







FedDM: Federated Weakly Supervised Segmentation via Annotation Calibration and Gradient De-Conflicting
Authors: Meilu Zhu, Zhen Chen, and Yixuan Yuan, Member, IEEE
Keywords: Federated learning, weakly supervised learning, medical image segmentation.
Source: IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 42, NO. 6, JUNE 2023IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 42, NO. 6, JUNE 2023

Abstract:
弱监督分割(WSS)旨在利用弱形式的注释来实现分割训练,从而减轻注释负担。然而,现有方法依赖于大规模集中数据集,而由于医学数据的隐私问题,构建这种数据集存在困难。联邦学习(FL)提供了一种跨站点训练范式,显示出解决这一问题的巨大潜力。在这项工作中,首次提出了联邦弱监督分割(FedWSS)的问题,并提出了一种新颖的联邦偏移缓解(FedDM)框架,用于跨多个站点学习分割模型,而无需共享原始数据。
FedDM致力于解决FL设置中弱监督信号引起的两个主要挑战(即客户端优化的局部偏移和服务器聚合的全局偏移),通过协作注释校准(CAC)和分层梯度去冲突(HGD)来实现。为缓解局部偏移,CAC通过蒙特卡罗采样策略为每个客户端定制一个远程对等体和一个近端对等体,然后利用客户端间的知识一致性和差异性分别识别干净标签和修正噪声标签。此外,为了缓解全局偏移,HGD在每轮通信时在全局模型的历史梯度指导下在线构建客户端层次结构。通过从底层到顶层对同一父节点下的客户端进行梯度去冲突,HGD实现了服务器端的稳健梯度聚合。
此外,在理论上分析了FedDM,并在公共数据集上进行了广泛的实验。实验结果证明了方法相比现有技术的卓越性能。

图1。提出的联邦漂移缓解(FedDM)的总体管道,旨在训练一个使用来自多个站点的分散数据集的全局分割模型。
自动医学图像分割是计算机辅助诊断系统(CAD)中一项关键任务,用于识别异常区域以进行疾病分析和诊断。当前众多方法是在具有像素级注释的数据上进行训练的,这需要大量人力和昂贵的成本。最近,弱监督分割(WSS)算法引起了广泛关注,旨在减少对像素级注释的依赖。这些方法在诸如图像级注释、边界框、点和涂鸦等弱形式注释的监督下,能够达到与完全监督范式相当的性能。
然而,现有的WSS方法依赖于在大规模集中数据集上进行训练,而在现实医疗场景中构建这种数据集由于隐私和伦理问题而存在困难。最近兴起的联邦学习(FL)为解决这一问题提供了一种可行的解决方案,通过跨站点协作。FL范式允许参与机构(称为客户端)将其模型梯度或参数共享给可信的中心(称为服务器)进行模型聚合,同时保持数据去中心化。然而,在FL系统中采用弱监督信号训练分割模型存在挑战,目前尚未探索。在这项工作中,研究了一个新颖且实用的联邦弱监督分割(FedWSS)问题设置,使用边界框作为监督,目标是通过来自多个站点的去中心化数据集训练一个全局分割模型。这种设置不仅减轻了参与客户端的数据收集和注释负担,还可以交换客户端间的知识以提高模型泛化能力,并大幅降低隐私和安全风险,为发展未来智能医疗保健系统提供了可持续的道路。
