







#本文发表于08年12月《程序员》杂志,贴出以备遗失。
对!我想介绍的和你从标题中理解的是一样的东西:大型多人在线角色扮演游戏客户端和服务器端之间通讯的数据包!之所以加一个“系”,是因为我想包含围绕数据包展开工作的相关话题。下面我所提到的数据包系就是基于这个定义。在我看到的很多网络应用中,数据包系的设计千奇百怪。这么形容并不是贬意,数据包系的本身并没有一个固定的模式,也不可能有一个统一的模式来满足所有网络应用的需求。这一点恰恰说明了数据包类与网络应用本身结合的紧密。不同的应用总要根据自己的需要对数据包本身和数据外围的功能进行重构。下面我尽量多的例举了数据包开发中涉及的环节和技巧,你可以在开发MMORPG时,针对自己的特殊应用,对上面提供的意见和技巧进行重构裁剪。
格式
TCP协议通讯时,接收方收到的数据是连续的,非官方的说法叫“粘包”。所以为了准确的分割出发送方发送的包结构,有两种做法:一种是基于“行”,这里所说的行是指在一个包结束的地方用特殊的标识符标示出来,这种办法在经典的文本协议中应用得非常广泛,这样的协议设计在互用性和扩展性上有它不可比拟的优点,Eric S. Raymond的《UNIX编程艺术》的5.4节里有着激情洋溢而又带些偏激的注解。但文本协议通常在数据冗余,协议安全等方面被人诟病,所以用在网游显然不太适合。
另外一个阵营就二进制协议,当然如果你通过巧妙的设计,也可以在二进制的协议里使用基于“行”的数据包分割办法,即通过编码方式,保证数据体里不包含标识符号。早期的一些网游,例如网上流传的《传奇1》的源代码里就是使用这种方法。但无论是扫描标识符还是编码动作本身对服务器资源都是一大浪费。通常的做法就是在每个数据包的前面添加一个数据包头,包头里面应该包含数据体的长度。也可以不显式的在数据头里包含数据包的长度,网上曾经有人在博客中写过这样一个有趣的话题,讨论到是不是要在数据包里面显式的包含一个数据包的长度数据,他认为,客户端和服务器在协议上充分认知时,只要双方能够同时理解一个数据包的命令标识,就可以推算出这个包的长度。因此,在数据包内部则不需要包含数据包的长度数据,转而将数据包的长度数据包含在数据包的接收者内部。这种方法确实可行,而且至少可以减少两个字节的长度。但从设计的角度看,接收者需要对包结构充分认知,这样的耦合是OOer不能接收的。如果是C语言的爱好者,也许并不介意这一点。
我看到过很多的包设计,都包括一个复杂的包头。里面的信息可以让这个包结构成为一个通用的设计。但如果一个只有1个字节的数据体的包,却带着一个64个字节的包头,无论是从性价比上还是美学的观点,都让人不太舒服。所以,下面我列举的包头信息是可以也是必须进行裁剪的。
l 包长度
l 公司标识
l 应用标识
l 包协议版本
l 压缩标志
l 加密标志
l 密钥标识
l 校验标志
l 包命令标识
l 发送者ID
l 接收者ID
l 发送时间
l 有效时间
l 优先级标识
l 分类标识
l 保留位置
存储
最简实现
数据包归根到底是用来存储数据的,出口点应该是提供给Send系函数的一个指针,而入口点应该提供对各种数据类型,标准库容器类以及自定义对象的串行化服务。当然入口的功能可以是由数据包类自己提供,也可以由几个辅助类协作进行。中间的部分便是如何对数据包进行存储了。最简单的办法就是直接new一个buffer出来,设置一个写指针,一个读指针,手工将数据memcpy进去。
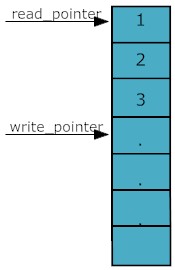
如果觉得同时维护两个指针要处理更多的边界情况,你可以干脆把数据包类设计成一个CInputPacket和一个COutPacket,开源的IM软件eva便是这么做的。在这种最简单的情况下,预分配的buffer的大小是个问题,太大了,浪费内存;太小了,又会频繁的进行再分配。
Mangos的实现
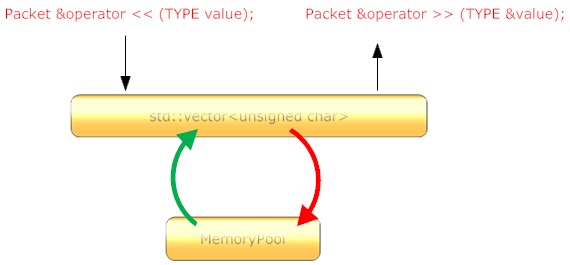
