







Transferability-Guided Multi-source Model Adaptation for Medical Image Segmentation
Authors: Chen Yang, Yifan Liu, and Yixuan Yuan
Source: MICCAI 2023
Keywords: Source-free Domain Adaptation · Multi-source · Label-free transferability metric
Abstract
无监督域适应通过将知识从有标签的源数据迁移到未标记的目标域,在医学图像分割领域引起了持续的关注。然而,大多数现有方法假设源数据来自单个客户端,这无法成功地探索来自具有较大分布差异的多个源域的互补可迁移知识。此外,它们在训练过程中需要访问源数据,由于隐私保护和内存存储的原因,这是低效且不切实际的。为了应对这些挑战,研究了一个新颖且实用的问题,称为多源模型自适应(MSMA),其目的是在没有任何源数据的情况下将多个源模型迁移到未标记的目标域。由于没有提供目标标签和源数据来评估每个源模型的可迁移性或源域与目标域之间的域差距,可能会遇到来自那些不太相关的源域的负迁移,从而损害目标性能。为了解决这个问题,提出了一个可迁移性引导的模型自适应(TGMA)框架来消除负迁移。
具体来说,1)首次设计了一种无标签可迁移性度量(LFTM)来评估源模型在没有目标标注情况下的可迁移性。2)基于设计的度量,计算实例级可迁移性矩阵(ITM)用于目标伪标签校正,以及域级可迁移性矩阵(DTM)来实现模型选择,以获得更好的目标模型初始化。在多站点前列腺分割数据集上的大量实验表明了框架的优越性。
背景:
深度神经网络在医学图像分析中取得了巨大进步,但需要大量标注数据进行训练,这在医学图像分割任务中尤其耗时且容易出错。在一个临床中心(源域)训练的分割模型,在部署到新的中心(目标域)时,由于数据分布的差异,往往无法很好地泛化。无监督域适应 (UDA) 试图通过将知识从标签丰富的源域迁移到标签稀缺的目标域来解决这一难题。由于存储和隐私问题,源数据在医疗环境中可能无法访问,这阻碍了域适应的广泛应用。源码无关域适应 (SFDA) 应运而生,它可以在不访问源数据的情况下,将预训练的源模型适配到未标记的目标域。如何在隐私保护下,利用多个源域的知识实现对未标记目标域的适应,仍然是一个有待解决的问题。
