







一、学前概览
任务内容:学习batch normalization、cnn基础知识
任务目的:学习并掌握
本节出现术语:批量归一化、卷积神经网络
1.学前疑惑
A.error surface很崎岖,有没有一种方式能把山铲平?
B.w1跟w2斜率差很多的状况,到底是从什么地方来的。
2.学中疑问
C.如何给不同的维度同样的数值范围?
D.中间层的归一化处理需要在激活函数还是激活函数后呢?
E.如何对中间层的输出做归一化处理?
F.已知计算批量归一化的均值和标准差都是要靠batch得来,但是测试的时候没有batch,均值和标准差如何得来?
G.为什么batch normalization会有帮助?
3.学后解答
A.有,BN就是其中之一
B.见图1
C.见图2
D.实际应用中差别不大,如果是sigmoid(s型曲线,在0附近斜率较大)则推荐在前。
E.见图3
F.见知识点3
G.见知识点4
二、Task3.1 特征归一化
产生不同方向的error surface不同的原因之一:输入数据大小差异太大,比如说x1是一个小数值,x2是一个很大的数值,分别乘上对应的参数,即便参数改动很小,但是变化量是很大的。如图1所示。
解决办法是给不同的维度同样的数值范围。

图1:不同方向的error surface差异不同的原因
1.知识点1:feature normalization(这里只一种可能性)
一张图看懂归一化,见图2.

图2:归一化
从深度学习的角度考虑,此时已经对原始输入已经进行了特征归一化处理,但是,当一个神经网络有很多层的时候,原始输入通过第一层后的各个输出之间的差异还是很大,不在相同的值范围内,此时是否还需要对这些中间输出做归一化处理呢?答案是肯定的。见图3。

图3:中间层的归一化处理
2.知识点2:batch normalization的由来
做特征归一化的时候,可以把整个过程当做是网络的一部分。该网络吃了一堆输入,用这堆输入在这个网络里面计算出 µ,σ,接下来产生 一堆输出。如果数据量较大的话,GPU的显存是无法把整个数据集的数据都加载进去的。因此实现的时候,不会让网络考虑整个训练数据里面的所有样本,而是只考虑一个批量里面的样本。比如批量设 64,就是把 64 笔数据读进网络,计算这64 笔数据的µ,σ,对这64笔数据做归一化。实际实现的时候,只对一个批量里面的数据做归一化,因此该技巧被称为批量归一 化。
一定要有一个够大的批量,才算得出µ,σ(批量大小如果比较大,也许这个批量大小里面的数据就足以表示整个数据集的分布,近似为整个数据集)。
实际中会在正则化的向量中加入两个参数,防止归一化后均值为0,使得可能会对网络造成影响。但是又会有一个问题,就是加入参数之后,数据的范围又会是不一样了,所以在一开始的时候让γ设置为1,β为零向量,然后再慢慢加进去。如图4所示。

图4:实际中的归一化操作
3.知识点3:测试时的批量归一化
pytorch处理好了,在训练过程中,将每一个batch计算得来的μ和σ存储起来,最后算moving average。如图5所示。