弱监督学习范式为联邦医学图像分割带来了两个新挑战,即客户端优化的局部偏移和服务器聚合的全局偏移。首先,在客户端方面,WSS中的边界框注释涉及大量噪声像素标签,可能会导致客户端模型学习到错误和不一致的决策边界,从而导致客户端模型在优化过程中产生局部偏移。一个客户端学习到的错误知识会通过服务器传递给其他客户端,甚至导致FL系统的训练失败。此外,由于FL场景下各客户端的数据是由具有不同经验和标准的相应专家注释的,因此难以保证注释质量。先前的WSS方法施加了紧凑性约束来减小噪声标签的影响。然而,这些方法的性能有限,因为紧凑性约束的有效性高度依赖于边界框的质量。
第二个挑战是在服务器端的梯度聚合过程中产生的全局偏移。客户端模型是在带有噪声像素标签的弱注释监督下训练的。这意味着一个客户端上传的梯度是干净和噪声组件的混合。噪声部分会导致客户端梯度之间产生冲突。如果直接聚合这些相互矛盾的客户端梯度来更新全局模型,它们将相互产生破坏性干扰,从而使全局模型发生全局偏移。此外,严重的冲突表明客户端模型之间存在巨大分歧,以及它们的决策边界之间不一致,已被发现会导致收敛缓慢和不稳定以及整个FL系统的性能不佳。尽管一些方法在梯度聚合时引入了重新加权策略,并在局部更新时引入了各种约束项来缓解这一问题,但它们是为完全监督训练设置而设计的,无法直接应用于FedWSS场景。
为解决上述两个挑战,提出了一种新颖的联邦弱监督分割框架Federated Drift Mitigation (FedDM),通过协作注释校准(CAC)来纠正噪声标签从而缓解局部偏移,并通过分层梯度去冲突(HGD)来消除客户端梯度之间的冲突从而缓解全局偏移,如图1所示。
为缓解局部偏移,CAC首先通过蒙特卡罗采样策略为每个客户端定制一个远程对等模型和一个近端对等模型。之后,CAC利用当前客户端模型与其远程对等模型之间的知识一致性来识别潜在的干净像素标签。当前客户端模型与其近端对等模型之间的知识差异则被用于识别和纠正噪声像素标签。
此外,为了消除客户端梯度间的冲突从而缓解全局偏移,HGD在每轮通信时在全局模型历史梯度的指导下构建了一个在线的客户端层次结构。在这个层次结构中,HGD通过将同一父节点下客户端的梯度投影到彼此梯度的法平面上,从底层到顶层消除了它们之间的冲突梯度分量。在层次结构的根节点处,所有客户端梯度汇聚并融合用于更新全局模型。通过消除局部和全局偏移,提出的FedDM能够在边界框监督下实现稳定训练和高分割性能。工作的主要贡献总结如下:
-
通过FedDM框架解决了联邦弱监督分割这一新颖且实用的问题。这是首次努力以联邦学习的方式,让不同机构协作利用各自的弱注释私有数据训练共享分割模型。
-
提出了协作注释校准(CAC),通过客户端间的知识一致性和差异性来识别干净标签、纠正噪声标签,从而缓解局部偏移。
-
设计了分层梯度去冲突(HGD),以缓解全局偏移,它构建了一个客户端层次结构,逐层进行梯度去冲突和聚合。
Methodology
A. Overview
在这部分,作者概述了提出的Federated Drift Mitigation (FedDM)框架。FedDM利用来自K个客户端的带有边界框注释的分散数据,在中央服务器的协调下,共同训练一个共享的全局分割模型,而无需共享个人的原始数据。FedDM的训练过程包括客户端和服务器之间的T轮通信。具体地,在第t轮中,所有客户端下载全局模型F的参数作为本地模型的初始化。然后,第k个客户端利用本地数据D_k来更新初始参数