本文贡献:
- 首次研究了从多个源分割模型(而非源数据)向未标记目标域迁移知识的实际域适应问题,即多源模型自适应 (MSMA)。
- 设计了一种新的无标签可迁移性度量 (LFTM),基于注意力掩码一致性来评估源域和目标域之间的相关性。
- 基于 LFTM,提出了一个可迁移性引导的模型自适应 (TGMA) 框架,包括通过实例级可迁移性矩阵 (ITM) 进行伪标签校正和通过域级可迁移性矩阵 (DTM) 进行模型选择。
- 在多站点前列腺分割数据集上进行的大量实验表明,TGMA 相比于现有方法具有显著的优势。
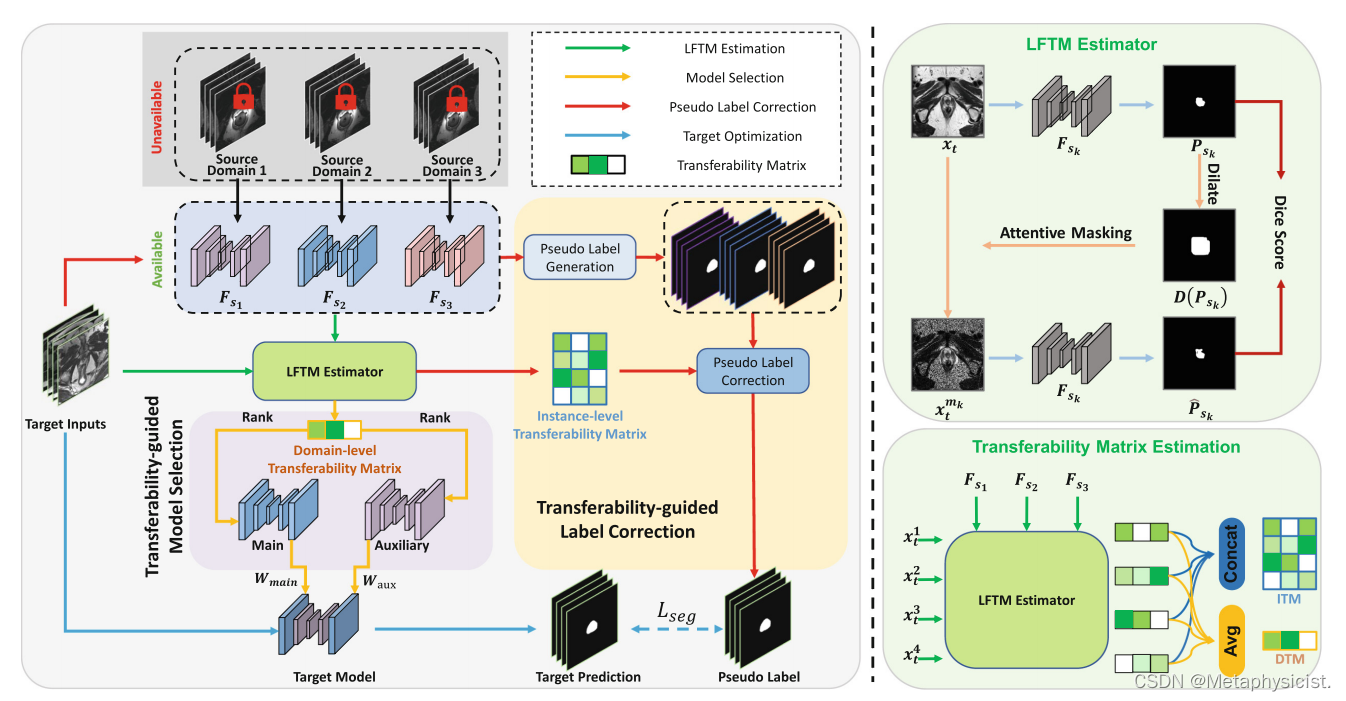
图1。可转移性引导的多源模型自适应(TGMA)框架的说明,包括(a)无标签可转移性度量(LFTM)估计器,(b)可转移性引导的模型选择和©可转移性引导的标签校正。
方法总结
问题描述:
多源模型自适应 (MSMA) 旨在将多个在不同域上训练的分割模型联合适应到一个新的未标记目标域。
目标:
在没有访问源数据的情况下,利用预训练的源模型学习目标域的分割模型 F t F_t Ft。
方法:
-
无标签可迁移性度量 (LFTM): 用于评估源模型在没有目标标注情况下的可迁移性。
- 基于注意力掩码一致性,假设:
- 相似样本应具有相同的预测结果。
- 如果源模型对样本做出准确决策,则对无关区域的少量扰动不会影响预测。
- 计算公式:
L F T M ( x t , F s k ) = 2 ∗ P s k ∩ P ^ s k P s k + P ^ s k LFTM(x_t, F_{s_k}) = \frac{2 \ast P_{s_k} \cap \hat{P}_{s_k}}{P_{s_k} + \hat{P}_{s_k}} LFTM(xt,Fsk)=Psk+P^sk2∗Psk∩P^sk
