







 本文介绍了K近邻算法的基本原理,包括定义、性能和使用方法,以及在股票行业分类中的应用尝试。作者通过实例展示了如何利用历史收益率数据进行预测,指出特征选择和K值对结果的影响,以及实践中遇到的挑战和经验教训。
本文介绍了K近邻算法的基本原理,包括定义、性能和使用方法,以及在股票行业分类中的应用尝试。作者通过实例展示了如何利用历史收益率数据进行预测,指出特征选择和K值对结果的影响,以及实践中遇到的挑战和经验教训。
免责声明:本文由作者参考相关资料,并结合自身实践和思考独立完成,对全文内容的准确性、完整性或可靠性不作任何保证。同时,文中提及的数据仅作为举例使用,不构成推荐;文中所有观点均不构成任何投资建议。请读者仔细阅读本声明,若读者阅读此文章,默认知晓此声明。
21年上班空闲之际,就开始尝试学习机器学习理论,前后整体有3次,每次大概持续1-3个月,最终均以放弃告终。这一次,采用记笔记的方式来作为监督,希望能坚持得更长一点。作为一个金融专业普通大学的毕业生,于大四机缘下学习了Python,而后一直持续到现在,属实不易。然而,机器学习毕竟有着较高的门槛,堪比蜀道难。从期望入门到放弃也是大多数人常态,包括我自己;只是每一次的尝试,都能让自己接近那么一点点。秉持这种借口式的想法,继续出发吧。
按照顺序,本期就先记录下关于K近邻算法,由于智商和经验均不在线,就浅尝辄止,大放厥词了,因此各位读者且看且谨慎,也希望大神能不吝赐教,评论区多多指正!
1. 算法简介
1.1 定义
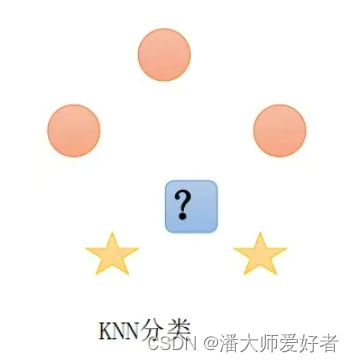
如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。在计算相邻的距离时,使用欧式距离。举个例子:下图中,蓝色方框需要确认其类型是圆圈还是五角星。在K取值为3的情况下,其距离最近的有一个圆圈,两个五角星,五角星数量多于圆圈,因此判定其类别为五角星;在K取值为5的情况下,其距离最近的有三个圆圈,两个五角星,因此判定其类别属于圆圈。
1.2 性能
优点:1.容易理解和实现;2.不需要参数估计和训练
缺点:1.属于懒惰算法,计算量较大,耗内存;2. K值对结果的影响很大
使用场景:数据量较小,几千到几万的数据量
1.3 函数
使用python的sklearn模块。
from sklearn.neighbors import KNeighborsClassifier2. 案例介绍
2.1 思路一
在分类的预测上,希望使用过去1,5,10,20,30日收益率数据作为特征,来判断某只股票对应的所属行业。
使用房地产和化工两个行业,最终有效标的252个;按照近80%训练,近20%检验的思路,最终得分在54%-57%之间。两个行业,即使是去猜的情况下,也应该有50%左右的胜率,因此说明模型整体的效果不好,同时在数据上也应该增加相应的其他行业,使得数据量更大,类型更多。同时,如果新增数据后,得分降低到30%-40%之间,说明选取的特征数据具有较强一致性,在分类的效果上不佳。
2.2 思路二
在思路一的基础上,使用房地产、化工和汽车制造三个行业,最终有效标的352个;按照近80%训练,近20%检验的思路,最终得分在37%-40%之间,说明选取的特征值具有较强的一致性,同时数据量也不足。
'''
根据过去1日,5日,10日,20日,30日的涨跌幅来判断股票所属的行业分类
'''
import akshare as ak
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
def hist_return(n, data):
# 获取历史的涨跌幅,异常情况设置特殊值便于后续剔除
try:
close = data['收盘'].values[-2]
last_close = data['收盘'].values[-2 - n]
value = round(close / last_close - 1, 4)
except:
value = 9999
return value
def get_one_data(code):
# 获取单个股票的数据
data = ak.stock_zh_a_hist(str(code), 'daily', '20240101', '20240329')
out_df = {'code': code, 'last': hist_return(1, data), 'last_5': hist_return(5, data),
'last_10': hist_return(10, data), 'last_20': hist_return(20, data),
'last_30': hist_return(30, data)}
return out_df
# 获取行业数据
industry = ak.stock_sector_spot('新浪行业')
# 获取行业数据的成分股,并合并对应的数据
dfc = ak.stock_sector_detail('new_fdc')
dfc['所属行业'] = '房地产'
dfc['行业编码'] = 0
fdc_data = dfc.loc[:, ['code', 'name', '所属行业', '行业编码']]
hghy = ak.stock_sector_detail('new_hghy')
hghy['所属行业'] = '化工'
hghy['行业编码'] = 1
hghy_data = hghy.loc[:, ['code', 'name', '所属行业', '行业编码']]
qczz = ak.stock_sector_detail('new_qczz')
qczz['所属行业'] = '汽车制造'
qczz['行业编码'] = 2
qczz_data = qczz.loc[:, ['code', 'name', '所属行业', '行业编码']]
me_df = pd.concat([fdc_data, hghy_data])
code_df = pd.concat([me_df,qczz_data])
# 获取特征值的数据(即收益率数据),并对数据进行清洗
data_list = []
for code in code_df['code']:
print(code)
data_list.append(get_one_data(code))
data_set = pd.DataFrame(x for x in data_list)
new_data = data_set.loc[data_set['last'] != 9999]
all_data = pd.merge(new_data, code_df, how='left', on='code')
all_data.to_excel('data.xlsx', index=False)
# 选择需要的特征数据,并切割训练数据和检验数据
x = np.array(all_data.loc[:, ['last', 'last_5', 'last_10', 'last_20', 'last_30']])
y = np.array(all_data['行业编码'])
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.8, random_state=len(all_data))
# 建模并进行相应的预测和打分
knc = KNeighborsClassifier(5)
knc.fit(X_train, y_train)
y_predict = knc.predict(X_test)
score_value = round(knc.score(X_test, y_test), 4)2.3 思路三
在思路二的基础上,剔除其他特征,仅保留1日日收益率两个特征,按照近80%训练,近20%检验的思路,最终得分在35%-37%之间,说明特征的区分度不足。
3. 总结
案例算是一次新的尝试,踩了坑,最终的结果也不好,但是也加深了印象,积累了经验。对于K近邻,样本的特征比较重要,若不能找到合适的特征,分类的效果也会受到影响,当然我这是基于逆行推导的想法(希望特征数据具备因子的特性,能够有助于结果的精度);K值的影响也很大,其次就是数据的量。优化的过程远比建模的过程复杂,路漫漫其修远兮。
免责声明:本文由作者参考相关资料,并结合自身实践和思考独立完成,对全文内容的准确性、完整性或可靠性不作任何保证。同时,文中提及的数据仅作为举例使用,不构成推荐;文中所有观点均不构成任何投资建议。请读者仔细阅读本声明,若读者阅读此文章,默认知晓此声明。















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









