试准确率={}".format(epoch + 1, test_acc))
model_train_acc.append(train_acc)
model_test_acc.append(test_acc)
print('total train time:', time.time() - start)
# 绘制训练过程
plt.plot(model_train_acc)
plt.plot(model_test_acc)
plt.ylim(ymin=0.5, ymax=1.01)
plt.title("The accuracy of textCNN model")
plt.legend(['train', 'dev test'])
plt.show()
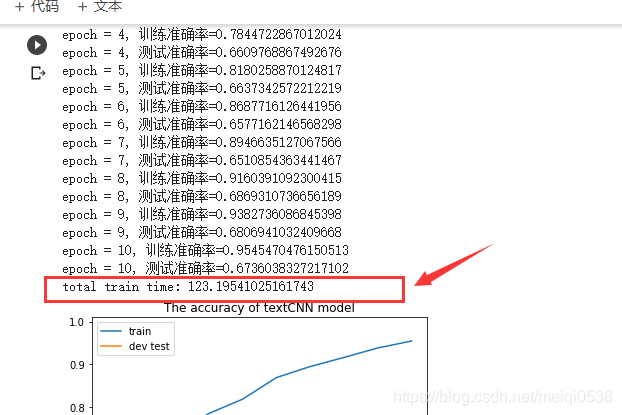
使用GPU运行时间如下:
不使用GPU运行如下:

确实使用GPU会快一点,但是我本机使用GTX 950M运行时间如下:
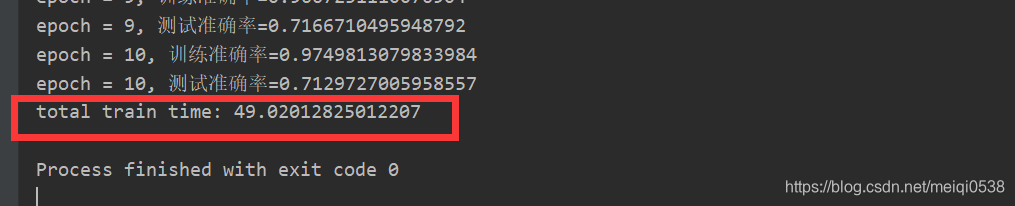
反而更快,还是快了不少,但是比本地CPU去跑还是快了不少。资本主义羊毛不好薅呀。
3 总结
总的来说,这个平台能用,学习什么的还是挺方便的。但是其GPU性能不一定真的能够释放给你用,关键时候还是得——加钱。或许还有更多其他特性我还未发掘出来。这里就抛砖引玉了,欢迎大家补充。
原创不易,科皮子菊我请各位友友帮帮个忙:
-
点赞支持一下, 您的肯定是我在csdn创作的源源动力。
-
微信搜索「pipizongITR」,关注我的公众号(新人求支持),我会第一时间在公众号分享知识技术,根据自己的经验回答你遇到的问题。
记得关注、咱们下次再见!



















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