图5:测试集中的均值和标准差的由来
4.知识点4:可解释性
有理论和实验的支撑,但是其发现可能是跟盘尼西林的发现一样是偶然的,但是不管怎样,就是有用。至少支持批量归一化可以改变误差表面。详见论文“How Does Batch Normalization Help Optimization"。
三、Task3.2:卷积神经网络
1.知识点5:CNN基础知识
CNN专门被用在影像上,本质上是给机器一张图片,让机器决定图片里面有什么东西(前提条件:图片输入大小固定)。模型的输出目标为分类结果,通常把每个类别表示成独热编码,通过softmax后输出y',优化目标则是让真实值与y'之间的cross entropy越小越好。
2.知识点6:影像输入模型
对于机器而言,一张图片=3维Tensor(长,宽,channels(rgb)),对于图片而言,做FC是没有必要的,因为这样计算量太大,而且容易过拟合,因此有人提出检测模式不需要整张图像。那么如何设计这个简化后的网络架构呢?
简化方式1:感受野
感受野(receptive field)应运而生。让network只关心感受野里面发生的事情。假设感受野是一个3×3×3的三维矩阵,我们将其拉直形成一个27维的向量,然后将该向量作为neuron的输入,并分配给每一个维度一个weight,加上bias得到的输出,继续传送给neuron。
最经典的感受野设置方式:默认视为全部channel(第三纬度),只看高度跟宽度,将其称为kernel size。让kernel size在图片上做上下左右平移,平移的步长命名为stride。如图6所示。当kernel size移动时,会出现overlap的情况,此时超出的部分,使用padding填充0。