- P s k P_{s_k} Psk: 源模型 F s k F_{s_k} Fsk 对目标样本 x t x_t xt 的预测结果。
- P ^ s k \hat{P}_{s_k} P^sk: 源模型 F s k F_{s_k} Fsk 对掩码后的目标样本 x t m k x_t^{m_k} xtmk 的预测结果。
- 基于注意力掩码一致性,假设:
-
可迁移性引导的模型自适应 (TGMA):
- 标签校正: 利用实例级可迁移性矩阵 (ITM) 对多个源模型生成的伪标签进行加权,以消除负迁移并提高伪标签的准确性。
y t = a r g m a x ( ∑ i = 1 M L F T M ( x t , F s i ) ∗ y s i ) y_t = argmax(\sum_{i=1}^M LFTM(x_t, F_{s_i}) * y_{s_i}) yt=argmax(i=1∑MLFTM(xt,Fsi)∗ysi)
- 模型选择: 利用域级可迁移性矩阵 (DTM) 对源模型进行排序,选择最具可迁移性的源模型作为主网络 F m a i n F_{main} Fmain,次优模型作为辅助网络 F a u x F_{aux} Faux,并采用加权优化策略。
F t = m i n F ∩ W L d i c e ( y t , W m a i n ∗ F m a i n ( x t ) + W a u x ∗ F a u x ( x t ) ) F_t = min_{F \cap W} L_{dice}(y_t, W_{main} * F_{main}(x_t) + W_{aux} * F_{aux}(x_t)) Ft=minF∩WLdice(yt,Wmain∗Fmain(xt)+Waux∗Faux(xt))
预期效果:
通过消除负迁移、提高伪标签质量和选择合适的模型初始化,TGMA 可以有效地将多个源模型的知识迁移到目标域,从而提高目标域的分割性能。
实验总结
数据集:
- 前列腺 MR (PMR) 数据集,包含来自 6 个不同公共数据源的前列腺分割数据。
- 将数据集划分为 6 个站点 {A, B, C, D, E, F},每个站点包含不同数量的切片。
- 采用留一法进行实验,每次选择 5 个站点作为源域,剩余 1 个站点作为目标域。
