







最近在维护一个检测网页篡改检测的程序代码,代码会判断网页内容的大小,如果大小发生很大的变化就会报警,程序是通过CURL来获取网页大小的,程序运行在windows7下,使用的是VS2008
下面贴的代码是获取网页信息的函数:
int NetHelper::GetWebPageInfo( CString strUrl, bool bIsWap, bool bJustHeader, int& nFileSize, string& strContent )
{
strContent.clear();
nFileSize =0;
init_curl initcurl;
CURL * curl = initcurl.get_curl();
CURLcode curlres;
//libcurl初始化失败
if(!curl)
{
strContent = "curl初始化失败!";
return -1;
}
// 在堆栈上分配内存供 W2A等函数使用
USES_CONVERSION;
// 设置URL
curl_easy_setopt(curl, CURLOPT_URL, W2A(strUrl));
// 如果是ssl网站,不对ssl网站的证书进行验证
curl_easy_setopt(curl,CURLOPT_SSL_VERIFYPEER,0);
curl_easy_setopt(curl,CURLOPT_SSL_VERIFYHOST,0);
curl_easy_setopt(curl,CURLOPT_COOKIEJAR,"e:\\cookie.txt");
curl_easy_setopt(curl,CURLOPT_COOKIEFILE,"e:\\cookie.txt");
// 超时设置
curl_easy_setopt(curl,CURLOPT_TIMEOUT,10);
if ( !bJustHeader )
{
// 设置读取HTTP返回内容的回调函数
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_callback);
// 设置回调函数的参数,见write_callback函数的最后一个参数
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &strContent);
}//end if
else
{
// 设置读取HTTP头部内容的回调函数
curl_easy_setopt(curl,CURLOPT_HEADERFUNCTION,header_callback);
// 设置回调函数的参数,见header_callback函数的最后一个参数, 如果没有用到,
curl_easy_setopt(curl, CURLOPT_HEADERDATA, &strContent);
curl_easy_setopt( curl, CURLOPT_NOBODY, 1 );
}
// 自动转向
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1);
// 设置头
curl_slist *chunk = NULL;
chunk = curl_slist_append( chunk, "Accept: text/html, application/xhtml+xml, */*" );
chunk = curl_slist_append( chunk, "Accept-Language: zh-CN" );
if ( bIsWap )
{
chunk = curl_slist_append( chunk, "User-Agent: Mozilla/5.0 (Linux; U; Android 2.3.4; zh-cn; GT-I9100 Build/GINGERBREAD) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1" );
} //end if
else
{
chunk = curl_slist_append( chunk, "User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.7 (KHTML, like Gecko)" );
}
chunk = curl_slist_append( chunk, "Accept-Encoding: gzip, deflate" );
chunk = curl_slist_append( chunk, "Connection: Keep-Alive" );
curl_easy_setopt( curl, CURLOPT_HTTPHEADER, chunk );
strContent.clear();
curlres = curl_easy_perform(curl);
long nStatus;
if( curlres == CURLE_OK )
{
//服务器返回码
curl_easy_getinfo(curl, CURLINFO_RESPONSE_CODE, &nStatus);
nFileSize = strContent.size();
}
else
{
nStatus = curlres;
}
return nStatus;
}情况是这样的,当我调试这个程序,检测网站,请求网页的时候,我用httpdebug抓包,获取的网页的Body大小是96354,我查看了内容,里面是完整的网页,这说明程序设置的url请求是没有错误的,每次都可以返回正确的网页,状态码Status是200.
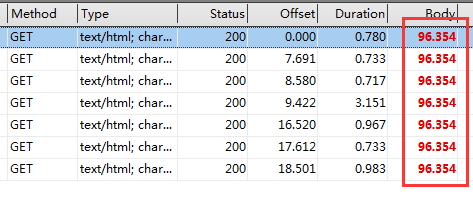
然后我下断点查看nFileSize(表示网页内容大小的变量)情况是这样的:
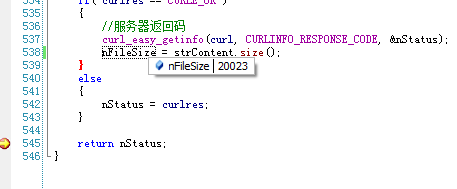
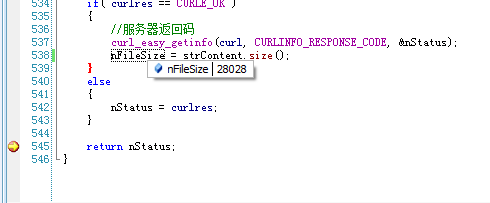
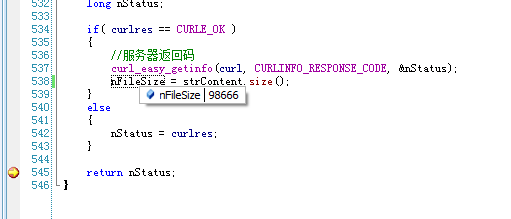
大小是变化的,只有98666可以看到是完整的网页内容,其它都是“?”。
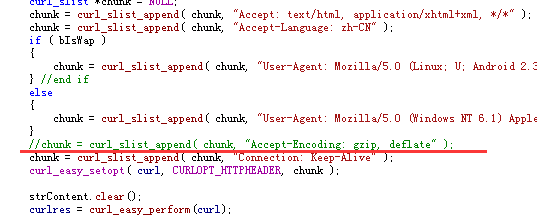
最后找出来的原因是:网页是被压缩了,把下图中的语句注释掉,服务器就不会返回压缩过的网页。这样每次获取的网页内容都是正常的了,大小都是98666。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