mangos里的数据包类就设计得更高级一点了,作者给出了所有基本数据类型的输入输出操作,而且还针对他的Object设计,提供了对std::map的串行化接口。值得一提的是,mangos里存储数据体的不是我们通常认为的buffer而是一个std::vector<unsigned char>,这样的设计至少有着两种好处,第一标准库里对小尺寸内存的申请释放使用了二级分配技术,也就是通常所说的内存池,大大提高了数据包这样高频度的内存使用对象的工作效率;第二,在对数据体进行操作时,可以方便的使用标准库提供的算法操作。独辟蹊径,让人拍案叫绝。
ACE提供的大餐
还有现成的美餐可以直接享用,我看到过的最复杂最强大的数据包类是ACE里的ACE_Message_Block这样的重量级作品,我们可以看看ACE_Message_Block类的构造函数:
ACE_Message_Block (size_t size,
ACE_Message_Type type = MB_DATA,
ACE_Message_Block *cont = 0,
const char *data = 0,
ACE_Allocator *allocator_strategy = 0,
ACE_Lock *locking_strategy = 0,
unsigned long priority = ACE_DEFAULT_MESSAGE_BLOCK_PRIORITY,
const ACE_Time_Value &execution_time = ACE_Time_Value::zero,
const ACE_Time_Value &deadline_time = ACE_Time_Value::max_time,
ACE_Allocator *data_block_allocator = 0,
ACE_Allocator *message_block_allocator = 0);
有三个参数化的分配器,你可以制定出自己的分配策略,使得ACE_Message_Block像前面基于std::vector的数据包类一样享用内存池带来的高效。不过,通常美餐都不是免费的,要使用ACE_Message_Block你就得把你的整个应用都移植到ACE上来。另外一个不好的地方,就是基本上没有办法在客户端复用你在服务器端关于数据包的设计,因为用ACE并不适合作为客户端的网络开发库。
数据包的存储方式还应该考虑到针对数据包的一些高频操作的优化。例如,在异步模式发送广播数据包时,应该考虑到数据包的线程安全。针对同一个数据包的多次异步发送操作,如果你能加入引用计数的话,就不需要对数据包进行深度clone了。
比较

串行化
前两天在某个同好的博客上看到一篇关于数据包类里面使用自定义协议还是分布式对象系统的争论,列举出诸多的利弊。前者嘲笑后者效率低下,代码量大。后者则反唇前者可靠性欠缺,互操作性差。回忆一下,现在这样的争论还真不少。
关于效率与设计的争论:一方说,目前网游的效率瓶颈还是主要矛盾,分布式的对象系统不适合使用在网游之上;另一方说,良好的分布式对象平台,可以大大提高网游的开发速度,更重要的是可以比自定义协议更加的可靠。说实在话,我不想扮演一个公平者的角色,然后不知不觉地倒向一方。
自定义协议在目前的网游设计中占了绝对的多数,设计者可以把握通讯过程中的细节,还有很多的消息是不太适合使用对象序列化的方法。但如果你的设计足够的复杂,并且达到一定的数据级时,数据包的数量会成指数级的增长,我看过许多优秀的设计者,在设计串行化时,或多或少的借鉴了对象序列化的方法。回想一下,我们目前网游的设计,Session,Proxy等关键词出现的频繁很高。当你自己开发的通讯模型,考虑了出错重发,连接事务,远程过程调用,服务器仿真对象,客户机代理控制,这样的设计模式使得网游本身就已经是一个分布式系统的雏形,很多的大公司已经这样称呼自己的游戏产品中所用到的服务器-客户机通讯模型。既然这样,是不是建立在一个分布式对象系统之上,唯一的理由就是效率了。分布式对象系统通讯的数据中总是要包含一些格式信息的,另外频繁的数据编解码也会耗费很多的系统资源。