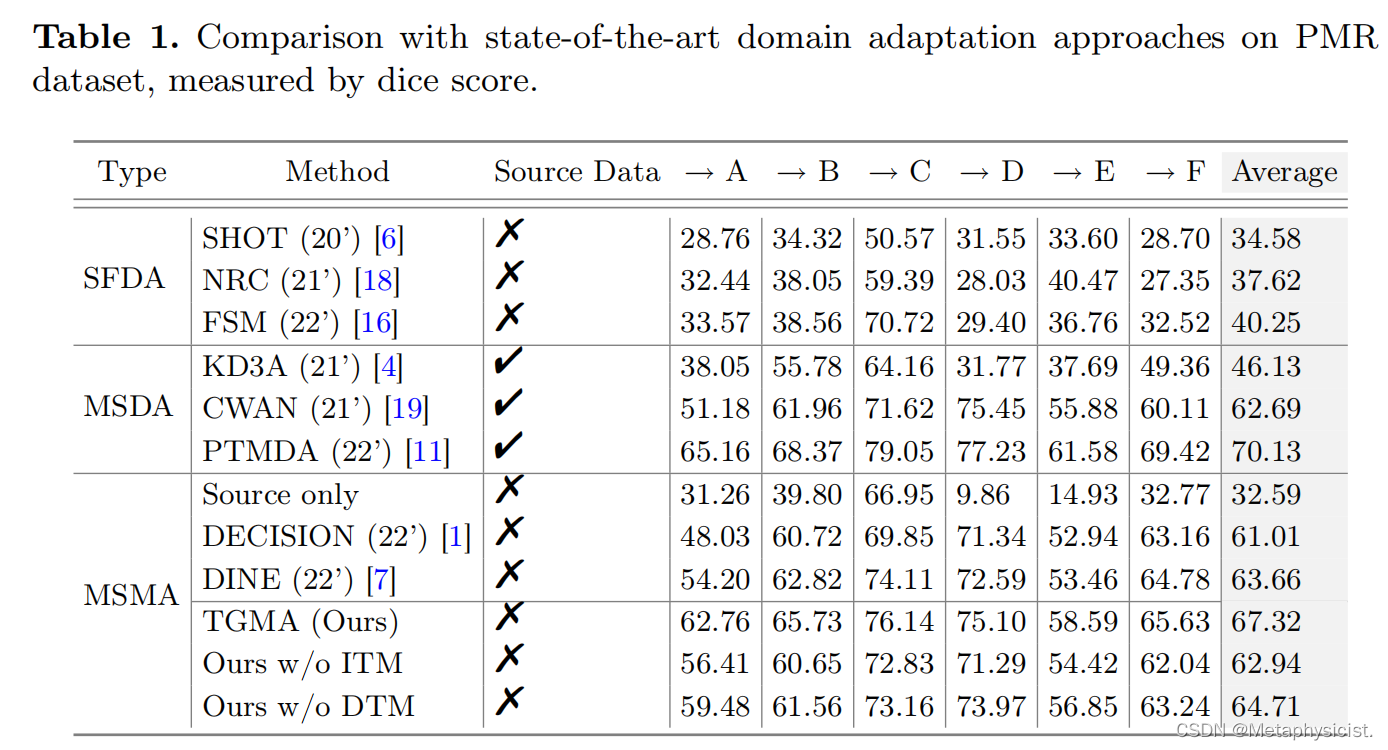
图2。对不同DA方法的PMR数据集的定性比较。
实现细节:
- 使用 PyTorch 1.7.0 和 NVIDIA RTX 2080Ti GPU 进行实现。
- 采用 UNet 作为分割模型骨干。
- 训练目标模型 200 个 epoch,batch size 为 6。
- 使用 Adam 优化器,学习率为 0.001。
- 采用 Dice 系数作为分割评估指标。
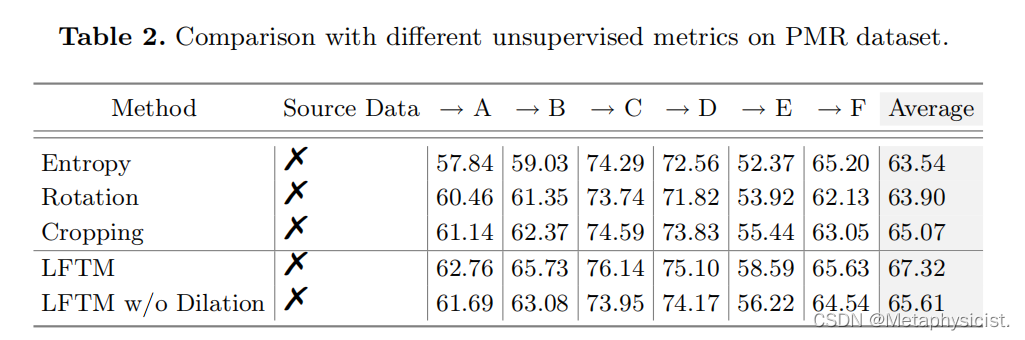
结果:
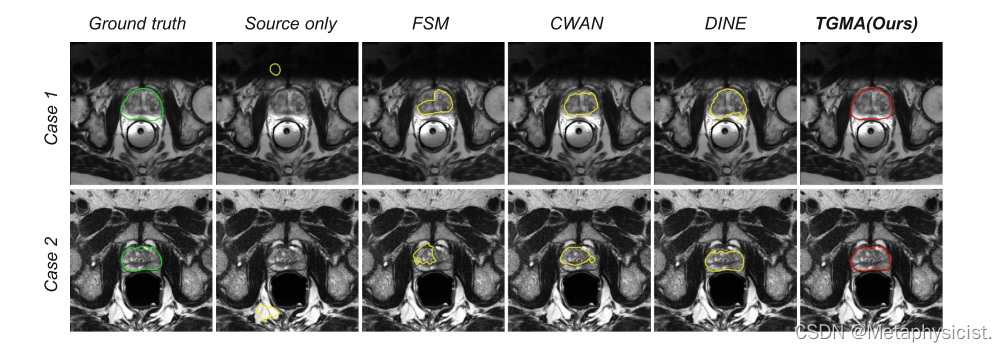
- 与现有的单源域适应 (SFDA)、多源域适应 (MSDA) 和多源模型自适应 (MSMA) 方法相比,TGMA 在平均 Dice 系数上取得了最佳性能 (67.32%)。
- 消融实验表明,实例级可迁移性矩阵 (ITM) 和域级可迁移性矩阵 (DTM) 对提高性能至关重要。
- 与其他无监督度量 (熵、旋转一致性和裁剪一致性) 相比,LFTM 在评估模型可迁移性方面表现更优。
结论:
- TGMA 通过 LFTM 有效地消除了负迁移,并通过 ITM 和 DTM 实现了精确的伪标签校正和模型选择,从而提高了目标域的分割性能。
- 该方法在多站点前列腺分割数据集上取得了显著的性能提升,证明了其有效性和实用性。
Reference
[1] Yang, C., Liu, Y., & Yuan, Y. (2023, October). Transferability-Guided Multi-source Model Adaptation for Medical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 703-712). Cham: Springer Nature Switzerland.















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