到
。在这个过程中,使用了Collaborative Annotation Calibration (CAC)来减少本地漂移,CAC通过减轻客户端噪声像素标签的影响来实现。在第t轮结束时,服务器收集客户端的梯度,并通过Hierarchical Gradient De-conflicting (HGD)合并这些梯度,从而更新全局模型参数θ{t-1}到θ_t。HGD旨在消除客户端梯度之间的冲突,缓解全局漂移。
B. Collaborative Annotation Calibration for Local Drift
为了克服边界框注释中存在的噪声像素标签导致的本地漂移问题,作者提出了Collaborative Annotation Calibration (CAC)模块。CAC利用客户端之间的知识一致性和差异性来识别干净的标签和纠正噪声标签。具体地,在服务器端,CAC首先使用蒙特卡罗(MC)采样策略为每个客户端定制两个peer模型;然后,这些peer模型被发送到相应的客户端,通过两个步骤来指导本地训练:识别干净的标签和纠正噪声标签。
1.通过MC采样自定义Peers:
通过MC采样,在服务器端为第k个客户端采样G个高斯噪声张量{ξ_g}{g=1}^G。每个噪声张量ξ_g被输入到第k个上传的客户端模型F_k(θ{k,t})中,获得预测a_k^g。然后,利用欧几里德距离来测量第k个客户端模型与其他客户端模型之间的预测相似性{d_{k,k'}^g}{k'=1}^K,k'≠k,其中d{k,k'}^g=||a_k^g-a_{k'}^g||2。通过比较相似性值,噪声张量ξ_g可以帮助第k个客户端找到一个最相似(k'=arg max_k'd{k,k'}^g)和一个最不相似(k'=arg min_k'd_{k,k'}^g)的peer客户端模型。为了消除随机采样操作的偏差,对于每个客户端,统计G个噪声张量的比较结果,并选择被最多噪声张量投票为最相似的客户端模型作为proximal peer F_k(θ_t^p),同时选择被最多噪声张量投票为最不相似的客户端模型作为distal peer F_k(θ_t^d)。这些peer模型F_k(θ_t^p)和F_k(θ_t^d)与全局模型一起被发送到第k个客户端,在本地训练过程中保持冻结状态。
2.通过Distal Peer识别干净的标签:
从边界框注释中选择干净的像素标签来更新客户端模型对于本地训练的收敛至关重要。为此,利用本地模型F_k(θ_{k,t})和distal peer F_k(θ_t^d)之间的预测一致性来区分干净的像素和小损失像素。具体地,对于第k个客户端,样本x_k^i被分别输入模型F_k(θ_{k,t})和F_k(θ_t^d)以获得分割预测。然后,通过阈值化像素的交叉熵损失ℓ_{ce}来计算它们的初始干净像素掩码m_k^i和m̃_k^i,如下所示:
\begin{align}
m_k^i &= T(ℓ_{ce}(F_k(θ_{k,t}, x_k^i), y_k^i), λ(e)) \
m̃_k^i &= T(ℓ_{ce}(F_k(θ_t^d, x_k^i), y_k^i), λ(e))
\end{align}