数落了半天之后,不提一下ICE(Internet Communications Engine)对中间件派显然是不公平的。ICE是一个现代的面向对象的中间件平台,支持基本所有的流行语言,它的效率远远超过CORBA。ICE宣称已经有了一个完美的网游实作(《Wish》Mutable Realms, Inc.),通过ICE的分布式对象平台,利用它提供的使得的分布式计算环境,你可以让成千上万的对象生活在同一个网格的世界里。另外的方面,丰富的语言接口,也使得你有做应用整合时不需要那么绞尽脑汁。当然这已经是题我话了,按下不提。
总的看来,自己构建一个通讯的平台要比去裁剪一个成熟的分布式对象系统门坎要低得多。
标识
标识是指标示每个数据包类型的标志,也有人把它称作命令字。数据包是网游系统内部交换信息的重要手段,随着系统复杂性的增加系统内部交换的数据包越来越多,当这个数量达到一定规模时,理解代码就有一点困难了,对调试来说也是个恶梦,所以把所有的标识都定义在一个连续的空间里并不是一个明智的做法。可以将所有的标识号按照一定的规则进行分类,最常见的分类规则是按收发双方进行分类,然后为每个分类指定一个号段。按照数据包的优先级分类也很有效,这样可以避免在服务器内部再维护一个优先级号码的字典。当你的分类不是很多的时候,你可以综合上面两种分类办法,使用一个字节的高低位分别存放两种信息。完成一个功能簇的命令标识太多时,会强迫你去写一个长长的switch语句。这样的通心粉式的代码很容易引起逻辑上的漏洞。最好把一个功能簇里的标识号数量控制在一定的规模以内,至于究竟多少合适,我的建议是Arthur J.Riel提到的神奇数据7(《Object-Oriented Design Heuristics》Arthur J.Rie)。
流程
现在的网游越来越复杂了,为了提高同时在线人数,都使用了服务器集群技术。包含了:登录服务器,连接代理服务器,游戏世界服务器,聊天服务器,角色服务器,数据服务器,计费服务器等。以上各个部分之间的通讯都是以数据包作为信息的载体,当系统运行时,如果一个个数据都能被看到的话,那系统一定比南京的交通还要糟糕。这一节的标题是:流程,我想表达的意思是如何在设计时控制好数据包的流向问题,让这一切变得有序、高效、可调试、可跟踪。
我赞同某位大拿关于单线程多进程的做法。每一个进程都像一个数据的管道,设计时你要尽管避免多入多出的情形出现,保证是单入单出或者单入多出或者多入单出中的一种。这样,你就可以在单的那一头对数据进行调试,跟踪。
为了能减少各部分之间在数据包这一层次上的耦合,数据包的自说明应该是必不可少的,这也是为什么我前面同意将数据包长度显式的放在数据包头部的做法。隐含的约束也许会带来那么一点点开发时或者运行时的效率,但这一定是bug的温床。
连接代理服务器连接的是两个不同的世界,一面是低效的、不可靠的、危险的internet;一面是高效的、可靠的、安全的服务器组内部网络。所以,为了提高世界服的工作效率,那所有费时费力的工作都应该移出来放到连接代理服务器上。前面说到的,压缩、校验、加密等工作都应该在这里完成。从连接代理服务器出来进入服务器组的网络后,数据就可以裸奔了。我认为连接代理服务器的复杂度仅次于世界服,必要的时候还应该有一个连接代理管理服务器来统一管理所有的连接代理服。比如,获取负载信息,更新加密策略,改变登录流程等。
数据包还存在分级的问题,系统中流动的数据包有的时效性强,有的时效性弱。有的不可丢失,有的允许少量缺失。所以设计时,考虑建立一个科学的分级体系,在数据包缓存,转发,处理时都可以作为制定策略的参考。
压缩
压缩,在这里包括对数据压缩,也包括对数据包进行重新组合。数据包越长,出错的概率越高,所以,在长数据包发送之前进行压缩是很明智的做法。特别是从世界服裸奔来的长数据需要在连接代理服务器上广播时,这样的做法更加的有效了。另一方面,对世界服而言,接收多个数据包的场景切换比起接收一个长数据包来要昂贵得多,所以,将一段时间间隔内积累的数据包打包成一个长数据包发送给世界服这样的做法也同样有利于提高世界服的工作效能。