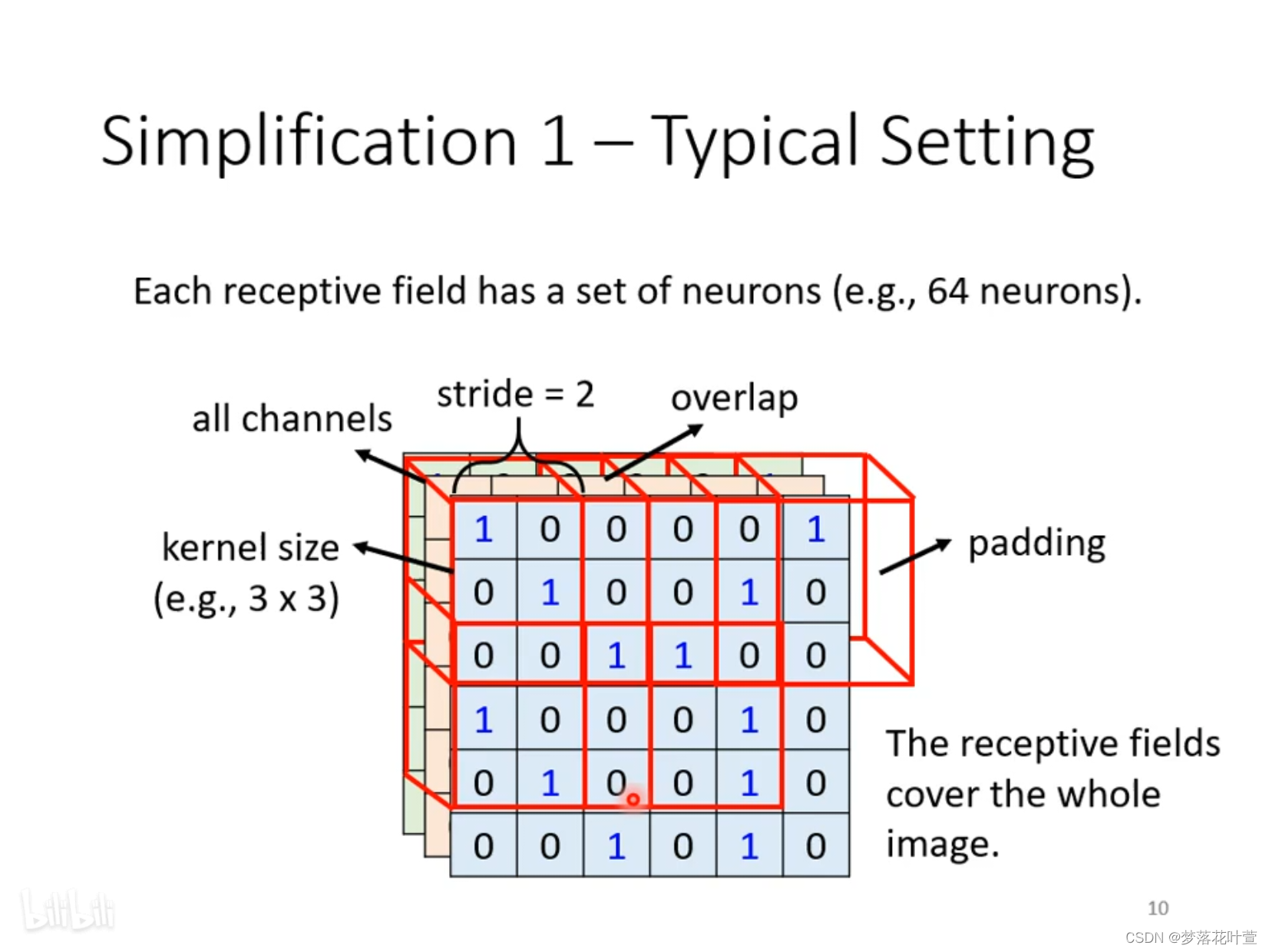
图6:cnn相关参数介绍
简化方式2:共享参数
设想:同样的pattern可能会出现在图片的不同区域,因此,能不能让不同receptive field的neuron共享参数呢?解决办法为让每个neuron保持权重一致。
常用共享方法的设定:每一组rf(感受野)都有一个neuron在负责守卫,并且每一个rf都有一组参数,参数名为filter。
图7是卷积层的总结
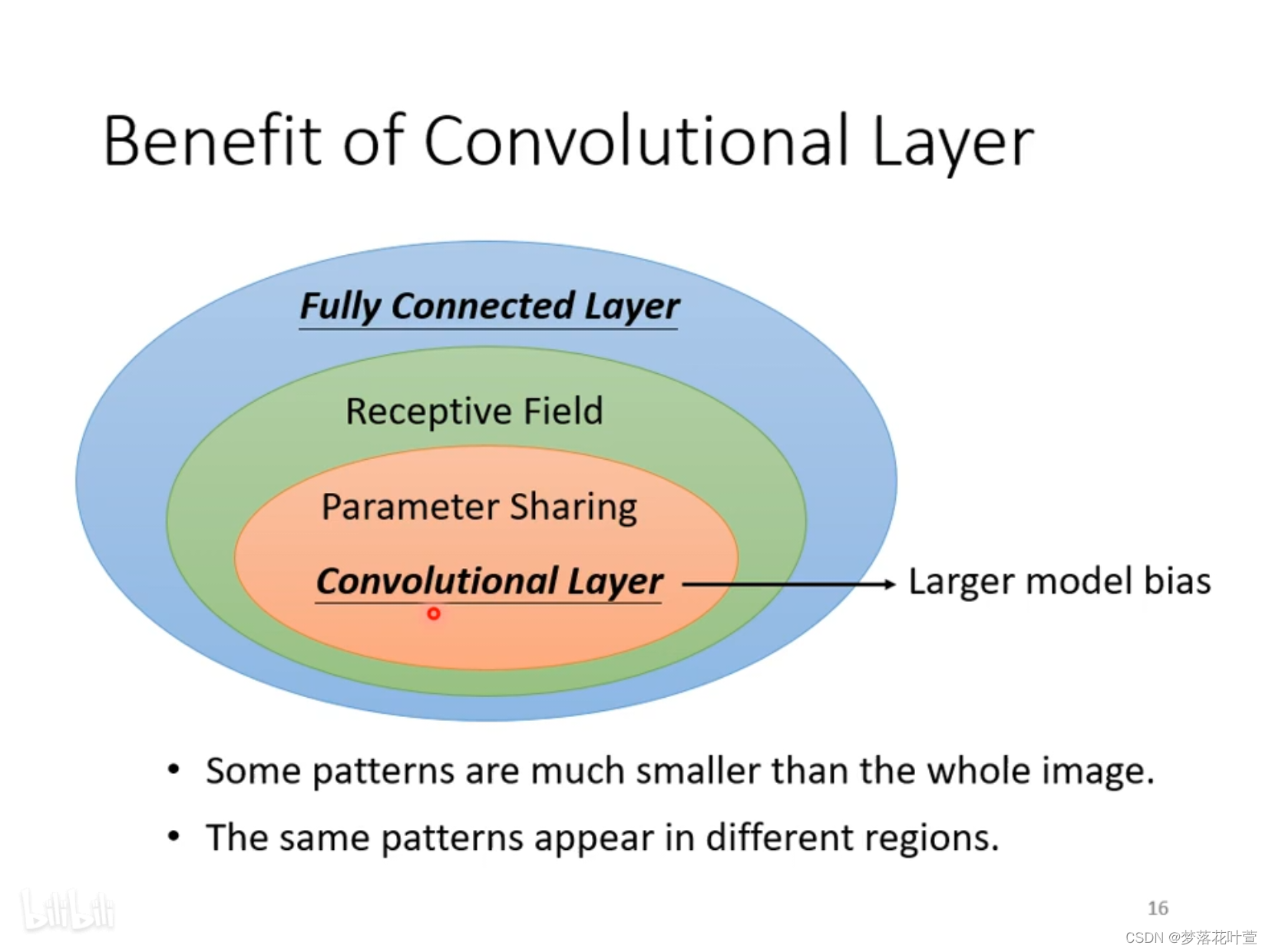
图7:卷积层的总结
3.知识点7:feature map
一组图通过卷积层的filter产生得到的结果,称为feature map,而feature map又是新一轮卷积输入的channel。
4.知识点8:pooling
pooling的作用是把图片缩小,起到降低计算复杂度的作用,而这个过程的channel是保持不变的。工作原理:将filter后得到的矩阵里的值进行分组(可以自己决定分组特征),每一组选出一个代表保留,其他数据丢弃(代表可以是该组的max或者是min,或者是自定义)。起到降低计算复杂度的作用。
5.知识点9:flatten
在做卷积运算并进行池化操作后,进行下一步操作前,需要整合特征,n维的特征并不好处理,flatten的作用就是讲池化后的结果进行展平,变成一个一维的向量,方便做全连接计算。















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