其中,T(·,λ(e))表示在第e个epoch中对每个输入样本的分割预测选择λ(e)百分比的小损失像素的操作。对于干净的像素,来自模型F_k(θ_{k,t})和F_k(θ_t^d)的相应预测应该是一致的,并且具有高置信度分数。因此,将掩码m_k^i和m̃_k^i之间的一致位置视为干净像素,从而得到干净像素掩码A_k^i=m_k^i∩m̃_k^i。
3.通过Proximal Peer纠正噪声标签:
发现和纠正噪声像素标签是消除本地漂移的关键步骤。为了实现这一目标,利用本地模型F_k(θ_{k,t})和proximal peer F_k(θ_t^p)之间的预测不一致性来区分噪声像素和小损失像素。与distal peer类似,proximal peer F_k(θ_t^p)的初始干净像素掩码m̃_k^i可以通过以下方式计算:
\begin{align}
m̃_k^i = T(ℓ_{ce}(F_k(θ_t^p, x_k^i), y_k^i), λ(e))
\end{align}
相似模型F_k(θ_{k,t})和F_k(θ_t^p)之间的预测不一致性反映了一个像素的高度不确定性,这是噪声像素的内在特性。因此,将掩码m_k^i和m̃_k^i之间不一致的位置视为噪声像素,可以获得噪声像素掩码\tilde{A}_k^i=m_k^i∪m̃_k^i-m_k^i∩m̃_k^i。对于噪声像素,如果其原始标签属于背景类,直接将相应的标签翻转为前景类,反之亦然。
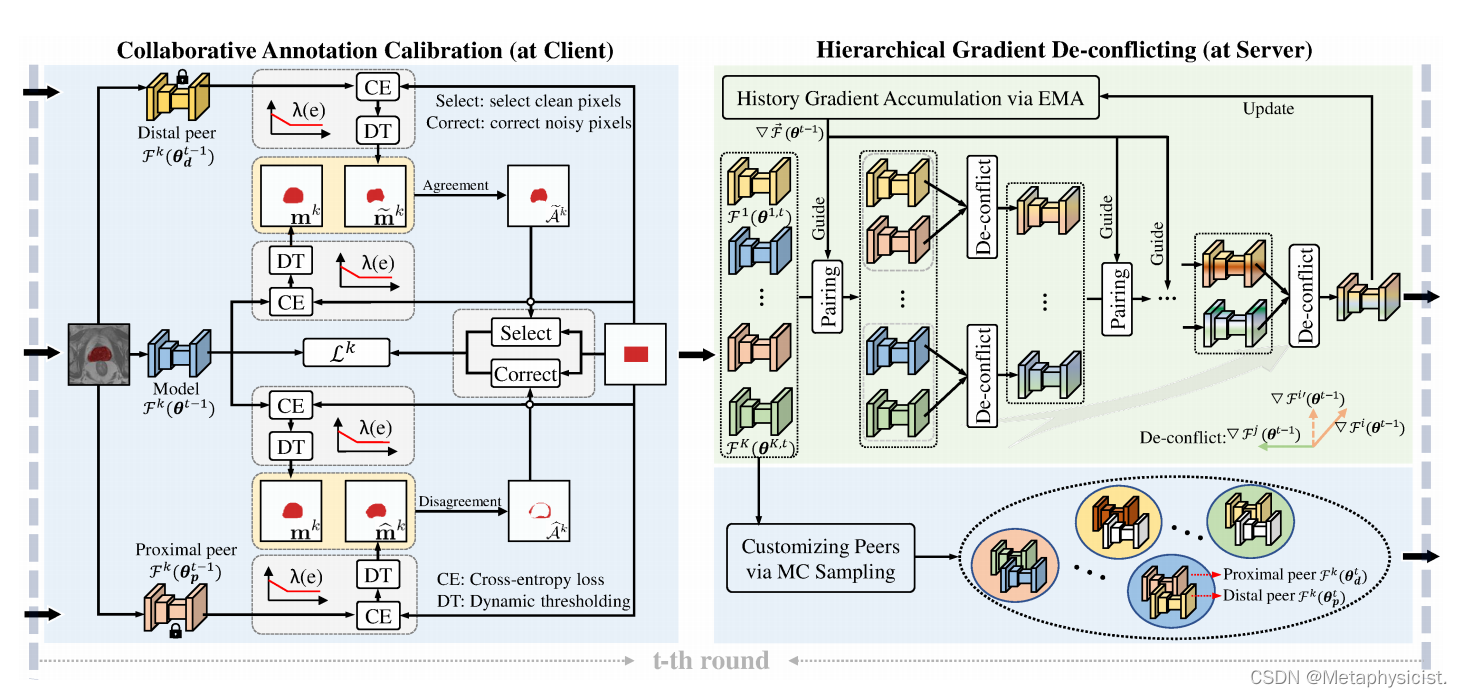
图2。提出了用于联邦弱监督分割的FedDM框架。FedDM分别通过协同注释校准(CAC)和分层梯度去冲突(HGD)来缓解局部和全局漂移。在客户端,每个客户端将接收到全局模型、远端对等和近端对等,并输入CAC进行局部耐噪声训练。完成本地培训后,所有客户端模型都上传到服务器,并通过HGD以分层方式进行聚合。(具有最佳颜色的显示视图)。
梯度冲突补正对全局趋势的影响
服务器端梯度聚合的目的是整合所有客户端的知识,从而提高全局模型在FedDM中的泛化能力。但是,由于弱标注产生的标签噪声影响,客户端梯度可能存在冲突。如果直接在服务器端通过元素级平均直接聚合这些冲突梯度,将破坏客户端上传的知识,导致知识聚合的全局趋势发生偏移。为去除客户端梯度之间的冲突,提出了一个等级式梯度冲突补正(HGD)策略。它利用全局模型的历史梯度累积信息在每轮通信中构建客户端等级层次结构,并从底层到顶层逐级补正客户端梯度对,实现稳定的梯度聚合,如图2所示。
为清楚地分析客户端梯度之间冲突对知识聚合有害影响,先考察一个简单的两个客户端案例,如图3所示。给定服务器端的一个客户端对,包括第i个客户端$F_i(\theta_{t+1})$和第j个客户端$F_j(\theta_{j,t+1})$,可以将第i个客户端梯度$\nabla F_i(\theta_t)$分解为两个正交成分$\nabla F_{i1}(\theta_t)$和$\nabla F_{i2}(\theta_t)$,它们分别与第j个客户端梯度$\nabla F_j(\theta_t)$正交和平行。直接平均$\nabla F_i(\theta_t)$和$\nabla F_j(\theta_t)$时,与$\nabla F_j(\theta_t)$正交的成分$\nabla F_{i1}(\theta_t)$不会影响$\nabla F_j(\theta_t)$,因为它们无关。但是,与$\nabla F_j(\theta_t)$成角大于90°时,平行成分$\nabla F_{i2}(\theta_t)$会对$\nabla F_j(\theta_t)$产生负影响,因为它们方向相反。同样,第j个客户端梯度$\nabla F_j(\theta_t)$的平行成分也可能影响$\nabla F_i(\theta_t)$。基于此观察,给出了两个客户端梯度$\nabla F_i(\theta_t)$和$\nabla F_j(\theta_t)$冲突的定义:
当两个客户端梯度$\nabla F_i(\theta_t)$和$\nabla F_j(\theta_t)$之间的角$\alpha_{ij}$满足$\cos(\alpha_{ij})<0$时,则认为它们存在冲突。
这一观察指导去除平行(冲突)成分,以减少客户端梯度间的破坏性相互作用,如图3(b)所示。具体做法是在聚合前,将两个客户端梯度投影到彼此的正交方向上:
\begin{align}
\nabla F_i^{\prime}(\theta_t) &= \nabla F_i(\theta_t) - \nabla F_i(\theta_t) \cdot \nabla F_j(\theta_t) \frac{\nabla F_j(\theta_t)}{\lVert \nabla F_j(\theta_t) \rVert^2} \
\nabla F_j^{\prime}(\theta_t) &= \nabla F_j(\theta_t) - \nabla F_j(\theta_t) \cdot \nabla F_i(\theta_t) \frac{\nabla F_i(\theta_t)}{\lVert \nabla F_i(\theta_t) \rVert^2}
\end{align}
其中等式(3)和(4)中的最后项即为第i个客户端梯度$\nabla F_i(\theta_t)$和第j个客户端梯度$\nabla F_j(\theta_t)$之间的冲突成分。通过去除这些冲突成分,两个客户端梯度将正相关。如果梯度$\nabla F_i(\theta_t)$和$\nabla F_j(\theta_t)$无冲突,则无需进行补正操作。
接着考虑一个复杂FL系统中K(K>2)个客户端的全面冲突最小化问题。一种自然思路是将第i个客户端梯度$\nabla F_i(\theta_t)$投影到其余K-1个客户端梯度${\nabla F_k(\theta_t)}_{k=1}^K,k\neq i$的正交平面上,但随机投影顺序可能导致补正无效,因为其余客户端梯度会将$\nabla F_i(\theta_t)$向不同方向引导,最终可能不改变其方向。因此,在线构建客户端等级层次结构,每轮通信实现冲突最小化和梯度聚合。具体来说,考虑全局模型历史梯度可以指导其未来更新方向,利用指数滑动平均(EMA)在服务器端累积全局模型梯度:
\begin{align}
\nabla \bar{F}(\theta_t) = \omega \nabla \bar{F}(\theta_{t-1}) + (1-\omega) \nabla F(\theta_t)
\end{align}
其中$\omega$是一个平滑系数超参数来控制梯度累积率。$\nabla \bar{F}(\theta_t)$表示第t轮的历史梯度累积,将其用于下一轮构建客户端等级层次结构。