最常用的压缩算法当然是zip了。但因为zip算法本身的原因,只有在你的数据包里冗余的数据占一定比例时,压缩才是有效益的。在网游中,当数据里包含大量的字符串或者大量的重复数据时,压缩率比较高。
还有一种基于动态字典的数据压缩方法。在客户机与服务器之间时共同维护一个压缩的字典,这个字典是在通讯的过程中动态积累的。当新的客户机连接进来时,会从服务器端同步到一个相同压缩字典,这样双方通讯时,可以将字典中已经定义的高频数据,替换成字典的编码。这样可以大大减少数据包的体积,如果数据吞吐量成了你的网游的瓶颈时,你可以试试这样的方案。
校验
校验,TCP协议本身传递的数据包是不需要校验的。对数据包的校验只是为了防止数据在从客户端出来后,到达连接代理之前被第三方篡改。即使你使用了加密技术对数据包的数据进行了加密,校验还是必不可少的。防止错误的数据提交给世界服,从而带来不必要的干扰。常用的算法有CRC、MD5。
安全
网游中的信息安全问题,最基础的有两个,一个是用户的认证,另一个是数据包的加密。认证问题和本文谈到的数据包没有多大的关系。WOW用到的spr6是一个不错的解决方案。
数据包的加密,是一个比较复杂的问题,早期那些固定算法,固定密钥的办法现在已经不太常见了。高手们总是可以通过跟踪,暴力,反编译等手断得到他们想要知道的知识。所有的用户,甚至合法的用户都会够成对网游的危险。源自用户名和口令的加密密钥肯定是不安全的。一个想使用第三方的作弊软件的用户,会无私的把他所掌握知识提交给作弊软件。目前多数网游采用了公钥体制来完成会话密钥的协商。用户名和口令只起到身份认证的作用,而与生成的会话密钥没有直接的关系。如果要完整的说明一个相对安全的网游安全系统这一点篇幅是不够的,但有一些现成的模型可以使用。
算法的选择也很多:bluefish,3DES都被使用过。你需要在效率和安全性上找到一个平衡。其实如果你有一个健壮的密钥协商机制的话,那简单的异或加减也会起到不错的效果。毕竟对算法的攻击不是一般的游击队可以做到的。
模式
像上面说的,围绕Packet类展开的功能很多,最直接的做法是你写一个庞大臃肿的Packet类,包含所有的功能。
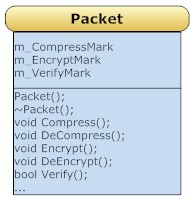
这样的设计显然比较笨拙和原始,不过这并不是我杜撰出来的。出自某个著名的网游的程序之手。现在越来越多的人认同,网游是一种服务而不是一个产品。网游从上线测试到下线关服是在不断的衍生的。在这一过程中,各种对于数据包的操作也会变更的需求,使用脚本是一种办法,但在数据包这个层次,脚本的效率太低了。所以要追求一种结构上的灵活设计。

这样的设计无论是在客户端还是服务端,你都可以使用更新动态库的办法在你需要的时候变更你对数据包的操作。而Packet类本身以及后端的服务器组里不需要为之变化。这样显然比前一种办法要好得多。
Packet类在服务器内部是使用频度最高的对象,服务器每收发一个包都需要创建或销毁一个Packet对象。最好的办法是使用对象池来完成你的设计。我尝试过使用Boost::pool来完成这部分的功能。预分配出若干Packet对象,使用时从池中分配出一个空闲Packet,使用完毕后再放回池中。预分配的Packet对象的数量你需要参数化并放到配置文件中,根据你的应用规模调节到一个比较合适的值。
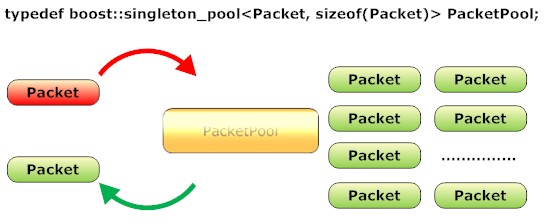
使用数据包池的实现要小心处理数据包池和数据包存储数据时使用的内存池的关系,处理不当很容易引起错误。
小结
网游开发是一个项杂活,涉及到的软件技术很多,应该考虑到的问题也很多。很多的作法还在不断的演进,上文只能作一小瞥。















 1411
1411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