在第(t+1)轮,服务器收集所有客户端梯度${\nabla F_k(\theta_t)}{k=1}^K$后,从底层开始构建客户端等级结构。首先计算历史梯度$\nabla \bar{F}(\theta_t)$与各客户端梯度${\nabla F_k(\theta_t)}k^K$的余弦相似性 ${s_k}{k=1}^K$。然后利用这些相似性值${s_k}{k=1}^K$构建客户端对,相似性大的客户端与相似性小的客户端配对。如果客户端数为奇数,剩余的作为单独节点。这些客户端对构成第一层等级结构。

图3。两个客户端梯度Fi(θt)和Fj(θt)的去冲突过程。(a)这两个梯度是直接聚合。(b)这两个梯度首先消除冲突,然后聚合。黄线和绿线分别代表这两种情况的聚集梯度。×表示删除冲突组件的操作。
为构建第二层等级结构,补正第一层所有客户端对中的冲突。每对客户端经补正后的梯度相加作为其父节点。与第一层剩余节点一起,继续利用历史梯度$\nabla \bar{F}(\theta_t)$对它们配对,建立第二层等级结构。重复此过程构建最后一层(根节点)等级结构。通过分层补正和聚合,所有客户端梯度${\nabla F_k(\theta_t)}{k=1}^K$融合为根节点的全局梯度$\nabla F(\theta_t)$,其除以客户端数后用于更新全局模型参数$\theta_t$至$\theta{t+1}$。
在此客户端等级结构中,全局模型历史梯度$\nabla \bar{F}(\theta_t)$可以指导梯度聚合走向精确方向,因为它累积了通常干净和准确的早期训练阶段梯度。此外,分层结构可以实现去除所有客户端梯度间的任意两客户端冲突,因为第一层没有配对的任意两个冲突客户端梯度$F_i(\theta_t)$和$F_j(\theta_t)$会融合到更高层结构的父节点中,隐式实现冲突补正。

图4。不同方法的前列腺和息肉数据集的结果可视化(边缘M = 20)。从左到右是(1) FedAvg [14],(2) FedProx [15],(3) IDA [41],(4)兰皮斯基等人,[3],(5)约束-CNN[4],(6)全局约束[5],(7)PINT[42],(8)FedDM。


图7。在前列腺和息肉数据集上提出的FedDM框架的失败案例的说明。(a)和(d)列显示了输入的图像。(b)列和(e)列给出了相应的地面真相。方法的预测在(c)和(f)列中给出。
FedDM在IID前列腺分割和多癜杖分割数据集上的实验表明,与其他联邦学习和弱监督方法相比,FedDM在各种边界框条件下都显著提高了分割准确率。在非IID前列腺数据集上,FedDM也能有效提高分割精度,证明了它在非IID场景下的鲁棒性能。消融实验表明,CAC和HGD模块各自都有效提升了模型性能,而它们的组合可以最大限度发挥FedDM框架的优势。不管是边界框位置变化还是客户端数量和本地迭代次数的改变,FedDM都表现出很好的稳健性。定性结果展示FedDM能更好地识别难点区域。出现失败的一些例子主要是由于目标区域与背景对比度不足所致,这也是弱监督领域的挑战。
Reference:
[1] Zhu, M., Chen, Z., & Yuan, Y. (2023). FedDM: Federated weakly supervised segmentation via annotation calibration and gradient de-conflicting. IEEE Transactions on Medical Imaging.















 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











